文章目录
- 实验目标
- 实验要求
- 实验原理
- 实验步骤
- 实验分析
- 源代码
实验目标
多层感知器(Multi-Layer Perceptron,MLP)也叫人工神经网络(Artificial Neural Network,ANN),除了输入输出层,它中间可以有多个隐层。最简单的MLP需要有一层隐层,即输入层、隐层和输出层才能称为一个简单的神经网络。通俗而言,神经网络是仿生物神经网络而来的一种技术,通过连接多个特征值,经过线性和非线性的组合,最终完成目标识别。
通过本实验,掌握多层感知器神经网络的原理和实现算法,将其应用到 目标识别。
实验要求
1. 理解多层感知器神经网络原理,能对BP算法进行阐述和解释。学生应自行研
究教材和参考资料。
2. 编写程序,通过多层感知器神经网络完成FASION-MNIST数据集的目标识别。
3. 编写程序,对已经实现的目标识别程序进行精度检测,对结果进行分析。
4. 编写实验报告,其要求为:
1) 使用指定的模板,提交PDF格式的文件;
2) 实验原理:阐述该实验所涉及的原理,综述其他人的工作
3) 实验步骤:阐述自己的实现过程,包括程序结构、算法设计、实验记录
等,尽量使用图和表提升可读性
4) 实验分析:对实验的结果进行分析,得出一定的结论
5) 附录 源代码:将自己的源代码整理好复制到此处,并恰当排版,建议使
用等宽字体(比如Consolas)
实验原理
我们先进行一层隐含层的原理介绍,多层的可在一层的基础上进行推广拓展:
给定训练集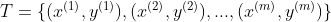
其中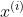 :为第
:为第 个样本的特征,
个样本的特征, 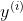 :为第 个样本的标签,且
:为第 个样本的标签,且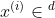 ,
,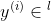 ;
;

为此我们构建拥有 个输入神经元、
个输入神经元、  个隐层神经元、
个隐层神经元、 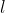 个输出神经元;
个输出神经元;
以下是相关变量的定义:
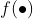 :激活函数形式;
:激活函数形式;
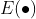 :损失函数形式;
:损失函数形式;
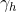 :隐含层第
:隐含层第 个神经元阈值;
个神经元阈值;
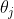 :输出层第
:输出层第 个神经元阈值;
个神经元阈值;
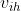 :输入层第 个神经元与隐含层第 个神经元之间连接权重;
:输入层第 个神经元与隐含层第 个神经元之间连接权重;
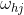 :隐含层第 个神经元与输出层第 个神经元之间连接权重;
:隐含层第 个神经元与输出层第 个神经元之间连接权重;
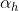 :隐含层第 个神经元输入
:隐含层第 个神经元输入 ;
;
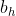 :隐含层第 个神经元输出
:隐含层第 个神经元输出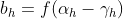 ;
;
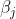 :输出层第 个神经元输入
:输出层第 个神经元输入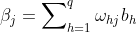 ;
;
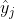 :输出层第 个神经元输出
:输出层第 个神经元输出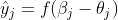 ;
;
下面利用随机梯度下降进行权重与阈值更新:
选择一个训练样本

其中 ,
,
由于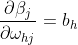 ,
, ,因此
,因此 

由于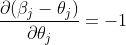 ,因此
,因此 
由于这两更新都涉及 ,因此给出定义:
,因此给出定义:

因此可以将其改写为:
 ,
, 
同理对于隐含层也做类似操作可得:
 ,
, 
其中 
以上便是含一个隐藏层的权重与偏置更新的公式推导,对于含多个隐藏层的神经网络,我们可以将含一个隐藏层的进行拓展推广,同理可得;
实验步骤
一、算法步骤
-
网上下载FASHION-MNIST数据集,由于格式为idx1-ubyte、idx3-ubyte,因此先要将其进行格式转化,转化为csv格式;
-
采用误差平方和 作为损失函数,
作为损失函数, 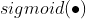 作为激活函数;
作为激活函数;
-
构建含有一层输入层,一层隐含层,一层输出层的神经网络,随机将0~0.01赋值输入-隐含权重网络、隐含-输出权重网络,将隐含层偏置、输出层偏置设置为0;
-
利用随机梯度下降法进行权值与阈值的更新;
-
进行训练集准确率、测试集准确率的计算;
二、程序结构
2.1、文件格式转化:
将idx1-ubyte、idx3-ubyte格式文件转化为csv格式文件,将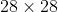 图片矩阵“压扁”为
图片矩阵“压扁”为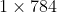 的向量, 每一行代表一个样本,第一列为标签值,其余列为特征值;
的向量, 每一行代表一个样本,第一列为标签值,其余列为特征值;
1.def convert(imgf, labelf, outf, n):
2. f = open(imgf, "rb")
3. o = open(outf, "w")
4. l = open(labelf, "rb")
5.
