keras example
文章目录
- Activation Function
-
- reuters_mlp_relu_vs_selu.py
- MLP
-
- mnist_mlp.py
- reuters_mlp.py
- CNN
-
- mnist_cnn.py
- AE
-
- mnist_denoising_autoencoder.py
- variational_autoencoder.py
- RNN
-
- imdb_lstm.py
- lstm_seq2seq.py
- cnn_seq2seq.py
- imdb_bidirectional_lstm.py
- GAN
-
- mnist_acgan.py
Activation Function
reuters_mlp_relu_vs_selu.py
'''Compares self-normalizing MLPs with regular MLPs.
Compares the performance of a simple MLP using two
different activation functions: RELU and SELU
on the Reuters newswire topic classification task.
# Reference
- Klambauer, G., Unterthiner, T., Mayr, A., & Hochreiter, S. (2017).
Self-Normalizing Neural Networks. arXiv preprint arXiv:1706.02515.
https://arxiv.org/abs/1706.02515
'''
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout
from keras.layers.noise import AlphaDropout
from keras.preprocessing.text import Tokenizer
max_words = 1000
batch_size = 16
epochs = 40
plot = True
def create_network(n_dense=6,
dense_units=16,
activation='selu',
dropout=AlphaDropout,
dropout_rate=0.1,
kernel_initializer='lecun_normal',
optimizer='adam',
num_classes=1,
max_words=max_words):
"""Generic function to create a fully-connected neural network.
# Arguments
n_dense: int > 0. Number of dense layers.
dense_units: int > 0. Number of dense units per layer.
dropout: keras.layers.Layer. A dropout layer to apply.
dropout_rate: 0 <= float <= 1. The rate of dropout.
kernel_initializer: str. The initializer for the weights.
optimizer: str/keras.optimizers.Optimizer. The optimizer to use.
num_classes: int > 0. The number of classes to predict.
max_words: int > 0. The maximum number of words per data point.
# Returns
A Keras model instance (compiled).
"""
model = Sequential()
model.add(Dense(dense_units, input_shape=(max_words,),
kernel_initializer=kernel_initializer))
model.add(Activation(activation))
model.add(dropout(dropout_rate))
for i in range(n_dense - 1):
model.add(Dense(dense_units, kernel_initializer=kernel_initializer))
model.add(Activation(activation))
model.add(dropout(dropout_rate))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
return model
network1 = {
'n_dense': 6,
'dense_units': 16,
'activation': 'relu',
'dropout': Dropout,
'dropout_rate': 0.5,
'kernel_initializer': 'glorot_uniform',
'optimizer': 'sgd'
}
network2 = {
'n_dense': 6,
'dense_units': 16,
'activation': 'selu',
'dropout': AlphaDropout,
'dropout_rate': 0.1,
'kernel_initializer': 'lecun_normal',
'optimizer': 'sgd'
}
print('Loading data...')
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words,
test_split=0.2)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
num_classes = np.max(y_train) + 1
print(num_classes, 'classes')
print('Vectorizing sequence data...')
tokenizer = Tokenizer(num_words=max_words)
x_train = tokenizer.sequences_to_matrix(x_train, mode='binary')
x_test = tokenizer.sequences_to_matrix(x_test, mode='binary')
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Convert class vector to binary class matrix '
'(for use with categorical_crossentropy)')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)
print('\nBuilding network 1...')
model1 = create_network(num_classes=num_classes, **network1)
history_model1 = model1.fit(x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1)
score_model1 = model1.evaluate(x_test,
y_test,
batch_size=batch_size,
verbose=1)
print('\nBuilding network 2...')
model2 = create_network(num_classes=num_classes, **network2)
history_model2 = model2.fit(x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1)
score_model2 = model2.evaluate(x_test,
y_test,
batch_size=batch_size,
verbose=1)
print('\nNetwork 1 results')
print('Hyperparameters:', network1)
print('Test score:', score_model1[0])
print('Test accuracy:', score_model1[1])
print('Network 2 results')
print('Hyperparameters:', network2)
print('Test score:', score_model2[0])
print('Test accuracy:', score_model2[1])
plt.plot(range(epochs),
history_model1.history['val_loss'],
'g-',
label='Network 1 Val Loss')
plt.plot(range(epochs),
history_model2.history['val_loss'],
'r-',
label='Network 2 Val Loss')
plt.plot(range(epochs),
history_model1.history['loss'],
'g--',
label='Network 1 Loss')
plt.plot(range(epochs),
history_model2.history['loss'],
'r--',
label='Network 2 Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.savefig('comparison_of_networks.png')

Network 1 results
Hyperparameters: {‘n_dense’: 6, ‘dense_units’: 16, ‘activation’: ‘relu’, ‘dropout’:
Test score: 1.9538986459971537
Test accuracy: 0.5213713268297439
Network 2 results
Hyperparameters: {‘n_dense’: 6, ‘dense_units’: 16, ‘activation’: ‘selu’, ‘dropout’:
Test score: 1.5389474697231929
Test accuracy: 0.6714158504007124
MLP
mnist_mlp.py
'''Trains a simple deep NN on the MNIST dataset.
Gets to 98.40% test accuracy after 20 epochs
(there is *a lot* of margin for parameter tuning).
2 seconds per epoch on a K520 GPU.
'''
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
batch_size = 128
num_classes = 10
epochs = 20
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
Test loss: 0.11690922913084084
Test accuracy: 0.9836
reuters_mlp.py
'''Trains and evaluate a simple MLP
on the Reuters newswire topic classification task.
'''
from __future__ import print_function
import numpy as np
import keras
from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.preprocessing.text import Tokenizer
max_words = 1000
batch_size = 32
epochs = 5
print('Loading data...')
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words,
test_split=0.2)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
num_classes = np.max(y_train) + 1
print(num_classes, 'classes')
print('Vectorizing sequence data...')
tokenizer = Tokenizer(num_words=max_words)
x_train = tokenizer.sequences_to_matrix(x_train, mode='binary')
x_test = tokenizer.sequences_to_matrix(x_test, mode='binary')
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Convert class vector to binary class matrix '
'(for use with categorical_crossentropy)')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)
print('Building model...')
model = Sequential()
model.add(Dense(512, input_shape=(max_words,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1)
score = model.evaluate(x_test, y_test,
batch_size=batch_size, verbose=1)
print('Test score:', score[0])
print('Test accuracy:', score[1])
Test score: 0.890080013130779
Test accuracy: 0.7934105075690115
CNN
mnist_cnn.py
'''Trains a simple convnet on the MNIST dataset.
