深度卷积神经网络演化历史及结构改进脉络总结
Table of Contents
CNN基本部件介绍
1. 局部感受野
2. 池化
3. 激活函数
4. 全连接层
深度学习模型火的原因?
网络模型命名规则
最古老的的CNN
LeNet5
ILSVRC竞赛历年的佼佼者(AlexNet、VGG、GoogLeNet、ResNet)
AlexNet(2012)
VGG(2014)
Network in network(2014)
贡献
MAP作用/好处
Resnet残差网络(2016)
ResNeXt(2017)
ResNet和Inception结合体
一般来说增加网络表达能力的途径有三种
谷歌系列 :Inception v1到v4(2015年-2017年)
Inception v1模型(2014)
Inception v2模型(BN-Inception)(2015)
与Inception V1区别
深度网络为什么难训练?
Inception v3模型(2016)
Inception V3核心思想
Inception V3的目的
Inception V3网络结构最大的变化
Inception V4(2017)
Inception-ResNet系列(V1和V2)
Inception-Resnet-v1
Inception-Resnet-v2
ResNeXt(2017)
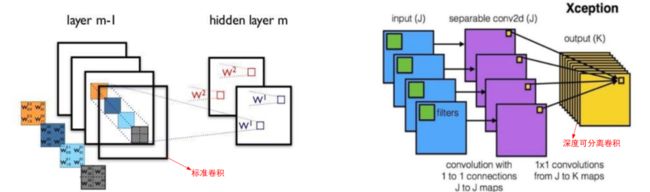
Xception(2017)
基本思想
设计目的
基本步骤
Xception与Inception-v3在结构上有什么差别?
MobileNet V1(2017)
V1创新点总括
V1创新点详解
能够减少参数数量和计算量的原理
标准卷积和深度可分离卷积的区别
MobileNet的弊端,为以后ShuffleNet提出奠定基础
TensorFlow 中的代码实现
Caffe 中的代码实现
Densenet(2017)
创新点
EffNet(2018)
EffNet是对MobileNet-v1的改进,主要思想
mobilenet-v2(2018)
相比于Mobilenet-V1的三点不同总括:
Mobilenet-V2创新点详解
网络优化
MobileNetV2和 MobileNetV1 的区别
相同点
不同点:Linear Bottleneck
对比 MobileNet V2与ResNet 的微结构
Mobilenet-v3(2019)
SqueezeNet(2017ICLR)
命名
创新点
ShuffleNet V1(2018)
ShuffleNet V2(2018ECCV)
SENet(2018)
SKNet(2019CVPR)
博客参考
参考文献
CNN基本部件介绍
1. 局部感受野
在图像中局部像素之间的联系较为紧密,而距离较远的像素联系相对较弱。因此,其实每个神经元没必要对图像全局进行感知,只需要感知局部信息,然后在更高层局部信息综合起来即可得到全局信息。卷积操作即是局部感受野的实现,并且卷积操作因为能够权值共享,所以也减少了参数量。
2. 池化
池化是将输入图像进行缩小,减少像素信息,只保留重要信息,主要是为了减少计算量。主要包括最大池化和均值池化。
3. 激活函数
激活函数的用是用来加入非线性。常见的激活函数有sigmod, tanh, relu,前两者常用在全连接层,relu常见于卷积层
4. 全连接层
全连接层在整个卷积神经网络中起分类器的作用。在全连接层之前需要将之前的输出展平
深度学习模型火的原因?
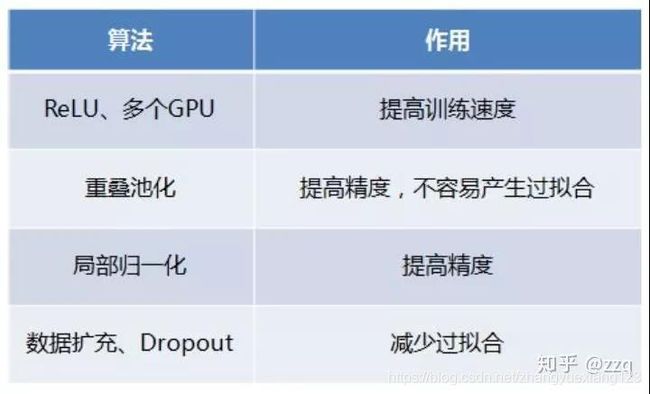
- 大量数据,Deep Learning领域应该感谢李飞飞团队搞出来如此大的标注数据集合ImageNet;
- GPU,这种高度并行的计算神器确实助了洪荒之力,没有神器在手,Alex估计不敢搞太复杂的模型;
- 算法的改进,包括网络变深、数据增强、ReLU、Dropout等。
网络模型命名规则
1.人名。LeNet以其作者名字LeCun命名,这种命名方式类似的还有AlexNet
2.机构名。GoogLeNet、VGG。
3.核心算法命名。ResNet。
最古老的的CNN
LeNet之前其实还有一个更古老的CNN模型。1985年,Rumelhart和Hinton等人提出了后向传播(Back Propagation,BP)算法[1](也有说1986年的,指的是他们另一篇paper:Learning representations by back-propagating errors),使得神经网络的训练变得简单可行,这篇文章在Google Scholar上的引用次数达到了19000多次。
几年后,LeCun利用BP算法来训练多层神经网络用于识别手写邮政编码[2],这个工作就是CNN的开山之作。
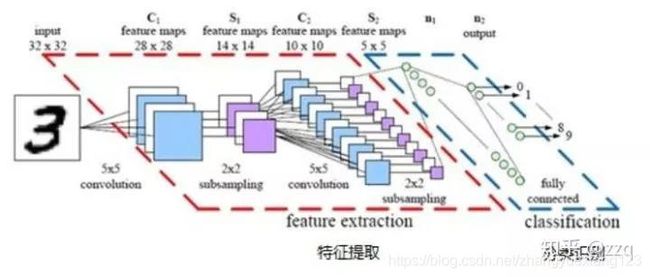
LeNet5
模型多处用到了5*5的卷积核,但在这篇文章中LeCun只是说把5*5的相邻区域作为感受野,并未提及卷积或卷积神经网络。关于CNN最原始的雏形感兴趣的读者也可以关注一下文献[3]。
LeNet5由两个卷积层,两个池化层,两个全连接层组成。卷积核都是5×5,stride=1,池化层使用maxpooling
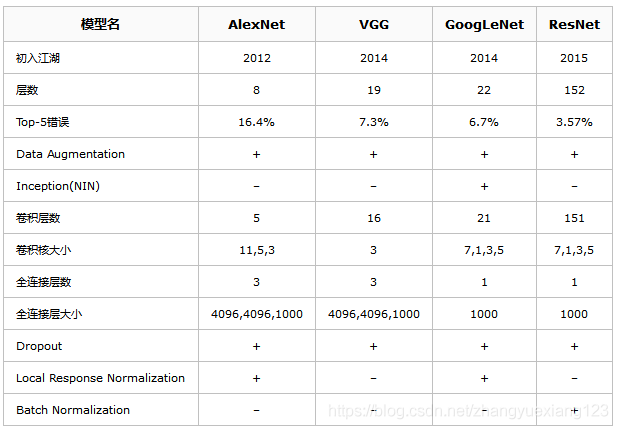
ILSVRC竞赛历年的佼佼者(AlexNet、VGG、GoogLeNet、ResNet)
下表具体比较AlexNet、VGG、GoogLeNet、ResNet四个模型。
AlexNet(2012)
模型共八层(不算input层),包含五个卷积层、三个全连接层。最后一层使用softmax做分类输出
AlexNet使用了ReLU做激活函数;防止过拟合使用dropout和数据增强;双GPU实现;使用LRN