6. f.read(16)
7. l.read(8)
8. images = []
9.
10. for i in range(n):
11. image = [ord(l.read(1))]
12. for j in range(28 * 28):
13. image.append(ord(f.read(1)))
14. images.append(image)
15.
16. for image in images:
17. o.write(",".join(str(pix) for pix in image) + "\n")
18. f.close()
19. o.close()
20. l.close()
21.
22.
23.convert("C:/Users/Administrator/Desktop/第二次模式识别实验/train-images-idx3-ubyte",\
24. "C:/Users/Administrator/Desktop/第二次模式识别实验/train-labels-idx1-ubyte",
25. "mnist_train.csv", 60000)
26.convert("C:/Users/Administrator/Desktop/第二次模式识别实验/t10k-images-idx3-ubyte", \
27. "C:/Users/Administrator/Desktop/第二次模式识别实验/t10k-labels-idx1-ubyte",
28. "mnist_test.csv", 10000)
29.
30.print("Convert Finished!")
2.2、数据预处理
由于图片数据分布为0~255范围,但是对于 函数而言,过大范围的数值会造成梯度消失,因此我们首先要进行将数据映射到一个较小的范围-1~1内;
1.#标准化
2.for i in range(len(train)):
3. train[i][1:] = (2*train[i][1:]-255.0)/255.0
4.for j in range(len(test)):
5. test[j][1:] = (2*test[j][1:]-255.0)/255.0
图片类型共有十种,以0~9进行编号,但是这样的编号方式会无形中引入序关系,因此我们得先进行独热编码,对每个类别赋予一个十维的向量,例如:0的独热编码为![[1,0,0,0,0,0,0,0,0,0,0]](http://img.e-com-net.com/image/info8/8c1ccb10d76b44b6bfa1fc37f4aa597e.gif) 依次类推;
依次类推;
1.#选取样本
2.label = int((list(train[i]))[0])
3.#独热编码
4.y = np.mat(np.zeros((num_label, 1)))
5.y[label][0] = 1
2.3、构建网络结构
我们构建只包含一层隐含层的网络,输入层神经元个数为特征维度:784,隐含层神经元个数为超参数,可以人为进行改变,我们将其设置为:256,输出层神经元个数为标签值维度:10;随机将0~0.01赋值输入-隐含权重网络、隐含-输出权重网络,将隐含层偏置、输出层偏置设置为0;
1.#数据维度与样本个数
2.[num_train, devision] = train.shape
3.num_in = devision-1
4.num_hidden = 256
5.num_label = 10
6.
7.#定义网络结构并完成初始化
8.#定义权重矩阵
9.eta = 0.1 #学习率
10.max_iter = 50 #遍历训练集次数
11.v_ih = np.mat(np.random.rand(num_in, num_hidden)*0.01) #输入-隐含
12.w_hj = np.mat(np.random.rand(num_hidden, num_label)*0.01) #隐含-输出
13.
14.#定义偏置
15.grama_h = np.mat(np.zeros((num_hidden, 1))) #隐藏层
16.theta_j = np.mat(np.zeros((num_label, 1))) #输出层
2.4、利用随机梯度下降进行权重与偏置更新
本次实验损失函数选取为误差平方和,将问题转化为优化问题: ,采用随机梯度下降进行该优化问题的求解:每次利用一个样本进行权重与偏置的更新,总共遍历训练集max_iter次;
,采用随机梯度下降进行该优化问题的求解:每次利用一个样本进行权重与偏置的更新,总共遍历训练集max_iter次;
1.#利用梯度下降进行网络训练
2.for iter in range(max_iter):
3. print('* * * * * * 第 ', iter+1, ' 遍训练集迭代* * * * * * ')
4. for i in range(num_train):
5. #选取样本
6. label = int((list(train[i]))[0])
7. #独热编码
8. y = np.mat(np.zeros((num_label, 1)))
9. y[label][0] = 1
10.