Gets to 99.25% test accuracy after 12 epochs
(there is still a lot of margin for parameter tuning).
16 seconds per epoch on a GRID K520 GPU.
'''
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
K.image_data_format()
Out[2]: 'channels_last'
相当于在tensorflow的4个维度上,分别是[batch, heigh, weight, channel]
与普通RGB格式相似。
x_train.shape
Out[3]: (60000, 28, 28)
需要增加一个轴
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
需要增加一个轴
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
归一化
y_train
Out[4]: array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
需要将label进行dummy化(转one hot)
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
y_train
Out[5]:
array([[0., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.]], dtype=float32)
用keras.utils.to_categorical执行这个操作
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
模型的定义与编译(损失函数,优化器,模型评价)

绘图网站
插播一个代码,我们看看另外一种定义模型的方法:
def get_1Dcnn_charge(self,x:tf.Tensor)->tf.Tensor:
conv=layers.Conv2D(filters=1,kernel_size=(self.window_size_Ele,self.n_subg_euc))(x) # need change window_size
elu=layers.Activation('relu')(conv)
pool=layers.AveragePooling2D(pool_size=(2,1),strides=(1,1),padding='valid')(elu)
self.fc_input_num+=pool.shape[1]
flat=layers.Flatten()(pool)
return flat
def get_model(self):
Feature_tensors=layers.Input(shape=[self.n_bins,self.n_subg,self.n_channel])
FeatureFlat_Euc=layers.Input(shape=[self.n_bins_euc,self.n_subg_euc,1])
FeatureFlat_Ele=layers.Input(shape=[self.n_bins_euc,self.n_subg_euc,1])
self.fc_input_num=0
concat=layers.Concatenate(axis=1)([
self.get_2Dcnn_layer(Feature_tensors),
self.get_1Dcnn_distance(FeatureFlat_Euc),
self.get_1Dcnn_charge(FeatureFlat_Ele),
])
fc1=layers.Dense(units=self.fc_layer1_num,input_dim=self.fc_input_num)(concat)
ac1=layers.Activation('elu')(fc1)
fc2=layers.Dense(units=1,input_dim=self.fc_layer1_num)(ac1) #fc_layer1_num
y=layers.Activation('elu')(fc2)
model=models.Model([Feature_tensors, FeatureFlat_Euc, FeatureFlat_Ele],y)
通过keras函数式编程的方法,构造很多层。最后用models.Model([inputs],ouput)的方法构造一个模型对象。
model.compile(loss='mse',optimizer=optimizer,metrics=[keras_r2])
最后将一些参数编译进模型。
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
最后来看模型的训练与预测,可以看到API与sklearn的及其相似。
在拟合的过程中,可以传入验证集,防止过拟合。
AE
mnist_denoising_autoencoder.py
降噪自编码器
'''Trains a denoising autoencoder on MNIST dataset.
Denoising is one of the classic applications of autoencoders.
The denoising process removes unwanted noise that corrupted the
true signal.
Noise + Data ---> Denoising Autoencoder ---> Data
Given a training dataset of corrupted data as input and
true signal as output, a denoising autoencoder can recover the
hidden structure to generate clean data.
This example has modular design. The encoder, decoder and autoencoder
are 3 models that share weights. For example, after training the
autoencoder, the encoder can be used to generate latent vectors
of input data for low-dim visualization like PCA or TSNE.
'''
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import keras
from keras.layers import Activation, Dense, Input
from keras.layers import Conv2D, Flatten
from keras.layers import Reshape, Conv2DTranspose
from keras.models import Model
from keras import backend as K
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
np.random.seed(1337)
# MNIST dataset
(x_train, _), (x_test, _) = mnist.load_data()
image_size = x_train.shape[1]
x_train = np.reshape(x_train, [-1, image_size, image_size, 1])
x_test = np.reshape(x_test, [-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# Generate corrupted MNIST images by adding noise with normal dist
# centered at 0.5 and std=0.5
noise = np.random.normal(loc=0.5, scale=0.5, size=x_train.shape)
x_train_noisy = x_train + noise
noise = np.random.normal(loc=0.5, scale=0.5, size=x_test.shape)
x_test_noisy = x_test + noise
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
# Network parameters
input_shape = (image_size, image_size, 1)
batch_size = 128
kernel_size = 3
latent_dim = 16
# Encoder/Decoder number of CNN layers and filters per layer
layer_filters = [32, 64]
# Build the Autoencoder Model
# First build the Encoder Model
inputs = Input(shape=input_shape, name='encoder_input')
x = inputs
# Stack of Conv2D blocks
# Notes:
# 1) Use Batch Normalization before ReLU on deep networks
# 2) Use MaxPooling2D as alternative to strides>1
# - faster but not as good as strides>1
for filters in layer_filters:
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=2,
activation='relu',
padding='same')(x)
# Shape info needed to build Decoder Model
shape = K.int_shape(x)
# Generate the latent vector
x = Flatten()(x)
latent = Dense(latent_dim, name='latent_vector')(x)
# Instantiate Encoder Model
encoder = Model(inputs, latent, name='encoder')
encoder.summary()
# Build the Decoder Model
latent_inputs = Input(shape=(latent_dim,), name='decoder_input')
x = Dense(shape[1] * shape[2] * shape[3])(latent_inputs)
x = Reshape((shape[1], shape[2], shape[3]))(x)
# Stack of Transposed Conv2D blocks
# Notes:
# 1) Use Batch Normalization before ReLU on deep networks
# 2) Use UpSampling2D as alternative to strides>1
# - faster but not as good as strides>1
for filters in layer_filters[::-1]:
x = Conv2DTranspose(filters=filters,
kernel_size=kernel_size,
strides=2,
activation='relu',
padding='same')(x)
x = Conv2DTranspose(filters=1,
kernel_size=kernel_size,
padding='same')(x)
outputs = Activation('sigmoid', name='decoder_output')(x)
# Instantiate Decoder Model
decoder = Model(latent_inputs, outputs, name='decoder')
decoder.summary()