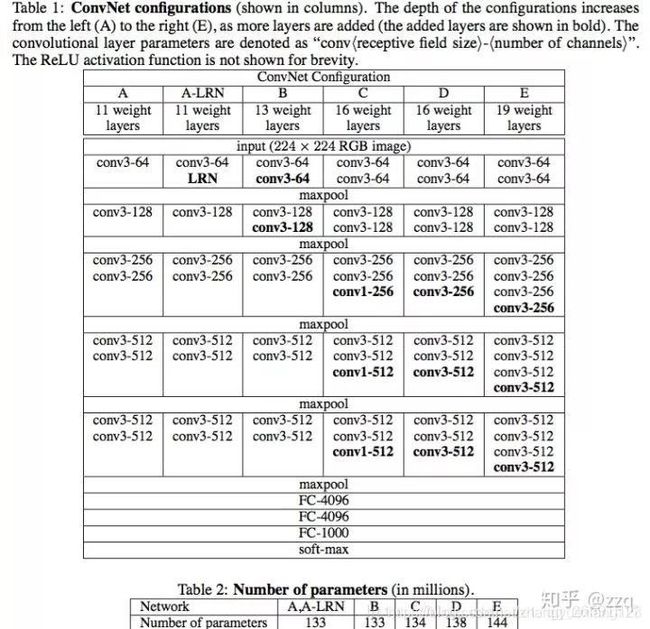
VGG(2014)
论文:《Very Deep Convolutional Networks for Large-scale Image Recognition》
论文链接:https://arxiv.org/pdf/1409.1556.pdf%20http://arxiv.org/abs/1409.1556.pdf
全部使用3×3卷积核的堆叠,来模拟更大的感受野,并且网络层数更深。VGG有五段卷积,每段卷积后接一层最大池化。卷积核数目逐渐增加。
总结:LRN作用不大;越深的网络效果越好;1×1的卷积也很有效但是没有3×3好
Network in network(2014)
论文:《Network In Network》
论文链接:https://arxiv.org/pdf/1312.4400.pdf
NiN是Shuicheng Yan组ICLR 2014的论文。
贡献
(1)提出在CONV3x3中插入CONV1x1层。(同等输入CONV1x1比CONV3x3参数数量少9倍,理论计算量降低9倍)
(2)提出Global Average Pooling (GAP)层。(GAP层没有参数,计算量可以忽略不计,是压缩模型的关键技术)
虽然论文并没有强调这两个组件对减小CNN体积的作用,但它们确实成为CNN压缩加速的核心。
MAP作用/好处

Resnet残差网络(2016)
论文:《Deep Residual Learning for Image Recognition》
手段:残差网络(Residual Network)[15]用跨层连接(Shortcut Connections)拟合残差项(Residual Representations)的手段来解决深层网络难以训练的问题。
实验结果:作者在ImageNet数据集上使用了一个152层的残差网络,深度是VGG网络的8倍但复杂度却更低,在ImageNet测试集上达到3.57%的top-5错误率,这个结果赢得了ILSVRC2015分类任务的第一名,另外作者还在CIFAR-10数据集上对100层和1000层的残差网络进行了分析。
网络对比:VGG19网络和ResNet34-plain及ResNet34-Redisual网络对比如下:

过拟合和退化问题:之前的经验已经证明,增加网络的层数会提高网络的性能,但增加到一定程度之后,随着层次的增加,神经网络的训练误差和测试误差会增大,这和过拟合还不一样,过拟合只是在测试集上的误差大,这个问题称为退化。
技术1:
为了解决这个问题,作者设计了一种称为深度残差网络的结构,这种网络通过跳层连接和拟合残差来解决层次过多带来的问题,这种做法借鉴了高速公路网络(Highway Networks)的设计思想,与LSTM有异曲同工之妙。这一结构的原理如下图所示:
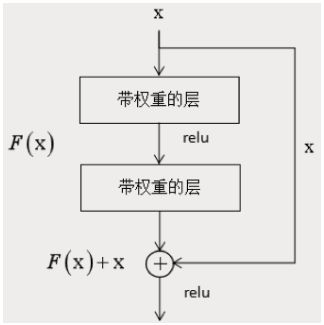
对应的代码:
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride技术2:
ResNet还采用了另一项常用技术:
- 用CONV/s2(步进2的卷积)代替MaxPool+CONV,将降低分辨率的Pool层合并之后通道数翻倍的CONV层,参数数量不变,省去了MaxPool的计算量。
ResNeXt(2017)
网络详解:https://blog.csdn.net/hejin_some/article/details/80743818
论文:Aggregated Residual Transformations for Deep Neural Networks
论文链接:https://arxiv.org/abs/1611.05431
PyTorch代码:https://github.com/miraclewkf/ResNeXt-PyTorch
ResNet和Inception结合体
基于ResNet和Inception的split+transform+concate结合。但效果却比ResNet、Inception、Inception-ResNet效果都要好。可以使用group convolution。
一般来说增加网络表达能力的途径有三种
1.增加网络深度,如从AlexNet到ResNet,但是实验结果表明由网络深度带来的提升越来越小;
2.增加网络模块的宽度,但是宽度的增加必然带来指数级的参数规模提升,也非主流CNN设计;
3.改善CNN网络结构设计,如Inception系列和ResNeXt等。且实验发现增加Cardinatity即一个block中所具有的相同分支的数目可以更好的提升模型表达能力。
谷歌系列 :Inception v1到v4(2015年-2017年)
网络模型的相关论文以及下载地址:
[v1] [2015 CVPR] [GoogLeNet / Inception-v1][Going Deeper with Convolutions][6.67% test error]
https://arxiv.org/abs/1409.4842
[v2] [2015 ICML] [BN-Inception / Inception-v2] [Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift][4.8% test error]
https://arxiv.org/abs/1502.03167
[v3] [2016 CVPR] [Inception-v3][Rethinking the Inception Architecture for Computer Vision][3.5% test error]
https://arxiv.org/abs/1512.00567
[v4][2017 AAAI] [Inception-v4][Inception-ResNet and the Impact of Residual Connections on Learning][3.08% test error]
https://arxiv.org/abs/1602.07261
CNN结构演化图:
图片参考
纯粹的增大网络的缺点:
//1.参数太多,容易过拟合,若训练数据集有限;
//2.网络越大计算复杂度越大,难以应用;
//3.网络越深,梯度越往后穿越容易消失(梯度弥散),难以优化模型Inception v1模型(2014)
论文:《Going Deeper with Convolutions》
论文链接:https://arxiv.org/pdf/1409.4842.pdf
模型命名:即是我们熟知的GoogleNet。
设计初衷:从VGG中我们了解到,网络层数越深效果越好。但是随着模型越深参数越来越多,这就导致网络比较容易过拟合,需要提供更多的训练数据;另外,复杂的网络意味更多的计算量,更大的模型存储,需要更多的资源,且速度不够快。GoogLeNet就是从减少参数的角度来设计网络结构的。
模型核心思想:GoogLeNet核心思想是通过增加网络宽度的方式来增加网络复杂度,让网络可以自己去应该如何选择卷积核。这种设计减少了参数 ,同时提高了网络对多种尺度的适应性。使用了1×1卷积可以使网络在不增加参数的情况下增加网络复杂度。
Inception v1的网络,将1x1,3x3,5x5的conv和3x3的pooling,堆叠在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性;
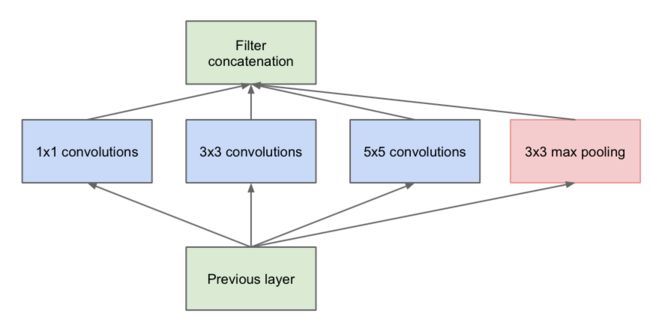

第一张图是论文中提出的最原始的版本,所有的卷积核都在上一层的所有输出上来做,那5×5的卷积核所需的计算量就太大了,造成了特征图厚度很大。为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低特征图厚度的作用,也就是Inception v1的网络结构。
小知识:GoogLeNet是谷歌(Google)研究出来的深度网络结构,为什么不叫“GoogleNet”,而叫“GoogLeNet”,据说是为了向“LeNet”致敬,因此取名为“GoogLeNet”
GoogLeNet的模型参数详细如下:

GoogLeNet的结构模型如下:

