LXMERT:从Transformers学习跨模态编码器表示LXMERT: Learning Cross-Modality Encoder Representations from Transfors
摘 要
视觉和语言推理需要理解视觉概念、语言语义,以及最重要的是,这两种模式之间的对齐和关系。因此,原论文提出了LXMERT(从Transforms学习跨模态编码器表示)框架来学习这些视觉和语言连接。在LXMERT中,原论文构建了一个大型转换器模型,该模型由三个编码器组成:对象关系编码器、语言编码器和跨模态编码器。接下来,为了赋予模型连接视觉和语言语义的能力,原论文通过五个不同的代表性预训练任务,使用大量图像和句子对模型进行预训练:masked语言建模,masked对象预测(特征回归和标签分类),跨模态匹配和图像问题解答。这些任务有助于学习模态内和模态间的关系。在对预训练参数进行微调后,模型在两个可视化问答数据集(即VQA和GQA)上获得了最新的结果。除此之外,原论文还通过将预训练的跨模态模型应用于具有挑战性的视觉推理任务NLVR2,证明了该模型的通用性,并将之前的最佳结果绝对值提高了22%(54%-76%)。最后,展示了详细的消融研究,以证明新模型组件和预训练策略对这个强大的结果有显著贡献;并给出了不同编码器的几种注意可视化。
关键词:视觉和语言;LXMERT;编码器
1 引言
1.1主要任务及其定义和挑战
1.1.1主要任务
建立一个跨模态框架,用于学习视觉和语言之间的联系,并应用于大规模数据集。
1.1.2定义与挑战
对于多模态问题,.1,充分挖掘模态之间的信息,从而消除数据的异构问题带来的挑战。本文的挑战在于三点:语言任务——Masked跨模态LM、视觉任务——Masked目标预测、跨模态任务。
1.2应用场景及应用价值
本文的方法可应用于分类任务中,其包括视觉问答 (VQA)、视觉推理和合成问答 (GQA)、自然语言视觉推理 (NLVR)等。在未来的如视觉语言导航,机器人的自主功能与环境的全面了解,视觉字幕生成丰富和有意义的语言描述等等一系列场景中具有重要意义。
1.3 现有工作研究思路及取得的进展
对于现有的视觉内容,人们已经开发了几个骨干模型,并在大型视觉数据集上显示了它们的有效性。开拓性工作还通过在不同任务上微调这些预训练的骨干模型来显示它们的泛化性。在语言理解方面,论文在构建具有大规模语境化语言模型预训练的通用背骨模型方面取得了强劲进展,这将各种任务的性能提高到了显著水平。
1.4 现有工作存在的问题
视觉语言推理要求对视觉内容、语言语义以及跨模态的对齐和关系进行理解。尽管有这些影响较大的单模态研究,但针对视觉和语言模态对的大规模预训练和微调研究还很不发达。
1.5 本文所做的改进
提出了构建预先训练的视觉和语言跨模态框架的首批工作之一。并将此框架命名为“LXMERT”。该框架进一步适应有用的跨模态场景。新跨模态模型侧重于学习视觉和语言交互,尤其是单个图像及其描述性句子的表示。它由三个Transformer编码器组成:对象关系编码器、语言编码器和跨模态编码器。
1.6 本文改进所具有的优势和效果
这种多模态预训练允许模型从同一模态中的可见元素或其他模态中的对齐组件推断掩蔽特征,有助于建立模态内和模态间的关系。