# Autoencoder = Encoder + Decoder
# Instantiate Autoencoder Model
autoencoder = Model(inputs, decoder(encoder(inputs)), name='autoencoder')
autoencoder.summary()
autoencoder.compile(loss='mse', optimizer='adam')
# Train the autoencoder
autoencoder.fit(x_train_noisy,
x_train,
validation_data=(x_test_noisy, x_test),
epochs=10,
batch_size=batch_size)
# Predict the Autoencoder output from corrupted test images
x_decoded = autoencoder.predict(x_test_noisy)
# Display the 1st 8 corrupted and denoised images
rows, cols = 10, 30
num = rows * cols
imgs = np.concatenate([x_test[:num], x_test_noisy[:num], x_decoded[:num]])
imgs = imgs.reshape((rows * 3, cols, image_size, image_size))
imgs = np.vstack(np.split(imgs, rows, axis=1))
imgs = imgs.reshape((rows * 3, -1, image_size, image_size))
imgs = np.vstack([np.hstack(i) for i in imgs])
imgs = (imgs * 255).astype(np.uint8)
plt.figure()
plt.axis('off')
plt.title('Original images: top rows, '
'Corrupted Input: middle rows, '
'Denoised Input: third rows')
plt.imshow(imgs, interpolation='none', cmap='gray')
Image.fromarray(imgs).save('corrupted_and_denoised.png')
plt.show()
layer_filters = [32, 64]
feature map: 1 -> 32 -> 64
size: 28 -> 14 -> 7
# Build the Autoencoder Model
# First build the Encoder Model
inputs = Input(shape=input_shape, name='encoder_input')
x = inputs
# Stack of Conv2D blocks
# Notes:
# 1) Use Batch Normalization before ReLU on deep networks
# 2) Use MaxPooling2D as alternative to strides>1
# - faster but not as good as strides>1
for filters in layer_filters:
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=2,
activation='relu',
padding='same')(x)
注意到这里没有用BN
# Generate the latent vector
x = Flatten()(x)
latent = Dense(latent_dim, name='latent_vector')(x)
获取隐变量
# Instantiate Encoder Model
encoder = Model(inputs, latent, name='encoder')
encoder.summary()
encoder模型
# Shape info needed to build Decoder Model
shape = K.int_shape(x)
# Build the Decoder Model
latent_inputs = Input(shape=(latent_dim,), name='decoder_input')
x = Dense(shape[1] * shape[2] * shape[3])(latent_inputs)
x = Reshape((shape[1], shape[2], shape[3]))(x)
K.int_shape(x)
Out[2]: (None, 7, 7, 64)
编码器先把4维张量通过MLP压缩为16维向量,解码再用MLP压缩为原张量size大小的向量,再用reshape还原回来变成张量
for filters in layer_filters[::-1]:
x = Conv2DTranspose(filters=filters,
kernel_size=kernel_size,
strides=2,
activation='relu',
padding='same')(x)
x = Conv2DTranspose(filters=1,
kernel_size=kernel_size,
padding='same')(x) # 注意到最后一步没有用激活函数
7x7x64->14x14x64->28x28x32
28x28x32->28x28x1
outputs = Activation('sigmoid', name='decoder_output')(x)
# Instantiate Decoder Model
decoder = Model(latent_inputs, outputs, name='decoder')
用sigmoid激活最后一层。

sigmoid函数能将输出映射到[0,1]值域范围内,与归一化后的y_true值域相同。
autoencoder = Model(inputs, decoder(encoder(inputs)), name='autoencoder')
autoencoder.summary()
autoencoder.compile(loss='mse', optimizer='adam')
# Train the autoencoder
autoencoder.fit(x_train_noisy,
x_train,
validation_data=(x_test_noisy, x_test),
epochs=10,
batch_size=batch_size)
三个模型共享参数:

程序返回结果:

# encoder 参数
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
encoder_input (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 14, 14, 32) 320
_________________________________________________________________
conv2d_2 (Conv2D) (None, 7, 7, 64) 18496
_________________________________________________________________
flatten_1 (Flatten) (None, 3136) 0
_________________________________________________________________
latent_vector (Dense) (None, 16) 50192
=================================================================
Total params: 69,008
Trainable params: 69,008
Non-trainable params: 0
_________________________________________________________________
我们复习一下参数量的计算
320 = ( 1 × 3 × 3 + 1 ) × ( 32 ) {320}=({1}\times{3}\times{3}+{1})\times(32) 320=(1×3×3+1)×(32)
18496 = ( 32 × 3 × 3 + 1 ) × ( 64 ) {18496}=({32}\times{3}\times{3}+{1})\times(64) 18496=(32×3×3+1)×(64)
史上最全的cnn参数计算详解
# decoder 参数
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
decoder_input (InputLayer) (None, 16) 0
_________________________________________________________________
dense_1 (Dense) (None, 3136) 53312
_________________________________________________________________
reshape_1 (Reshape) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 14, 14, 64) 36928
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 28, 28, 32) 18464
_________________________________________________________________
conv2d_transpose_3 (Conv2DTr (None, 28, 28, 1) 289
_________________________________________________________________
decoder_output (Activation) (None, 28, 28, 1) 0
=================================================================
Total params: 108,993
Trainable params: 108,993
Non-trainable params: 0
_________________________________________________________________
# autoencoder 参数
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
encoder_input (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
encoder (Model) (None, 16) 69008
_________________________________________________________________
decoder (Model) (None, 28, 28, 1) 108993
=================================================================
Total params: 178,001
Trainable params: 178,001
Non-trainable params: 0
_________________________________________________________________
注释中提到:
This example has modular design. The encoder, decoder and autoencoder
are 3 models that share weights. For example, after training the
autoencoder, the encoder can be used to generate latent vectors
of input data for low-dim visualization like PCA or TSNE.
