TensorFlow搭建VGG-Siamese网络
TensorFlow搭建VGG-Siamese网络
- Siamese原理
Siamese网络,中文称为孪生网络。大致结构如下图所示: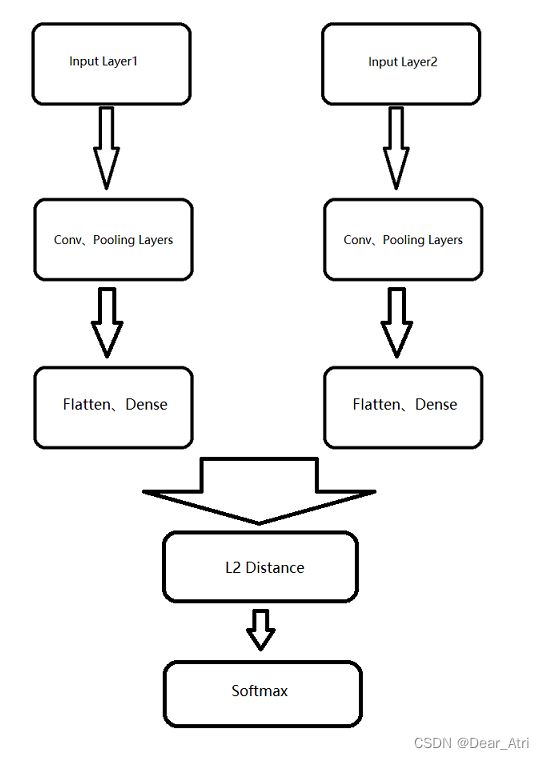
Siamese网络有两个输入,一个输出。其中,两个输入经过相同的网络层知道成为一个n维向量,再对这个n维向量进行求距离,对此距离应用softmax函数,得到输出的结果。
例如,使用Siamese做一个人脸识别,那么输入就是两个人脸图像,若是同一个人输出1,若是不同的人则输出0。
首先,我们制作一个输入为(h, w, c),输出为(1, 128)的VGG模型,这里不使用完整的模型,我称为VGG-lite版。
import tensorflow as tf
from tensorflow import keras
from keras import backend as K
from tensorflow.keras import layers, Sequential
from tensorflow.keras.layers import Conv2D, ZeroPadding2D, Activation, MaxPooling2D, Dropout, Flatten, Dense, Lambda, Input
from tensorflow.keras.models import Model
# 这里实现一个VGG网络,返回的是一个128维向量,用于siamese的输入
def VGG(X_input):
X = X_input
X = Conv2D(64, (3,3), padding = 'same',activation='relu')(X)
X = Conv2D(64, (3,3), padding = 'same',activation='relu')(X)
X = MaxPooling2D(pool_size=(2,2), strides=2)(X)
X = Conv2D(128, (3,3), padding = 'same',activation='relu')(X)
X = Conv2D(128, (3,3), padding = 'same',activation='relu')(X)
X = Dropout(0.4)(X)
X = MaxPooling2D(pool_size=(2,2), strides=2)(X)
X = Conv2D(256, (3,3), padding = 'same',activation='relu')(X)
# X = MaxPooling2D(pool_size=(2,2), strides=2)(X)
X = Conv2D(256, (3,3), padding = 'same',activation='relu')(X)
X = Conv2D(256, (3,3), padding = 'same',activation='relu')(X)
X = Dropout(0.4)(X)
X = MaxPooling2D(pool_size=(2,2), strides=2)(X)
X = Conv2D(512, (3,3), padding = 'same',activation='relu')(X)
X = MaxPooling2D(pool_size=(2,2), strides=2)(X)
X = Conv2D(512, (3,3), padding = 'same',activation='relu')(X)
X = Conv2D(512, (3,3), padding = 'same',activation='relu')(X)
X = Dropout(0.4)(X)
X = MaxPooling2D(pool_size=(2,2), strides=2)(X)
X = Flatten()(X)
X = Dense(1024, activation="relu")(X)
X = Dense(128, activation="relu")(X)
X = Lambda(lambda x: K.l2_normalize(x,axis=1))(X)
return X
这里对模型不再详细解释,只解释下对X的最后一步操作:通过keras.layers中的Lambda将128维的X进行L2正则化再输出。
对于模型构建其他部分的疑问,可以参考我的前两份文章。
接下来,我们要制作一个可以接受两个输入的模型。在TensorFlow中,只需要在定义模型的函数中,使用多次Input()即可获得多个输入。
def VGG_Siamese(input_shape):