在VQA(2015)和GQA(2019)数据集上。模型在所有问题类别上都优于以前的工作。此外,在NLVR2(2019)数据集上,不使用其数据集中的自然图像进行预训练,而是对真实图像进行微调和评估。模型实现了22%绝对精度和30%绝对一致性的大幅提高。最后,展示了详细的消融研究,以证明模型组件和预训练策略均对本论文成果做出了重要贡献;并提供了针对不同编码器的几种注意力可视化图。
1.7 本文主要贡献总结
提出了LXMERT框架来学习视觉和语言的联系。在LXMERT中,本论文建立了一个由三个编码器组成的大型Transformer模型。其次,为了使模型具有视觉和语言语义的融合能力,本论文利用大量的图像和句子对对模型进行了预训练,通过五个不同的预训练任务:masked语言建模、masked对象预测(特征回归和标签分类)、跨模态匹配和图像答疑。这些任务有助于学习情态内和跨情态关系。在对预先训练的参数进行微调后,本论文的模型在两个视觉问答数据集(即VQA和GQA)上都取得了最新的结果。
2. 国内外研究现状
2.1 相同或者相似问题的方法分类介绍
Visual Captioning (VC):视觉字幕,视觉字幕是一种以自动的方式为给定的视觉(图像或视频)输入生成语法和语义上适当的描述的任务。为视觉输入生成解释性和相关的字幕不仅需要丰富的语言知识,还需要对视觉输入中出现的实体、场景及其交互有连贯的理解。[1]
Visual Generation (VG):视觉生成,视觉生成是从给定的文本输入中生成视觉输出(图像或视频)的任务。它通常需要对语义信息进行良好的理解,并据此生成相关的和上下文丰富的连贯的视觉形成。
Visual retrieval(VR):视觉检索, 文本-图像检索是一项跨模态的任务,需要对语言域和视觉域进行理解,并采用适当的匹配策略。这样做的目的是根据文本描述从更大的图像库中提取最相关的图像。
Vision-Language Navigation (VLN):视觉语言导航,视觉语言导航是一种基于语言指令的主体运动的基础自然语言任务。这通常被视是一项序列到序列转编码的任务,类似于VQA。然而,这两者之间有明显的区别。VLN通常有更长的序列,问题的动态完全变化,因为它是一个实时演化的任务。[2]
Multimodel Machine Translation (MMT):多模态机器翻译,多模态机器翻译是翻译和描述生成的双重任务。它包括将描述从一种语言翻译成另一种语言,并从其他形式(比如视频或音频)中获取额外信息。[4]
2.2 相关方法的介绍
Transformer是一种基于Self-Attention机制的Seq2seq模型(序列模型),是用于机器翻译的,由编码器和解码器组成。BERT之中的Transformer仅有encoder部分,该处仅介绍此部分。[3]
图2.2-2左侧框即为encoder部分。首先是输入word embedding,这里是直接输入一整句话的所有embedding。输入embedding需要加上位置编码然后经过一个Multi-Head Attention结构。之后是做了一个shortcut的处理,就是把输入和输出按照对应位置加起来。然后经过一个归一化normalization的操作。接着经过一个两层的全连接网络,最后同样是shortcut和normalization的操作。这里需要注意的是,每个小模块的输入和输出向量,维度都是相等的。
本文在单模态编码器处,应用了两个Transformer编码器:语言编码器和对象关系编码器。

图2.2-1 Transformer结构图
