基于CNN的2D多人姿态估计论文综述
bottom up系列算法(直接获取全图人体关键点):
1.Openpose(coco2016关键点冠军,利用paf进行group)
2.Lightweight OpenPose(轻量级Openpose)
3.Associative Embedding (关键点分组编码思想)
4.Pose Proposal Networks(利用YOLO思想采用网格级别姿态估计)
5.GPN(生成分区网络用以实现多人姿态估计)
6.SPM(单阶段多人姿态估计机器)
7.personlab(将人体关键点检测和实例分割统一到一个网络中)
8.pifpaf(效果远超Openpose)
9.HigherHrnet(改进hrnet用于多人关键点估计,达到目前最优)
top down系列算法(获取全图人体框后再提取人体框内的关键点,因此其本质和单人姿态估计类似,如下有部分算法与单人姿态估计中重合)
1.Joint-to-Person Associations(利用线性规划尝试解决拥挤和遮挡问题)
2.Deepcut & Deepercut(基于人体聚类后利用线性规划获取关键点)
3.G-RMI(关键点检测基石,有许多基础思路)
4.alphapsoe1 & alphapsoe2(解决人体框不准和拥挤场景姿态估计)
5.Joint Pose & Segmentation(联合姿态估计和躯干分割网络)
6.Joint Pose & Detection(联合姿态估计和目标检测网络)
1.Openpose(coco2016关键点冠军,利用paf进行group)
CVPR2016 | Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
Arxiv 2018 | OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
Official Code: caffe
3rdparty Code:tensorflow1
3rdparty Code:tensorflow2
3rdparty Code:tensorflow3
3rdparty Code:tensorflow4
3rdparty Code:tensorflow5
3rdparty Code:tensorflow6
3rdparty Code:pytorch1
3rdparty Code:pytorch2
3rdparty Code:pytorch3
3rdparty Code:Caffe2
openpsoe的训练过程中,两个版本都是基于多stage进行训练的。而且都需要输出两个部分,如下图一所示,淡蓝色模块用于输出图像中所有人体的关键点之间的方向。米色模块用于输出图像中人体关键点的置信度图。openpsoe的训练过程中,两个版本都是基于多stage进行训练的。而且都需要输出两个部分,如下图一所示,淡蓝色模块用于输出图像中所有人体的关键点之间的方向。米色模块用于输出图像中人体关键点的置信度图。openpose版本2之所以提出了这个思想,如图二所示(CM表示置信度图,PAF表示关键点间方向),作者将计算限定在最多6个阶段,分布在PAF和置信图分支上。从图二的结果中,可以得出三个结论:
- 首先,PAF需要更多的阶段来聚合,并从细化阶段获得更多的好处。
- 增加PAF通道的数量主要是改善真阳性的数量,即使它们可能不是太精确(更高的AP50)。但是,增加置信度图通道的数量可以进一步提高定位精度(更高的AP75)。
