ECCV 2020 | STAR:基于Transformer的行人轨迹预测模型(一)
这是一篇ECCV 2020 行人轨迹预测的文章,在这里对论文进行浅浅的翻译。当然,由于水平的局限,有些地方只能意译。
论文链接:Spatio-Temporal Graph Transformer Networks for Pedestrian Trajectory Prediction
Abstract
理解人群动态运动对真实世界的一些应用,例如监控系统、自动驾驶来说是非常重要的。这是具有挑战性的,因为它(理解人群动态运动)需要对具有社会意识的人群的空间交互和复杂的时间依赖性进行建模。我们认为,注意力机制对于轨迹预测来说是最重要的因素。在这篇论文中,我们提出了STAR网络,一种基于时空图注意力机制的模型架构,它能仅依靠注意力机制解决轨迹预测(的问题)。STAR通过TGConv对图内人群进行建模,TGConv是一种基于Transformer的新型图卷积机制。图间的时间依赖性由单独的temporal Transformer进行建模。STAR通过spatial Transformer与temporal Transformer的交互,捕捉复杂的时空关系。为了校准由于消失行人的长期影响的时间预测,我们引入了一个可读写的外部存储模块,由temporal Transforemer持续更新。我们表明,仅通过注意力机制,STAR在5个常用的现实世界行人预测数据集上实现了SOTA的性能。
1. Introduction
行人轨迹预测对于计算机视觉和机器人产业来说都至关重要。行人轨迹预测是具有挑战性的,因为:1)人与人之间的交互是多模态的,并且很难捕捉,举例来说陌生人会尽量避免与他人的亲密接触,而同伴则倾向于成群结队地行走;2)复杂的时间预测和人与人之间的空间交互,举例来说人们会根据neighbors过去和未来的运动,来调节他们(自身)的运动。
捕捉人与人之间交互的经典模型是通过人为(设定)的energy-function来实现的,这需要大量特征工程的工作,并且在建立拥挤空间的人群交互时通常是以失败告终的。随着深度神经神经网络的崛起,RNN已经被用于轨迹预测,并且取得了良好的效果。基于RNN的模型通过行人潜在的状态来捕捉其运动,然后融合空间邻近行人的潜在状态来实现人与人之间交互的建模。Social-pooling平等地看待邻里区域的行人,并通过池化机制合并他们潜在的状态。注意力机制放宽了这种假设,并根据学习到的函数对行人进行加权,该函数编码了相邻行人对于轨迹预测的不同的重要性(意思就是说不同的行人对轨迹预测有着不同的影响)。然而,现今的(轨迹)预测器有两个共同的局限性:1)注意力机制的使用过于单一,无法完全对行人间的交互进行建模;2)RNNs通常难以对复杂的时间依赖性进行建模。
最近,Transformer网络在NLP领域取得了开创性的成果。Transformer摒弃了语言序列的序列性质,仅通过强而有力的self-attention机制就能对时间依赖性进行建模。相较于RNNs,Transformer架构的主要优势是,仅通过sel-attention就能够极大地改善对时间依赖性的建模,尤其是对水平序列来说。然而,基于Transformer的模型受限于正常的数据序列,很难将其推广到结构化数据(序列),例如图序列。
在该论文中,我们引入了STAR模型——一种新颖的基于纯自注意力机制(self-attention)的时空轨迹预测模型。我们坚信,时间attention、空间attention、时空attention的学习是精确预测行人轨迹的关键,而Transformer恰恰为这项任务提供了一个简洁的、有效的解决方案。STAR通过spatial graph Transformer捕捉行人间的交互。特别地,我们引入了TGConv架构——一种基于Transformer的图卷积机制。TGConv通过Transformer的自注意力机制改善了基于注意力机制的图卷积,可以捕捉更为复杂的社交互动。准确来说,TGConv倾向于在行人密度较高的数据集如ZARA1、ZARA2、UNIV上做较大的改善。我们用一个单独的temporal Transformer对行人的运动进行建模,相较于RNNs来说可以更好的捕捉(行人间的)时间依赖性。STAR通过spatial Trans former和temporal Transformer之间的交互来提出行人之间的时空interaction,这是一种简单而有效的策略。此外,由于Transformer将序列视为一组词袋模型,因此Transformer难以对时间序列数据进行建模,这是因为时间序列具有很强的(数据)一致性。我们引入了一个额外的可读写图形的内存模块,该模块在预测期间连续对嵌入(序列)执行平滑(操作)。对STAR的概述见于图2。
