计算机视觉学习第六章——图像聚类
目录
引言
一、K-means聚类
1.1 Scipy聚类包
1.2 图像聚类
1.3 在主成分上可视化图像
1.4 像素聚类
二、层次聚类
2.1 图像聚类
三、 谱聚类
引言
在这个章节将学习几种聚类方法,并利用这些方法对图像进行聚类,从而寻找相似的图像组。聚类可以用于识别、划分图像数据集,组织和导航,同时还会对聚类的图像进行相似性可视化。
一、K-means聚类
K-means是一种将输入数据划分位k个簇的简单的聚类算法。K-means反复提炼初始评估的类中心,具体步骤:
1、以随机或猜测的方式初始化类中心![]()
2、将每个数据点归并到离它距离最近的类中心所属的类
3、对所有属于该类的数据点求平均,将平均值作为新的类中心
4、重复步骤2和步骤3知道收敛
K-means试图使类内总方差最小:
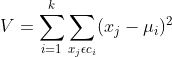
 是输入数据,并且是矢量。该算法是启发式提炼算法,虽然可以在多数情形下使用,但并不能保证得到最优的结果。通常为了避免出现没选好类中心处置而出现误差的情形,该算法通常会初始化不同的类中心进行多次运算,选择方差V最小的结果。
是输入数据,并且是矢量。该算法是启发式提炼算法,虽然可以在多数情形下使用,但并不能保证得到最优的结果。通常为了避免出现没选好类中心处置而出现误差的情形,该算法通常会初始化不同的类中心进行多次运算,选择方差V最小的结果。
算法的优缺点:
缺陷:必须设定好聚类数k,如果选择不恰当就会导致结果很差。
优点:易于实现。
1.1 Scipy聚类包
可以通过Scipy矢量量化包scipy.cluster.vq实现K-means算法。
下面为利用K-means对二维数据进行聚类的示例:
from scipy.cluster.vq import *
from pylab import *
from numpy import *
class1 = 1.5 * random.randn(100, 2)
class2 = random.randn(100, 2) + array([5, 5])
features = vstack((class1, class2))
centroids, variance = kmeans(features, 2)
code, distance = vq(features, centroids)
figure()
ndx = where(code == 0)[0]
plot(features[ndx, 0], features[ndx, 1], '*')
ndx = where(code == 1)[0]
plot(features[ndx, 0], features[ndx, 1], 'r.')
plot(centroids[:, 0], centroids[:, 1], 'go')
axis('off')
show()分析:
在该算法中,首先生成两类二维正态分布数据,并用k=2对这些数据进行聚类,由于K-means算法会计算若干次,并选择方差最小的结果。接着使用矢量量化函数对每个数据点进行归类。函数where会给出每个类的索引点。
输出结果如上图所示,类中心就为两个类的中心绿色的点,其周围的蓝色和红色点就是预测出来的类。
1.2 图像聚类
使用了书中推荐的selectedfontimages.zip中的字体数据集图像进行聚类,可以在Python计算机视觉编程页面中下载实验所需要的压缩包。
import pickle
from PIL import Image
from pylab import *
from numpy import *
from scipy.cluster.vq import *
from PCV.tools import imtools
# 获取seleced-fontimages文件下图像文件名,并保存在列表中
imlist = imtools.get_imlist('D:\\picture\selected_thumbs\\')
imnbr = len(imlist)
# 载入模型文件
with open('a_pca_modes.pkl', 'rb') as f:
immean = pickle.load(f)
V = pickle.load(f)
# 创建矩阵,存储所有拉成一组形式后的图像
immartix = array([array(Image.open(im)).flatten() for im in imlist], 'f')
# 投影到前40个主成分上
immean = immean.flatten()