- 作者证明了将PAF模块放在前面,置信度图放在后面,最终的精度有了很大的提高,相反的结果是绝对精度下降了4%。即使只有4个阶段(3 PAF - 1 CM)的模型也比计算上更昂贵的6个阶段模型(3 CM - 3 PAF)更准确(这就是本文提出改进版本结构的原因)。

2.Lightweight OpenPose(轻量级Openpose)
Arxiv 2018 | Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose
Official Code openpose3: pytorch
基于Openpose的方案,通过优化其后处理方案,在Intel®NUC 6i7KYB mini PC 达到了28fps ,在Core i7-6850K CPU达到了26fps。该算法只有2-stageOpenpose的15%大小,但却实现了相同的效果。该算法利用mobilenetv1结合空洞卷积的方式优化了openpose的backbone。

3.Associative Embedding (关键点分组编码思想)
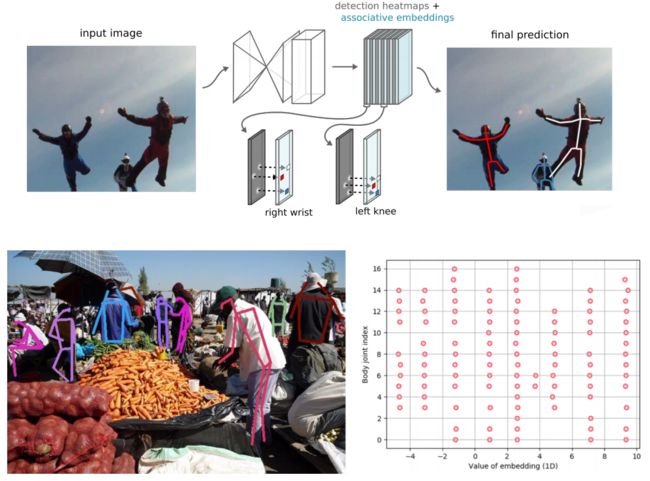
CVPR 2016 | Associative Embedding:End-to-End Learning for Joint Detection and Grouping
3rdparty Code:pytorch
3rdparty Code:tensorflow
本文使用stacked hourglass检测关节点,在原来的基础上每一次下采样时增加输出通道的个数,同时individual layers的残差模型改为3*3的卷积结构,其他结构不变。但除了输出关键点的多峰heatmap外,还输出对应的embedding tag。并通过对不同实例的tag进行分组(分组标准按照欧式距离进行),最终通过分组将关节分配到各个实例上。
4.Pose Proposal Networks(利用YOLO思想采用网格级别姿态估计)
ECCV 2018 | Pose Proposal Networks
3rdparty Code:pytorch
3rdparty Code:chainer
采用了YOLO目标检测的思想,将人体姿态检测看作是一个目标检测问题,对人体部位不再采用 pixel-wise(像素级别) 的检测,而是采用 grid-wise(网格级别) 来得到人体部位的feature map,其中利用一个 single-shot CNN 网络同时对身体关节和肢体(limb)来进行检测,然后采用类似OpenPose中的PAF分析方法来得到完整的人体姿态。
5.GPN(生成分区网络用以实现多人姿态估计)
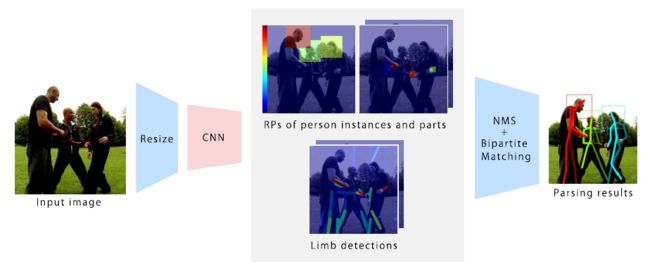
ECCV 2018 | Generative Partition Networks for Multi-Person Pose Estimation
Official Code:pytorch
为了有效地解决具有挑战性的多人姿态估计问题,提出了生成式划分网络(GPN)。GPN通过同时检测和划分多人关节来解决这一问题。提出了一种基于人中心体参数化的嵌入空间中联合候选节点的划分方法。此外,GPN引入了一种局部贪婪推理方法,利用分区信息来估计person实例的位姿。GPN首先使用CNN来预测(a)联合置信度图和(b)稠密的联合质心回归图。然后,GPN通过稠密回归对嵌入空间中的所有关节候选对象进行©质心聚类,在人员检测范围内产生(d)关节分区。最后,GPN进行(e)局部贪婪推理,局部生成每个关节分区的关节构型,给出多个体的位姿估计结果。

