Hive数据查询语言-DQL-含示例演练(Select查询数据、Join查询)
文章目录
- 1. Select查询数据
-
- 1.1 基础语法
-
- 1.1.1 select_ecpr
- 1.1.2 ALL、DISTINCT
- 1.1.3 WHERE
- 1.1.4 分区查询、分区裁剪
- 1.1.5 GROUP BY
- 1.1.6 HAVING
- 1.1.7 LIMIT
- 1.1.8 执行顺序
- 1.2 高阶语法
-
- 1.2.1 ORDER BY
- 1.2.2 CLUSTER BY
- 1.2.4 Union联合查询
- 1.2.5 from子查询(Subqueries)
- 1.2.6 where字句子查询(Subqueries)
- 1.2.7 CTE介绍
- 2. Join查询
-
- 2.1 Join语法规则
- 2.2 6种Join方式详解
-
- 2.2.1 inner join 内连接
- 2.2.2 left join 左连接
- 2.2.3 right join 右连接
- 2.2.4 full outer join 全外连接
- 2.2.5 left semi join 左半开连接
- 2.2.6 cross join 交叉连接
- 2.3 Join使用注意事项
1. Select查询数据
语法树
- 从哪里查询取决于FROM关键字后面的table_reference。
- 表名和列名不区分大小写
---------select语法树------------
[WITH CommonTableExpression (, CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows];
1.1 基础语法
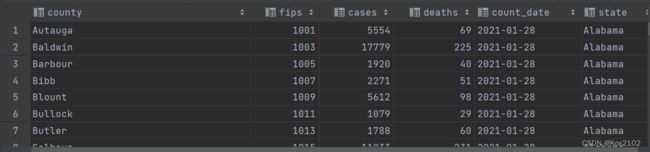
示例数据:
1.1.1 select_ecpr
- select_expr表示检索查询返回的列,必须至少有一个select_expr。
示例:
- 查询所有字段或者指定字段
select * from t_usa_covid19_p;
select county, cases, deaths from t_usa_covid19_p;
- 查询匹配正则表达式的所有字段
SET hive.support.quoted.identifiers = none; --反引号不在解释为其他含义,被解释为正则表达式

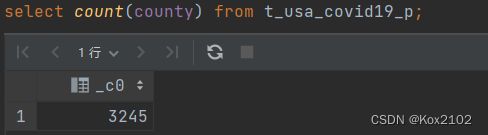
- 查询当前数据库

- 查询使用函数
1.1.2 ALL、DISTINCT
- 用于指定查询返回结果中重复的如何出来
- 如果不指定则默认为ALL(返回所有匹配的行)。
- DISTINCT指定从结果中删除重复的列。
示例:
- 返回所有匹配的行