需要注意的是,为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,实际测试的时候,这两个额外的softmax会被去掉。
Inception v2模型(BN-Inception)(2015)
论文:《Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift》
论文链接:https://arxiv.org/pdf/1502.03167.pdf%E7%9A%84paper%E9%80%82%E5%90%88%E6%83%B3%E6%B7%B1%E5%85%A5%E4%BA%86%E8%A7%A3%E5%8E%9F%E7%90%86%EF%BC%8C%E8%BF%99%E4%B8%AA%E8%A7%86%E9%A2%91%E5%BE%88%E6%B8%85%E6%A5%9A%E7%9A%84%E8%AE%B2%E4%BA%86bn%E8%B5%B7%E5%88%B0%E7%9A%84%E4%BD%9C%E7%94%A8%E3%80%82
与Inception V1区别
(1)在v1的基础上加入batch normalization技术,在tensorflow中,使用BN在激活函数之前效果更好;
(2)将5×5卷积替换成两个连续的3×3卷积,使网络更深,参数更少
参考博客:https://mp.csdn.net/postedit/86653765
深度网络为什么难训练?
因为internal covariate shift。因此提出了一种改善该问题的机制(Batch Normalization(归一化,即固定每一层数据输入的均值和方差))。Batch Norm可谓深度学习中非常重要的技术,不仅可以使训练更深的网络变容易,加速收敛,还有一定正则化的效果,可以防止模型过拟合。
Q: 如果数据的分布不发生改变,真的会是的网络的训练变得更简单吗?
A: 首先,考虑机器学习领域中的一个很重要的假设:
- IID独立同分布假设:如果训练数据与测试数据满足相同的分布,那么通过神经网络训练出来的模型,能够在测试集上同样取得很好的效果。
- 同样,在训练的过程中,如果每一层的数据输入保持稳定的数据分布,那么对于网络的训练肯定是有帮助的。
- 在机器学习中,常用的数据处理的方法“白化操作”(whiten),例如PCA降维等方法,可以有效的提升机器学习的效果。而“白化操作”本质上,就是对输入数据的分布进行改变,使其变为均值为0,单位方差的正态分布。
- 从而,作者认为如果对每一层的数据输入,固定其分布,可定能够加快深度模型的训练。
BN的思想?
因为深层神经网络在做非线性变换前的激活输入值(就是那个 x=WU+B, U 是输入) 随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于 Sigmoid 函数来说,意味着激活输入值 WU+B 是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因, 而 BN 就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为 0 方差为 1 的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
经过 BN 后,目前大部分 Activation 的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
如果都通过 BN,那么不就跟把非线性函数替换成线性函数效果相同了?
如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。 所以 BN 为了保证非线性的获得,对变换后的满足均值为 0 方差为 1 的 x 又进行了 scale 加上 shift 操作(y=scale*x+shift),每个神经元增加了两个参数 scale 和 shift 参数,这两个参数是通过训练学习到的,意思是通过 scale 和 shift 把这个值从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。
Q:Batch Normalization带来了哪些好处?
(1)可以使用更高的学习率, BN 有快速收敛的特性。在没有加 Batch Normalization 的网络中我们要慢慢的调整学习率时,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适。现在,我们在网络中加入 Batch Normalization 时,可以采用初始化很大的学习率,然后学习率衰减速度也很大,因此这个算法收敛很快。
(2)模型中 BN 可以代替 dropout 或者使用较低的 dropout。 dropout 是经常用来防止过拟合的方法,但是模型中加入 BN 减少 dropout,可以大大提高模型训练速度,提高网络泛化性能。
(3)减少 L2 权重衰减系数。用了 Batch Normalization 后,可以把 L2 权重衰减系数降低,论文中降低为原来的 5 倍。
(4)取消 Loacl Response Normalization 层。(局部响应归一化是 Alexnet 网络用到的方法),因为 BN 本身就是一个归一化网络层。
(5) BN 本质上解决了反向传播过程中梯度消失的问题。 BN 算法对 Sigmoid 激活函数的提升非常明显,解决了困扰学术界十几年的 sigmoid 过饱和造成梯度消失的问题。在深度神经网络中,靠近输入的网络层在梯度下降的时候,得到梯度值太小,导致深层神经网络只有靠近输出层的那几层网络在学习。因为数据使用 BN 后,归一化的数据仅使用了 sigmoid 线性的部分。
(6)可以把训练数据彻底打乱。防止了每批训练的时候,某一个样本经常被挑选到。论文中指出这个操作可以提高 1%的精度。
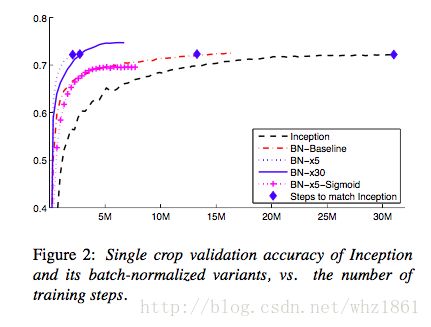
从图上可以看出,增加了BN操作后,Inception模型的效果都得到了提升,收敛速度都很快。
Inception v3模型(2016)
论文:《Rethinking the Inception Architecture for Computer Vision》
论文链接:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Szegedy_Rethinking_the_Inception_CVPR_2016_paper.pdf
Inception V3核心思想
核心思想是将卷积核分解成更小的卷积,如将7×7分解成1×7和7×1两个卷积核,使网络参数减少,深度加深。
Inception V3的目的
研究如何在增加网络规模的同时保证计算高效率,这篇论文中还提出了一些CNN调参的经验型规则。
Rethinking这篇论文中提出了一些CNN调参的经验型规则,暂列如下:
1. 避免特征表征的瓶颈。特征表征就是指图像在CNN某层的激活值,特征表征的大小在CNN中应该是缓慢的减小的。
2. 高维的特征更容易处理,在高维特征上训练更快,更容易收敛
3. 低维嵌入空间上进行空间汇聚,损失并不是很大。这个的解释是相邻的神经单元之间具有很强的相关性,信息具有冗余。
4. 平衡的网络的深度和宽度。宽度和深度适宜的话可以让网络应用到分布式上时具有比较平衡的computational budget。
Inception V3网络结构最大的变化
用了1*n结合n*1来代替n*n的卷积,结构如下:
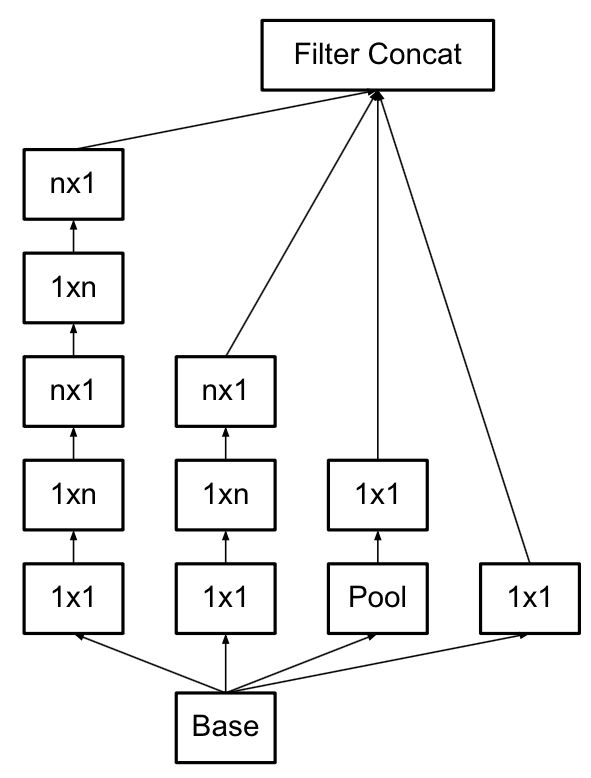
Inception V4(2017)
论文:《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》
论文链接:https://www.aaai.org/ocs/index.php/AAAI/AAAI17/paper/viewFile/14806/14311
Inception v4 和 Inception -ResNet 在同一篇论文《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》中介绍。为清晰起见,我们分成两个部分来介绍。
详情参考:https://www.jiqizhixin.com/articles/2018-05-30-7
网络说明:
Inception v4没有使用残差学习的思想,Inception v4基本延续了Inception v2/v3的结构。
出自同一篇论文的Inception-Resnet-v1和Inception-Resnet-v2才是Inception module与残差学习的结合产物。
Inception-ResNet和Inception v4网络结构都是基于Inception v3的改进。
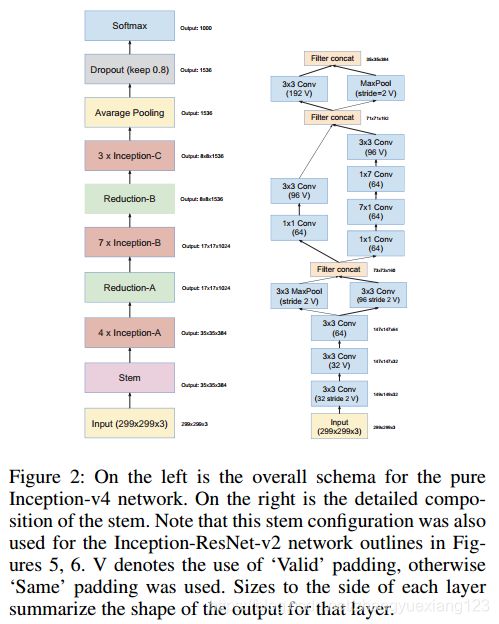
V4整个网络结构:
左图为Inception v4的网络结构,右图为Inception v4的Stem模块
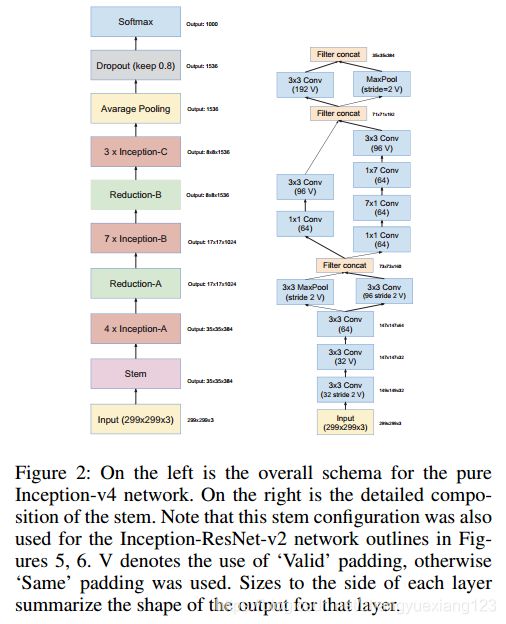
v4中的三个基本模块:

对上图进行说明:
1. 左图是基本的Inception v2/v3模块,使用两个3x3卷积代替5x5卷积,并且使用average pooling,该模块主要处理尺寸为35x35的feature map;
2. 中图模块使用1xn和nx1卷积代替nxn卷积,同样使用average pooling,该模块主要处理尺寸为17x17的feature map;
3. 右图在原始的8x8处理模块上将3x3卷积用1x3卷积和3x1卷积。
总的来说,Inception v4中基本的Inception module还是沿袭了Inception v2/v3的结构,只是结构看起来更加简洁统一,并且使用更多的Inception module,实验效果也更好。
Inception-ResNet系列(V1和V2)
本节将介绍和Inception v4同一篇文章的两个Inception-ResNet结构:Inception-Resnet-v1和Inception-Resnet-v2。
论文:《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》
博客:https://blog.csdn.net/zzc15806/article/details/83504130
残差连接是指浅层特征通过另外一条分支加到高层特征中,达到特征复用的目的,同时也避免深层网路的梯度弥散问题。下图为一个基本的残差结构:
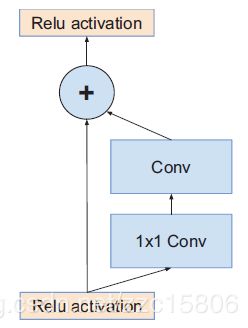
Inception-Resnet-v1
Inception-Resnet-v1内部网络的基本模块:
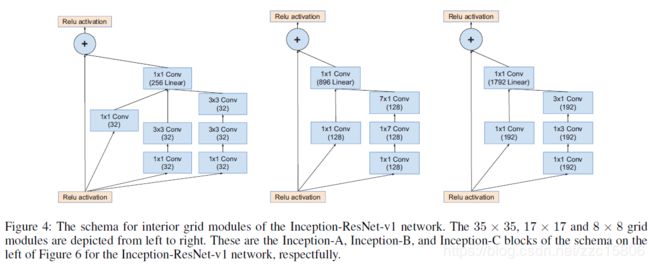
对上图进行说明:
1. Inception module都是简化版,没有使用那么多的分支,因为identity部分(直接相连的线)本身包含丰富的特征信息;
2. Inception module每个分支都没有使用pooling;
3. 每个Inception module最后都使用了一个1x1的卷积(linear activation),作用是保证identity部分和Inception部分输出特征维度相同,这样才能保证两部分特征能够相加。
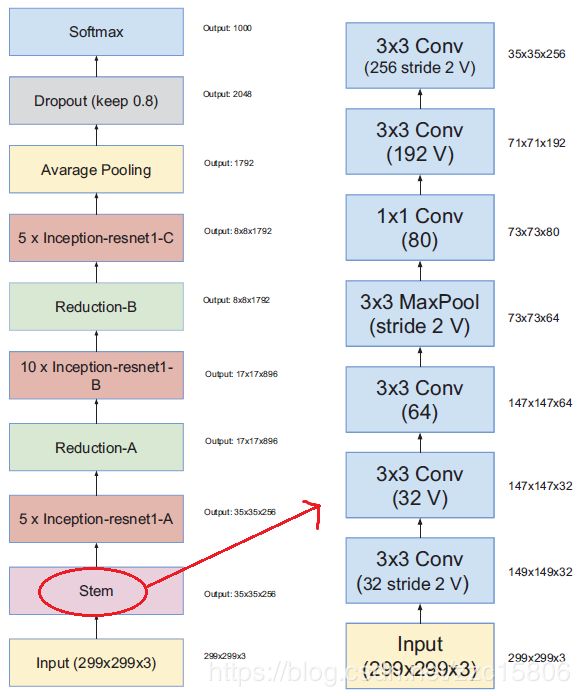
Inception-Resnet-v1网络结构(左),右图为Inception-Resnet-v1的Stem模块:
Inception-Resnet-v2
Inception-Resnet-v2基本模块:
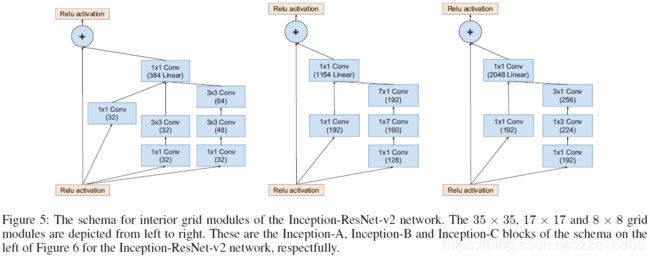
Inception-Resnet-v2网络结构同Inception-Resnet-v1(如上上图左侧图所示),Stem模块同Inception v4(如下图右侧图所示)。
ResNeXt(2017)
论文:Aggregated Residual Transformations for Deep Neural Networks
论文链接:https://arxiv.org/abs/1611.05431
PyTorch代码:https://github.com/miraclewkf/ResNeXt-PyTorch
博客:https://blog.csdn.net/hejin_some/article/details/80743818
提出ResNeXt的原因:
传统模型要提高准确率,都是加深或加宽网络,但是随着超参数数量的增加(比如channels数,filter size等等),网络设计的难度和计算开销也会增加。为了解决上述问题,提出 ResNeXt 结构。在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量(得益于子模块的拓扑结构一样,后面会讲)。
ResneXt与VGG和Inception的互鉴:
作者在论文中提到,VGG主要采用堆叠网络来实现,之前的 ResNet 也借用了这样的思想。然后提到 Inception 系列网络,简单讲Inception就是 split-transform-merge 的策略,但是 Inception 系列网络有个问题:网络的超参数设定的针对性比较强,当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。
重点来了:
作者提出的 ResNeXt网络,同时采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,但是可扩展性比较强,可以认为是在增加准确率的同时基本不改变或降低模型的复杂度。
名词解释cardinality:
原文的解释是the size of the set of transformations,如下图 Fig1 右边是 cardinality=32 的样子,这里注意每个被聚合的拓扑结构都是一样的(这也是和 Inception 的差别,减轻设计负担)

ResNeXt优越性佐证1:
附上原文比较核心的一句话,点明了增加 cardinality 比增加深度和宽度更有效,这句话的实验结果在后面有展示:

ResNeXt优越性佐证2:

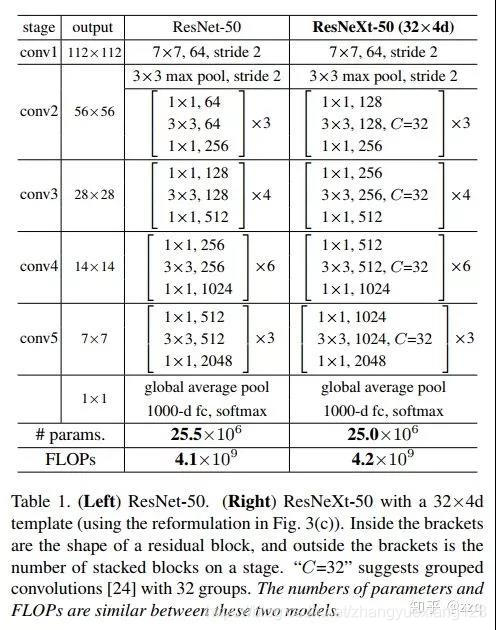
Table1 列举了 ResNet-50 和 ResNeXt-50 的内部结构.
附:最后两行说明二者之间的参数复杂度差别不大。

接下来作者要开始讲本文提出的新的 block,举全连接层(Inner product)的例子来讲,我们知道全连接层的就是以下这个公式:

再配上这个图就更容易理解其splitting,transforming和aggregating的过程。

然后作者的网络其实就是将其中的 wixi替换成更一般的函数,这里用了一个很形象的词:Network in Neuron,式子如下:

其中C就是 cardinality,Ti有相同的拓扑结构(本文中就是三个卷积层的堆叠)。
然后看看fig 3。这里作者展示了三种相同的 ResNeXt blocks。fig3.a 就是前面所说的aggregated residual transformations。 fig3.b 则采用两层卷积后 concatenate,再卷积,有点类似 Inception-ResNet,只不过这里的 paths 都是相同的拓扑结构。fig 3.c采用的是grouped convolutions,这个 group 参数就是 caffe 的 convolusion 层的 group 参数,用来限制本层卷积核和输入 channels 的卷积,最早应该是 AlexNet 上使用,可以减少计算量。这里 fig 3.c 采用32个 group,每个 group 的输入输出 channels 都是4,最后把channels合并。这张图的 fig3.c 和 fig1 的左边图很像,差别在于fig3.c的中间 filter 数量(此处为128,而fig 1中为64)更多。作者在文中明确说明这三种结构是严格等价的,并且用这三个结构做出来的结果一模一样,在本文中展示的是 fig3.c 的结果,因为 fig3.c 的结构比较简洁而且速度更快。

表2列举了一些参数,来说明 fig1 的左右两个结构的参数复杂度差不多。第二行的d表示每个path的中间channels数量,最后一行则表示整个block的宽度,是第一行C和第二行d的乘积。
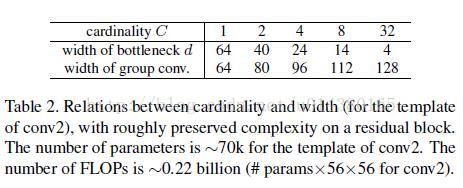
在实验中作者说明ResNeXt和ResNet-50/101的区别仅仅在于其中的block,其他都不变。
贴一下作者的实验结果:
相同层数的ResNet和ResNeXt的对比:(32*4d表示32个paths,每个path的宽度为4,如fig3)。实验结果表明ResNeXt和ResNet的参数复杂度差不多,但是其训练误差和测试误差都降低了。

另一个实验结果的表格,主要说明增加Cardinality和增加深度或宽度的区别。
增加宽度就是简单地增加filter channels。
第一个是基准模型,增加深度和宽度的分别是第三和第四个,可以看到误差分别降低了0.3%和0.7%。但是第五个加倍了Cardinality,则降低了1.3%,第六个Cardinality加到64,则降低了1.6%。显然增加Cardianlity比增加深度或宽度更有效。
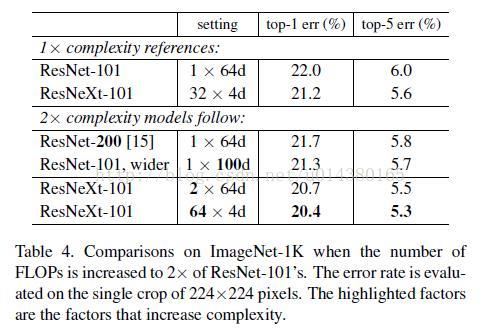
接下来这个表一方面证明了residual connection的有效性,也证明了aggregated transformations的有效性,控制变量的证明方式,比较好理解。

全文看下来,作者的核心创新点就在于提出了 aggregrated transformations,用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
Xception(2017)
https://imlogm.github.io/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/inception/
基本思想
在Inception-v3的基础上提出,基本思想是通道分离式卷积,但是又有区别。模型参数稍微减少,但是精度更高。
设计目的
Xception的目标是设计出易迁移、计算量小、能适应不同任务,且精度较高的模型。
基本步骤
Xception先做1×1卷积再做3×3卷积,即先将通道合并,再进行空间卷积。depthwise正好相反,先进行空间3×3卷积,再进行通道1×1卷积。核心思想是遵循一个假设:卷积的时候要将通道的卷积与空间的卷积进行分离。而MobileNet-v1用的就是depthwise的顺序,并且加了BN和ReLU。Xception的参数量与Inception-v3相差不大,其增加了网络宽度,旨在提升网络准确率,而MobileNet-v1旨在减少网络参数,提高效率。
Xception与Inception-v3在结构上有什么差别?
如图1为Inception-v3的模块结构,依据化繁为简的思想,把模块结构改造为图2。
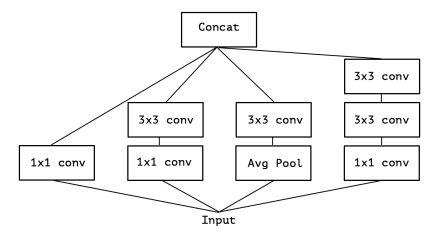 图1
图1
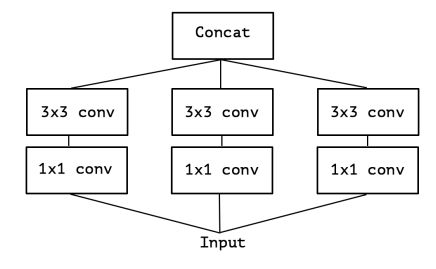 图2
图2
依据depthwise separable convolution的思想,可以进一步把图2改造到图3。
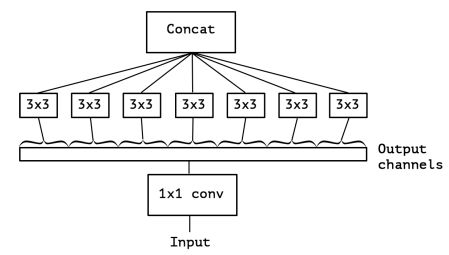 图3
图3

什么是depthwise separable convolution呢?MobileNet等网络为了减少计算量都有用到这个方法,不过Xception在这里的用法和一般的depthwise separable convolution还有点不同,所以为了防止大家搞糊涂,我就不介绍一般性的用法了,直接介绍Xception中的用法。
对于112×112×64的输入做一次普通的3×3卷积,每个卷积核大小为3×3×64,也就是说,每一小步的卷积操作是同时在面上(3×3的面)和深度上(×64的深度)进行的。
那如果把面上和深度上的卷积分离开来呢?这就是图3所要表达的操作。依旧以112×112×64的输入来作例子,先进入1×1卷积,每个卷积核大小为1×1×64,有没有发现,这样每一小步卷积其实相当于只在深度上(×64的深度)进行。
然后,假设1×1卷积的输出为112×112×7,我们把它分为7份,即每份是112×112×1,每份后面单独接一个3×3的卷积(如图3所示,画了7个3×3的框),此时每个卷积核为3×3×1,有没有发现,这样每一小步卷积其实相当于只在面上(3×3的面)进行。
最后,把这7个3×3的卷积的输出叠在一起就可以了。根据Xception论文的实验结果,Xception在精度上略低于Inception-v3,但在计算量和迁移性上都好于Inception-v3。
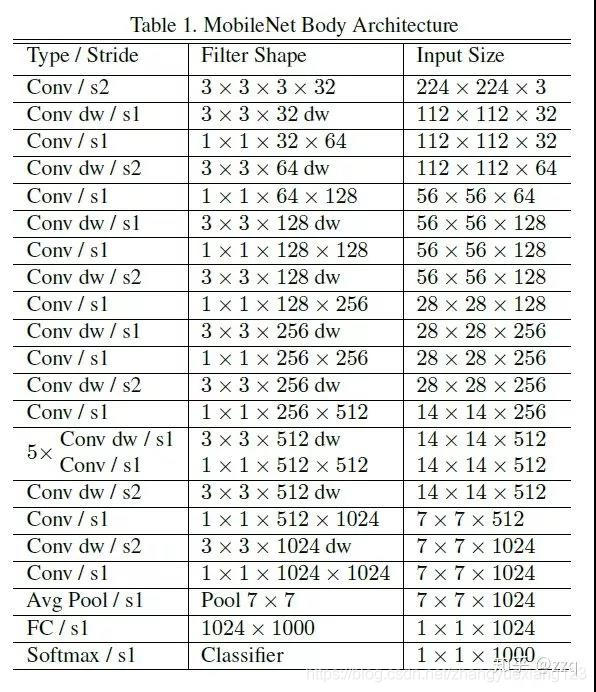
MobileNet V1(2017)
《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision》
来自CVPR2017,由Google团队提出
代码链接:https://github.com/Zehaos/MobileNet
V1创新点总括
使用depthwise separable convolutions;放弃pooling层,而使用stride=2的卷积。标准卷积的卷积核的通道数等于输入特征图的通道数;而depthwise卷积核通道数是1;还有两个参数可以控制,a控制输入输出通道数;p控制图像(特征图)分辨率。
V1创新点详解
https://blog.csdn.net/derteanoo/article/details/81160521
假设输入为Df*Df*M,卷积核为Dk*Dk*N,传统卷积计算量为Df*Df*M*Dk*Dk*N。mobilenet采用深度可分离卷积(depthwise separable concolution),将其分为深度卷积和1*1的卷积(如下图所示),深度卷积的卷积核个数与输入的通道数相同,1*1卷积核用来改变输出通道数,计算量分别为Dk*Dk*M*DF*DF和M*N*DF*DF,实现了spatial与channels间的解耦,减少了计算量。
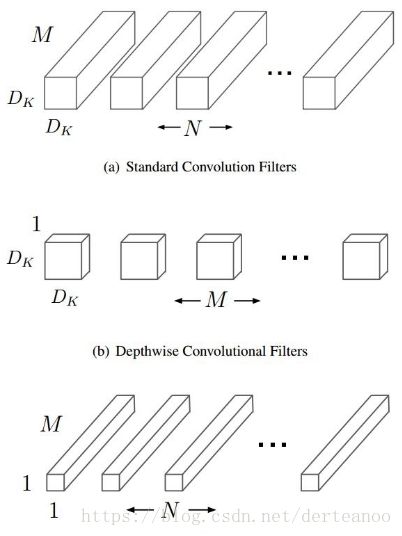
能够减少参数数量和计算量的原理
https://blog.csdn.net/mzpmzk/article/details/82976871#_3
(1)变化1:使用深度可分离卷积(Depthwise separable convolution)
组成:Depthwise separable convolution are made up of two layers: depthwise convolutions and pointwise convolutions。
特征提取:depthwise convolution时只使用了一种维度为in_channels的卷积核进行特征提取(没有进行特征组合)。
特征组合:pointwise convolution时只使用了output_channels维度为in_channels 1*1 的卷积核进行特征组合。普通卷积不同 depth 层的权重是按照 1:1:1…:1的比例进行相加的,而在这里不同 depth 层的权重是按照 不同比例(可学习的参数) 进行相加的。
参数量:参数数量由原来的p1 = F*F*in_channels*output_channels 变为了p2 = F*F*in_channels*1 + 1*1*in_channels*output_channels,减小为原来的p2/p1 = 1/output_channels + 1/F*F,其中 F 为卷积核的尺寸,若 F=3,参数量大约会减少到原来的 1/8→1/9。
论文中上述参数量前后变化的写法:

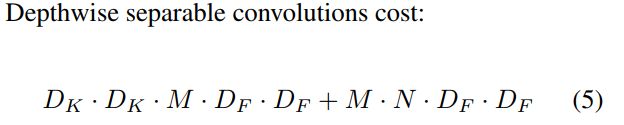
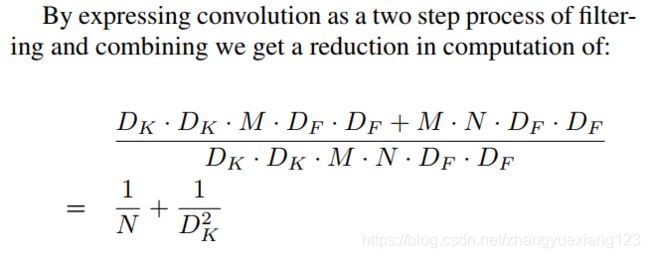
Note: 原论文中对第一层没有用此卷积,深度可分离卷积中的每一个后面都跟 BN 和 RELU。

(2)变化2:用 CONV/s2(步进2的卷积)代替 MaxPool+CONV:使得参数数量不变,计算量变为原来的 1/4 左右,且省去了MaxPool 的计算量。
Note:采用 depth-wise convolution 会有一个问题,就是导致信息流通不畅 ,即输出的 feature map 仅包含输入的 feature map 的一部分,在这里,MobileNet 采用了 point-wise(1*1) convolution 帮助信息在通道之间流通。
(3)变化3:论文提供了两个用户定制参数
https://zhuanlan.zhihu.com/p/37074222

框架图
标准卷积和深度可分离卷积的区别
上面右图也证明了(2)中的Note结论,即:
采用 depth-wise convolution 会有一个问题,就是导致信息流通不畅 ,即输出的 feature map 仅包含输入的 feature map 的一部分,在这里,MobileNet 采用了 point-wise(1*1) convolution 帮助信息在通道之间流通。
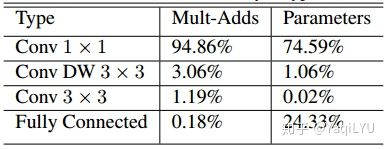
MobileNet的弊端,为以后ShuffleNet提出奠定基础
https://zhuanlan.zhihu.com/p/37074222
论文统计了不同类型层的计算量和参数数量,仅一个CONV一个FC,计算量可以忽略,前面也提到FC层参数占比较大,重点关注,大量使用的![]() 计算量仅3%,参数数量仅1%,其貌不扬的CONV1x1竟然是罪魁祸首,CONV1x1计算量占95%,参数数量占75%,所以MobileNet速度快不快,与inferece framework中CONV1x1的优化程度密切相关。
计算量仅3%,参数数量仅1%,其貌不扬的CONV1x1竟然是罪魁祸首,CONV1x1计算量占95%,参数数量占75%,所以MobileNet速度快不快,与inferece framework中CONV1x1的优化程度密切相关。
Block分析:MobileNet虽然没有明确指出,Depthwise Separable Convolution也可以看做block
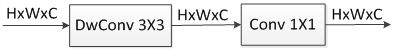

TensorFlow 中的代码实现
可使用 tensorflow 中的tf.nn.separable_conv2d() 来实现, 参数depthwise_filter中的 channel_multiplier 设为 1 即可。
# 使用 slim 来实现
def _depthwise_separable_conv(inputs,
num_pwc_filters,
kernel_width,
phase,
sc,
padding='SAME',
width_multiplier=1,
downsample=False):
""" Helper function to build the depth-wise separable convolution layer.
"""
num_pwc_filters = round(num_pwc_filters * width_multiplier)
_stride = 2 if downsample else 1
# skip pointwise by setting num_outputs=None
depthwise_conv = slim.separable_convolution2d(inputs,
num_outputs=None,
stride=_stride,
depth_multiplier=1,
kernel_size=[kernel_width, kernel_width],
padding=padding,
activation_fn=None,
scope=sc + '/depthwise_conv')
bn = slim.batch_norm(depthwise_conv, activation_fn=tf.nn.relu, is_training=phase, scope=sc + '/dw_batch_norm')
pointwise_conv = slim.convolution2d(bn,
num_pwc_filters,
kernel_size=[1, 1],
activation_fn=None,
scope=sc + '/pointwise_conv')
bn = slim.batch_norm(pointwise_conv, activation_fn=tf.nn.relu, is_training=phase, scope=sc + '/pw_batch_norm')
return bnCaffe 中的代码实现
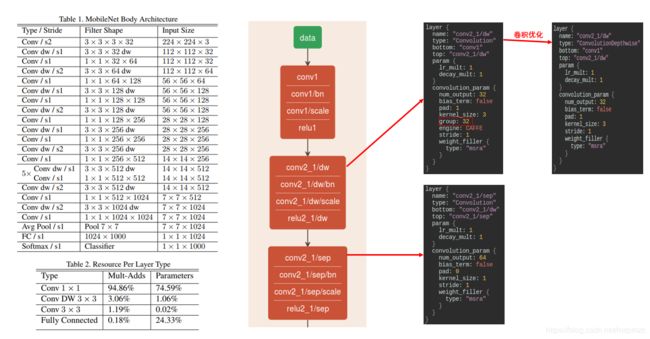
Densenet(2017)
论文:《Densely Connected Convolutional Networks》
原文链接:https://arxiv.org/pdf/1608.06993.pdf
代码链接:https://github.com/liuzhuang13/DenseNet
https://github.com/miraclewkf/DenseNet
CVPR 2017最佳论文,作者是康奈尔大学博士后黄高博士、清华大学本科生刘壮、Facebook 人工智能研究院研究科学家 Laurens van der Maaten 及康奈尔大学计算机系教授 Kilian Q. Weinberger
创新点
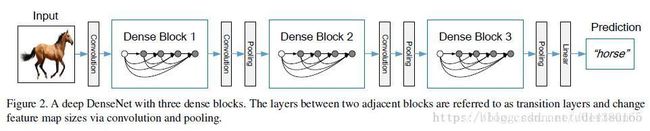
(1)采用DenseBlock的结构。如图,将网络中所有层都连起来,每一层的输入来自前面所有层的输出,保证网络中信息的最大传递,和RNN的感觉类似。这样,一减轻了vanishing-gradient(梯度消失)(梯度消失的原因是由于梯度信息在很多层之间传递所以丢失),二加强了feature的传递 ,三更有效地利用了feature ,四每一层的通道数更窄(小于100),一定程度上较少了参数数量,因此过拟合现象也会减轻。