6.SPM(单阶段多人姿态估计机器)
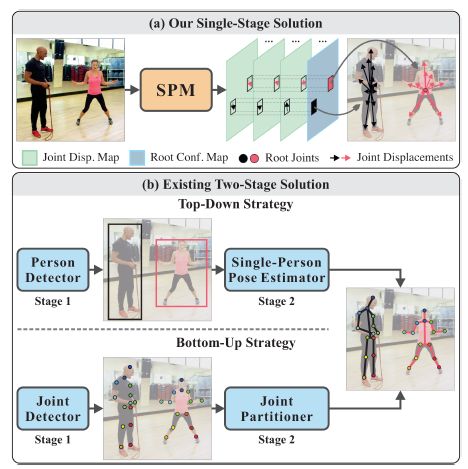
ICCV 2019 | Single-Stage Multi-Person Pose Machines
3edParty:tensorflow
本文的核心策略为:SPR(Structured Pose Representation),该模块就是想把人体位置信息和其对应的关键点位置信息联系起来,SPR模块利用一个root点来表征每个人体在图像中的位置信息,并且通过当前root点位置进行编码得到对应人体的所有关键点位置。本文首次提出了one-stage的多人姿态估计网络,利用单阶段多人姿态机(Single-stage multi-person Pose Machine, SPM),对root点和相对偏移量进行回归。
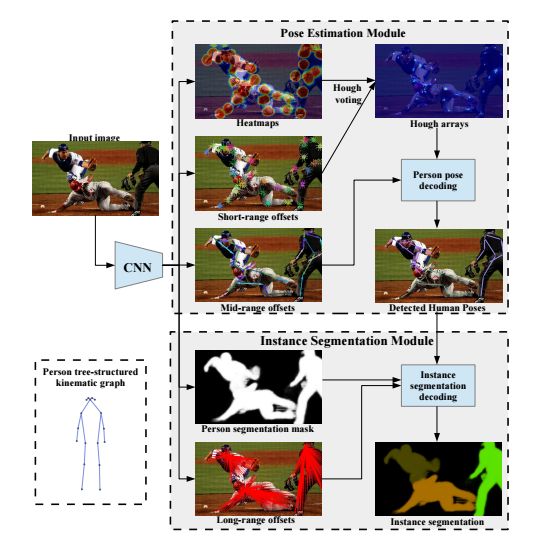
7.personlab(将人体关键点检测和实例分割统一到一个网络中)
ECCV 2018 | PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
3rdParty : Keras
3rdParty : tensorflow
作者将图片中每个人的所有关键点找到。然后预测每一对关键点的相对位置关系,为了提高两个远距离的关键点预测的准确率,提出一种新的循环的方法,极大地提高了效果。最后使用贪婪解码方法,将所有的关键点对应分到各自的实例中。PersonLab采用了先从最有把握的关键点开始进行分割,而不是直接定义一个确定的基准,例如鼻子,使得在聚类的时候表现的很好。
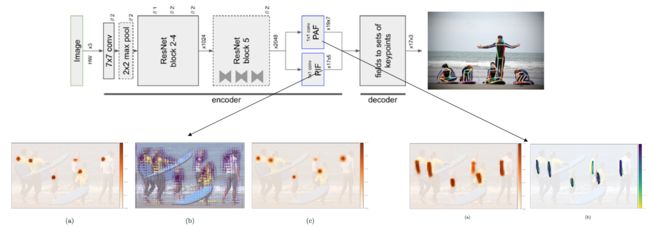
8.pifpaf(效果远超Openpose)
CVPR 2019 | PifPaf: Composite Fields for Human Pose Estimation
Official Code:pytorch
文章提出Part Intensity Field (PIF) 用来定位人体关节点位置,提出Part Association Field (PAF) 用来确定关节点之间的连接。通过预测图片中每个位置的Pif信息, 来确定图片上的位置是否是人体关节点位置; 并通过paf信息把同属于同一个人的人体关节点连接起来, 这样就可以 (1) 预测出图片上所有人的关节点 (2) 把属于同一个人的人体关节点连接起来。在 COCO keypoint task 上达到了state-of-the-art, 打败了目前所有的bottom-up方法, 按照文章的说法, 比openpose提高了大约AP/AR12个点左右。
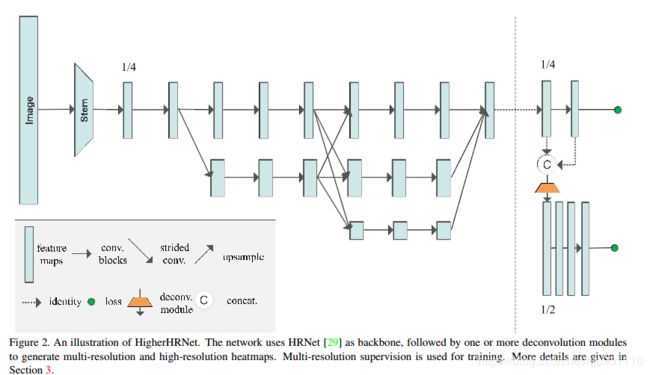
9.HigherHrnet(改进hrnet用于多人关键点估计,达到目前最优)
CVPR 2019 | Bottom-up Higher-Resolution Networks for Multi-Person Pose Estimation
Official Code: pytorch
在高分辨率网络(HRNet)上增加一个高效的反卷积模块,以降低计算开销,提出了一种高分辨率网络(HigherHRNet)。提出了一种训练阶段的多分辨率训练和热度图聚合策略,使高分辨率网络能够预测具有尺度感知的热图。达到了bottom-up的最好效果——70map。
#------------------
top-down
1.Joint-to-Person Associations(利用线性规划尝试解决拥挤和遮挡问题)