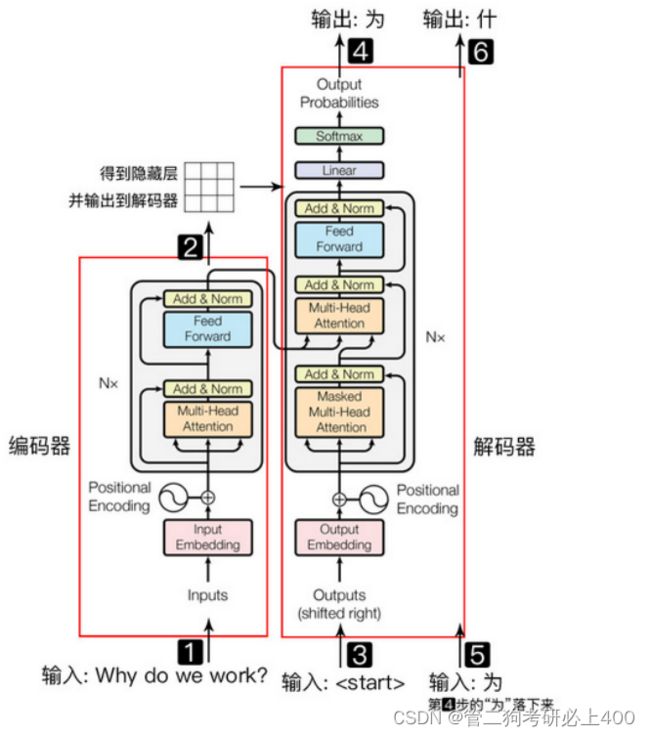
图2.2-2 Transformer流程图
新型多模态编码器:
该交叉模态编码器为本文原创编码器,其中的每个交叉模态层(图2.2-3中的右侧虚线框)均由两个自注意子层,一个双向交叉注意子层和两个前馈子层组成。在我们的编码器实现中,我们将这些交叉模态层叠加(即,使用第k层的输出作为第(k + 1)层的输入)。在第k层内部,首先应用了双向交叉注意子层(“交叉”),该子层包含两个单向交叉注意子层:一个从语言到视觉,另一个从视觉到语言。查询和上下文向量是第(k-1)层的输出(即语言特征和视觉特征):
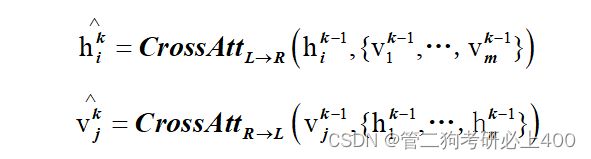
交叉注意子层用于交换信息和对齐两种模式之间的实体,以学习联合的交叉模式表示。为了进一步建立内部连接,然后将自关注子层(“self”)应用于交叉关注子层的输出:


图2.2-3 论文编码器结构图
3 方法介绍
3.1模型架构
本论文的模型接受两个输入:一个图像和它的相关句子(例如,一个caption或一个问题)。每个图像被表示为一系列的物体,每个句子被表示为一系列的单词。通过仔细设计和组合这些自注意力层和交叉注意力层,本论文的模型能够从输入中生成语言表征、图像表征和跨模态表征。
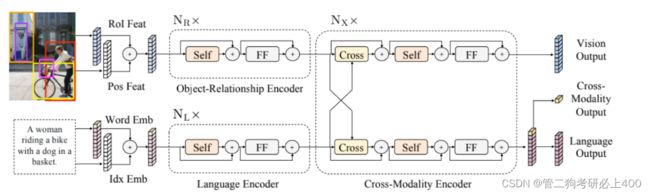
图3.1-1 论文模型主要流程结构
3.2输入嵌入
LXMERT的输入嵌入层将输入(图像和句子)分为两个特征序列:词级句子嵌入和目标级图像嵌入。这些嵌入特征将由后几个编码层进一步处理。
单词级句子嵌入。首先,使用WordPiece tokenizer将句子拆分为多个单词。然后将 Word embedding 和 positional embedding 相加后得到 index-aware word embedding,即,通过嵌入子层将每个单词及其索引(单词在句子中的绝对位置)投影到向量上,并添加到索引感知的单词嵌入中。

目标级图像嵌入。代替使用卷积神经网络输出的特征映射,本论文将被检测物体的特征作为图像的嵌入。具体地说,目标检测器检测多个目标。首先由 Faster-RCNN 检测出m个物体并返回物体的 位置特征(即,边界框坐标)和其2048维感兴趣区域(RoI)特征表示。本论文通过添加2个全连接层的输出来学习位置感知嵌入。除了在视觉推理中提供空间信息外,位置信息的包含对于本论文的masked目标预训练任务也是必要的。由于图像嵌入层和后续的注意层对其输入的绝对分值是不可知的,因此不指定目标的顺序。

3.3编码器
编码器。包括语言编码器、目标关系编码器和跨模态编码器,主要基于两种注意力层:自注意力层和交叉注意力层。
单模态编码器。在嵌入层之后,首先应用两个transformer编码器,即语言编码器和对象关系编码器,它们中的每一个都只专注于一个单一的模态(即语言或视觉)。在单模态编码器中,每层都包含一个自注意力(“Self”)子层和一个前馈(“FF”)子层,其中前馈子层进一步由两个完全连接的子层组成.。分别在语言编码器和目标关系编码器中采用NL层和NR层,在每个子层之后添加一个残差连接和层归一化。
跨模态编码器。跨模态编码器中的每个跨模态层均由两个自注意力子层,一个双向交叉注意力子层和两个前馈子层组成。在编码器实现中,将这些跨模态层叠加Nx层(即,使用第k层的输出作为第(k + 1)层的输入)。在第k层内部,首先应用了双向交叉注意力子层,该子层包含两个单向交叉注意力子层:一个从语言到视觉,一个从视觉到语言。查询和上下文向量 是(k-1)层的输出。
