深度学习 -- Faster rcnn 算法流程详解
经典论文,后续很多论文以此为基础,所以搞懂流程比较重要,中间如果 有写的不对、有问题或者看不懂的地方,还望指正。如果有了新的理解,我会持续更新。
Faster Rcnn是目前学术上用的非常多的目标检测算法,这里来认真的梳理一遍该算法的流程,主要看检测的部分。
一、 网络结构:

这是faster rcnn的整个网络结构,一共有四个部分组成:
1. CNN特征提取网络:
2. RPN网络:
3. ROI Pooling :
4. classifier :
想要把整个流程走下来,首先要理解几个必须知道的关键词:
1.1 卷积操作(conv layer)
何为卷积操作,看下图,图中有一个黄色的 3*3 的矩阵在绿色的矩阵上做滑窗,生成了粉色的计算结果,每一次计算都是一次卷积,这就是最简单的平面卷积,黄色的滑窗也被称为滤波器(filter)或者卷积核(Convolution kernel)。

然后,卷积核的个数增加时,卷积的结果就等于卷积核的个数,例如 30*30*256 的 feature map 和 (3*3*256)*256作卷积,pading = 1 ,strip = 1 得到的结果仍然是30*30*256。
1.2 anchors:
anchors是一组由 rpn/generate_anchors.py 生成的矩形。是RPN网络提出的候选框的雏形,因为RPN网络最终要生成一定数量的 proposal(候选区域的提议),所以要先在CNN网络提取到的 feature map 上提出anchors,每个点上提出9个anchor。anchor的格式如下:
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
# 从前到后分别是anchor左上角的坐标,右下角的坐标。
# 一共有9个矩形,3种形状,长宽比为大约为 1:1 ,2:1,1:2 三种,网络的多尺度方法就是通过anchors就引入的。然后来看这9个 anchors 的作用,下图是Faster RCNN论文中的原图,最下面的是卷积后得到的 feature maps ,为每一个点都配备这 9 种 anchors 作为初始的检测框。

1 .在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions
2. 在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息,也就是图中的红框。
3. 假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4k coordinates
从这个角度看,RPN就是利用feature map生成anchor,然后用 softmax 去判断哪些Anchor是里面有目标的,哪些是没目标的(相当于提出了一堆候选框,再判断里边是不是有东西,有东西的标记为foreground anchor,没东西的标记为backgroud)。下面的图非常好的体现了anchor究竟是什么。注意:右边的密密麻麻的红色框就是anchor映射到原图上的效果,这个坐标是超出原图尺寸的,因为在原图过CNN网络的时候,有pading操作,所以其实anchor是能够顾及到原图中的所有像素点的。

1.3 softmax:
这篇博客介绍了什么是softmax,https://blog.csdn.net/red_stone1/article/details/80687921
二、 运行流程:
知道了上面几个关键词的意思,我们来看算法的流程。
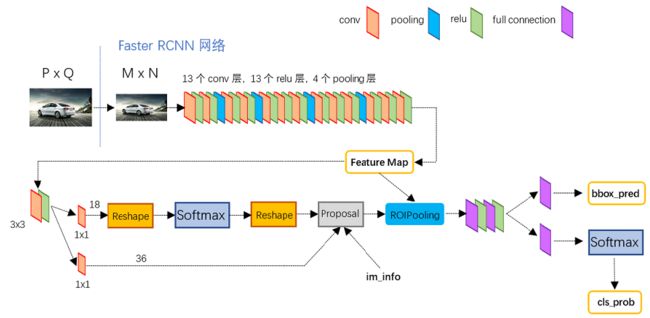
1. 首先是CNN网络
上图是分解之后的Faster rcnn,这张图展示了使用 VGG16 模型的 faster_rcnn 网络结构。可以看到该网络首先将一副任意大小PxQ的图像,首先缩放至固定大小MxN,然后将MxN图像送入网络;而 Conv layers 中包含了13个conv层+13个relu层+4个 pooling 层。经过这一系列的操作,图像的大小变为的原图的 (M/16)x(N/16),也就是图中的 Feature Map 的大小。(这里应该没有很多问题,CNN网络是可以替换的,比如可以换成比较新的 Resnet 和 DenseNet等,只要保证数据的维度正确)
2. RPN网络:
RPN网络首先对输入的(M/16)x(N/16)的 Feature Map 做一个3x3卷积操作,然后分成两条路:一条去判断anchors的类别,另一条计算 bounding box 的预测值。这样 Proposal 的输入就有6个,分别是bbox的四个预测值(x,y,w,h),以及anchor的类别(foreground和background)(这里两条路的anchor是一一对应的,这样才能进行后续的回归)。有了上面的几个参数,就可以进行bounding box 的修正(也就是文中的 bounding box regression )。
例如:下图中的绿色框为飞机的Ground Truth(GT),红色为提取的foreground anchors,即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得foreground anchors和GT更加接近。