ECCVworkshop 2016 | Multi-Person Pose Estimation with Local Joint-to-Person Associations
本文提出的多人关键点检测算法,首先检测出图像中的所有人体。其次检测出每个人体框中所包含的所有关键点。之后以所有关键点为顶点,关键点之间的连接为边构建一个图。最后针对于每一个矩形框中的图,利用线性规划得到最优连接。该方法相较于传统的topdown方法能够更好的处理遮挡和拥挤的情况。
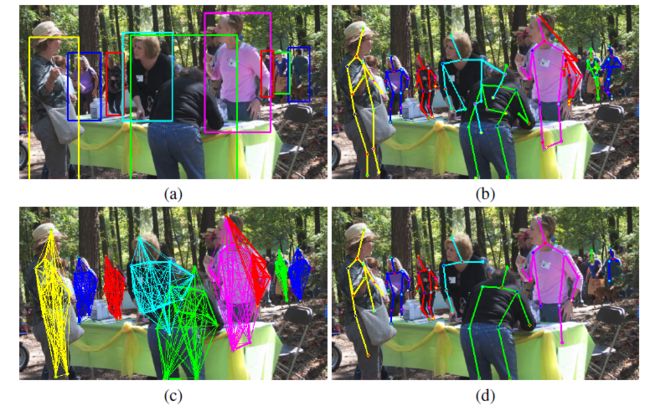
2.Deepcut & Deepercut(基于人体聚类后利用线性规划获取关键点)
CVPR 2016 | DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation
ECCV 2016 | DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model
Official Code: caffe
Deepcut:
该算法提出了一种联合解决检测和姿态估计的方法,首先利用CNN的方法提取图像中的所有关键点,所有的关键点作为节点组成一个dense graph(密度图)。其次利用Fasterrcnn获取人体位置,并联合密度图。最终将属于同一个人的关键点(节点)归为一类,每个人作为一个单独类。
本文的思路具有以下几个优势:
1)可以解决未知个数人的图像,通过归类得到有多少个人
2)通过图论节点的聚类,有效的进行了非极大值抑制
3)优化问题表示为 Integer Linear Program (ILP),可以有效求解
Deepercut:
本算法是在Deepcut的基础上,对其进行改进,改进的方式基于以下两个方面:
(1)使用最新提出的residual net进行关键点的提取,效果更加准确,精度更高。
(2)使用Image-Conditioned Pairwise Terms的方法,能够将众多候选区域的节点压缩到更少数量的节点,这也是本文为什么stronger和faster的原因所在。该方法的原理是通过候选节点之间的距离来判断其是否为同一个重要节点。
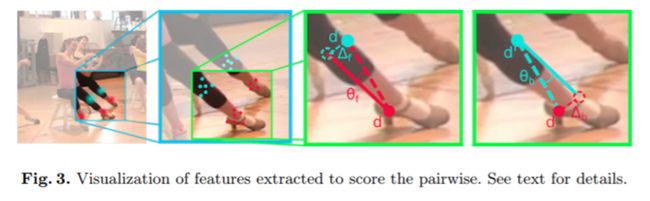
3.G-RMI(关键点检测基石,有许多基础思路)
CVPR2017 Google | Towards accurate multi-person pose estimation in the wild
Official Code: pytorch
本文提出了一种2D人体关键点检测的方法,该方法是一种简单而强大的自上而下的方法,包括两个阶段。在第一阶段,算法预测图片中人体的位置和大小;为此,算法使用Faster RCNN检测器。在第二阶段,算法估计每个人体框框中可能包含的关键点。对于每种关键点类型,算法使用全卷积的ResNet预测对应的热图和偏移量。为了结合这些输出,算法引入了一种新颖的聚类来获得高度本地化的关键点预测。文章还使用了一种全新的基于关键点的非极大值抑制(NMS),而不是较粗糙的基于人体的NMS,以及一种新颖的基于关键点的置信度估计的形式,而不是基于目标框评分。本文提出的基于关键点的NMS在后面的自上而下的文章中被普遍应用。

4.alphapsoe1 & alphapsoe2(解决人体框不准和拥挤场景姿态估计)
ICCV 2017 | RMPE: Regional Multi-person Pose Estimation
