简单对抗神经网络GAN实现与讲解-图片对抗
1、理论讲解,清晰易懂:
一文看懂「生成对抗网络 - GAN」基本原理+10种典型算法+13种应用 (easyai.tech)
2、代码实现集合:
GitHub - eriklindernoren/Keras-GAN: Keras implementations of Generative Adversarial Networks.
3、这里简单说以下
GNN的通俗理解基于两个对手之间相互博弈,共同进步。类似于:假设一个城市治安混乱,很快,这个城市里就会出现无数的小偷。在这些小偷中,有的可能是盗窃高手,有的可能毫无技术可言。假如这个城市开始整饬其治安,突然开展一场打击犯罪的「运动」,警察们开始恢复城市中的巡逻,很快,一批「学艺不精」的小偷就被捉住了。之所以捉住的是那些没有技术含量的小偷,是因为警察们的技术也不行了,在捉住一批低端小偷后,城市的治安水平变得怎样倒还不好说,但很明显,城市里小偷们的平均水平已经大大提高了。
在图像处理方面可以这么理解:你用真实图片和生成器(Generater)生成的虚假图片共同训练判别器(Discriminator),以致于其能够达到区分真假的功能。生成器(Generater)利用你随机输入的数字生成其对应与真实图片类似的图片,反复训练以至于能够生成越来越逼真的图片。
其图片如下:
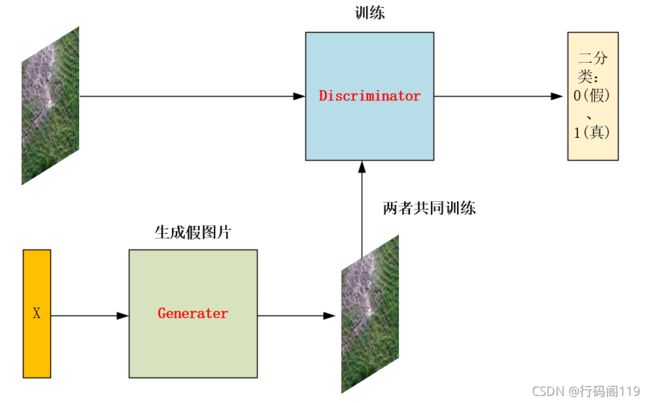
生成图片和训练代码用的是卷积。
4、其损失函数
其实对于两者的损失函数可以分开考虑。对于判别器(Discriminator),就是其真实图片损失函数和制造的假图片损失函数求和。valid、fake对应的是其虚假标签;imgs,gen_imgs分别是真实图片和虚假图片。
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)对于生成器(Generater),其先将判别器(Discriminator)设置为预测状态,然后X将传入生成器(Generater),将生成的虚假图片输入判别器(Discriminator)进行判别,这样就可以达到更新生成器(Generater)的参数。这里0(真)、1(假)主要是当Discriminator识别效果很好,说明Generater需要努力学习,才能继续蒙混过关,所以其损失值大;反之亦然。

其代码实现时将其标签直接传为了1(真实图片):

5、其代码实现:
代码时相对于Mnist实现,通过生成Mnist图像蒙混判别器(Discriminator)。
from __future__ import print_function, division
import tensorflow as tf
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
config = tf.ConfigProto(allow_soft_placement = True)
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = 0.5)
config.gpu_options.allow_growth = True
sess0 = tf.InteractiveSession(config = config)
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import sys
import numpy as np
class GAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
# The generator takes noise as input and generates imgs
z = Input(shape=(self.latent_dim,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The discriminator takes generated images as input and determines validity
validity = self.discriminator(img)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
self.combined = Model(z, validity)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
model = Sequential()
model.add(Dense(256, input_dim=self.latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
model = Sequential()
model.add(Flatten(input_shape=self.img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, sample_interval=50):
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# Rescale -1 to 1
X_train = X_train / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3)
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random batch of images
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Generate a batch of new images
gen_imgs = self.generator.predict(noise)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Train the generator (to have the discriminator label samples as valid)
g_loss = self.combined.train_on_batch(noise, valid)
# Plot the progress
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# If at save interval => save generated image samples
if epoch % sample_interval == 0:
self.sample_images(epoch)
def sample_images(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
if __name__ == '__main__':
gan = GAN()
gan.train(epochs=30000, batch_size=1, sample_interval=200)其结果如下(训练时间不会很久,有兴趣的可以试试):



通过结果可以发现 随着训练步数的增加,生成的图片越来越能以假乱真。