projected = array([dot(V[:40], immartix[i] - immean) for i in range(imnbr)])
# 进行K-means聚类
projected = whiten(projected)
centroids, distortion = kmeans(projected, 4)
code, distance = vq(projected, centroids)
# 绘制聚类簇
for k in range(4):
ind = where(code == k)[0]
figure()
gray()
for i in range(minimum(len(ind), 40)):
subplot(4, 10, i+1)
imshow(immartix[ind[i]].reshape((25, 25)))
axis('off')
show()
通过之前计算过的前40个主成分进行投影,用投影系数作为每幅的向量描述符,code变量中包含的是每幅图像属于哪个簇,设定聚类数k=4,并用whiten()函数对数据进行”白化“处理,以及归一化处理,使得每个特征具有单位方差。
当将主成分数目改为30,聚类数改成3时可视化聚类结果就为;

1.3 在主成分上可视化图像
利用PIL中的ImageDraw模块进行可视化,观察如何利用主成分进行聚类,可以在一对主成分方向的坐标上可视化这些图像,可以将projected改为:
projected = array([dot(V[[0,2]], immartix[i] - immean) for i in range(imnbr)])import pickle
from PIL import Image, ImageDraw
from matplotlib.image import thumbnail
from numpy import *
from PCV.tools import imtools
h,w = 1200,1200
# 创建一幅白色背景图
# 获取seleced-fontimages文件下图像文件名,并保存在列表中
imlist = imtools.get_imlist('D:\\picture\selected_thumbs\\')
imnbr = len(imlist)
# 载入模型文件
with open('a_pca_modes.pkl', 'rb') as f:
immean = pickle.load(f)
V = pickle.load(f)
# 创建矩阵,存储所有拉成一组形式后的图像
immartix = array([array(Image.open(im)).flatten() for im in imlist], 'f')
# 投影到前40个主成分上
immean = immean.flatten()
projected = array([dot(V[[0,2]], immartix[i] - immean) for i in range(imnbr)])
img = Image.new('RGB', (w,h),(255, 255, 255))
draw = ImageDraw.Draw(img)
# 绘制坐标轴
draw.line((0, h/2, w, h/2), fill=(255, 0, 0))
draw.line((w/2, 0, w/2, h), fill=(255, 0, 0))
# 缩放以适应坐标系
scale = abs(projected).max(0)
scaled = floor(array([(p/scale)*(w/2-20,h/2-20)+(w/2,h/2) for p in projected])).astype(int)
for i in range(imnbr):
nodeim = Image.open(imlist[i])
nodeim.thumbnail((25, 25))
ns = nodeim.size
box = (scaled[i][0] - ns[0] // 2, scaled[i][1] - ns[1] // 2,
scaled[i][0] + ns[0] // 2 + 1, scaled[i][1] + ns[1] // 2 + 1)
img.paste(nodeim,box)
img.save('pca_font.jpg')根据书中给出的源代码运行时,给出了

这里是由于paste处理的应当是整数而非浮点数,需要将:
scaled = floor(array([(p/scale)*(w/2-20,h/2-20)+(w/2,h/2) for p in projected]))改为:
scaled = floor(array([(p/scale)*(w/2-20,h/2-20)+(w/2,h/2) for p in projected])).astype(int)这时运行成功,在项目文件夹里就会出现pca_font.jpg,打开就会显示为
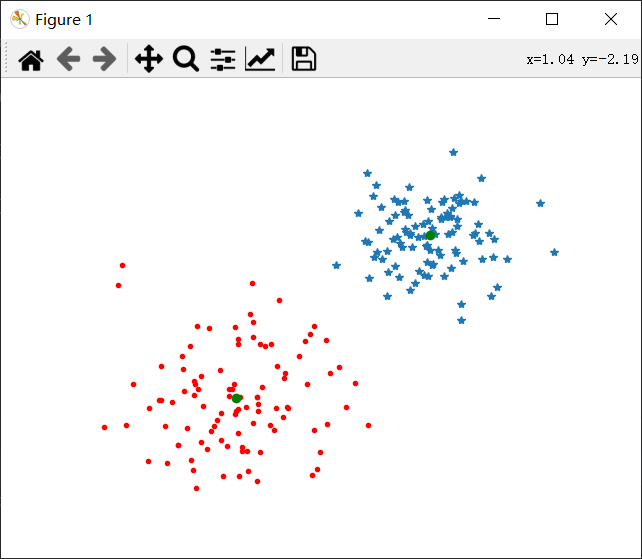
这类图像说明了这些字体图像在40维里的分布情况,对于选择一个好的描述子具有很好的帮助,从图中我们可以看到相似的字体挨得比较近。
1.4 像素聚类
这里进行对一个单幅图像中的像素而非全部图像中的像素而非全部图像进行聚类的例子,除了在一些简单的图像上,单纯在像素水平上应用K-means是无意义的,要产生有意义的结果往往就需要更复杂的类模型。
下面就是用一个步长为steps的方形网格在图像中滑动,每滑一次对网格中图像区域像素求平均值,将其作为新生的低分辨率图像对应位置处的像素值,并用K-means进行聚类:
from scipy.cluster.vq import *
from PIL import Image
from pylab import *
steps = 50 # 图像被划分为steps*steps的区域
im = array(Image.open('D:\picture\\test_img0\\tem1.jpg'))
dx = im.shape[0]//steps
dy = im.shape[1]//steps
# 计算每个区域的颜色特征
features = []
for x in range(steps):
for y in range(steps):
R = mean(im[x * dx:(x + 1) * dx, y * dy:(y + 1) * dy, 0])
G = mean(im[x * dx:(x + 1) * dx, y * dy:(y + 1) * dy, 1])
B = mean(im[x * dx:(x + 1) * dx, y * dy:(y + 1) * dy, 2])
features.append([R, G, B])
features = array(features, 'f') # 变成数组
# 聚类
centroids, variance = kmeans(features, 3)
code, distance = vq(features, centroids)
# 用聚类标记创建图像
codeim = code.reshape(steps,steps)
subplot(121)
imshow(im),axis('off')
subplot(122)
imshow(codeim),axis('off')
show() 
二、层次聚类
这是另一种简单有效的聚类算法,其思想是基于样本间成对距离建立一个简相似性树,首先将特征向量距离最近的两个样本归并为一组,并在树中创建一个平均节点,将两个距离最近的样本作为该“平均”节点下的子节点,然后再剩下的包含任意平均节点节点的样本中寻找下一个最近的对,重复进行前面的操作。在每一个节点处保存了两个子节点之间的距离。遍历整个树,通过设置的阈值,遍历过程可以在比阈值大的节点位置终止从而提取出聚类簇。
层次聚类的优缺点:
优点:利用树结构可以可视化数据间的关系,并显示这些簇是如何关联的。对于给定的不同的阈值,可以直接利用原来的树,无需重新计算。
缺点:对于实际需要的聚类簇,需要选择一个合适的阈值。
算法体现:
class ClusterNode(object):
def __init__(self,vec,left,right,distance=0.0,count=1):
self.left = left
self.right = right
self.vec = vec
self.distance = distance
self.count = count # 只用于加权平均
def extract_clusters(self,dist):
""" 从层次聚类树中提取距离小于dist的子树簇群列表 """
if self.distance < dist:
return [self]
return self.left.extract_clusters(dist) + self.right.extract_clusters(dist)
def get_cluster_elements(self):
""" 在聚类子树中返回元素的id """