好,我们在训练完成后绘制降维效果。
(x_train, _), (x_test, y_test) = mnist.load_data()
修改源代码,添加y_test方便我们绘图。
随机取100个样本点,对latent和原训练集train_x进行降维。
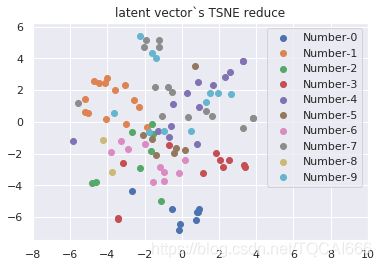
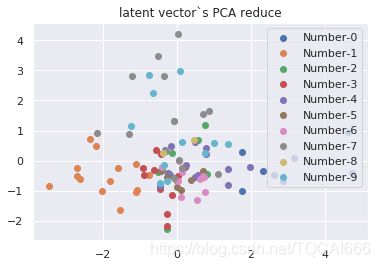
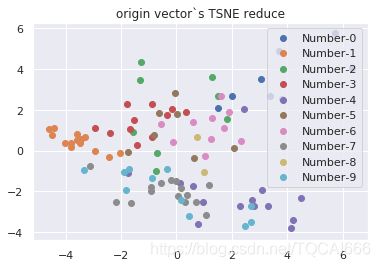

虽然我们从直观上能看到latent向量+TSNE的聚类效果最好,但是计算机可不会看这些。
如果计算机要评价,可以参考聚类算法的评价指标。
variational_autoencoder.py
'''Example of VAE on MNIST dataset using MLP
The VAE has a modular design. The encoder, decoder and VAE
are 3 models that share weights. After training the VAE model,
the encoder can be used to generate latent vectors.
The decoder can be used to generate MNIST digits by sampling the
latent vector from a Gaussian distribution with mean = 0 and std = 1.
# Reference
[1] Kingma, Diederik P., and Max Welling.
"Auto-Encoding Variational Bayes."
https://arxiv.org/abs/1312.6114
'''
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from keras.layers import Lambda, Input, Dense
from keras.models import Model
from keras.datasets import mnist
from keras.losses import mse, binary_crossentropy
from keras.utils import plot_model
from keras import backend as K
import numpy as np
import matplotlib.pyplot as plt
import argparse
import os
# reparameterization trick
# instead of sampling from Q(z|X), sample epsilon = N(0,I)
# z = z_mean + sqrt(var) * epsilon
def sampling(args):
"""Reparameterization trick by sampling from an isotropic unit Gaussian.
# Arguments
args (tensor): mean and log of variance of Q(z|X)
# Returns
z (tensor): sampled latent vector
"""
z_mean, z_log_var = args
batch = K.shape(z_mean)[0]
dim = K.int_shape(z_mean)[1]
# by default, random_normal has mean = 0 and std = 1.0
epsilon = K.random_normal(shape=(batch, dim))
return z_mean + K.exp(0.5 * z_log_var) * epsilon
def plot_results(models,
data,
batch_size=128,
model_name="vae_mnist"):
"""Plots labels and MNIST digits as a function of the 2D latent vector
# Arguments
models (tuple): encoder and decoder models
data (tuple): test data and label
batch_size (int): prediction batch size
model_name (string): which model is using this function
"""
encoder, decoder = models
x_test, y_test = data
os.makedirs(model_name, exist_ok=True)
filename = os.path.join(model_name, "vae_mean.png")
# display a 2D plot of the digit classes in the latent space
z_mean, _, _ = encoder.predict(x_test,
batch_size=batch_size)
plt.figure(figsize=(12, 10))
plt.scatter(z_mean[:, 0], z_mean[:, 1], c=y_test)
plt.colorbar()
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.savefig(filename)
plt.show()
filename = os.path.join(model_name, "digits_over_latent.png")
# display a 30x30 2D manifold of digits
n = 30
digit_size = 28
figure = np.zeros((digit_size * n, digit_size * n))
# linearly spaced coordinates corresponding to the 2D plot
# of digit classes in the latent space
grid_x = np.linspace(-4, 4, n)
grid_y = np.linspace(-4, 4, n)[::-1]
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z_sample = np.array([[xi, yi]])
x_decoded = decoder.predict(z_sample)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
plt.figure(figsize=(10, 10))
start_range = digit_size // 2
end_range = (n - 1) * digit_size + start_range + 1
pixel_range = np.arange(start_range, end_range, digit_size)
sample_range_x = np.round(grid_x, 1)
sample_range_y = np.round(grid_y, 1)
plt.xticks(pixel_range, sample_range_x)
plt.yticks(pixel_range, sample_range_y)
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.imshow(figure, cmap='Greys_r')
plt.savefig(filename)
plt.show()
# MNIST dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
image_size = x_train.shape[1]
original_dim = image_size * image_size
x_train = np.reshape(x_train, [-1, original_dim])
x_test = np.reshape(x_test, [-1, original_dim])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# network parameters
input_shape = (original_dim, )
intermediate_dim = 512
batch_size = 128
latent_dim = 2 # 隐变量直接设为2,方便初始化
epochs = 10
# VAE model = encoder + decoder
# build encoder model
inputs = Input(shape=input_shape, name='encoder_input')
x = Dense(intermediate_dim, activation='relu')(inputs)
z_mean = Dense(latent_dim, name='z_mean')(x)
z_log_var = Dense(latent_dim, name='z_log_var')(x)
# use reparameterization trick to push the sampling out as input
# note that "output_shape" isn't necessary with the TensorFlow backend
z = Lambda(sampling, output_shape=(latent_dim,), name='z')([z_mean, z_log_var])
# instantiate encoder model
encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder')
encoder.summary()
plot_model(encoder, to_file='vae_mlp_encoder.png', show_shapes=True)
# build decoder model
latent_inputs = Input(shape=(latent_dim,), name='z_sampling')
x = Dense(intermediate_dim, activation='relu')(latent_inputs)
outputs = Dense(original_dim, activation='sigmoid')(x)
# instantiate decoder model
decoder = Model(latent_inputs, outputs, name='decoder')
decoder.summary()
plot_model(decoder, to_file='vae_mlp_decoder.png', show_shapes=True)
# instantiate VAE model
outputs = decoder(encoder(inputs)[2])
vae = Model(inputs, outputs, name='vae_mlp')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
help_ = "Load h5 model trained weights"
parser.add_argument("-w", "--weights", help=help_)
help_ = "Use mse loss instead of binary cross entropy (default)"
parser.add_argument("-m",
"--mse",
help=help_, action='store_true')
args = parser.parse_args()
models = (encoder, decoder)
data = (x_test, y_test)
# VAE loss = mse_loss or xent_loss + kl_loss
if args.mse:
reconstruction_loss = mse(inputs, outputs) # 不是output和y_true
else:
reconstruction_loss = binary_crossentropy(inputs,
outputs)
reconstruction_loss *= original_dim
kl_loss = 1 + z_log_var - K.square(z_mean) - K.exp(z_log_var)
kl_loss = K.sum(kl_loss, axis=-1)
kl_loss *= -0.5
vae_loss = K.mean(reconstruction_loss + kl_loss)
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')
vae.summary()
plot_model(vae,
to_file='vae_mlp.png',
show_shapes=True)
if args.weights:
vae.load_weights(args.weights)
else:
# train the autoencoder
vae.fit(x_train,
epochs=epochs,
batch_size=batch_size,
validation_data=(x_test, None))
vae.save_weights('vae_mlp_mnist.h5')
plot_results(models,
data,
batch_size=batch_size,
model_name="vae_mlp")
VAE KL-loss推导

 ##
##
RNN
RNN教程
imdb_lstm.py
'''
#Trains an LSTM model on the IMDB sentiment classification task.