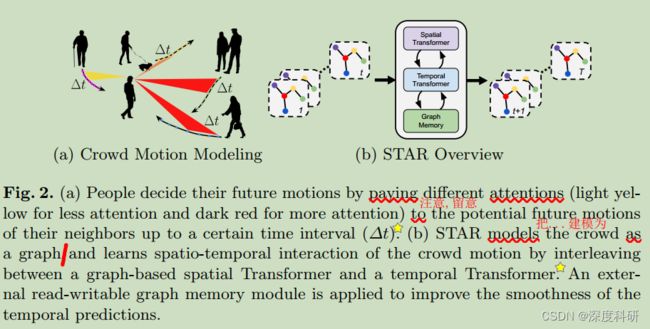
我们在5个常用的现实世界行人预测数据集进行了实验。仅靠注意力机制,STAR在这5个数据集上都取得了SOTA的实验效果。为了更好的理解所提出的每个component(的作用),我们还进行了额外的消融实验。
2. Background
2.1 Self-Attention and Transformer Networks
Transformer网络在NLP领域取得了巨大的成功,例如机器翻译、情感分析以及文章总结。Transformer沿用了被广泛用在RNN Seq2Seq模型里的encoder-decoder架构。
Transformer的核心思想是完全通过多头注意力机制来取代recurrence。对于嵌入的向量![]() ,Transformer的自注意力层首先学习
,Transformer的自注意力层首先学习![]() 到
到 的所有嵌入的query矩阵
的所有嵌入的query矩阵![]() 、key矩阵
、key矩阵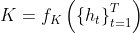 和相应的value矩阵
和相应的value矩阵![]() 。然后通过下式计算注意力:
。然后通过下式计算注意力:
![]()
其中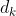 代表每个query的维度。
代表每个query的维度。![]() 是缩放点乘积项,用于注意力数值稳定。通过计算跨不同时间步长的嵌入向量间的自注意力,就能够学习到长范围的时间依赖性,这与使用有限内存的单个向量来记忆历史的RNN不同。另外,将attention结构为query, key, value元组,能够使自注意力捕捉更为复杂的时间依赖性。
是缩放点乘积项,用于注意力数值稳定。通过计算跨不同时间步长的嵌入向量间的自注意力,就能够学习到长范围的时间依赖性,这与使用有限内存的单个向量来记忆历史的RNN不同。另外,将attention结构为query, key, value元组,能够使自注意力捕捉更为复杂的时间依赖性。
多头注意机制在计算attention时会将多个假设结合起来。多头自注意力允许模型在不同的位置共同关注来自不同表征的信息。对于 个头,我们有:
个头,我们有:
![]()
![]()
其中![]() 表示全连接层,融合来自个头的输出;
表示全连接层,融合来自个头的输出;![]() 表示第
表示第 个头的自注意力。附加位置编码用于在Transformer嵌入中添加位置信息。最后,Transformer 通过两个残差连接的全连接层输出更新后的embedding。
个头的自注意力。附加位置编码用于在Transformer嵌入中添加位置信息。最后,Transformer 通过两个残差连接的全连接层输出更新后的embedding。
然而,目前基于Transformer的模型的一个主要局限是只适用于非结构化的数据序列,如词序列。STAR将Transformers扩展到更结构化的数据序列——作为第一步——图序列,并将其应用于轨迹预测。
2.2 Related Works
Graph Neutral Networks 图神经网络(GNNs)是一种强大的图结构数据深度学习结构。图卷积在图机器学习任务上表现出了显著的改进,如物理系统建模、药物预测和社会推荐系统。特别地,图注意力网络( Graph Attention Networks,GAT ) 实现了节点间高效的加权消息传递,并取得了跨多个领域的最新成果。从序列预测的角度看,时序图 RNNs 允许在图序列中学习时空关系。我们的 STAR利用 Transformer TGConv改进了GAT,它提高了注意力机制,解决了Transformer 结构的图形时空建模问题。
Squence Prediction RNNs及其变体,如LSTM和GRU ,在序列预测任务中取得了巨大成功,如语音识别、机器人定位、机器人决策等。RNNs 也被成功应用于行人的时间运动模式建模。基于 RNNs的预测器使用Seq2Seq结构进行预测。附加的结构,例如social polling、注意力机制和图神经网络,用于改进轨迹预测与社会交互建模。