每个Densenet由多个dense block组成,每个dense block的feature map的size一样,便于concat。
(2)DenseBlock的输入开始,频繁使用Bottleneck Layer先进行降维,以减少feature map的层数。在两个Dense Block中间,使用transition layer,通过设置参数reduction(范围是0到1),用1*1的卷积核以一定比例进行降维。
(3)Densenet在concat过程会重新开辟内存,因此很占显存,可以通过共享内存的方式去优化部署。
EffNet(2018)
EffNet是对MobileNet-v1的改进,主要思想
将MobileNet-1的dw层分解层两个3×1和1×3的dw层,这样 第一层之后就采用pooling,从而减少第二层的计算量。EffNet比MobileNet-v1和ShuffleNet-v1模型更小,进度更高。


mobilenet-v2(2018)
博客:https://zhuanlan.zhihu.com/p/37919669
《mobilenet-v2:Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation》
论文链接:https://arxiv.org/abs/1801.04381
代码链接:https://github.com/miraclewkf/MobileNetV2-PyTorch
https://github.com/suzhenghang/MobileNetv2/tree/master/.gitignore
https://github.com/austingg/MobileNet-v2-caffe
降低DWCONV-bottleneck block中CONV1x1的占比,除了ShuffleNet和IGCV2用GCONV+shuffle/permutation方法,还有其他好办法吗?MobileNet采用了两种新技术来解决这个问题,按照论文来说,即创新点如下:
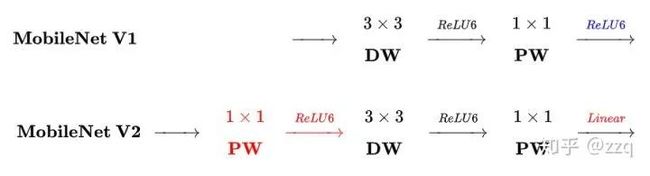
相比于Mobilenet-V1的三点不同总括:
1.引入了残差结构;
2.在dw之前先进行1×1卷积增加feature map通道数,与一般的residual block是不同的;
3.pointwise结束之后弃用ReLU,改为linear激活函数,来防止ReLU对特征的破环。这样做是因为dw层提取的特征受限于输入的通道数,若采用传统的residual block,先压缩那dw可提取的特征就更少了,因此一开始不压缩,反而先扩张。但是当采用扩张-卷积-压缩时,在压缩之后会碰到一个问题,ReLU会破环特征,而特征本来就已经被压缩,再经过ReLU还会损失一部分特征,应该采用linear。
Mobilenet-V2创新点详解
(1)Inverted Residuals 逆残差。把原来两头大中间小的bottleneck block变成两头小中间大的形式,强行降低了CONV1x1与DWCONV3x3的比例,这里有个超参数expansion factor扩展因子t,推荐是5~10。小网络使用小的扩张系数(expansion factor),大网络使用大一点的扩张系数(expansion factor),推荐是5~10,论文中 t=6。
Inverted residual block使用 RELU6(最高输出为 6)激活函数,使得模型在低精度计算下具有更强的鲁棒性。
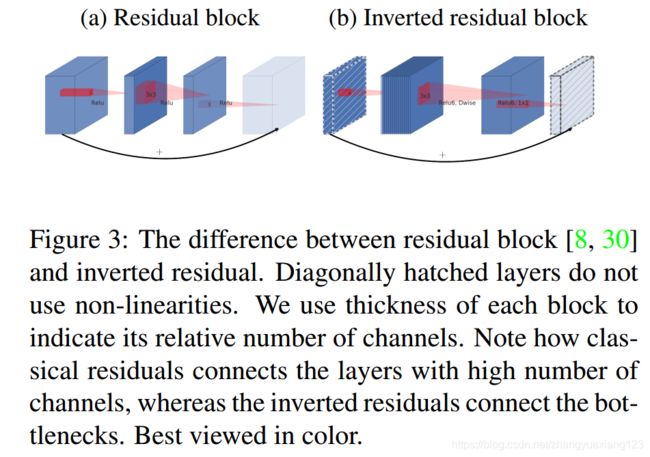
原文对此模块解释:

(2)Linear Bottlenecks 线性瓶颈:去掉了第二个CONV1x1后面的ReLU,改为线性神经元,其实就是没有非线性激活函数,论文解释是在低维度空间ReLU会破坏信息。

网络优化
bottleneck的输出通道数非常小[24 32 64-96 160-320],这在以前的结构中容量是远远不够的。再来看经expand layer扩展以后的DWCONV3x3层,baseline版本通道数是[144 192 384-576 960-1920],比较接近ShuffleNetx2的配置,略高于V1,从这个角度来看,MobileNetV2设计上是保持DWCONV3x3层通道数基本不变或轻微增加,将bottleneck的输入和输出通道数直接减小t倍,扩展因子其实更像是压缩因子,将CONV1x1层的参数数量和计算量直接减小t倍,轻微增加DWCONV3x3的通道数以保证的网络容量。ShuffleNet中标准卷积更多、深度分离卷积更少的优化思路完全相反,MobileNetV2中标准卷积更少、深度分离卷积更多(相对的,计算量占比CONV1x1依然绝对优势)。
- baseline版本MobileNetV2,参数数量3.4M,计算量300M,top-1 72%,这个理论计算量与SqueezeNet是同一等级,比MobileNetV1更好更小更快
- MobileNetV2-1.4版本(1.4**2=1.96,大约是baseline的2倍)参数数量6.9M,计算量585M,top-1 74.7%,这个计算量与1.0-MobileNet-224和ShuffleNetx2g3同一等级,性能超过ShuffleNet 1%
- 甚至超过了NASNet,是目前最好的高效小网络结构,更重要的是开源了模型和代码,github上有各个平台的模型复现
结构方面,每个bottleneck里面两个ReLU6,方便量化;输入图像以s2方式逐阶平滑降维;用户定制依然是宽度乘子和分辨率乘子,同MobileNetV1;通道数量分布前期少后期多,在14x14和7x7阶段通道数量额外增加了一次,分别上升50%和100%。
ncnn-benchmark中MobileNetV2是caffe复现的baseline,但由于标准卷积比深度分离卷积优化更好,且CONV3x3比CONV1x1优化更好,导致部分ARM上MobileNetV2与MobileNet速度接近,但性能差距还是存在的,期待进一步优化后能接近SqueezeNetv1.1速度。
每个stage的通道数量:【24 32 64-96 160-320】*6
每个stage的block数量:【2 3 7 4】
Block分析:MobileNetV2 block,类似MobileNet没有加shotcut


MobileNetV2网络结构:

MobileNetV2和 MobileNetV1 的区别
https://zhuanlan.zhihu.com/p/33075914
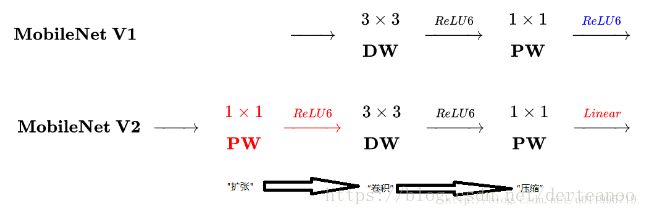
相同点
都采用 Depth-wise (DW) 卷积搭配 Point-wise (PW) 卷积的方式来提特征。这两个操作合起来也被称为 Depth-wise Separable Convolution,之前在 Xception 中被广泛使用。这么做的好处是理论上可以成倍的减少卷积层的时间复杂度和空间复杂度。由下式可知,因为卷积核的尺寸K通常远小于输出通道数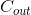 ,因此标准卷积的计算复杂度近似为DW+PW组合卷积的
,因此标准卷积的计算复杂度近似为DW+PW组合卷积的 ![]() 倍。
倍。

不同点:Linear Bottleneck
(1)V2 在 DW 卷积之前新加了一个 PW 卷积。这么做的原因,是因为 DW 卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以如果上一层给的通道数本身很少的话,DW 也只能很委屈的在低维空间提特征,因此效果不够好。现在 V2 为了改善这个问题,给每个 DW 之前都配备了一个 PW,专门用来升维,定义升维系数t=6,这样不管输入通道数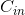 是多是少,经过第一个 PW 升维之后,DW 都是在相对的更高维
是多是少,经过第一个 PW 升维之后,DW 都是在相对的更高维 ![]() 进行着辛勤工作的。
进行着辛勤工作的。
(2)论文作者称其为 Linear Bottleneck。这么做的原因,是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于第二个 PW 的主要功能就是降维,因此按照上面的理论,降维之后就不宜再使用 ReLU6 了。
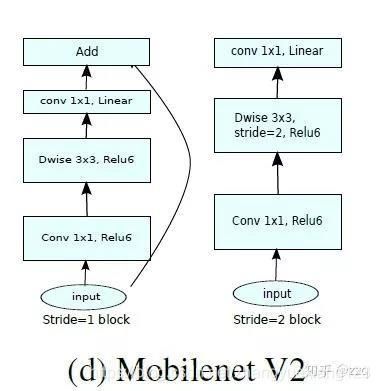
对比 MobileNet V2与ResNet 的微结构
https://zhuanlan.zhihu.com/p/33075914