The dataset is actually too small for LSTM to be of any advantage
compared to simpler, much faster methods such as TF-IDF + LogReg.
**Notes**
- RNNs are tricky. Choice of batch size is important,
choice of loss and optimizer is critical, etc.
Some configurations won't converge.
- LSTM loss decrease patterns during training can be quite different
from what you see with CNNs/MLPs/etc.
'''
from __future__ import print_function
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdb
max_features = 20000
# cut texts after this number of words (among top max_features most common words)
maxlen = 80
batch_size = 32
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Build model...')
model = Sequential()
model.add(Embedding(max_features, 128))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
# try using different optimizers and different optimizer configs
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=1,
validation_data=(x_test, y_test))
score, acc = model.evaluate(x_test, y_test,
batch_size=batch_size)
print('Test score:', score)
print('Test accuracy:', acc)
理解LSTM
Test score: 0.38406453870773316
Test accuracy: 0.83056
lstm_seq2seq.py
'''
#Sequence to sequence example in Keras (character-level).
This script demonstrates how to implement a basic character-level
sequence-to-sequence model. We apply it to translating
short English sentences into short French sentences,
character-by-character. Note that it is fairly unusual to
do character-level machine translation, as word-level
models are more common in this domain.
**Summary of the algorithm**
- We start with input sequences from a domain (e.g. English sentences)
and corresponding target sequences from another domain
(e.g. French sentences).
- An encoder LSTM turns input sequences to 2 state vectors
(we keep the last LSTM state and discard the outputs).
- A decoder LSTM is trained to turn the target sequences into
the same sequence but offset by one timestep in the future,
a training process called "teacher forcing" in this context.
It uses as initial state the state vectors from the encoder.
Effectively, the decoder learns to generate `targets[t+1...]`
given `targets[...t]`, conditioned on the input sequence.
- In inference mode, when we want to decode unknown input sequences, we:
- Encode the input sequence into state vectors
- Start with a target sequence of size 1
(just the start-of-sequence character)
- Feed the state vectors and 1-char target sequence
to the decoder to produce predictions for the next character
- Sample the next character using these predictions
(we simply use argmax).
- Append the sampled character to the target sequence
- Repeat until we generate the end-of-sequence character or we
hit the character limit.
**Data download**
[English to French sentence pairs.
](http://www.manythings.org/anki/fra-eng.zip)
[Lots of neat sentence pairs datasets.
](http://www.manythings.org/anki/)
**References**
- [Sequence to Sequence Learning with Neural Networks
](https://arxiv.org/abs/1409.3215)
- [Learning Phrase Representations using
RNN Encoder-Decoder for Statistical Machine Translation
](https://arxiv.org/abs/1406.1078)
'''
from __future__ import print_function
from keras.models import Model
from keras.layers import Input, LSTM, Dense
import numpy as np
batch_size = 64 # Batch size for training.
epochs = 100 # Number of epochs to train for.
latent_dim = 256 # Latent dimensionality of the encoding space.
num_samples = 10000 # Number of samples to train on.
# Path to the data txt file on disk.
data_path = 'fra-eng/fra.txt'
# Vectorize the data.
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
for line in lines[: min(num_samples, len(lines) - 1)]:
input_text, target_text, _ = line.split('\t')
# We use "tab" as the "start sequence" character
# for the targets, and "\n" as "end sequence" character.
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
input_token_index = dict(
[(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict(
[(char, i) for i, char in enumerate(target_characters)])
# 三维数组: 样本数 x 序列长度 x token长度 (token采取one hot编码)
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
# decoder_input_data == decoder_target_data
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
# 这句话意思是填充后面的字符为空格
encoder_input_data[i, t + 1:, input_token_index[' ']] = 1.
# decoder 的output相比较于input,少了头和尾
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
decoder_input_data[i, t + 1:, target_token_index[' ']] = 1.
decoder_target_data[i, t:, target_token_index[' ']] = 1.
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs) # todo : 弄明白encoder_outputs是什么
# We discard `encoder_outputs` and only keep the states.
encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states) # 相当于把encoder与decoder连接起来了
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# Run training
model.compile(optimizer='rmsprop', loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
# Save model
model.save('s2s.h5')
# Next: inference mode (sampling).
# Here's the drill:
# 1) encode input and retrieve initial decoder state
# 2) run one step of decoder with this initial state
# and a "start of sequence" token as target.
# Output will be the next target token
# 3) Repeat with the current target token and current states
# Define sampling models
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# Reverse-lookup token index to decode sequences back to
# something readable.
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())
def decode_sequence(input_seq):
# Encode the input as state vectors.
states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first character of target sequence with the start character.
target_seq[0, 0, target_token_index['\t']] = 1.
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Exit condition: either hit max length
# or find stop character.
if (sampled_char == '\n' or
len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# Update the target sequence (of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update states
states_value = [h, c]
return decoded_sentence
for seq_index in range(100):
# Take one sequence (part of the training set)
# for trying out decoding.
input_seq = encoder_input_data[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:', input_texts[seq_index])
print('Decoded sentence:', decoded_sentence)
cnn_seq2seq.py
'''# Sequence-to-sequence example in Keras (character-level).
