Bagging策略和随机森林的应用以及线性回归与局部加权回归三种实例(线性回归、AdaBoost、GradientBoostingRegressor)【机器学习】
一.Bagging策略
-
bootstrap aggregation 有放回抽样集合
-
从样本集中重采样(有重复的)选出n个样本
-
在所有属性上,对这n个样本建立分类器(ID3、C4.5、CART、SVM、Logistic回归等)
-
重复以上两步m次,即获得了m个分类器
-
将数据放在m个分类器上,最后根据m个分类器的投票结果,决定数据属于哪一类

二.随机森林
随机森林在bagging基础上做了修改。
- 从样本集中用Bootstrap采样选出n个样本;
- 从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立CART决策树;
- 重复以上两步m次,即建立了m棵CART决策树-这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类
2.1 随机森林的应用
下图是实际B超拍摄的胎儿影像。完成头骨的自动检测算法,从而能够进一步估算胎儿头骨直径、胎龄等信息。假定现在有已经标记的几千张不同胎儿的图像,对于新的一张图像,如何做自动检测和计算?

一种可行的解决方案:随机森林
- 通过Haar特征提取等对每幅图片分别处理,得到M个特征。N个图片形成NM的矩阵。
随机选择若干特征和样本,得到ab的小矩阵,建立决策树; - 重复K次得到随机森林。
- 投票方法选择少数服从多数。
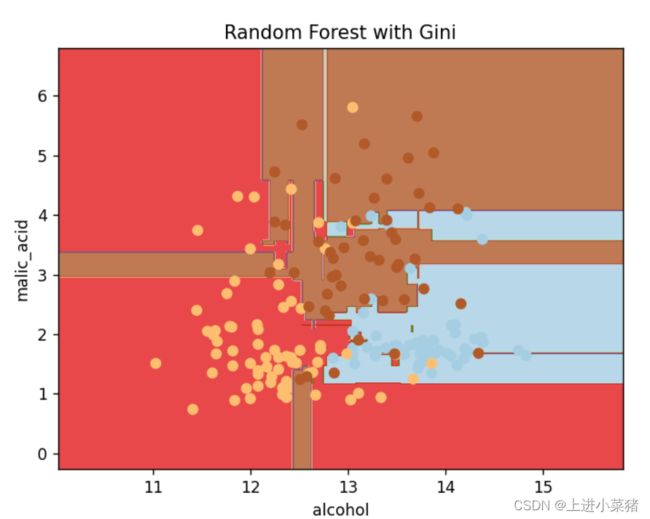
2.2红酒数据集(随机森林)
1.使用红酒数据集使用随机森林,引包如下:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_wine
wine = load_wine()
X=wine.data
y=wine.target
2.输出训练结果:
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier(n_estimators=3,random_state=9)
model.fit(X[:,:2],y)
print("traing score:",model.score(X[:,:2],y))
运行结果如下:

3.可视化随机森林结果:
x_min,x_max=X[:,0].min()-1,X[:,0].max()+1
y_min,y_max=X[:,1].min()-1,X[:,1].max()+1
h=(x_max/x_min)/100
xx,yy=np.meshgrid(np.arange(x_min,x_max,h),np.arange(y_min,y_max,h))
plt.subplot(1,1,1)
Z= model.predict(np.c_[xx.ravel(),yy.ravel()])
Z=Z.reshape(xx.shape)
plt.contourf(xx,yy,Z,cmap=plt.cm.Paired,alpha=0.8)
plt.scatter(X[:,0],X[:, 1], c=y, cmap=plt.cm.Paired)
plt.xlabel(wine['feature_names'][0])
plt.ylabel(wine['feature_names'][1])
plt.xlim(xx.min(), xx.max())
plt.title('Random Forest with Gini')
plt.show()
可视化结果如下:
三.线性回归与局部加权回归
-
黑色是样本点
-
红色是线性回归曲线
-
绿色是局部加权回归曲线