近年来,Transformer网络在自然语言处理领域占据主导地位。Transformer模型完全抛弃了递归并将注意力集中在跨时间步骤上。这种架构允许长期依赖性建模和大批量并行训练。Transformer架构也被成功应用于其他领域,例如股票预测、机器人决策等。STAR将Transformer的思想应用于图形序列。我们在一个具有挑战性的人群轨迹预测任务上演示它,其中我们将人群交互视为一个图形。STAR是一个通用框架,可以应用于其他图序列预测任务,例如社交网络中的事件预测和物理系统建模。我们把这个留给以后学习。
Crowd Interaction Modeling 作为开创性的工作,社会力量模型已被证明在各种应用中有效,例如人群分析和机器人。他们假设行人在虚拟力的驱动下进行目标导航和避碰。社会力模型在交互建模方面工作良好,但在轨迹预测方面表现不佳。基于几何的方法,如ORCA 和PORCA ,考虑Agent的几何结构,将交互建模转化为优化问题。经典方法的一个主要局限在于它们依赖于手工制作的特征,这些特征非常容易调整,难以概括。
基于深度学习的模型通过直接从数据中学习模型来实现自动特征工程。行为CNNs 通过CNNs捕捉人群互动。Social-Pooling通过近似人群交互的聚合机制进一步编码近端行人状态。最近的研究将人群视为一个图,将空间邻近行人的信息与注意机制进行合并。与池化方法相比,注意机制对行人进行重要建模。图神经网络也被应用于解决人群建模。显式消息传递使得网络能够对更复杂的社会行为进行建模。
3. Method
3.1 Overview
本节,我们将介绍基于轨迹预测架构的spatial-temporal Transformer——STAR。我们坚信,attention对于有效且高效预测轨迹是最重要的因素。
STAR将时空注意力模型分解为时间模型(temporal modeling)和空间模型(spatial modeling)。对于时间建模,STAR 独立地考虑每个行人,并应用标准的temporal Transformer network来提取时间依赖项。与RNNs相比,temporal Transformer提供了一个更好的时间依赖建模协议,我们在消融实验中验证了这一点。对于空间建模,我们引入了基于 Transformer的消息传递的图卷积机制TGConv。TGConv以更好的注意机制改进了目前的图卷积方法,为复杂的空间相互作用给出了更好的模型。特别是,TGConv更倾向于在行人密度较高(ZARA1、ZARA2、UNIV)和复杂交互的数据集上改进。我们构造了两个编码器模块,每个模块包含一对spatial and temporal Transformer,并将其叠加,以提取时空交互。
3.2 Problem Setup
给定在时间步长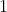 到
到![]() 的行人运动历史,我们感兴趣的问题是,预测在某一场景中
的行人运动历史,我们感兴趣的问题是,预测在某一场景中 个行人在时间步长
个行人在时间步长![]() 到的未来轨迹。在每一时间步长
到的未来轨迹。在每一时间步长 中,(假定)我们有N个行人
中,(假定)我们有N个行人![]() ,其中
,其中![]() 在某个场景中自上而下行人的位置。我们假设距离小于
在某个场景中自上而下行人的位置。我们假设距离小于 的行人对
的行人对![]() 有一条无向边
有一条无向边 。这就导致在每个时间步长处有一个交互图
。这就导致在每个时间步长处有一个交互图![]() :
:![]() ,其中
,其中![]() ,
,![]() 。(实际上
。(实际上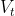 就是节点的集合,而
就是节点的集合,而![]() 就是边的集合)。对于在时间时的每个节点,我们定义其邻接集为
就是边的集合)。对于在时间时的每个节点,我们定义其邻接集为![]() ,其中对于每个节点
,其中对于每个节点 ,
,![]()
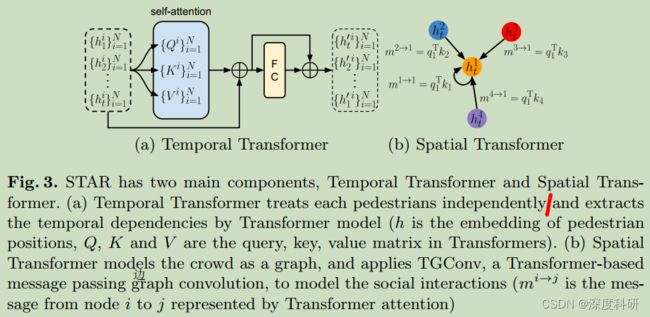
3.3 Temporal Transformer