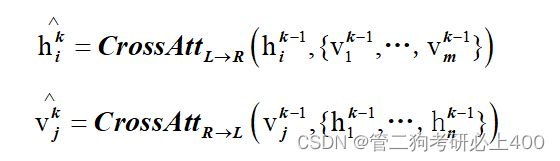
交叉注意子层用于交换信息和对齐两种模式之间的实体,以学习联合的交叉模式表示。为了进一步建立内部连接,然后将自关注子层(“self”)应用于交叉关注子层的输出:

最后,第k层输出由第k层交叉关注子层的输出顶部的前馈子层(FF)产生。 还在每个子层后添加了残差连接和层归一化,类似于单模态编码器。
LXMERT跨模态模型有三个输出,分别用于语言、视觉和交叉模态。语言和视觉输出特征序列由跨模态编码器产生的;对于跨模态输出,在句子词之前附加了一个特殊的标记[CLS],并且该特殊标记在语言特征序列中的对应特征向量被用作跨模态输出。
3.4预训练
预训练策略:为了更好地理解视觉和语言之间的联系,在一个大的聚合数据集上采用不同的模态预训练任务对模型进行预训练。
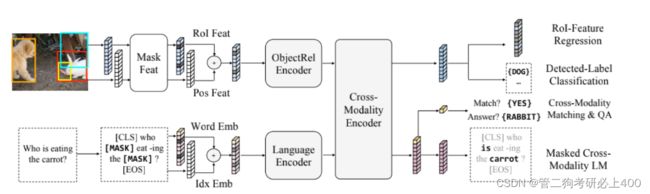
图3.4-1
预训练任务:
1.语言任务——Masked跨模态LM
任务设置与BERT几乎相同:单词被概率为0.15的随机masked,模型被要求预测这些masked。除了在BERT中,从语言模态中的非masked词预测masked词,LXMERT具有跨模态模型体系结构,可以从视觉模态中预测masked词,从而解决模糊性问题。如上图2所示。很难从其语言上下文中确定masked词“胡萝卜”,但如果考虑视觉信息,则单词选择是明确的。因此,它有助于建立从视觉模态到语言模态的联系,将这项任务称为masked跨模态LM。
2.视觉任务——Masked目标预测
通过概率为0.15的随机masked物体(即用零填充ROI特征)来预先训练视觉的一面,并要求模型预测这些masked目标的结构。与语言任务(即masked跨模态LM)相似,模型可以从可见目标或语言模态推断masked目标。从视觉方面推断目标有助于学习目标关系,从语言方面推断有助于学习跨模态对齐。因此,执行两个子任务:
1)RoI-Feature Regression:用L2损失回归对象ROI特征,
2)Detected-Label Classification:学习具有交叉熵损失的masked对象的标签。
在“Detected-Label Classification”的子任务中,虽然大多数预训练图像都有目标级注释,但在不同的数据集中,注释目标的ground truth标签是不一致的(例如,标签类别的数目不同)。因为这些原因,采用Faster RCNN把检测到的标签输出。
3.跨模态任务
如上图2中最右边部分所示。为了学习一个强大的跨模态表示,本论文用两个明确需要语言模态和视觉模态的任务对LXMERT模型进行了预训练。
其中语言模态和视觉模态的任务分别为:
1)Cross-Modality Matching:对于每个句子,按照0.5的概率,用一个不匹配的句子替换它。然后,训练一个分类器来预测图像和句子是否相互匹配。这个任务是如BERT一样进行“下一句预测”。
2)Image Question Answering (QA):为了扩大预训练的数据集,预训练数据中大约1/3的句子是关于图像的问题。当图像和问题匹配时,要求模型预测这些图像相关问题的答案。实验表明,用这种图像QA进行预训练可以得到更好的跨模态表示。