This script demonstrates how to implement a basic character-level CNN
sequence-to-sequence model. We apply it to translating
short English sentences into short French sentences,
character-by-character. Note that it is fairly unusual to
do character-level machine translation, as word-level
models are much more common in this domain. This example
is for demonstration purposes only.
**Summary of the algorithm**
- We start with input sequences from a domain (e.g. English sentences)
and corresponding target sequences from another domain
(e.g. French sentences).
- An encoder CNN encodes the input character sequence.
- A decoder CNN is trained to turn the target sequences into
the same sequence but offset by one timestep in the future,
a training process called "teacher forcing" in this context.
It uses the output from the encoder.
Effectively, the decoder learns to generate `targets[t+1...]`
given `targets[...t]`, conditioned on the input sequence.
- In inference mode, when we want to decode unknown input sequences, we:
- Encode the input sequence.
- Start with a target sequence of size 1
(just the start-of-sequence character)
- Feed the input sequence and 1-char target sequence
to the decoder to produce predictions for the next character
- Sample the next character using these predictions
(we simply use argmax).
- Append the sampled character to the target sequence
- Repeat until we hit the character limit.
**Data download**
[English to French sentence pairs.
](http://www.manythings.org/anki/fra-eng.zip)
[Lots of neat sentence pairs datasets.
](http://www.manythings.org/anki/)
**References**
- lstm_seq2seq.py
- https://wanasit.github.io/attention-based-sequence-to-sequence-in-keras.html
'''
from __future__ import print_function
import numpy as np
from keras.layers import Input, Convolution1D, Dot, Dense, Activation, Concatenate
from keras.models import Model
batch_size = 64 # Batch size for training.
epochs = 100 # Number of epochs to train for.
num_samples = 10000 # Number of samples to train on.
# Path to the data txt file on disk.
data_path = 'fra-eng/fra.txt'
# Vectorize the data.
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
for line in lines[: min(num_samples, len(lines) - 1)]:
input_text, target_text = line.split('\t')
# We use "tab" as the "start sequence" character
# for the targets, and "\n" as "end sequence" character.
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
input_token_index = dict(
[(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict(
[(char, i) for i, char in enumerate(target_characters)])
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None, num_encoder_tokens))
# Encoder
x_encoder = Convolution1D(256, kernel_size=3, activation='relu',
padding='causal')(encoder_inputs)
x_encoder = Convolution1D(256, kernel_size=3, activation='relu',
padding='causal', dilation_rate=2)(x_encoder)
x_encoder = Convolution1D(256, kernel_size=3, activation='relu',
padding='causal', dilation_rate=4)(x_encoder)
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# Decoder
x_decoder = Convolution1D(256, kernel_size=3, activation='relu',
padding='causal')(decoder_inputs)
x_decoder = Convolution1D(256, kernel_size=3, activation='relu',
padding='causal', dilation_rate=2)(x_decoder)
x_decoder = Convolution1D(256, kernel_size=3, activation='relu',
padding='causal', dilation_rate=4)(x_decoder)
# Attention
attention = Dot(axes=[2, 2])([x_decoder, x_encoder])
attention = Activation('softmax')(attention)
context = Dot(axes=[2, 1])([attention, x_encoder])
decoder_combined_context = Concatenate(axis=-1)([context, x_decoder])
decoder_outputs = Convolution1D(64, kernel_size=3, activation='relu',
padding='causal')(decoder_combined_context)
decoder_outputs = Convolution1D(64, kernel_size=3, activation='relu',
padding='causal')(decoder_outputs)
# Output
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.summary()
# Run training
model.compile(optimizer='adam', loss='categorical_crossentropy')
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
# Save model
model.save('cnn_s2s.h5')
# Next: inference mode (sampling).
# Define sampling models
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())
nb_examples = 100
in_encoder = encoder_input_data[:nb_examples]
in_decoder = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
in_decoder[:, 0, target_token_index["\t"]] = 1
predict = np.zeros(
(len(input_texts), max_decoder_seq_length),
dtype='float32')
for i in range(max_decoder_seq_length - 1):
predict = model.predict([in_encoder, in_decoder])
predict = predict.argmax(axis=-1)
predict_ = predict[:, i].ravel().tolist()
for j, x in enumerate(predict_):
in_decoder[j, i + 1, x] = 1
for seq_index in range(nb_examples):
# Take one sequence (part of the training set)
# for trying out decoding.
output_seq = predict[seq_index, :].ravel().tolist()
decoded = []
for x in output_seq:
if reverse_target_char_index[x] == "\n":
break
else:
decoded.append(reverse_target_char_index[x])
decoded_sentence = "".join(decoded)
print('-')
print('Input sentence:', input_texts[seq_index])
print('Decoded sentence:', decoded_sentence)
imdb_bidirectional_lstm.py
'''
#Trains a Bidirectional LSTM on the IMDB sentiment classification task.
Output after 4 epochs on CPU: ~0.8146
Time per epoch on CPU (Core i7): ~150s.
'''
from __future__ import print_function
import numpy as np
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Dropout, Embedding, LSTM, Bidirectional
from keras.datasets import imdb
max_features = 20000
# cut texts after this number of words
# (among top max_features most common words)
maxlen = 100
batch_size = 32
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
y_train = np.array(y_train)
y_test = np.array(y_test)
model = Sequential()
model.add(Embedding(max_features, 128, input_length=maxlen))
model.add(Bidirectional(LSTM(64)))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
# try using different optimizers and different optimizer configs
model.compile('adam', 'binary_crossentropy', metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=1,
validation_data=[x_test, y_test])
GAN
mnist_acgan.py
# -*- coding: utf-8 -*-
"""
#Train an Auxiliary Classifier GAN (ACGAN) on the MNIST dataset.
[More details on Auxiliary Classifier GANs.](https://arxiv.org/abs/1610.09585)
You should start to see reasonable images after ~5 epochs, and good images
by ~15 epochs. You should use a GPU, as the convolution-heavy operations are
very slow on the CPU. Prefer the TensorFlow backend if you plan on iterating,
as the compilation time can be a blocker using Theano.
