YOLOv7的转炉生产监控系统(源码&部署教程)
1.识别效果展示


2.视频演示
[YOLOv7]基于YOLOv7的转炉生产监控系统(源码&部署教程)_哔哩哔哩_bilibili
3.YOLOv7算法简介
YOLOv7 在 5 FPS 到 160 FPS 范围内,速度和精度都超过了所有已知的目标检测器
并在 GPU V100 上,30 FPS 的情况下达到实时目标检测器的最高精度 56.8% AP。YOLOv7 是在 MS COCO 数据集上从头开始训练的,不使用任何其他数据集或预训练权重。
相对于其他类型的工具,YOLOv7-E6 目标检测器(56 FPS V100,55.9% AP)比基于 transformer 的检测器 SWINL Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)速度上高出 509%,精度高出 2%,比基于卷积的检测器 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度高出 551%,精度高出 0.7%。
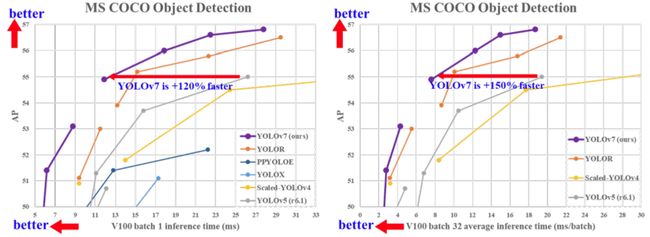
此外, YOLOv7 的在速度和精度上的表现也优于 YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR 等多种目标检测器。
4.YOLOv7 技术方法
近年来,实时目标检测器仍在针对不同的边缘设备进行开发。例如,MCUNet 和 NanoDet 的开发专注于生产低功耗单芯片并提高边缘 CPU 的推理速度;YOLOX、YOLOR 等方法专注于提高各种 GPU 的推理速度;实时目标检测器的发展集中在高效架构的设计上;在 CPU 上使用的实时目标检测器的设计主要基于 MobileNet、ShuffleNet 或 GhostNet;为 GPU 开发的实时目标检测器则大多使用 ResNet、DarkNet 或 DLA,并使用 CSPNet 策略来优化架构。
YOLOv7 的发展方向与当前主流的实时目标检测器不同,研究团队希望它能够同时支持移动 GPU 和从边缘到云端的 GPU 设备。除了架构优化之外,该研究提出的方法还专注于训练过程的优化,将重点放在了一些优化模块和优化方法上。这可能会增加训练成本以提高目标检测的准确性,但不会增加推理成本。研究者将提出的模块和优化方法称为可训练的「bag-of-freebies」。
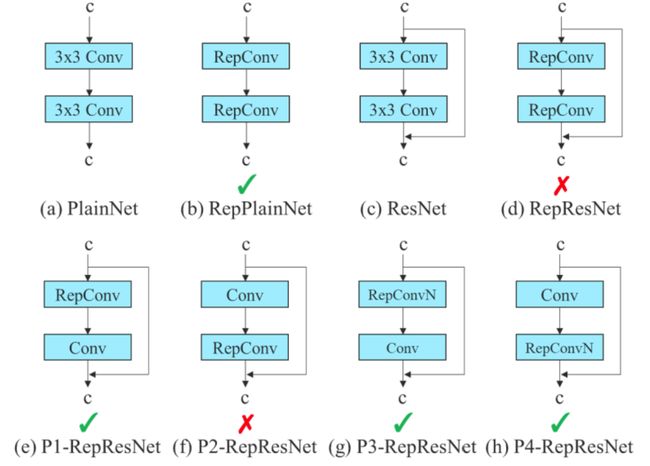
对于模型重参数化,该研究使用梯度传播路径的概念分析了适用于不同网络层的模型重参数化策略,并提出了有计划的重参数化模型。此外,研究者发现使用动态标签分配技术时,具有多个输出层的模型在训练时会产生新的问题:「如何为不同分支的输出分配动态目标?」针对这个问题,研究者提出了一种新的标签分配方法,称为从粗粒度到细粒度(coarse-to-fine)的引导式标签分配。
该研究的主要贡献包括:
参考该博客提出的创新点
(1) 设计了几种可训练的 bag-of-freebies 方法,使得实时目标检测可以在不增加推理成本的情况下大大提高检测精度;
(2) 对于目标检测方法的演进,研究者发现了两个新问题:一是重参数化的模块如何替换原始模块,二是动态标签分配策略如何处理分配给不同输出层的问题,并提出了解决这两个问题的方法;
(3) 提出了实时目标检测器的「扩充(extend)」和「复合扩展(compound scale)」方法,以有效地利用参数和计算;
(4) 该研究提出的方法可以有效减少 SOTA 实时目标检测器约 40% 的参数和 50% 的计算量,并具有更快的推理速度和更高的检测精度。
在大多数关于设计高效架构的文献中,人们主要考虑的因素包括参数的数量、计算量和计算密度。下图 2(b)中 CSPVoVNet 的设计是 VoVNet 的变体。CSPVoVNet 的架构分析了梯度路径,以使不同层的权重能够学习更多不同的特征,使推理更快、更准确。图 2 © 中的 ELAN 则考虑了「如何设计一个高效网络」的问题。
YOLOv7 研究团队提出了基于 ELAN 的扩展 E-ELAN,其主要架构如图所示。
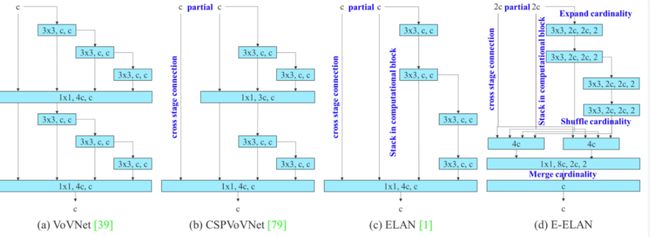
该博客提出的 E-ELAN 完全没有改变原有架构的梯度传输路径,其中使用组卷积来增加添加特征的基数(cardinality),并以 shuffle 和 merge cardinality 的方式组合不同组的特征。这种操作方式可以增强不同特征图学得的特征,改进参数的使用和计算效率。
无论梯度路径长度和大规模 ELAN 中计算块的堆叠数量如何,它都达到了稳定状态。如果无限堆叠更多的计算块,可能会破坏这种稳定状态,参数利用率会降低。新提出的 E-ELAN 使用 expand、shuffle、merge cardinality 在不破坏原有梯度路径的情况下让网络的学习能力不断增强。
在架构方面,E-ELAN 只改变了计算块的架构,而过渡层(transition layer)的架构完全没有改变。YOLOv7 的策略是使用组卷积来扩展计算块的通道和基数。研究者将对计算层的所有计算块应用相同的组参数和通道乘数。然后,每个计算块计算出的特征图会根据设置的组参数 g 被打乱成 g 个组,再将它们连接在一起。此时,每组特征图的通道数将与原始架构中的通道数相同。最后,该方法添加 g 组特征图来执行 merge cardinality。除了保持原有的 ELAN 设计架构,E-ELAN 还可以引导不同组的计算块学习更多样化的特征。
因此,对基于串联的模型,我们不能单独分析不同的扩展因子,而必须一起考虑。该研究提出图 (c),即在对基于级联的模型进行扩展时,只需要对计算块中的深度进行扩展,其余传输层进行相应的宽度扩展。这种复合扩展方法可以保持模型在初始设计时的特性和最佳结构。
此外,该研究使用梯度流传播路径来分析如何重参数化卷积,以与不同的网络相结合。下图展示了该研究设计的用于 PlainNet 和 ResNet 的「计划重参数化卷积」。
5.数据集的准备
标注收集到的图片制作YOLO格式数据集(文末提供下载链接)
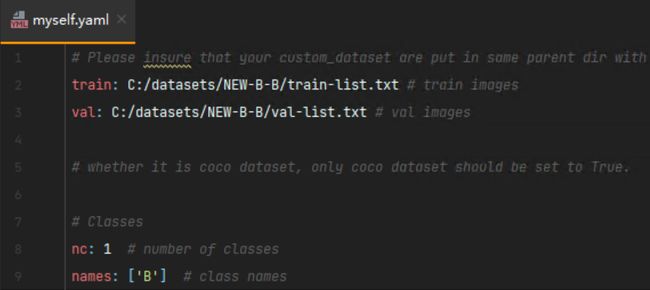
自己创建一个myself.yaml文件用来配置路径,路径格式与之前的V5、V6不同,只需要配置txt路径就可以
train-list.txt和val-list.txt文件里存放的都是图片的绝对路径(也可以放入相对路径)
如何获取图像的绝对路径,脚本写在下面了(也可以获取相对路径)
# From Mr. Dinosaur
import os
def listdir(path, list_name): # 传入存储的list
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
else:
list_name.append(file_path)
list_name = []
path = 'D:/PythonProject/data/' # 文件夹路径
listdir(path, list_name)
print(list_name)
with open('./list.txt', 'w') as f: # 要存入的txt
write = ''
for i in list_name:
write = write + str(i) + '\n'
f.write(write)
6.训练过程
运行train.py
train文件还是和V5一样,为了方便,我将需要用到的文件放在了根目录下