return self.left.get_cluster_elements() + self.right.get_cluster_elements()
def get_height(self):
""" 返回节点的高度,高度是各分支的和 """
return self.left.get_height() + self.right.get_height()
def get_depth(self):
""" 返回节点的深度,深度是每个子节点取最大再加上它的自身距离 """
return max(self.left.get_depth(), self.right.get_depth()) + self.distance
class ClusterLeafNode(object):
def __init__(self,vec,id):
self.vec = vec
self.id = id
def extract_clusters(self,dist):
return [self]
def get_cluster_elements(self):
return [self.id]
def get_height(self):
return 1
def get_depth(self):
return 0
def L2dist(v1,v2):
return sqrt(sum((v1-v2)**2))
def L1dist(v1,v2):
return sum(abs(v1-v2))
def hcluster(features,distfcn=L2dist):
""" 用层次聚类对行特征进行聚类 """
# 用于保存计算出的距离
distances = {}
# 每行初始化为一个簇
node = [ClusterLeafNode(array(f),id=i) for i,f in enumerate(features)]
while len(node)>1:
closest = float('Inf')
# 遍历每对,寻找最小距离
for ni,nj in combinations(node,2):
if (ni,nj) not in distances:
distances[ni,nj] = distfcn(ni.vec,nj.vec)
d = distances[ni,nj]
if d为树节点创建两个类,即ClusterNode和ClusterLeafNode,这两个类用于创建聚类树,函数hcluster()用于创建树。
距离度量的选择依赖于实际的特征向量, 是欧式距离,通过创建任意距离度量,并将其作为参数传递给hcluster(),每个子树,计算其所有节点特征向量的平均值,作为新的特征向量来表示该子树,并将每个子树视为一个对象。
是欧式距离,通过创建任意距离度量,并将其作为参数传递给hcluster(),每个子树,计算其所有节点特征向量的平均值,作为新的特征向量来表示该子树,并将每个子树视为一个对象。
下面就观察该聚类的过程。首先创建一些二维数据点:
from PCV.clustering import hcluster
from numpy import *
class1 = 1.5 * random.randn(100,2)
class2 = random.randn(100,2) + array([5,5])
features = vstack((class1,class2))
tree = hcluster.hcluster(features)
clusters = tree.extract_clusters(5)
print('number of clusters', len(clusters))
for c in clusters:
print(c.get_cluster_elements())这里设置阈值为5,并从列表中提取这些聚类簇,并于控制台中打印出来。
![]()
2.1 图像聚类
使用了sunset.zip中包含的图像集,可以在上面给的链接下载的文件包里获得。这里可以通过颜色直方图作为每幅图像的特征向量。
实验如下:
将R,G,B三个颜色通道作为特征向量,将其传递到Numpy的histogramdd()函数中计算多维直方图,并在每个颜色通道中使用8个小区间进行量化,将量化后的小区间拉成一行后用512维的特征向量描述每幅图像。为了可视化聚类树,就需要画出树状图:
from PIL import Image,ImageDraw
def draw_dendrogram(node,imlist,filename='clusters.jpg'):
""" 绘制聚类树状图,并保存到文件里 """
# 高和宽
rows = node.get_height()*20