11. x = np.mat(train[i][1:]).T
12. alphas = v_ih.T * x
13.
14. #定义隐藏层输出
15. b_h = sigmoid(alphas-grama_h)
16.
17. #定义输出层输入
18. beta_j = w_hj.T * b_h
19.
20. #定义输出层输出
21. y_hat = sigmoid(beta_j-theta_j)
22.
23. #相关梯度计算
24. g = np.multiply(y_hat, 1-y_hat)
25. g = np.multiply(g, y-y_hat)
26. e = np.multiply(b_h, 1-b_h)
27. e = np.multiply(e, w_hj*g)
28.
29. #更新权重与偏置
30. w_hj = w_hj + eta*b_h*g.T
31. theta_j = theta_j - eta*g
32. v_ih = v_ih + eta*x*e.T
33. grama_h = grama_h - eta*e
2.5、计算训练集正确率与测试集正确率
将样本特征值输入网络中,得到一个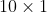 的输出向量,我们选取最大值的下标作为预测的类别,若预测值与真实值相同,则预测正确数+1;
的输出向量,我们选取最大值的下标作为预测的类别,若预测值与真实值相同,则预测正确数+1;
1.#训练集正确率
2.true_train = 0
3.for i in range(num_train):
4. # 选取样本
5. label = int((list(train[i]))[0])
6. y = np.mat(np.zeros((num_label, 1)))
7. y[label][0] = 1
8.
9. #输出预测
10. x = np.mat(train[i][1:]).T
11. alphas = v_ih.T * x
12. b_h = sigmoid(alphas - grama_h)
13. beta_j = w_hj.T * b_h
14. y_hat = sigmoid(beta_j - theta_j)
15.
16. max_index = np.unravel_index(np.argmax(y_hat, axis=None), y_hat.shape)
17. label_pre = max_index[0]
18. if label_pre == label:
19. true_train = true_train+1
20.print('训练集正确率: ', true_train/num_train*100, '%')
实验分析
(1)为了探究隐含层神经元个数对于训练效果好坏的影响,我们通过将隐含层神经元设置为16、32、64、128、256、512,分别记录下来训练集正确率与测试集正确率,绘制以下曲线:

可以看出,训练集正确率随着隐含层神经元个数变化幅度会大于测试集正确率,增加隐含层神经元个数对于测试集正确率增长作用不大,考虑到增长隐含层神经元个数会增加运算量,因此我们在保证正确率的前提下,选择最少的神经元个数:256;
(2)为了探究学习率对于实验结果有什么影响,我们将其他超参数固定:隐含层神经元个数:256、遍历训练集次数:25;将学习率进行改变,依次取以下不同值:0.01、 0.05、 0.1、 0.2、 0.5、 0.8,分别得出训练集正确率,并绘制成以下曲线:

由此看出,学习率太大、太小都会对训练集准确率造成影响,学习率太小:容易陷入局部最优解,如果采用批量梯度下降,则可能收敛不了;学习率太大:容易跳过最优值,造成找不到极值点;
(3)此次实验,我实验了两种损失函数:误差平方和、交叉熵,并比较了它们在训练集上的效果:在隐含层神经元个数:256,、学习率:0.1等条件一致的情况下,两损失函数效果大致相等,测试集正确率都在85%左右的水平;但是按照理论来说,交叉熵在处理分类问题应该会是一种比误差平方和更加合理的选择;通过上网查找资料,进行思考,发现:当误差平方和很小时,其交叉熵也会很小,交叉熵与误差平方和之间存在着联系,这也是为什么用误差平方和与交叉熵结果差不多的原因;
源代码
1.import numpy as np
2.import pandas as pa
3.
4.'''
5.load_data:导入数据集
6.第一列为label,其余列为features
7.'''
8.def load_data(filename):
9. data = pa.read_csv(filename)
10. print('* * * * * * ' + filename + '文件加载完成 * * * * * *')
11. return data
12.
13.'''
14.label_show:将数字转化为文字标签
15.'''
16.def label_show(labels):
17. text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
18. 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
19. return [text_labels[int(i)] for i in labels]
20.
21.'''
22.sigmoid:定义sigmoid函数
23.'''
24.def sigmoid(x):
25. return 1/(1+np.exp(-x))
26.