3.1 加利福尼亚的房价数据的线性回归实例
1.将加利福尼亚的房价数据集加载到本地
from sklearn.datasets import fetch_california_housing
import pandas as pd
from sklearn.model_selection import train_test_split
housing = fetch_california_housing()
X = housing.data
y = housing.target
df=pd.DataFrame()
2.切分数据集:七三分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
3.使用线性回归
from sklearn import linear_model
model = linear_model.LinearRegression()
model.fit(X_train, y_train)
print("train:", model.score(X_train, y_train))
print("test:", model.score(X_test, y_test))
4.训练结果如下:

3.2 AdaBoost 回归器超参数比较(加利福尼亚的房价数据)
AdaBoost 回归器是一个元估计器,它首先在原始数据集上拟合一个回归器,然后在同一数据集上拟合回归器的额外副本,但是实例的权重会根据当前预测的误差进行调整。
引入包:
from sklearn.ensemble import AdaBoostRegressor
进行训练,查看得分:
model = AdaBoostRegressor(n_estimators=3,random_state=3)
model.fit(X_train, y_train)
print("train:", model.score(X_train, y_train))
print("test:", model.score(X_test, y_test))
可以看出来:训练结果并不是很好。

3.3 GradientBoostingRegressor 向前分布算法的加法模型
梯度增强回归(GBR)是一种从错误中学习的技术。本质上,它是集思广益,整合一堆糟糕的学习算法进行学习。应注意两点:
- 每种学习算法的准备率都不高,但它们可以被集成以获得良好的准确性。
- 这些学习算法依次应用,即每个学习算法都从先前学习算法的错误中学习
from sklearn.ensemble import GradientBoostingRegressor
我们还是采用加利福尼亚的房价数据:
model = GradientBoostingRegressor(n_estimators=25,random_state=3)
model.fit(X_train, y_train)
print("train:", model.score(X_train, y_train))
print("test:", model.score(X_test, y_test))
运行结果如下:

四.评价指标
以下近考虑二分类问题,即将实例分成正类(positive)或负类(negative)。
对一个二分问题来说,会出现四种情况。
如果一个实例是正类并且也被预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。

五.ROC曲线实例

5.1 认识ROC曲线
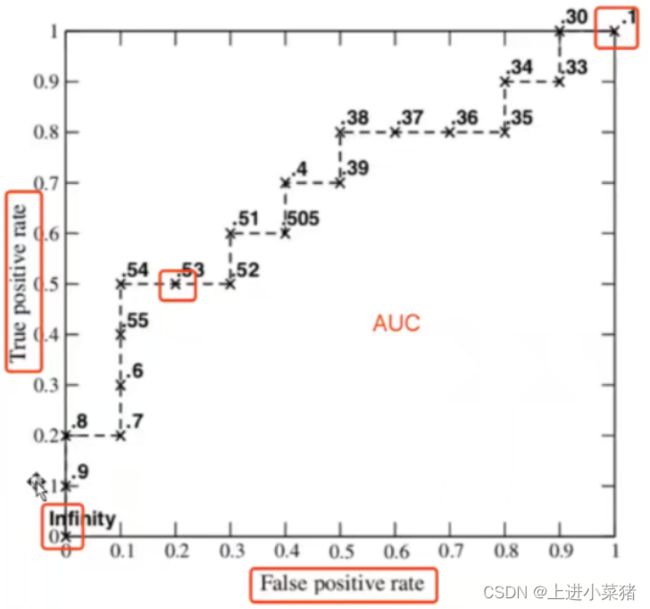
5.2 ROC曲线相关名词解释
- ROC的全称是Receiver Operating Characteristic Curve,中文名字叫“受试者工作特征曲线”。
- AUC(Area Under roc Curve),ROC曲线下面的面积。
- FPR(False Positive Rate),假阳性率。
- TPR (True Positive Rate),真阳性率。
- 混淆矩阵,confusion matrix。
- Cl:置信区间,Confidence interval。
- 约登指数,TPR+FPR-1(敏感性+特异性-1),最佳截断点。
5.3 改变阅值计算得到的最终ROC曲线
