声纹识别小总结
文章目录
- 1.声纹识别基础知识
-
- A.识别任务分类:1、固定文本:注册与验证内容相同;2、半固定文本:注册与验证内容一样但顺序不同,且文本属于固定集合;3、自由文本
- B.常见预处理特征:MFCC/FBank。
- C.常用的评价方法
- 2.相关论文总结
-
- 1.Probabilistic Linear Discriminant Analysis
- 2.Front-End Factor Analysis for Speaker Verification
- 3.A Time Delay Neural Network Architecture for Efficient Modeling of Long Temporal Contexts
- 4.ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification
- 5.Deep Neural Network Embeddings for Text-Independent Speaker Verification
- 6.X-VECTORS: ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION(与上面的论文基本一致)
- 7.Time Delay Deep Neural Network-Based Universal Background Models For Speaker Recognition
- 8.Deep Neural Networks for Small Footprint Text-Dependent Speaker Verification(d-vector)
1.声纹识别基础知识
A.识别任务分类:1、固定文本:注册与验证内容相同;2、半固定文本:注册与验证内容一样但顺序不同,且文本属于固定集合;3、自由文本
B.常见预处理特征:MFCC/FBank。
C.常用的评价方法
1.等错误率(Equal Error Rate, EER):
错误拒绝率EFR和错误接受率 EFA :EER 为EFR = EFA 时的错误率:EER = EFR = EFA
2.DET(Detection Error Trade-off) 曲线
DET 曲线也是说话人确认中,如下图所示,DET曲线建立对数刻度下 EFA与EFR 的关系。曲线离原点越近,EFA 与 EFR 越小,系统性能越好。曲线与第一象限 45◦ 线的交点即为 EER 点。曲线上的不同点对应不同的阈值。
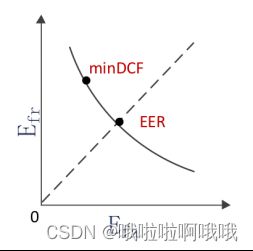
3.最小检测代价(Minimum Detection Cost Function, minDCF):
DCF 是 NIST SRE 中定义的一种性能评定方法
 (1)
(1)
其中 CFR和 CFA 分别代表错误拒绝和错误接受的惩罚代价,Ptarget和1 − Ptarget分别为真实说话测试和冒认测试的先验概率。可以根据不同的应用环境来设定它们的值。希望错误接受的概率比较小,那么可以增大 CFA 。当 CFR、CFA 、Ptarget和 1 − Ptarget取定后,EFR 与 EFA 的某一组取值使得 DCF 最小,此时的 DCF 成为 minDCF 。
在日常使用 DCF 时,CFR = 10,CFA = 1,Ptarget= 0.01 为准。minDCF不仅考虑了两类错误的不同代价,还考虑了两种测试情况的先验概率,比EER 更合理。
2.相关论文总结
1.Probabilistic Linear Discriminant Analysis
概率LDA,是一种生成模型。
![]()
(2)
第2个加项是信号成分,只与个体i相关,表示个体之间的差异;后两个式子是噪声成分,代表个体内部差异。μ是全体训练数据的均值,F是身份/信号空间,hi是第i个人在F中的位置,G是误差空间,wij是第i人的第j图在G中的位置,最后一项就是噪声。
借助另一篇论文理解这个公式:

第一行为前两个加项,第二行μ+噪声成分,第一行代表的是不同的人,第二行代表的就是相同的人,他们之间有一些个体差异。
公式(2)有4个参数,但是我们的目标是寻找说话人之间的区别,所以G可以不算,在测试的时候就计算语音是否由身份空间F的hi组成,或者是由hi生成的似然程度,不用再管误差空间G内差异了。利用下面的公式(3)计算结果:

(3)
2.Front-End Factor Analysis for Speaker Verification
这篇论文是第一篇提出i-vecctor方法的论文。
基于JFA公式进行优化,JFA 的原理是对语音的高斯超向量进行因子分解,得到说话人因子和通道因子。下面为JFA的公式:
![]()
(4)
根据 JFA 的假设,通道因子应该只包含语音中的传输通道、录音设备等与说话人无关的信息。但是,研究发现通道因子中还存在有用的说话人信息,可能会因为分离的不正确而丢失重要的信息,因此提出了一个简化的JFA 模型,总体变化模型(Total Variability Model,TVM),由于其提取的特征为 i-vector,故总体变化模型也称为i-vector模型。
文章一共提出了两个方法,这两个方法是串起来使用的:第一个是基于支持向量机的系统,它使用余弦核来估计输入数据之间的相似性。第二个系统直接使用目标说话人因子和测试总因子之间计算的余弦距离值作为决策分数。在总可变性空间中测试了三种通道补偿技术,分别是类内协方差归一化(WCCN)、线性判别分析(LDA)和滋扰属性投影(NAP)。论文发现,当 线性判别分析(LDA)之后使用 类内协方差归一化(WCCN)时,可以获得最好的结果。
在i-vector模型中,因子分析用于提取特征,在总因子空间进行通道补偿,与经典JFA 建模中的情况一样。i-vector方法的优点是运算量较小(因为在低维空间上处理的)。
3.A Time Delay Neural Network Architecture for Efficient Modeling of Long Temporal Contexts
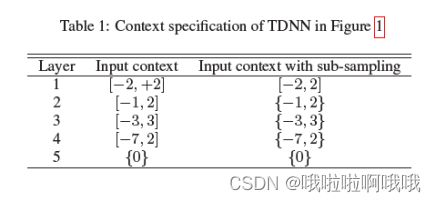
这篇论文提出了一个时滞网络TDNN,并进行了采样来减少花销:不直接拼接连续窗口,而是将当前帧-7处的和+2处的拼接({-7,+2}),如果是中括号就是连续拼接。
sub-sample的方法能减少5倍的计算量,也缩减了模型。作者认为left-context大于right-congtext比较好,这减少了在线解码中神经网络的延迟。最优结果为[-16,9]。