ArXiv 2018 | CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
Official Code: caffe
Official Code: pytorch
RMRE(该方法能够处理不准确的bounding box(边界框)和冗余检测。):论文中值得学习的思想有三点: 第一:Symmetric Spatial Transformer Network – SSTN 对称空间变换网络:在不准确的bounding box中提取单人区域。第二:Parametric Pose Non-Maximum-Suppression – NMS 参数化姿态非最大抑制:解决冗余。第三:Pose-Guided Proposals Generator – PGPG 姿态引导区域框生成器:增强训练数据。
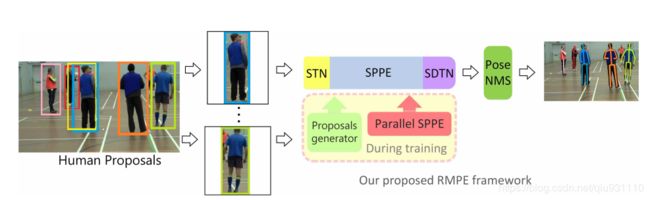
CrowdPose:论文中值得学习的思想有两点: 第一: joint-candidate single person pose estimation (SPPE):通过候选点的概念,设计了对应的候选loss,从而抑制非当前人体实例的点,实现了对拥挤人体关键点的提取。第二:global maximum joints associatio:基于上述特定的单人姿态估计网络,检测到的关键点数量比实际要多,因此提出以图论的方式,通过一个线性规划求解最优解的方式实现最优图的构建,从而实现最优实例的链接。

5.Joint Pose & Segmentation(联合姿态估计和躯干分割网络)
CVPR 2017 | Joint Multi-Person Pose Estimation and Semantic Part Segmentation
该算法的整体思路如下图所示,首先通过Fastrcnn等方法得到多人图像中的每个人体的bounding box,在使用PoseFCN得到对应人体的初步姿态分数图。同时对于当前的bounding box使用PartFCN得到对应的人体躯干分割初步结果。将PoseFCN和PartFCN得到的结果输入到FCRF(全连接条件随机场),利用分割结果辅助最终的关键点姿态的估计。并将更加精准的关键点姿态分数图输入到第二阶段的PartFCN中,利用精准的姿态估计结果辅助人体躯干分割。该方法通过两种结果的相辅相成,最终在两个结果上都有效果的提升。
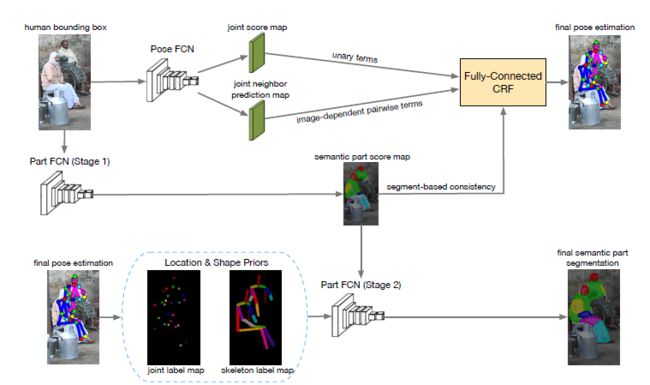
6.Joint Pose & Detection(联合姿态估计和目标检测网络)
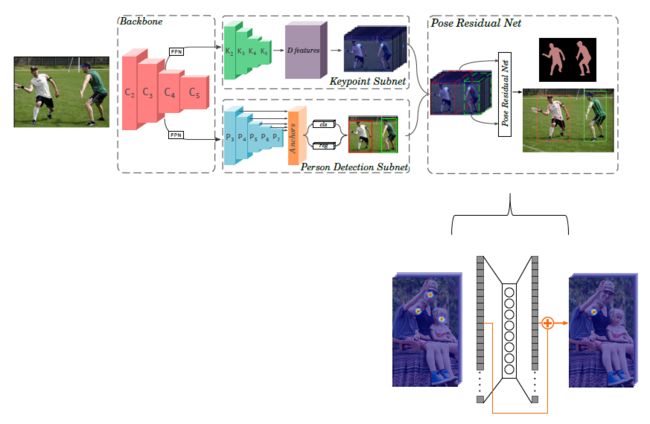
ECCV 2018 | MultiPoseNet: Fast Multi-Person Pose Estimation using Pose Residual Network
Official Code:pytorch
该算法叫做MultiPoseNet,可以联合处理人体检测、关键点定位问题。该方法利用位Pose Residual Network(PRN)实现了一种新的姿态分配方法。由于现有的基于全图作多人姿态估计的方法(openpose)存在性能上的瓶颈,而基于单人检测后的单人姿态估计方法(alphapose)随着人数的增多,处理时间暴增等问题。MultiPoseNet网络先通过对图像作全图的多人姿态估计,再结合与姿态估计共用参数层的人体检测网络得到的人体框,并结合PRN网络,最终实现多人姿态估计,均衡了时间和性能上的问题。