- 返回所有匹配的行 去除重复的结果
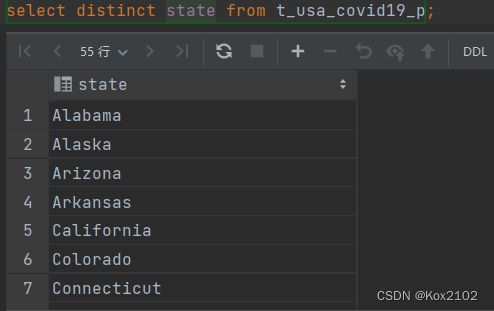
- 多个字段distinct 整体去重

1.1.3 WHERE
- WHERE后面是一个布尔表达式,用于查询过滤。
- 在WHERE表达式中,可以使用Hive支持的任何函数和运算符,但聚合函数除外
示例:
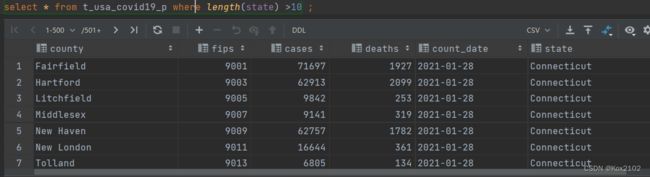
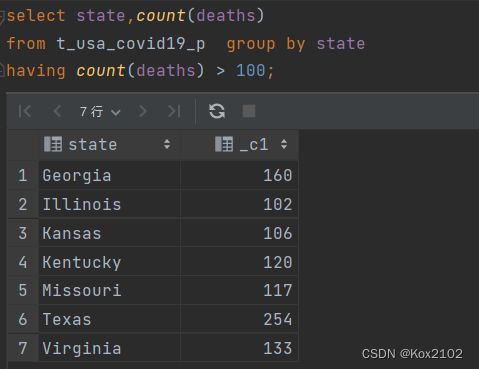
- where条件中使用函数 找出州名字母长度超过10位的有哪些
- 统计死亡人数大于100的州
1.1.4 分区查询、分区裁剪
- 针对Hive分区表,在查询时可以指定分区查询,减少全表扫描,也叫做分区裁剪。
- 所谓分区裁剪指:对分区表进行查询时,会检查WHERE字句或JOIN中的ON字句是否存在对分区字段的过滤,如果存在,则仅访问查询符合条件的分区,即裁剪掉没必要访问的分区。
示例:
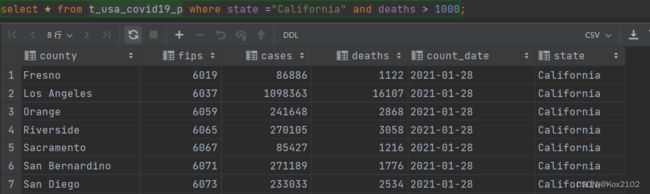
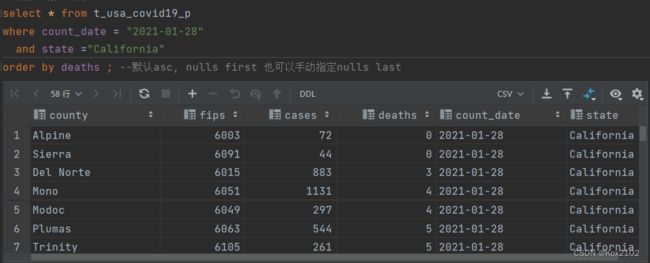
- 找出来自加州,累计死亡人数大于1000的县 state字段就是分区字段 进行分区裁剪 避免全表扫描
--多分区裁剪
select * from t_usa_covid19_p where count_date = "2021-01-28" and state ="California" and deaths > 1000;
1.1.5 GROUP BY
- GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
- 出现在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段。
示例: - 根据state州进行分组

1.1.6 HAVING
- having字句可以筛选分组后的各组数据,且可以使用聚合函数。
示例:
- 统计死亡病例数大于10000的州

HAVING和WHERE区别
- having是在分组后对数据进行过滤
- where是在分组前对数据进行过滤
- having后面可以使用聚合函数
- where后面不可以使用聚合函数
1.1.7 LIMIT
- LIMIT用于限制SELECT语句返回的行数。
- LIMIT接受一个或两个数字参数,这两个参数都必须是非负整数常量。
示例:
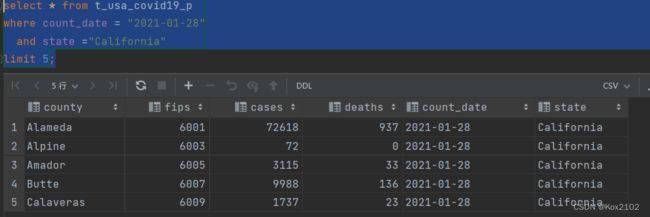
- 返回结果集的前5条
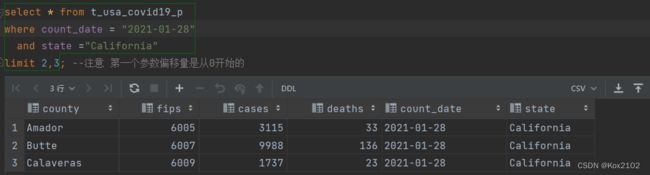
- 返回结果集从第1行开始 共3行
1.1.8 执行顺序
- 在查询过程中执行顺序:from > group(含聚合)> having > order > select ;
- 聚合语句(sum, min, max, avg, count)要比having字句优先执行
- where字句在查询过程中执行优先界别优先于聚合语句(sum, min, max, avg, count)
1.2 高阶语法
1.2.1 ORDER BY
- ORDER BY会对输出的结果进行全局排序
- 默认排序为升序(ASC),也可以指定为DESC降序。
- 在Hive 2.1.0和更高的版本中,支持ORDER BY字句中每个列指定null类型结果排序顺序。ASC顺序的默认空排序顺序为NULLS FIRST,而DESC顺序的默认空排序顺序为NULLS LAST。
示例:
- 根据字段进行排序
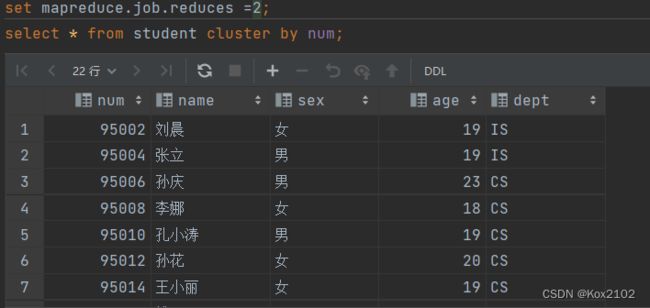
1.2.2 CLUSTER BY
- 根据同一个字段,分且排序。
- 分组规则hash散列(分桶表规则一样):Hash_Func(col_name) % reducetask个数
- 分为几组取决于reducetask的个数
示例:
- 不指定reduce task个数

