全志V853 NPU 转换部署 YOLO V5 模型
NPU 转换部署 YOLO V5 模型
本文以 YOLO v5s 模型为例,详述 ONNX 模型在 V853 平台的转换与部署的流程。
模型的准备
YOLO v5 目前开源于 Github,链接【GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite】
我们可以在 Release 页面找到预先训练好的各式各样的开源 YOLO V5 模型

我们选择 v6.0 版本的 yolov5s.onnx 模型作为示例,下载下来。
可以用开源的 Netron 工具打开模型查看模型的结构

模型预处理
由于下载的模型是动态 Shape 的,不限制输入图片的大小,对于 NPU 来说会增加处理工序,所以这里我们需要转换为静态 Shape 的模型。可以先安装 onnxsim 工具,然后使用这条命令转换:
python -m onnxsim yolov5s.onnx yolov5s-sim.onnx --input-shape 1,3,640,640
这里我们将输入固定为了 [1, 3, 640, 640] ,减少了 NPU 的预处理量。转换后的模型可以用 Netron 查看变化
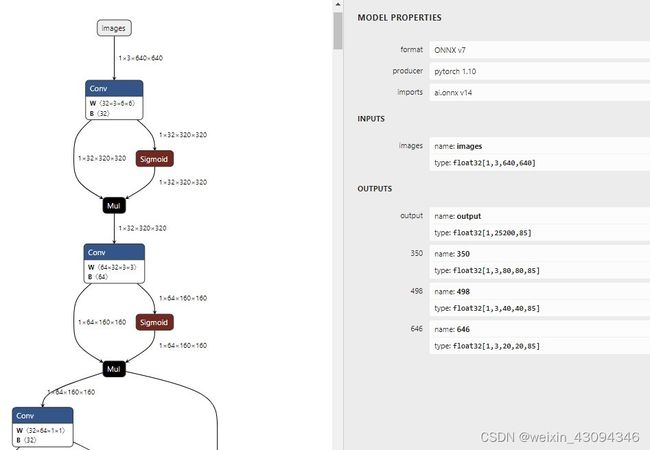
可以看到,输入已经被固定了。
检查预处理情况
转换后的模型不一定可以用,需要验证一下。这里就使用 YOLOv5 源码提供的 detect.py 测试转换后的 onnx 模型
python detect.py --weights ./yolov5s-sim.onnx --source ./dog.jpg --conf-thres 0.5
可以看到输出结果还是非常精确的,模型确认没有问题。

检查输出节点
我们使用 Netron 打开模型

可看到模型有 4 个输出节点,其中 ouput 节点为后处理解析后的节点;在实际测试的过程中,发现 NPU 量化操作后对后处理的运算非常不友好,输出数据偏差较大,所以我们可以将后处理部分放在 CPU 运行;因此保留 350,498, 646 三个后处理解析前的输出节点即可,后文会说明如何修改输出节点。
模型的转换
导入模型
我们先准备下需要的文件,与前文 YOLO v3 的类似,dataset 文件夹存放量化所需要的图片,从训练数据集里拿就ok,一个 dataset.txt 定义图片位置。还有我们的模型。
.
├── dataset
│ ├── COCO_train2014_000000000081.jpg
│ ├── COCO_train2014_000000001569.jpg
│ ├── COCO_train2014_000000002849.jpg
│ ├── COCO_train2014_000000004139.jpg
│ ├── COCO_train2014_000000005933.jpg
│ └── dog.jpg
├── yolov5s-sim.onnx
└── dataset.txt
运行下列命令导入模型,指定输出的节点。
pegasus import onnx --model yolov5s-sim.onnx --output-data yolov5s-sim.data --output-model yolov5s-sim.json --outputs "350 498 646"
导入生成两个文件,分别是是 yolov5s-sim.data 和 yolov5s-sim.json 文件,他们是 YOLO V5 网络对应的芯原内部格式表示文件,data 文件储存权重,cfg 文件储存模型。
生成 YML 文件
与上文一样,生成 YML 配置文件
pegasus generate inputmeta --model yolov5s-sim.json --input-meta-output yolov5s-sim_inputmeta.yml
pegasus generate postprocess-file --model yolov5s-sim.json --postprocess-file-output yolov5s-sim_postprocess_file.yml
同样的,修改 yolov5s-sim_inputmeta.yml 文件中的的 scale 参数为 0.0039216(1/255),目的是对输入 tensor 进行归一化,和网络进行训练的时候是对应的。

量化
生成量化表文件,使用非对称量化,uint8,修改 --batch-size 参数为你的 dataset.txt 里提供的图片数量。
pegasus quantize --model yolov5s-sim.json --model-data yolov5s-sim.data --batch-size 1 --device CPU --with-input-meta yolov5s-sim_inputmeta.yml --rebuild --model-quantize yolov5s-sim.quantize --quantizer asymmetric_affine --qtype uint8

预推理
利用前文的量化表执行预推理,得到推理 tensor
pegasus inference --model yolov5s-sim.json --model-data yolov5s-sim.data --batch-size 1 --dtype quantized --model-quantize yolov5s-sim.quantize --device CPU --with-input-meta yolov5s-sim_inputmeta.yml --postprocess-file yolov5s-sim_postprocessmeta.yml
输出了三个 tensor,把他拷贝出来,之后上传到开发板部署验证。
验证预推理
可在开发板上将输出 tensor 结合 Python 或 C++ 后处理代码解析出算法输出结果,也可以在 PC 上导入上一步预推理输出的 tensor来验证仿真推理输出是否正确。这里就采用在 Linux PC 端结合 C++ 编写的后处理代码验证仿真的推理输出。
后处理代码如下,使用 C++ 与 OpenCV 编写。这套后处理代码也可以部署到开发板使用。包括了输出的分析,图像的处理,打框打标等操作:
#include 编译运行后结果输出如下:

可以看到,量化后精度有所损失,不过大体上没什么问题。
导出模板代码与模型
pegasus export ovxlib --model yolov5s-sim.json --model-data yolov5s-sim.data --dtype quantized --model-quantize yolov5s-sim.quantize --batch-size 1 --save-fused-graph --target-ide-project 'linux64' --with-input-meta yolov5s-sim_inputmeta.yml --output-path ovxilb/yolov5s-sim/yolov5s-simprj --pack-nbg-unify --postprocess-file yolov5s-sim_postprocessmeta.yml --optimize "VIP9000PICO_PID0XEE" --viv-sdk ${VIV_SDK}
输出的模型可以在 ovxilb/yolov5s-sim_nbg_unify 文件夹中找到。
开发板部署测试
测试部署可以参照 【NPU Demo 使用说明 - V853】中提供的 lenet 的方法集成输出的模板代码到 Tina Linux 里,来生成 tensor 文件。
运行结果如下,准确率还是比较高的。

开发板输出打框后图像如下

原贴链接:https://v853.docs.aw-ol.com/npu/npu_yolov5/