窗口使用四维向量 (x,y,w,h) 表示,分别表示窗口的中心点坐标和宽高。对于上图,红色的框A代表原始的Foreground Anchors,绿色的框G代表目标的GT,我们的目标是寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G',任务可以描述为A为直接提出的anchor,GT为真实值ground truth,F是一种变换关系,G'是通过回归求到的预测框:

其中 F 的思路是先做平移在做缩放:
- 先做平移
- 再做缩放
这当中的未知量有四个,所以通过线性回归求这四个参数(每一个 anchor 都有这四个参数,所以 feature map 上的每个点都会有 4*9=36 个用于回归的参数),这四个参数是 anchor 和 G' 之间的变换关系:
怎样求这四个参数呢?我们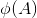 来表示经过第五次卷积的 feature map,则d(A)的求取方式如下
来表示经过第五次卷积的 feature map,则d(A)的求取方式如下
上面的4个参数作为预测值,t*是真实值(就是GT和anchor之间的变换关系,作为监督信号),这样就可以设计Loss函数如下
函数优化目标为:
只有在GT与需要回归框位置比较接近时,才可近似认为上述线性变换成立。说完原理,Faster RCNN原文中的变换关系求取方式如下图:

x , xa, x*三个参数分别是,G' ,anchors和 GT的坐标,前两行是从 anchor 到 G' 之间的变换,后两行是从anchor 到GT之间的变换,将后两行作为监督信号,前两行作为训练目标,尽量减小Loss就可以使 G' 不断的贴近 GT。这样,那么当bouding box regression工作时,再输入Φ时,回归网络分支的输出就是每个Anchor的平移量和变换尺度 上图中前两行的(tx,ty,tw,th),用这几个参数就能对提出的 anchor 进行修正了。
3. Proposal Layer
RPN网络的最后部分是 Proposal Layer 该部分的输入有三个:anchors分类器结果,bounding box 的回归结果,以及im_info。首先解释 im_info 。对于一副任意大小PxQ图像,传入Faster RCNN前首先reshape到固定MxN,im_info=[M, N, scale_factor]保存了此次缩放的所有信息。然后经过Conv Layers,经过4次pooling变为WxH=(M/16)x(N/16)大小,其中feature_stride=16则保存了该信息,用于计算anchor偏移量。
Proposal Layer的工作流程如下:
- 生成anchors, 对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
- 按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的foreground anchors。
- 限定超出图像边界的foreground anchors为图像边界(防止后续roi pooling时proposal超出图像边界)
- 剔除非常小(width
- 进行nonmaximum suppression
- 再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前 300 个结果作为proposal输出。
目标检测的部分基本上就到这里,最后的是对 bbox 的精修。
4 . ROI Pooling
Roi Pooling 的工作是:利用体渠道的 proposals 从 feature maps 中提取 proposal feature 送入后续全连接和 softmax 网络作classification(即分类proposal到底是什么object)。
为什么要有 ROI Pooling呢:
其实就是为了同意上层输出的 proposal 的大小,见下图:

参考资料: faster rcnn
知乎:https://zhuanlan.zhihu.com/p/31426458