cols = 1200
# 距离缩放因子
s = float(cols-150)/node.get_depth()
# 创建图像并绘制对象
im = Image.new('RGB',(cols,rows),(255,255,255))
draw = ImageDraw.Draw(im)
# 初始化开始的线条
draw.line((0,rows/2,20,rows/2),fill=(0,0,0))
# 递归地画出节点
node.draw(draw,20,(rows/2),s,imlist,im)
im.save(filename)
im.show()同时在绘制树状图时还使用了draw()方法:
def draw(self,draw,x,y,s,imlist,im):
""" 使用图像缩略图递归绘制叶节点 """
h1 = int(self.left.get_height()*20 / 2)
h2 = int(self.right.get_height()*20 /2)
top = y-(h1+h2)
bottom = y+(h1+h2)
draw.line((x,top+h1,x,bottom-h2),fill=(0,0,0))
ll = self.distance*s
draw.line((x,top+h1,x+ll,top+h1),fill=(0,0,0))
draw.line((x,bottom-h2,x+ll,bottom-h2),fill=(0,0,0))
self.left.draw(draw,x+ll,top+h1,s,imlist,im)
self.right.draw(draw,x+ll,bottom-h2,s,imlist,im)实际图像缩略图中,叶节点有自己的方法:
def draw(self,draw,x,y,s,imlist,im):
nodeim = Image.open(imlist[self.id])
nodeim.thumbnail([20,20])
ns = nodeim.size
im.paste(nodeim,[int(x),int(y-ns[1]//2),int(x+ns[0]),int(y+ns[1]-ns[1]//2)])主函数:
from PIL import Image
from pylab import *
from numpy import *
import os
from PCV.clustering import hcluster
# 创建图像列表
path = 'D:\\BaiduNetdiskDownload\\PCV-book-data\\data\sunsets\\flickr-sunsets-small'
imlist = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.jpg')]
# 提取特征向量,每个颜色通道量化成8个小区间
features = zeros([len(imlist),512])
for i,f in enumerate(imlist):
im = array(Image.open(f))
# 多维直方图
h,edges = histogramdd(im.reshape(-1,3),8,normed=True,
range=[(0,255),(0,255),(0,255)])
features[i] = h.flatten()
tree = hcluster.hcluster(features)
# 保存树状图
hcluster.draw_dendrogram(tree,imlist,filename='sunset.pdf')
# 设置一些阈值,得到可视化聚类簇
clusters = tree.extract_clusters(0.23*tree.distance)
# 绘制聚类簇中元素超过3个的图像
for c in clusters:
elements = c.get_cluster_elements()
nbr_elements = len(elements)
if nbr_elements>3:
figure()
for p in range(minimum(nbr_elements, 20)):
subplot(4, 5, p+1)
im = array(Image.open(imlist[elements[p]]))
imshow(im)
axis('off')
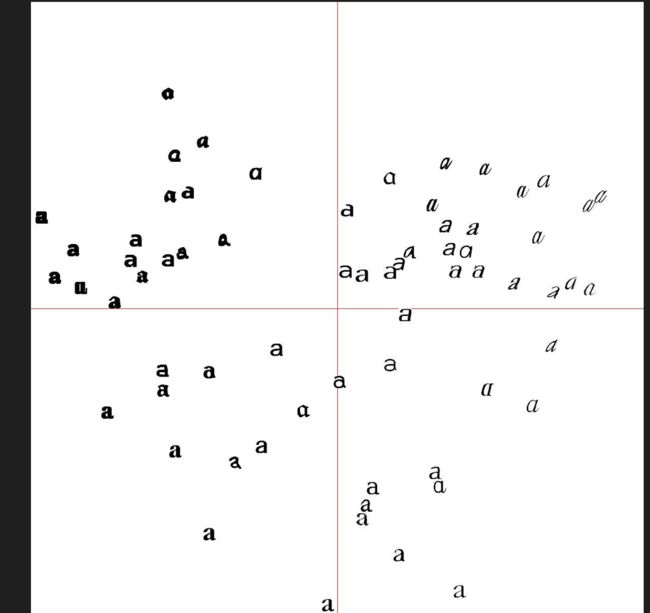
show()可以得到结果:
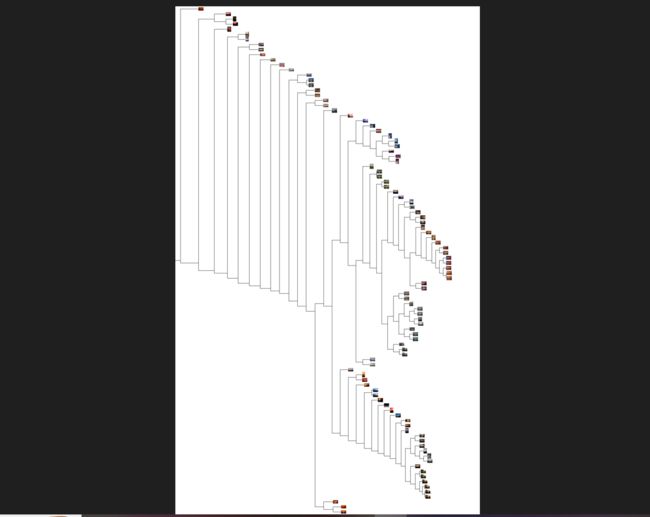
树状图的高和子部分由距离决定,这些需要经过调整来适应选择的图像分辨率,随着坐标向下传递到下一级,并递归绘制出这些节点。这里使用get_height()和get_depth()两个辅助函数获得树的高和宽。
在上图中就可以看到颜色相近的图像在树中的距离就比较近。
三、 谱聚类
谱聚类与K-means以及层次聚类方法完全不同。对于n个元素,相似矩阵是一个n*n的矩阵,矩阵的每个元素表示两两之间的相似性分数。谱聚类是由相似性矩阵构建谱矩阵而得名。
谱聚类的优点是仅需输入相似矩阵,并且可以采用你所想到的任意的度量方式构建该相似矩阵,对比K-means和层次聚类需要计算特征向量求平均,可这样就会将特征或描述子限制为向量,谱聚类就没有这类限制。
谱聚类的过程:
给定n*n的相似矩阵S,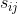 为相似性分数,创建矩阵,称为拉普拉斯矩阵:
为相似性分数,创建矩阵,称为拉普拉斯矩阵:
![]()
I为单位矩阵,D为对角矩阵,对角线上的元素是S对应行元素之和,![]() 分别为:
分别为:
![]()
![]() 为:
为:

对于相似性矩阵中的元素,使用较小的值并且要求大于等于0。
计算L的特征向量,并使用K个最大特征值对应的k个特征向量,构建出一个特征向量集从而找到聚类簇,创建一个矩阵,这个矩阵就是有求出的k个特征向量构成的每一行都可以看成是一个新的特征向量,长度为k,本质上谱聚类算法是将原始空间中的数据转换成更容易聚类的新的特征向量。
下面为谱聚类算法的实验:
from scipy.cluster.vq import *
import pickle
from PIL import Image
from pylab import *
from numpy import *
from PCV.tools import imtools
imlist = imtools.get_imlist('D:\\picture\selected_thumbs\\')
imnbr = len(imlist)
# 载入模型文件
with open('a_pca_modes.pkl', 'rb') as f:
immean = pickle.load(f)
V = pickle.load(f)
# 创建矩阵,存储所有拉成一组形式后的图像
immartix = array([array(Image.open(im)).flatten() for im in imlist], 'f')
# 投影到前40个主成分上
immean = immean.flatten()
projected = array([dot(V[[0,2]], immartix[i] - immean) for i in range(imnbr)])
n = len(projected)
# 计算距离矩阵
S = array([[sqrt(sum((projected[i]-projected[j])**2)) for i in range(n)] for j in range(n)], 'f')
# 创建拉普拉斯矩阵
rowsum = sum(S, axis=0)
D = diag(1 / sqrt(rowsum))
I = identity(n)
L = I - dot(D, dot(S, D))
# 计算矩阵L的特征向量
U, sigma, V = linalg.svd(L)
k = 5
# 从矩阵L的前k个特征向量中创建特征向量
# 叠加特征向量作为数组的列
features = array(V[:k]).T
# k-means聚类
features = whiten(features)
centroids, distortion = kmeans(features, k)
code, distance = vq(features, centroids)
# 绘制聚类簇
for c in range(k):
ind = where(code == c)[0]
figure()
for i in range(minimum(len(ind), 39)):
im = Image.open(imlist[ind[i]])
subplot(4, 10, i+1)
imshow(array(im))
axis('equal')
axis('off')
show()

这里使用两两间的欧式距离创建矩阵S,并对k个特征向量进行常规K-means进行聚类k=5,V包含的是对特征值进行排序后的特征向量并绘制出这些聚类簇。