- 手动设置reduce task个数
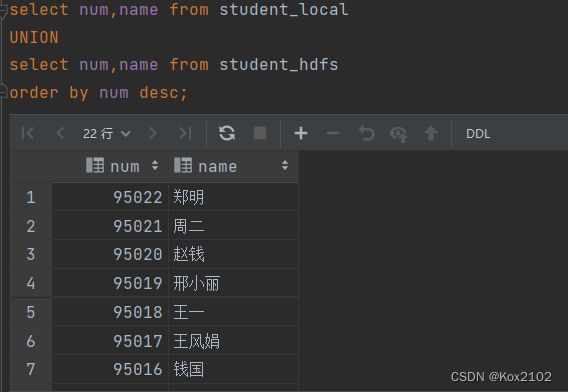
1.2.4 Union联合查询
- UNION用于将多个SELECT语句的结果合并为一个结果集。
- 使用DISTINCT关键字与只使用UNIONO默认值效果一样,都会删除重复行。
- 使用ALL关键字,不会删除重复行,结果集包括所有SELECT语句的匹配行。
- 每个select statement返回的列的数量和名称必须相同。
- 语法规则:
select_statement UNION [ALL | DISTINCT] select_statement UNION [ALL | DISTINCT] select_statement ...;
- 使用DISTINCT关键字与使用UNION默认值效果一样,都会删除重复行。

- 使用ALL关键字会保留重复行。

- 如果要将ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY或LIMIT应用于单个SELECT,请将子句放在括住SELECT的括号内。

- 如果要将ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY或LIMIT子句应用于整个UNION结果,请将ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY或LIMIT放在最后一个之后。
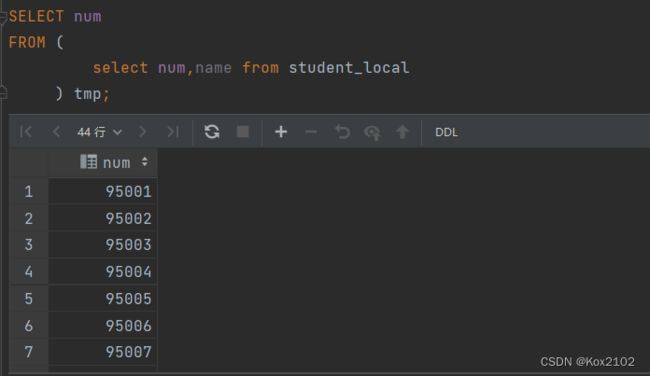
1.2.5 from子查询(Subqueries)
- 在Hive0.12版本,仅在FROM子句中支持子查询。而且必须要给子查询一个名称,因为FROM子句中的每个表都必须有一个名称。
- 子查询返回结果中的列必须具有唯一的名称。子查询返回结果中的列在外部查询中可用,就像真实表的列一样。子查询也可以是带有UNION的查询表达式。
- Hive支持任意级别的子查询,也就是所谓的嵌套子查询。
- Hive 0.13.0和更高版本中的子查询名称之前可以包含可选关键字“ AS” 。
示例:
- 子查询
- 包含UNION ALL的子查询