# 接收两个输入,X1_input和X2_input.
X1_input = Input(input_shape)
X2_input = Input(input_shape)
X1 = ZeroPadding2D((3, 3), name='layer1')(X1_input)
X2 = ZeroPadding2D((3, 3), name='layer2')(X2_input)
X1 = VGG(X1)
X2 = VGG(X2)
print(X1)
print(X2)
l1_distance_layer = Lambda(
lambda tensors: K.abs(tensors[0] - tensors[1]))
l1_distance = l1_distance_layer([X1, X2])
X = Dense(512, activation='relu')(l1_distance)
X = Dense(2, activation='softmax')(X)
model = Model(inputs = [X1_input, X2_input], outputs = X)
return model
在使用Input()获得两个输入后,将两个输入一同经过了VGG()函数,这说明两个输入会经历相同的卷积网络成为两个128维向量。而
l1_distance_layer = Lambda(
lambda tensors: K.abs(tensors[0] - tensors[1]))
l1_distance = l1_distance_layer([X1, X2])
这两句是将得到的两个128维向量进行距离求和,使用差值绝对值求得,得到的结果也是一个128维向量。
再之后,将得到的128维向量经过全连接层与512维、2维(即classes维)连接,得到一个二维向量,这个二维向量使用"softmax"激活函数,得到预测结果。
通过上面的两个函数,我们已经完成了模型的构建,接下来,我们从处理数据集开始,讲解如何对此模型进行训练。
笔者选用的数据集是LFW数据集,各位可以自行选择数据集,下面介绍一种简单的数据集处理方法(LFW数据集有pairs.txt文件,处理方式与下面介绍的不一致,这并不影响,因为得到的数据集形式是相同的):
- 因为不同数据集可能有不同的初步获取方式,因此这里假设我们获得了dataset_x(图像)、dataset_y(标签).
对于数据处理的思想是:首先取数据集中的任一图片,然后再随机取另一张图片(不要与第一张图片相同),将第一张图片加入X_L(这是一个list),将第二张图片加入X_R,如果两张图片是同一个人,将1加入labels(这是标签集),如果两张图片不是同一个人,将0加入labels。具体操作如下:
X_L = []
X_R = []
labels = []
for i in range(dataset_x.shape[0]):
for j in range(4): # 每个数据与四个其他数据对比
a = random.randint(0,dataset_x.shape[0]-1)
while a == i:
a = random.randint(0,dataset_x.shape[0]-1)
X_L.append(dataset_x[i])
X_R.append(dataset_x[a])
if dataset_y[i] == dataset_y[a]:
labels.append(1)
else:
labels.append(0)
这样,我们得到了一个具有两个图片并且已经标志其是否为同一人的数据集。但是我们对于数据集的处理还没有完成,如果使用以上的数据集去进行训练,会有多个错误产生。
- TensorFlow的模型训练应接收带有shape方法的数据集,而我们上面的数据集是list类型,不具有shape方法,要使其得到此方法,可按如下处理:
import numpy as np
X_L = np.array(X_L)
X_R = np.array(X_R)
labels = np.array(labels)
numpy.array()方法将list转化为array,具有shape方法。到这里,数据处理仍没有结束。还记得我们模型最后的输出吗?应该是(?, 2)维的向量,而我们的labels是(?, 1)维向量,这是怎么回事?
这里我们的labels向量使用0和1代表两种结果,因此对于每对图片都只有一个标签。要处理这个问题,有两种解决方案。
- 第一种解决方案是,将模型最后的输出激活函数换为’sigmoid’并改为1维。这样便与标签集维数相同。
- 第二种解决方案是,将标签转为2维,并且要与softmax输出匹配,即转化为独热编码。(0->(1,0), 1->(0,1)).
这里我们采用第二种解决方案
labels = to_categorical(labels, num_classes=2)
现在,我们可以获取我们的模型了:
model = VGG_Siamese(input_shape=x_train[0].shape)
设置模型参数:
model.compile(optimizer='adam', loss="categorical_crossentropy", metrics=['accuracy'])
# 如果刚才采用第一种解决方案,将loss改为'binary_crossentropy'
参数设置完毕后,可以开始训练模型了:
model.fit([X_L, X_R], labels, validation_split=0.2, batch_size=32, epochs=30, verbose=1)
这里只为了演示如何构建Siamese模型,因此选用的模型较简单,训练效果并不优秀,但是便于理解Siamese的工作原理和创建方式,为了优化训练效果,可以自己动手尝试更换模型进行训练。
- 训练完成后,可以将模型保存:
save_path = "./weights/my_weight" # 填文件地址和名称
model.save_weights(save_path) # 保存权重
model.save(save_path+'h5') # 保存模型和权重