Temporal Transformer block以一组行人轨迹![]() 作为输入(注意上表表示的是第几个行人,下表表示的是在哪个时刻),输出一组具有时间依赖关系的更新嵌入
作为输入(注意上表表示的是第几个行人,下表表示的是在哪个时刻),输出一组具有时间依赖关系的更新嵌入![]() 作为输出,独立考虑每个行人。
作为输出,独立考虑每个行人。
Temporal Transformer block的结构见图3(a)。自注意力模块首先学到query matrixs ![]() ,key matrixs
,key matrixs ![]() ,value matrixs
,value matrixs ![]() 。对于第个person,有:
。对于第个person,有:
其中![]() 是行人
是行人![]() 共享的query,key,value函数。我们可以利用GPU的加速实现所有行人的并行计算。
共享的query,key,value函数。我们可以利用GPU的加速实现所有行人的并行计算。
我们按照公式1分别计算每个行人的注意力。相似地,对于多头自注意力来说(![]() ),对于每个行人,我们有:
),对于每个行人,我们有:
其中![]() 是一个融合个head的全连接层,
是一个融合个head的全连接层,![]() 是第个head的索引。最终的输出由两个残差连接和一个全连接层产生,见图3(a)所示。
是第个head的索引。最终的输出由两个残差连接和一个全连接层产生,见图3(a)所示。
temporal Transformer是Transformer network对数据序列集的简单推广。我们在实验中论证了基于Transformer的体系结构提供了更好的时间建模。
3.4 Spatial Transformer
spatial Transformer block提取行人之间空间交互(的信息)。我们提出了一种新的基于Transformer的图卷积——TGConv——用于图上的消息传递。
通过观察发现,自注意力机制可以被视为在一个无向全连接图上(进行)消息传递。对于特征集![]() 的一个特征向量
的一个特征向量 ,我们可以将相应的query vector,key vector,value vector表示为
,我们可以将相应的query vector,key vector,value vector表示为![]() ,
,![]() ,
,![]() 。我们定义在全连接图中从节点到节点的信息传递为:
。我们定义在全连接图中从节点到节点的信息传递为:
![]()
所以注意力函数可以改写为:
![\operatorname{Att}(Q, K, V)=\frac{\operatorname{Softmax}\left(\left[m^{j \rightarrow i}\right]_{i, j=1: n}\right)}{\sqrt{d_{k}}}\left[v_{i}\right]_{i=1}^{n}](http://img.e-com-net.com/image/info8/aeac2dd4e8094909ad7c13d11d1d0edc.gif)
基于以上的见解,我们引入了TGConv模型。TGConv本质上仍是基于注意力的图卷积机制,有点儿像GATConv(图注意力网络),但是比GATConv具有更好的由Transformer所驱动的注意力机制。对于任意的graph ![]() ,
, 实际就是节点的集合,而
实际就是节点的集合,而 就是边的集合。对于节点的图卷积操作可以表示为:
就是边的集合。对于节点的图卷积操作可以表示为:
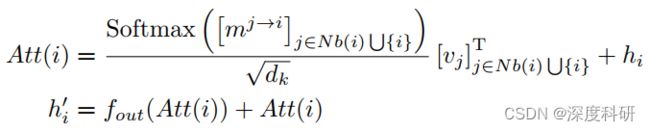
其中![]() 是输出函数,在我们的架构中,它是一个全连接层,
是输出函数,在我们的架构中,它是一个全连接层,![]() 是TGConv对节点的更新嵌入。我们通过
是TGConv对节点的更新嵌入。我们通过![]() 总结节点的TGConv函数。我们通常在上述方程中的每一个残差连接后都会由一个归一化(normalization)。我们在方程中忽略了它们,以得到一个整洁的符号。
总结节点的TGConv函数。我们通常在上述方程中的每一个残差连接后都会由一个归一化(normalization)。我们在方程中忽略了它们,以得到一个整洁的符号。