1.2.6 where字句子查询(Subqueries)
- 从Hive 0.13开始,WHERE字句支持下述类型的子查询:
- 不相关子查询:该子查询不引用父查询中的列,可以将查询结果视为IN和NOT IN语句的常量;
- 相关子查询:子查询引用父查询中的列;


1.2.7 CTE介绍
- 公式表达式CTE是一个临时结果集:该结果集是从WITH字句中指定的简单查询派生而来的,紧接在SELECT或INSERT关键字之前。
- CTE仅在单个语句的执行范围内定义。
- CTE可以在SELCT,INSERT,CREATE TABLE AS SELECT 或 CREATE VIEW AS SELECT语句中使用。
使用:
--select语句中的CTE
with q1 as (select num,name,age from student where num = 95002)
select *
from q1;
-- from风格
with q1 as (select num,name,age from student where num = 95002)
from q1
select *;
-- chaining CTEs 链式
with q1 as ( select * from student where num = 95002),
q2 as ( select num,name,age from q1)
select * from (select num from q2) a;
-- union
with q1 as (select * from student where num = 95002),
q2 as (select * from student where num = 95004)
select * from q1 union all select * from q2;
--视图,CTAS和插入语句中的CTE
-- insert
create table s1 like student;
with q1 as ( select * from student where num = 95002)
from q1
insert overwrite table s1
select *;
select * from s1;
-- ctas
create table s2 as
with q1 as ( select * from student where num = 95002)
select * from q1;
-- view
create view v1 as
with q1 as ( select * from student where num = 95002)
select * from q1;
select * from v1;
2. Join查询
2.1 Join语法规则
- 在Hive中,当下版本3.1.2总共支持6种join语法。分别是:inner join (内连接)、left join (左连接)、right on (右连接)、full outer join (全外连接)、left semi join (左半开连接)、cross join (交叉连接,也叫做笛卡尔乘积)
- table_reference:是join查询种使用的表名,也可也是子查询别名(查询结果当成表参与join)。
- table_factor:与table_reference相同,是联接查询中使用的表名,也可以是子查询别名。
- join_condition:join查询相关联的条件,如果在两个以上的表需要连接,则使用AND关键字。
join_table:
table_reference [INNER] JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)
join_condition:
ON expression
--隐式联接表示法
SELECT *
FROM table1 t1, table2 t2, table3 t3
WHERE t1.id = t2.id AND t2.id = t3.id AND t1.zipcode = '02535';
--支持非等值连接
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
SELECT a.* FROM a LEFT OUTER JOIN b ON (a.id <> b.id)
2.2 6种Join方式详解
2.2.1 inner join 内连接
- 内连接是最常见的一种连接,它也被称为普通连接,其中inner可以省略:inner join == join;
- 只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。

- inner join
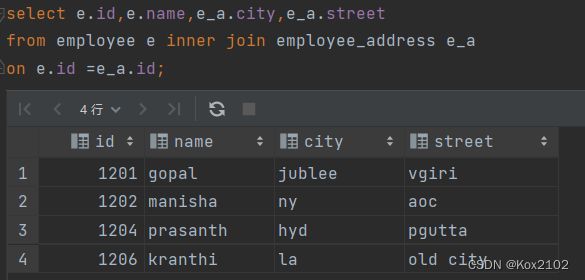
- 等价于 inner join=join

- 等价于 隐式连接表示法
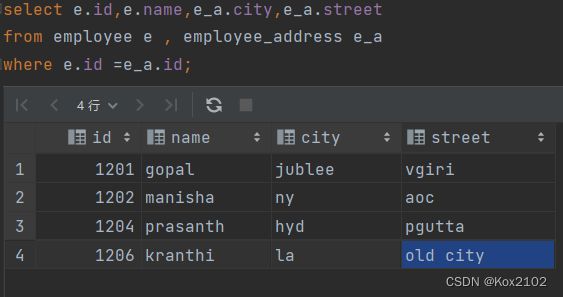
2.2.2 left join 左连接
- join时以左表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关联不上的显示null返回。

