python初体验-高效办公、数据分析、爬虫
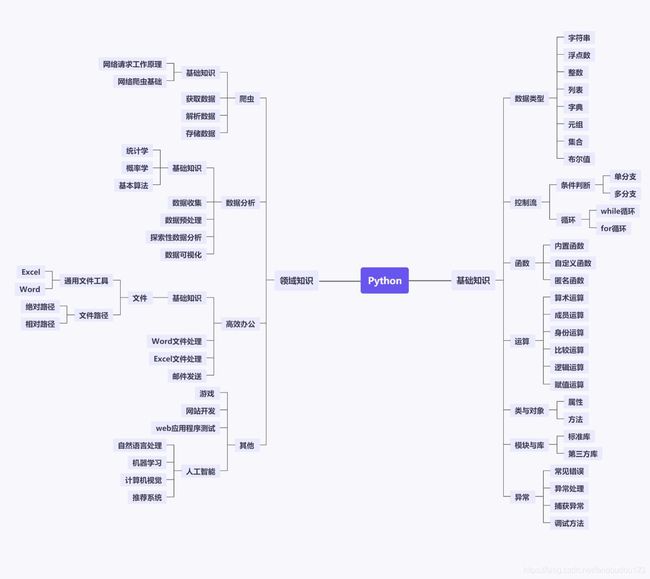
python学习体系
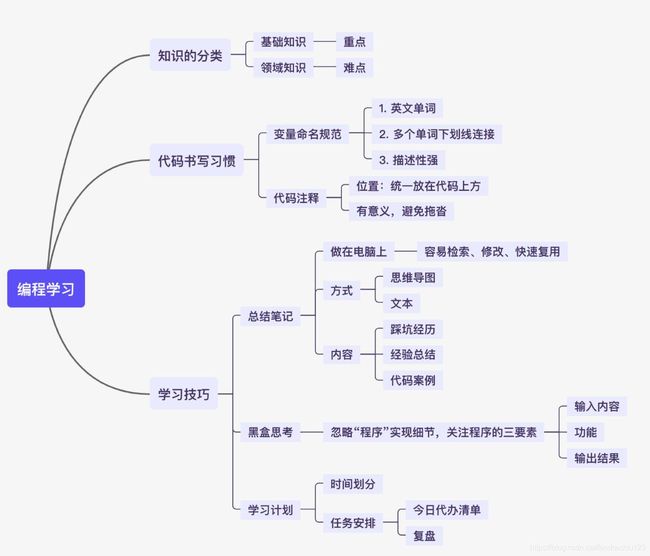
编程学习
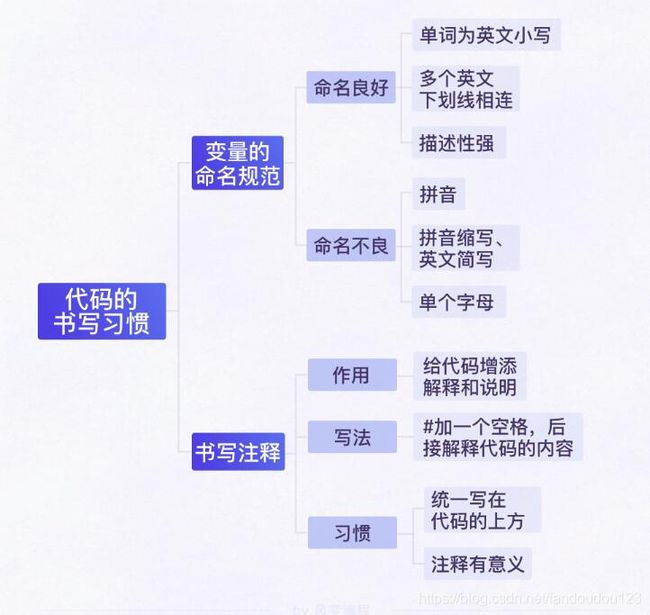
代码的书写习惯
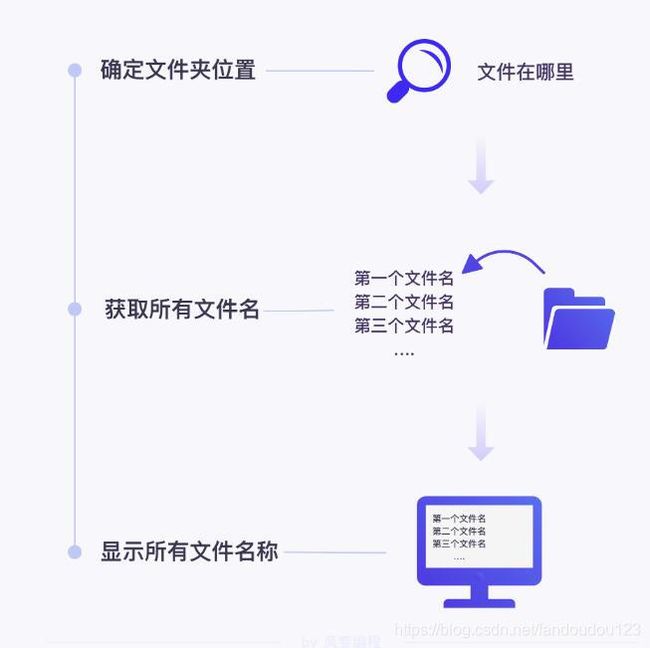
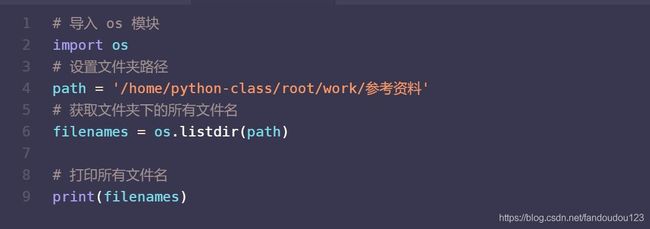
高效办公案例:获取所有文件夹名称
步骤:
代码:
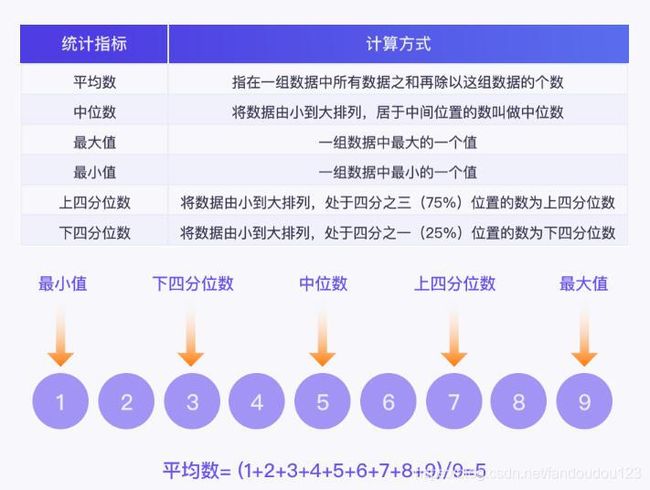
数据分析案例:显示数据分析结果
步骤:


计算方式:
代码:
成绩分析
练习介绍:老王是一名的风变小学五年级二班的班主任,他在学完了今天这一关后想对班上 40 名同学的这次月考成绩和一班成绩做个对比,看看班级里的同学的平均分是比一班高还是比一班低。
题目要求:使用 describe() 将两个班级的成绩表平均值打印出来
import pandas
# 赋值一班成绩表的文件路径
path_1 = 'work/风变小学五年级一班第二次月考成绩单.xlsx'
# 读取一班成绩表数据并存储到变量 grade_1
grade_1 = pandas.read_excel(path_1)
# 计算一班成绩表数据的统计指标
grade_1.describe()# 赋值二班成绩表的文件路径
path_2 ='work/风变小学五年级二班第二次月考成绩单.xlsx'
# 读取二班成绩表数据并存储到变量 grade_2
grade_2 = pandas.read_excel(path_2)
# 计算二班成绩表数据的统计指标
grade_2.describe()爬虫
步骤:【发起网络请求】 -> 【获取网页内容】 -> 【提取网页信息】 -> 【打印提取的信息】。

代码:
爬取博客人人都是蜘蛛侠中,全部文章的开头内容。
提示
1)人人都是蜘蛛侠的网址是:"https://wordpress-edu-3autumn.localprod.oc.forchange.cn/ "
2)我们需要的内容都在
3)我们可以在正则表达式中使用圆括号()来限制提取范围,这样括号外匹配到的字符不会被提取出来。
4)可以参考下课程的代码
# 导入模块与库
import re
import requests
# 发起网络请求
res = requests.get("https://wordpress-edu-3autumn.localprod.oc.forchange.cn/")
# 获取网页内容
page_source = res.text
# 提取网页信息
content = re.findall('(.*)
', page_source)
# 打印内容
print(content)