4. 实验
4.1 数据集介绍
VQAv2.0:VQA数据集包含来自Microsoft COCO数据集的图像的人工注释的问答对,所有问题类型分为是/否、数字和其他类别。Train、validation和test-standard包含82783、40504和81434张图片,分别包含443757、214354、447793个问题。每个问题包含来自不同批注者的10个答案。频率最高的答案被视为基本事实。
GQA:关于图像场景下的问答数据集。被用于对现实世界中的图像进行视觉推理与组合回答的任务中。该数据集中包括了有关各种日常图像的近2000万条问题。每个图像都与一组场景图对应。每个问题都与其语义的结构化表示相关联在一起,并且约束应答者必须采用特定的推理步骤来回答它。许多GQA的问题中涉及到了多种的推理技巧,空间理解和多步推理等,因此,通常比社区中使用的视觉问答数据集更有挑战性。数据集还确保了数据集的平衡性,严格控制不同问题组的答案分布,以防止使用语言和先验信息进行猜测。
NLVR2:给模型一对图像与一个句子,判断这句话正确与否。这个数据集的特点在于需要模型理解图像中的物体的属性,物体与物体的关系,物体与场景的关系。相较于上两个数据集具有更大的挑战,对模型的要求也更高。
4.2 评价指标
准确度ACC:
4.3 对比方法的实验结果展示与简要分析
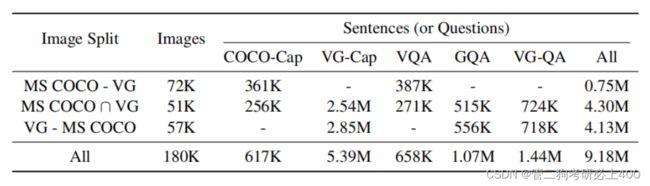 表4.3-1
表4.3-1
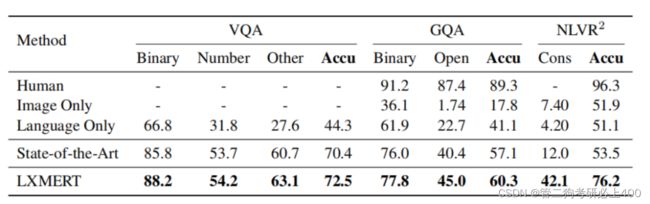 表4.3-2
表4.3-2
表4.3-1为训练前数据量,表4.3-2为测试集结果。实验中,本论文首先在两个流行的视觉问答数据集VQA和GQA上评估LXMERT。本论文的模型在所有问题类别(如二进制、数字、开放式)上都优于以往的工作,并且在总体准确性方面达到了最先进的结果。此外,为了展示本论文预训练模型的泛化能力,本论文在一个具有挑战性的视觉描述任务–自然语言用于真实的视觉推理(NLVR2)上对LXMERT进行了微调,在该任务中,本论文不使用其数据集中的自然图像进行本论文的预训练,而是对这些具有挑战性的真实世界图像进行微调和评估。在此基础上,系统的精度提高了22%,相对误差降低了48%,绝对误差提高了30%,相对误差降低了34%。LXMERT框架在所有三个数据集w.r.t.所有指标上都优于以前(可比较的)最先进的方法。
4.4 消融实验的实验结果展示与简要分析
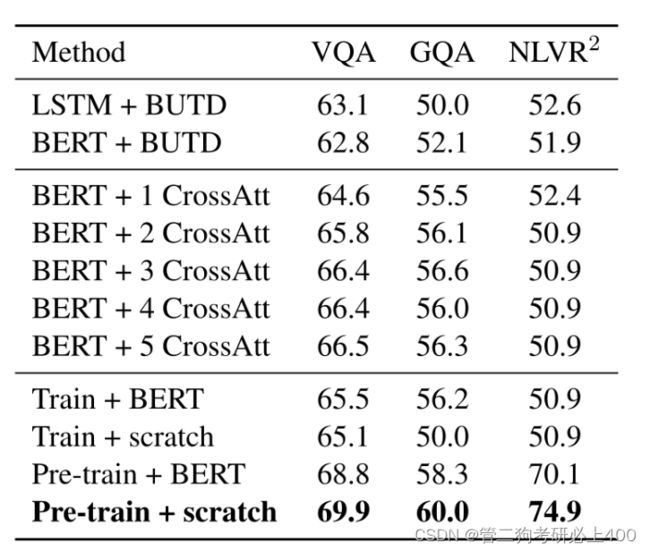 表4.4-1
表4.4-1
 表4.4-2
表4.4-2
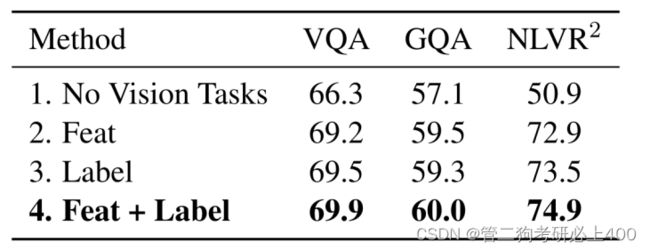
表4.4-3
如表4.4-1所示:
BERT是一种经过预训练的语言编码器,可改进多项语言任务。表中讨论了将BERT预训练模型用于视觉语言任务的几种方法,并将其与LXMERT方法进行了实证比较。虽然完整模型在NLVR2上实现了74.9%的准确率,但在不进行LXMERT预训练的情况下,所有结果都绝对低22%左右。
BERT+BUTD:自下而上和自上而下(BUTD)方法使用GRU对问题进行编码,然后关注对象RoI特征来预测答案。论文通过将其GRU语言编码器替换为BERT,将BERT应用于BUTD。如表的第一块所示,BERT编码器的结果与LSTM编码器相当。