- left join

- 等价于 left outer join

2.2.3 right join 右连接
- join时以右表的全部数据为准,左边与之关联;右表数据全部返回,左表关联上的显示返回,关联不上的显示null返回。

- right join

- 等价于 right outer join

2.2.4 full outer join 全外连接
-
对两个数据集合分别进行左外连接和右外连接,然后再使用消去重复行的操作将上述两个结果集合并为一个结果集。
-
full outer join
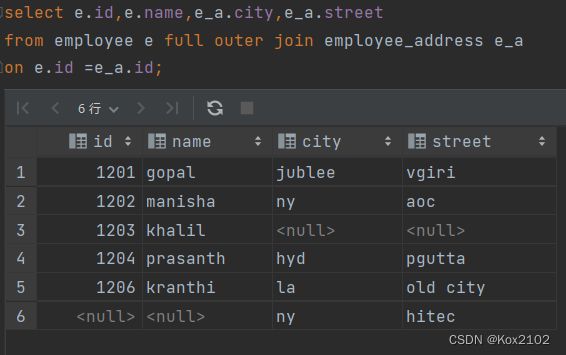
-
等价于

2.2.5 left semi join 左半开连接
- 会返回左边表的记录,前提是其记录对于右边的表满足ON语句中的判断条件。
- left semi join

- 相当于 inner join,但是只返回左表全部数据, 只不过效率高一些

2.2.6 cross join 交叉连接
- 交叉连接,将会返回被连接的两个表的笛卡尔积,返结果的行数等于两个表行数的乘积
- 下列A、B、C 执行结果相同,但是效率不一样:
--A:
select a.*,b.* from employee a,employee_address b where a.id=b.id;
--B:
select * from employee a cross join employee_address b on a.id=b.id;
select * from employee a cross join employee_address b where a.id=b.id;
--C:
select * from employee a inner join employee_address b on a.id=b.id;
- 一般不建议使用方法A和B,因为如果有WHERE子句的话,往往会先生成两个表行数乘积的行的数据表然后才根据WHERE条件从中选择。
- 因此,如果两个需要求交集的表太大,将会非常非常慢,不建议使用。
2.3 Join使用注意事项
- 允许使用复杂的联接表达式,支持非等值连接
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
SELECT a.* FROM a LEFT OUTER JOIN b ON (a.id <> b.id)
- 同一个查询中可以连接2个以上的表
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
- 如果每个表在联接字句使用相同的列,则Hive将多个表上的联接转换为单个MR作业
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
--由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
--会转换为两个MR作业,因为在第一个连接条件中使用了b中的key1列,而在第二个连接条件中使用了b中的key2列。
-- 第一个map / reduce作业将a与b联接在一起,然后将结果与c联接到第二个map / reduce作业中。
- join时的最后一个表会通过reducer流式传输,并在其中缓冲之前的其他表,因此,将大表放置在最后有助于减少reduer阶段缓存数据所需要的内存
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
--由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行,并且表a和b的键的特定值的值被缓冲在reducer的内存中。然后,对于从c中检索的每一行,将使用缓冲的行来计算联接。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
--计算涉及两个MR作业。其中的第一个将a与b连接起来,并缓冲a的值,同时在reducer中流式传输b的值。
-- 在第二个MR作业中,将缓冲第一个连接的结果,同时将c的值通过reducer流式传输。
- 在join的时候,可以通过语法STREAMTABLE提示指定要流式传输的表。如果省略STREAMTABLE提示,则Hive将流式传输最右边的表。
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
--a,b,c三个表都在一个MR作业中联接,并且表b和c的键的特定值的值被缓冲在reducer的内存中。
-- 然后,对于从a中检索到的每一行,将使用缓冲的行来计算联接。如果省略STREAMTABLE提示,则Hive将流式传输最右边的表。
- join在WHERE条件之前进行。
- 如果除一个要连接的表之外的所有表都很小,则可以将其作为仅map作业执行(mapjoin)。
SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key = b.key
--不需要reducer。对于A的每个Mapper,B都会被完全读取。限制是不能执行FULL / RIGHT OUTER JOIN b。