Timings:
Hardware | Backend | Time / Epoch
:------------------|:--------|------------:
CPU | TF | 3 hrs
Titan X (maxwell) | TF | 4 min
Titan X (maxwell) | TH | 7 min
Consult [Auxiliary Classifier Generative Adversarial Networks in Keras
](https://github.com/lukedeo/keras-acgan) for more information and example output.
"""
from __future__ import print_function
from collections import defaultdict
try:
import cPickle as pickle
except ImportError:
import pickle
from PIL import Image
from six.moves import range
from keras.datasets import mnist
from keras import layers
from keras.layers import Input, Dense, Reshape, Flatten, Embedding, Dropout
from keras.layers import BatchNormalization
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv2DTranspose, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
from keras.utils.generic_utils import Progbar
import numpy as np
np.random.seed(1337)
num_classes = 10
def build_generator(latent_size):
# we will map a pair of (z, L), where z is a latent vector and L is a
# label drawn from P_c, to image space (..., 28, 28, 1)
cnn = Sequential()
cnn.add(Dense(3 * 3 * 384, input_dim=latent_size, activation='relu'))
cnn.add(Reshape((3, 3, 384)))
# upsample to (7, 7, ...)
cnn.add(Conv2DTranspose(192, 5, strides=1, padding='valid',
activation='relu',
kernel_initializer='glorot_normal'))
cnn.add(BatchNormalization())
# upsample to (14, 14, ...)
cnn.add(Conv2DTranspose(96, 5, strides=2, padding='same',
activation='relu',
kernel_initializer='glorot_normal'))
cnn.add(BatchNormalization())
# upsample to (28, 28, ...)
cnn.add(Conv2DTranspose(1, 5, strides=2, padding='same',
activation='tanh',
kernel_initializer='glorot_normal'))
# this is the z space commonly referred to in GAN papers
latent = Input(shape=(latent_size,))
# TensorShape([Dimension(None), Dimension(100)])
# this will be our label
image_class = Input(shape=(1,), dtype='int32')
# TensorShape([Dimension(None), Dimension(1)])
cls = Embedding(num_classes, latent_size,
embeddings_initializer='glorot_normal')(image_class)
# TensorShape([Dimension(None), Dimension(1), Dimension(100)])
# hadamard product between z-space and a class conditional embedding
h = layers.multiply([latent, cls])
# TensorShape([Dimension(None), Dimension(1), Dimension(100)])
fake_image = cnn(h)
# TensorShape([Dimension(None), Dimension(None), Dimension(None), Dimension(1)])
return Model([latent, image_class], fake_image)
def build_discriminator():
# build a relatively standard conv net, with LeakyReLUs as suggested in
# the reference paper
cnn = Sequential()
cnn.add(Conv2D(32, 3, padding='same', strides=2,
input_shape=(28, 28, 1)))
cnn.add(LeakyReLU(0.2))
cnn.add(Dropout(0.3))
cnn.add(Conv2D(64, 3, padding='same', strides=1))
cnn.add(LeakyReLU(0.2))
cnn.add(Dropout(0.3))
cnn.add(Conv2D(128, 3, padding='same', strides=2))
cnn.add(LeakyReLU(0.2))
cnn.add(Dropout(0.3))
cnn.add(Conv2D(256, 3, padding='same', strides=1))
cnn.add(LeakyReLU(0.2))
cnn.add(Dropout(0.3))
cnn.add(Flatten())
image = Input(shape=(28, 28, 1))
features = cnn(image)
# first output (name=generation) is whether or not the discriminator
# thinks the image that is being shown is fake, and the second output
# (name=auxiliary) is the class that the discriminator thinks the image
# belongs to.
fake = Dense(1, activation='sigmoid', name='generation')(features)
aux = Dense(num_classes, activation='softmax', name='auxiliary')(features)
return Model(image, [fake, aux])
if __name__ == '__main__':
# batch and latent size taken from the paper
epochs = 100
batch_size = 100
latent_size = 100
# Adam parameters suggested in https://arxiv.org/abs/1511.06434
adam_lr = 0.0002
adam_beta_1 = 0.5
# build the discriminator
print('Discriminator model:')
discriminator = build_discriminator()
discriminator.compile(
optimizer=Adam(lr=adam_lr, beta_1=adam_beta_1),
loss=['binary_crossentropy', 'sparse_categorical_crossentropy']
)
discriminator.summary()
# build the generator
generator = build_generator(latent_size)
latent = Input(shape=(latent_size,))
image_class = Input(shape=(1,), dtype='int32')
# get a fake image
fake = generator([latent, image_class])
# we only want to be able to train generation for the combined model
discriminator.trainable = False
fake, aux = discriminator(fake)
combined = Model([latent, image_class], [fake, aux])
print('Combined model:')
combined.compile(
optimizer=Adam(lr=adam_lr, beta_1=adam_beta_1),
loss=['binary_crossentropy', 'sparse_categorical_crossentropy']
)
combined.summary()
# get our mnist data, and force it to be of shape (..., 28, 28, 1) with
# range [-1, 1]
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 不做归一化,仅仅做个去均值化
x_train = (x_train.astype(np.float32) - 127.5) / 127.5
x_train = np.expand_dims(x_train, axis=-1)
x_test = (x_test.astype(np.float32) - 127.5) / 127.5
x_test = np.expand_dims(x_test, axis=-1)
num_train, num_test = x_train.shape[0], x_test.shape[0]
train_history = defaultdict(list)
test_history = defaultdict(list)
for epoch in range(1, epochs + 1):
print('Epoch {}/{}'.format(epoch, epochs))
# 向下取整
num_batches = int(np.ceil(x_train.shape[0] / float(batch_size)))
progress_bar = Progbar(target=num_batches)
epoch_gen_loss = []
epoch_disc_loss = []
for index in range(num_batches):
# get a batch of real images
image_batch = x_train[index * batch_size:(index + 1) * batch_size]
label_batch = y_train[index * batch_size:(index + 1) * batch_size]
# generate a new batch of noise
noise = np.random.uniform(-1, 1, (len(image_batch), latent_size)) # 生成隐变量的噪声,[-1,1] 平均分布
# sample some labels from p_c
sampled_labels = np.random.randint(0, num_classes, len(image_batch))
# generate a batch of fake images, using the generated labels as a
# conditioner. We reshape the sampled labels to be
# (len(image_batch), 1) so that we can feed them into the embedding
# layer as a length one sequence
generated_images = generator.predict(
[noise, sampled_labels.reshape((-1, 1))], verbose=0)
x = np.concatenate((image_batch, generated_images))
# use one-sided soft real/fake labels
# Salimans et al., 2016
# https://arxiv.org/pdf/1606.03498.pdf (Section 3.4)
soft_zero, soft_one = 0, 0.95
y = np.array(
[soft_one] * len(image_batch) + [soft_zero] * len(image_batch))
aux_y = np.concatenate((label_batch, sampled_labels), axis=0)