spatial Transformer如图 3(b) 所示,可以方便地由TGConv 实现。对每个图 分别施加一个具有共享权重的TGConv。我们认为TGConv是通用的,可以应用于其他任务,我们将它留给未来的研究。
分别施加一个具有共享权重的TGConv。我们认为TGConv是通用的,可以应用于其他任务,我们将它留给未来的研究。
3.5 Spatio-Temporal Graph Transformer
在本小节,我们将介绍用于行人轨迹预测的spatial-temporal Transformer——STAR架构。
temporal Transformer可以单独对每个行人的动态运动进行建模,但不包含空间相互作用;spatial Transformer用TGConv解决人群交互(的问题),但很难推广到时间序列。行人预测的一个主要挑战是建立耦合的时空交互模型。行人的时空动态是紧紧相依的。例如,当一个人决定他的下一个动作时,首先要预测她的neighbors的未来动作,并选择一个在一个时间间隔 内避免与他人碰撞的动作。
内避免与他人碰撞的动作。
STAR通过将temporal Transformer与spatial Transformer交织在一个单一的框架下,来解决耦合的时空建模问题。图4展示了STAR的网络架构。STAR有两个encoder模组和一个简单的decoder模组。网络的输入是行人在时间![]() 到
到![]() 的位置序列,其中时刻的位置序列用
的位置序列,其中时刻的位置序列用![]() 表示,
表示,![]() 。在第一个encoder中,通过两个独立的全连接层对位置进行嵌入,并将嵌入(后的输出)传递给spatial Transformer 1和temporal Transformer 1,从行人历史中提取独立的时空信息(注意:虽然这里全连接层一样,但是全连接层的输入输出都是不一样的)。然后通过一个全连接层将spatial Transformer 1 和temporal Transformer 1的输出进行融合(实际上就是Concatenate拼接),(全连接层的输出)提供了一组具有时空编码的新特征。为了进一步在特征空间中对时空交互进行建模,我们在第二个encoder对得到的特征进行后处理。在第二个编码器中,spatial Transformer 2利用(第一个encoder的输出的)时间信息对空间交互进行建模,temporal Transformer 2增强了输出的空间嵌入性,具有时态注意力。STAR通过一个简单的全连接层来预测行人在
。在第一个encoder中,通过两个独立的全连接层对位置进行嵌入,并将嵌入(后的输出)传递给spatial Transformer 1和temporal Transformer 1,从行人历史中提取独立的时空信息(注意:虽然这里全连接层一样,但是全连接层的输入输出都是不一样的)。然后通过一个全连接层将spatial Transformer 1 和temporal Transformer 1的输出进行融合(实际上就是Concatenate拼接),(全连接层的输出)提供了一组具有时空编码的新特征。为了进一步在特征空间中对时空交互进行建模,我们在第二个encoder对得到的特征进行后处理。在第二个编码器中,spatial Transformer 2利用(第一个encoder的输出的)时间信息对空间交互进行建模,temporal Transformer 2增强了输出的空间嵌入性,具有时态注意力。STAR通过一个简单的全连接层来预测行人在![]() 时刻的位置,该全连接的输入是temporal Transformer 2的输出,并与随机高斯噪声相连接(concatenate拼接),以此产生各种未来预测。我们根据预测的位置连接距离小于的节点构造图
时刻的位置,该全连接的输入是temporal Transformer 2的输出,并与随机高斯噪声相连接(concatenate拼接),以此产生各种未来预测。我们根据预测的位置连接距离小于的节点构造图![]() 。将预测加入到历史中进行下一步预测
。将预测加入到历史中进行下一步预测
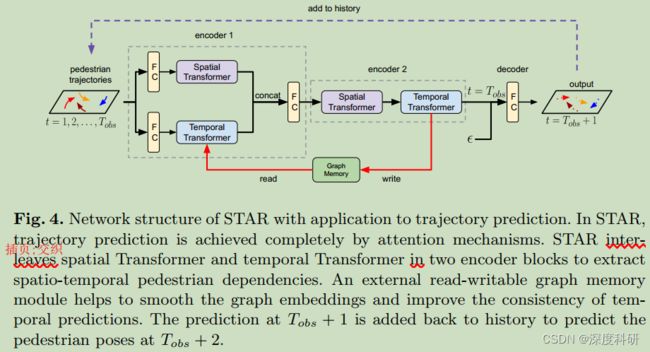
与简单讲spatial / temporal Transformer结合相比,STAR架构极大的改善了时空建模的性能。
3.6 External GraphMemory
...没有了,后面没有难度了...
要做核酸去了,记得针对甄姬!