27.
28.
29.
30.
31.#导入数据
32.filename_train = 'D:/BP/venv/mnist_train.csv'
33.filename_test = 'D:/BP/venv/mnist_test.csv'
34.train = np.array(load_data(filename_train), dtype=np.float32)
35.test = np.array(load_data(filename_test), dtype=np.float32)
36.
37.
38.#选取部分样本
39.train = train[0:6000]
40.test = test[0:1000]
41.
42.
43.#标准化
44.for i in range(len(train)):
45. train[i][1:] = (2*train[i][1:]-255.0)/255.0
46.for j in range(len(test)):
47. test[j][1:] = (2*test[j][1:]-255.0)/255.0
48.
49.
50.
51.#数据维度与样本个数
52.[num_train, devision] = train.shape
53.num_in = devision-1
54.num_hidden = 256
55.num_label = 10
56.
57.
58.
59.
60.#定义网络结构并完成初始化
61.#定义权重矩阵
62.eta = 0.1 #学习率
63.max_iter = 50 #遍历训练集次数
64.v_ih = np.mat(np.random.rand(num_in, num_hidden)*0.01) #输入-隐含
65.w_hj = np.mat(np.random.rand(num_hidden, num_label)*0.01) #隐含-输出
66.
67.#定义偏置
68.grama_h = np.mat(np.zeros((num_hidden, 1))) #隐藏层
69.theta_j = np.mat(np.zeros((num_label, 1))) #输出层
70.#print(v_ih)
71.
72.#利用梯度下降进行网络训练
73.for iter in range(max_iter):
74. print('* * * * * * 第 ', iter+1, ' 遍训练集迭代* * * * * * ')
75. for i in range(num_train):
76. #选取样本
77. label = int((list(train[i]))[0])
78. #独热编码
79. y = np.mat(np.zeros((num_label, 1)))
80. y[label][0] = 1
81.
82. x = np.mat(train[i][1:]).T
83. alphas = v_ih.T * x
84.
85. #定义隐藏层输出
86. b_h = sigmoid(alphas-grama_h)
87.
88. #定义输出层输入
89. beta_j = w_hj.T * b_h
90.
91. #定义输出层输出
92. y_hat = sigmoid(beta_j-theta_j)
93.
94. #相关梯度计算
95. g = np.multiply(y_hat, 1-y_hat)
96. g = np.multiply(g, y-y_hat)
97.
98. e = np.multiply(b_h, 1-b_h)
99. e = np.multiply(e, w_hj*g)
100.
101. #更新权重与偏置
102. w_hj = w_hj + eta*b_h*g.T
103. theta_j = theta_j - eta*g
104. v_ih = v_ih + eta*x*e.T
105. grama_h = grama_h - eta*e
106.
107.
108.#训练集正确率
109.true_train = 0
110.for i in range(num_train):
111. # 选取样本
112. label = int((list(train[i]))[0])
113. y = np.mat(np.zeros((num_label, 1)))
114. y[label][0] = 1
115.
116. #输出预测
117. x = np.mat(train[i][1:]).T
118. alphas = v_ih.T * x
119. b_h = sigmoid(alphas - grama_h)
120. beta_j = w_hj.T * b_h
121. y_hat = sigmoid(beta_j - theta_j)
122.
123. max_index = np.unravel_index(np.argmax(y_hat, axis=None), y_hat.shape)
124. label_pre = max_index[0]
125. if label_pre == label:
126. true_train = true_train+1
127.print('训练集正确率: ', true_train/num_train*100, '%')
128.
129.#测试集正确率
130.true_test = 0
131.num_test = len(test)
132.for i in range(num_test):
133. # 选取样本
134. label = int((list(test[i]))[0])
135. y = np.mat(np.zeros((num_label, 1)))
136. y[label][0] = 1
137.
138.
139. x = np.mat(test[i][1:]).T
140. alphas = v_ih.T * x
141. b_h = sigmoid(alphas - grama_h)
142. beta_j = w_hj.T * b_h
143. y_hat = sigmoid(beta_j - theta_j)
144.
145. max_index = np.unravel_index(np.argmax(y_hat, axis=None), y_hat.shape)
146. label_pre = max_index[0]
147. if label_pre == label:
148. true_test = true_test+1
149.print('测试集正确率: ', true_test/num_test*100, '%')