另外,文中写到p-norm效果好,但是后期发现relu效果更好,但当时论文还没写好。
4.ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification
这篇论文是前几年提出的,但目前还是sota。模型的输入是MFCC(25ms,80维,10ms每帧的移动),在使用之前用specaugment进行扩充,每段语句会生成额外的6段,遵循kaldi原则。同时也会有一些随机屏蔽:1.时域屏蔽0-5帧 2.频域屏蔽0-10通道,其中有瓶颈层(bottleneck layer)和res2net。


最后从网络中输出的结果,利用余弦距离计算试验分数(没有用PLDA),利用s-norm对分数归一化。
5.Deep Neural Network Embeddings for Text-Independent Speaker Verification
该论文在i-vector之后提出,embedding效果比较好,论文使用多分类交叉熵损失:

(5)
由于GPU限制,作者选择范围从 2 到 10 秒(200 到 1000 帧)以及 32 到 64 的mini batchsize的样本。示例语音块从录音中密集采样,每个说话者大约 3,400 个示例。Embedding a是直接在统计数据之上的仿射层的输出。Embedding b是从ReLU之后的下一个仿射层提取的,因此它是非线性函数。 因为它们是同一个DNN的部分,因此计算b,就可以获a。
后续也是PLDA在进行处理,最开始frame-layer里边是TDNN,一共5层。

6.X-VECTORS: ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION(与上面的论文基本一致)
这篇论文主要增加了数据增强(附加babble人声、music、noise噪声、reverb混响)。将可变长度的话语映射到x-vector,同时作者发现数据增强对于plda有效,但是对于i-vector没什么效果。
语音长度平均三秒,模型共有420万个参数。输出结果用s-norm归一化。
模型与上面的embedding一致,具体包含多层帧级别的TDNN层,一个统计池化层和两层句子级别的全连接层,以及一层softmax;损失函数为CE交叉熵。统计池化层将输出取均值和标准差,再将二者拼接起来,得到句子级别的特征表达。
他效果比较好主要是因为数据增强的比较合适。X-VECTORS在SRE和SITW上的表现均优于传统框架i-vector。
TDNN+stats pooling,能够将帧级别的输入特征转化为句子级别的特征表达embeddding。同样他也是利用PLDA在计算相似度。
7.Time Delay Deep Neural Network-Based Universal Background Models For Speaker Recognition
本文提出的主要方法是UBM,以传统方法GMM与UBM结合作为baseline。

GMM-UBM 复合方法示意图
- 模型:输入(60-d)→UBM(2048,4096,5297-c)→i-vector extractor(600-d)→PLDA
- 输入:共60维,20维MFCC+Delta+acceleration,25ms帧长,平均归一化,3s窗口,基于能量的VAD;
- UBM:full-covariance GMM with 2048, 4096, and 5297 components;
- i-vector:600-d,均值减法,长度归一化;
- PLDA:i-vector的均值m,类间和类内协方差矩阵Γ 和 Λ
这篇论文又在TDNN的基础之上,进行了下一步修改。提出了两种模型TDNN-GMM(花销大)和sup-GMM(速度快花销少)。
sup-GMM使用DNN的后验以及说话人特征(即MFCC)来生成,与无监督的GMM的不同仅在UBM的训练过程,i-vector提取过程中都如下所示

sup-GMM复合方法示意图

TDNN-UBM复合方法示意图
模型结构:首先输入MFCC到一个DNN(TDNN),然后使用DNN的输出(后验)以及说话人特征创建一个UBM,也就是之前提到的sup-GMM,然后使用UBM的输出以及声学特征生成一个TDNN,然后使用该TDNN的后验以及说话人特征提取i-vector。

在i-vector提取过程中,它与之前基于GMM的系统的唯一区别是该模型被用于计算后验。结合说话人识别特征,TDNN后端为i-vector提取创建了足够的统计信息。
8.Deep Neural Networks for Small Footprint Text-Dependent Speaker Verification(d-vector)
第一篇利用DNN提取声纹特征的方法,以训练好的DNN模型最后的隐藏层的累积输出作为说话者的特征。
得到d-vector之后,进行l2-norm,利用该值点积就可以获得余弦相似度,并通过阈值来验证是谁。