Mobilenet-v3(2019)
论文:《Searching for mobilenetv3》
论文链接:https://arxiv.org/pdf/1905.02244.pdf
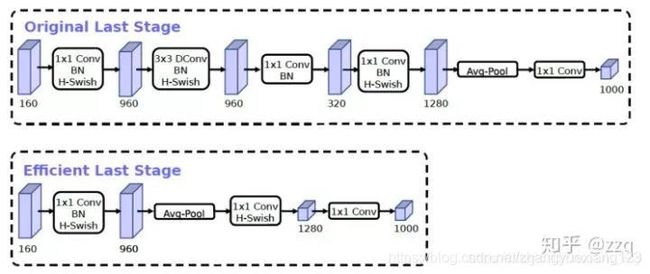
互补搜索技术组合:由资源受限的NAS执行模块集搜索,NetAdapt执行局部搜索;网络结构改进:将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数,修改了开始的滤波器组。
V3综合了v1的深度可分离卷积,v2的具有线性瓶颈的反残差结构,SE结构的轻量级注意力模型。


SqueezeNet(2017ICLR)
论文:《SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE》
论文链接:https://arxiv.org/pdf/1602.07360.pdf
详细参考:https://baijiahao.baidu.com/s?id=1589005428414488177&wfr=spider&for=pc
命名
从名字——SqueezeNet 就知道,本文的新意是 squeeze,squeeze 在 SqueezeNet 中表示一个 squeeze 层,该层采用 1*1 卷积核对上一层 feature map 进行卷积,主要目的是减少 feature map 的维数(维数即通道数,就是一个立方体的 feature map,切成一片一片的,一共有几片)。
创新点
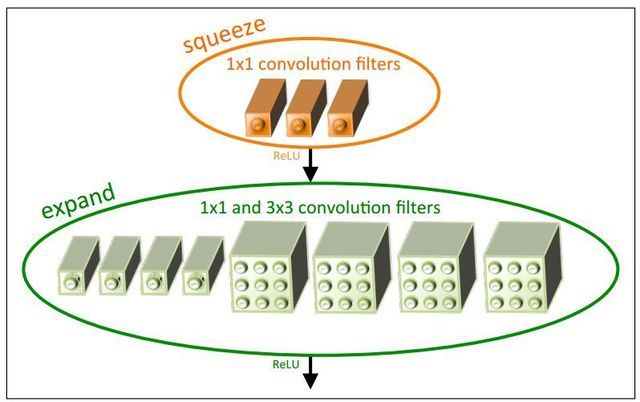
1. 采用不同于传统的卷积方式,提出 fire module;fire module 包含两部分:squeeze 层+expand 层
创新点与 inception 系列的思想非常接近!首先 squeeze 层,就是 1*1 卷积,其卷积核数要少于上一层 feature map 数,这个操作从 inception 系列开始就有了,并美其名曰压缩,个人觉得「压缩」更为妥当。
Expand 层分别用 1*1 和 3*3 卷积,然后 concat,这个操作在 inception 系列里面也有。
SqueezeNet 的核心在于 Fire module,Fire module 由两层构成,分别是 squeeze 层+expand 层,如下图 1 所示,squeeze 层是一个 1*1 卷积核的卷积层,expand 层是 1*1 和 3*3 卷积核的卷积层,expand 层中,把 1*1 和 3*3 得到的 feature map 进行 concat。
ShuffleNet V1(2018)
论文:《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices》
论文链接:http://openaccess.thecvf.com/content_cvpr_2018/papers/Zhang_ShuffleNet_An_Extremely_CVPR_2018_paper.pdf
详情参考:https://baijiahao.baidu.com/s?id=1589005428414488177&wfr=spider&for=pc
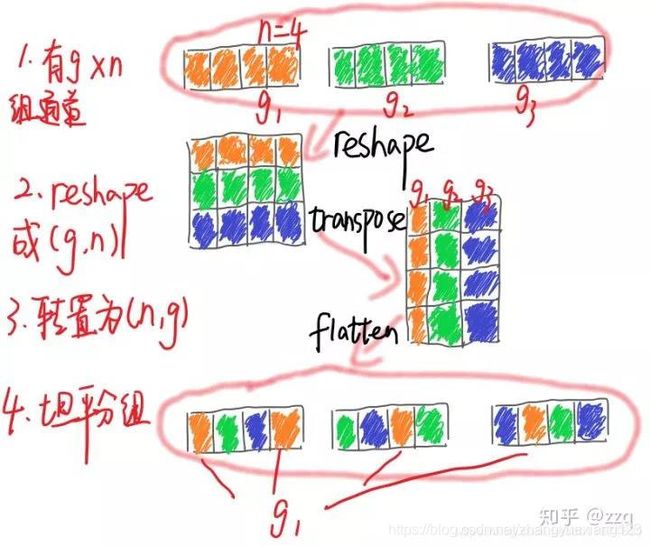
通过分组卷积与1×1的逐点群卷积核来降低计算量,通过重组通道来丰富各个通道的信息。Xception和ResNeXt在小型网络模型中效率较低,因为大量的1×1卷积很耗资源,因此提出逐点群卷积来降低计算复杂度,但是使用逐点群卷积会有副作用,故在此基础上提出通道shuffle来帮助信息流通。虽然dw可以减少计算量和参数量,但是在低功耗设备上,与密集的操作相比,计算、存储访问的效率更差,故shufflenet上旨在bottleneck上使用深度卷积,尽可能减少开销。
ShuffleNet V2(2018ECCV)
论文:《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design》
论文链接:http://openaccess.thecvf.com/content_ECCV_2018/papers/Ningning_Light-weight_CNN_Architecture_ECCV_2018_paper.pdf
详情参考:https://baijiahao.baidu.com/s?id=1589005428414488177&wfr=spider&for=pc
使神经网络更加高效的CNN网络结构设计准则:
输入通道数与输出通道数保持相等可以最小化内存访问成本
分组卷积中使用过多的分组会增加内存访问成本
网络结构太复杂(分支和基本单元过多)会降低网络的并行程度
element-wise的操作消耗也不可忽略

SENet(2018)
论文:《Squeeze-and-Excitation Networks》
论文链接:https://arxiv.org/abs/1709.01507
代码地址:https://github.com/hujie-frank/SENet
PyTorch代码地址:https://github.com/miraclewkf/SENet-PyTorch
详情参考:http://www.sohu.com/a/303625107_500659
https://blog.csdn.net/weixin_41923961/article/details/88983505
SKNet(2019CVPR)
《Selective Kernel Networks》
论文:https://arxiv.org/pdf/1903.06586.pdf
代码:https://github.com/implus/SKNet
详情参考:https://cloud.tencent.com/developer/article/1420865
https://blog.csdn.net/qixutuo6087/article/details/88822428
博客参考
深入浅出——网络模型中Inception的作用与结构全解析:https://blog.csdn.net/u010402786/article/details/52433324
Inception in CNN:https://blog.csdn.net/stdcoutzyx/article/details/51052847
Inception-v3:"Rethinking the Inception Architecture for Computer Vision":https://blog.csdn.net/cv_family_z/article/details/50789805
论文笔记 | Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning:https://blog.csdn.net/bea_tree/article/details/51784026
谈谈Tensorflow的Batch Normalization:https://www.jianshu.com/p/0312e04e4e83
TensorFlow中文社区:http://www.tensorfly.cn/tfdoc/api_docs/python/nn.html
什么是批标准化 (Batch Normalization):https://zhuanlan.zhihu.com/p/24810318
深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读:http://www.dataguru.cn/article-13532-1.html
大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进:https://my.oschina.net/u/876354/blog/1637819
参考文献
[1] DE Rumelhart, GE Hinton, RJ Williams, Learning internal representations by error propagation. 1985 – DTIC Document.
[2] Y. LeCun , B. Boser , J. S. Denker , D. Henderson , R. E. Howard , W. Hubbard and L. D. Jackel, “Backpropagation applied to handwritten zip code recognition”, Neural Computation, vol. 1, no. 4, pp. 541-551, 1989.
[3] K. Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4): 93-202, 1980.