# we don't want the discriminator to also maximize the classification
# accuracy of the auxiliary classifier on generated images, so we
# don't train discriminator to produce class labels for generated
# images (see https://openreview.net/forum?id=rJXTf9Bxg).
# To preserve sum of sample weights for the auxiliary classifier,
# we assign sample weight of 2 to the real images.
disc_sample_weight = [
np.ones(2 * len(image_batch)),
np.concatenate(
(np.ones(len(image_batch)) * 2,
np.zeros(len(image_batch)))
)
]
# [
# [1,1,1,1] ,
# [2,2,0,0] # 训练分类器的时候,对于假的图片我们根本就不想训练
# ]
# see if the discriminator can figure itself out...
epoch_disc_loss.append(discriminator.train_on_batch(
x, [y, aux_y], sample_weight=disc_sample_weight))
# make new noise. we generate 2 * batch size here such that we have
# the generator optimize over an identical number of images as the
# discriminator
noise = np.random.uniform(-1, 1, (2 * len(image_batch), latent_size))
sampled_labels = np.random.randint(0, num_classes, 2 * len(image_batch))
# we want to train the generator to trick the discriminator
# For the generator, we want all the {fake, not-fake} labels to say
# not-fake
trick = np.ones(2 * len(image_batch)) * soft_one
epoch_gen_loss.append(
combined.train_on_batch(
[noise, sampled_labels.reshape((-1, 1))],
[trick, sampled_labels]
)
)
progress_bar.update(index + 1)
print('Testing for epoch {}:'.format(epoch))
# evaluate the testing loss here
# generate a new batch of noise
noise = np.random.uniform(-1, 1, (num_test, latent_size))
# sample some labels from p_c and generate images from them
sampled_labels = np.random.randint(0, num_classes, num_test)
generated_images = generator.predict(
[noise, sampled_labels.reshape((-1, 1))], verbose=False)
x = np.concatenate((x_test, generated_images))
y = np.array([1] * num_test + [0] * num_test)
aux_y = np.concatenate((y_test, sampled_labels), axis=0)
# see if the discriminator can figure itself out...
discriminator_test_loss = discriminator.evaluate(
x, [y, aux_y], verbose=False)
discriminator_train_loss = np.mean(np.array(epoch_disc_loss), axis=0)
# make new noise
noise = np.random.uniform(-1, 1, (2 * num_test, latent_size))
sampled_labels = np.random.randint(0, num_classes, 2 * num_test)
trick = np.ones(2 * num_test)
generator_test_loss = combined.evaluate(
[noise, sampled_labels.reshape((-1, 1))],
[trick, sampled_labels], verbose=False)
generator_train_loss = np.mean(np.array(epoch_gen_loss), axis=0)
# generate an epoch report on performance
train_history['generator'].append(generator_train_loss)
train_history['discriminator'].append(discriminator_train_loss)
test_history['generator'].append(generator_test_loss)
test_history['discriminator'].append(discriminator_test_loss)
print('{0:<22s} | {1:4s} | {2:15s} | {3:5s}'.format(
'component', *discriminator.metrics_names))
print('-' * 65)
ROW_FMT = '{0:<22s} | {1:<4.2f} | {2:<15.4f} | {3:<5.4f}'
print(ROW_FMT.format('generator (train)',
*train_history['generator'][-1]))
print(ROW_FMT.format('generator (test)',
*test_history['generator'][-1]))
print(ROW_FMT.format('discriminator (train)',
*train_history['discriminator'][-1]))
print(ROW_FMT.format('discriminator (test)',
*test_history['discriminator'][-1]))
# save weights every epoch
generator.save_weights(
'params_generator_epoch_{0:03d}.hdf5'.format(epoch), True)
discriminator.save_weights(
'params_discriminator_epoch_{0:03d}.hdf5'.format(epoch), True)
# generate some digits to display
num_rows = 40
noise = np.tile(np.random.uniform(-1, 1, (num_rows, latent_size)),
(num_classes, 1))
sampled_labels = np.array([
[i] * num_rows for i in range(num_classes)
]).reshape(-1, 1)
# get a batch to display
generated_images = generator.predict(
[noise, sampled_labels], verbose=0)
# prepare real images sorted by class label
real_labels = y_train[(epoch - 1) * num_rows * num_classes:
epoch * num_rows * num_classes]
indices = np.argsort(real_labels, axis=0)
real_images = x_train[(epoch - 1) * num_rows * num_classes:
epoch * num_rows * num_classes][indices]
# display generated images, white separator, real images
img = np.concatenate(
(generated_images,
np.repeat(np.ones_like(x_train[:1]), num_rows, axis=0),
real_images))
# arrange them into a grid
img = (np.concatenate([r.reshape(-1, 28)
for r in np.split(img, 2 * num_classes + 1)
], axis=-1) * 127.5 + 127.5).astype(np.uint8)
Image.fromarray(img).save(
'plot_epoch_{0:03d}_generated.png'.format(epoch))
with open('acgan-history.pkl', 'wb') as f:
pickle.dump({'train': train_history, 'test': test_history}, f)
| component | loss | generation_loss | auxiliary_loss |
|---|---|---|---|
| generator (train) | 0.76 | 0.7600 | 0.0005 |
| generator (test) | 0.82 | 0.8248 | 0.0000 |
| discriminator (train) | 0.71 | 0.6935 | 0.0143 |
| discriminator (test) | 0.71 | 0.6992 | 0.0108 |