路径修改完之后右击运行即可
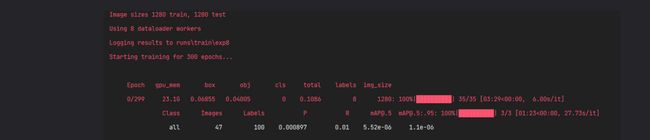
1.等待漫长的训练过程,实测GPU 3090ti训练长达40小时以上
2.在训练方面,YOLOv7相比YOLOv5更吃配置尤其是显存(上图可以看出需要23.1G显存,爆显存建议降低batchsize),建议电脑显存8G以下的谨慎尝试,可能训练的过程低配置的电脑会出现蓝屏等现象皆为显卡过载
3.在预测方面,使用本文提供的训练好的权重进行预测可以跳过上一步训练的步骤,CPU也能取得很好的预测结果且不会损伤电脑
附上推荐设备配置

7.测试验证
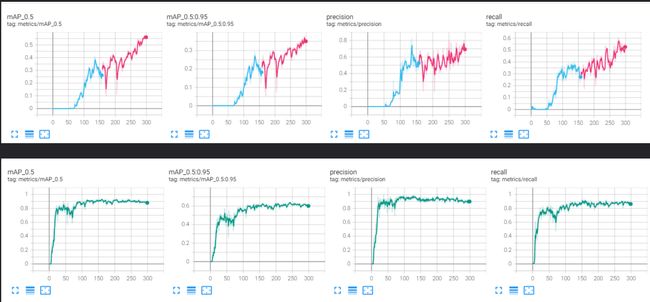
下面放上对比图:(上面V7,下面V5)
8.系统整合
下图完整源码&环境部署视频教程&数据集&自定义UI界面

参考博客《[YOLOv7]基于YOLOv7的转炉生产监控系统(源码&部署教程)》