BERT+CrossAtt:因为BUTD只取原始RoI特征,而不考虑对象位置和对象关系, 通过新颖的位置感知对象嵌入和跨模态层增强BERT+BUTD。如表4.4-1的第二块所示,1个跨模态层的结果优于BUTD,而叠加更多跨模态层则会进一步改善结果。然而,如果没有跨模态预训练(BERT是只经过语言预训练的),在添加3个交叉注意层后,结果变得稳定,与整个LXMERT框架相比有3.4%的差距。
BERT+LXMERT:论文还尝试将BERT参数加载到LXMERT中,并将其用于模型训练(即,无LXMERT预训练)或预训练。与即随机初始化模型参数方法相比,BERT改进了微调结果,但显示的结果比原论文完整模型弱。使用BERT参数初始化的训练前LXMERT在前3个训练前阶段具有更低(即更好)的训练前损失,但随后被论文的随机初始化模型方法赶上。一个可能的原因是,BERT已经用单模态掩蔽语言模型进行了预训练,因此可以仅基于语言模态而不考虑与视觉模态的联系。
总的来讲本论文进行了几个分析和消融研究,通过移除它们或与它们的替代选项进行比较来证明本论文的模型组件和不同的预训练任务的有效性,及其对本论文的结果有显著的贡献。特别地,本论文用几种方法对现有的BERT模型及其各种不同的方法进行了比较,结果表明了它们在视觉和语言任务中的不足之处,从总体上证明了本论文提出的新的跨模态预训练框架的必要性。本论文还针对不同的语言、目标关系和跨模态编码器提出了几种注意力可视化方法。
5. 个人思考
该模型在2019年度表现优异,在准确度的各方面均优于当时表现最优的模型。但Transformer依旧存在较多问题,如由于其复杂而又沉重的架构以及较小的模型偏差,Transformer通常需要一个大的训练语料库进行训练。且训练时,容易在小的或中等大小的数据集上出现过拟合问题。[5]
且在该模型下一些单词会被随机替换,而Transformer的encoder部分不知道它将被要求预测的那些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。同时,由于训练模型时,模型可能需要更多的预训练步骤才能收敛,增加了训练成本。
除此之外,本文所使用的句子-图像关系预测任务对视觉语言表征的预训练毫无帮助,可采用预训练模型VL-BERT。其可以提高对长句子和复杂句子的泛化能力。也可以改进视觉表示的调整。在VL-BERT中,快速R-CNN的参数也得到了更新,从而得到了视觉特征。为了避免语言线索掩盖的RoI分类预训练任务中的视觉线索泄漏,对输入的原始像素进行掩蔽操作,而不是对卷积层生成的特征图进行掩蔽操作。[6][7]
结 论
作者提出了一个跨模式框架LXMERT,用于学习视觉和语言之间的联系。 基于Transformer编码器和新颖的交叉模态编码器构建模型。 然后在图像和句子对的大规模数据集上使用各种预训练任务对该模型进行预训练。在LXMERT中,本论文建立了一个由三个编码器组成的大型Transformer模型:目标关系编码器、语言编码器和跨模态编码器。其次,为了使模型具有视觉和语言语义的融合能力,本论文利用大量的图像和句子对对模型进行了预训练,通过五个不同的预训练任务:masked语言建模、masked对象预测(特征回归和标签分类)、跨模态匹配和图像答疑。这些任务有助于学习情态内和跨情态关系。在对预先训练的参数进行微调后,本论文的模型在两个视觉问答数据集(即VQA和GQA)上都取得了最新的结果。
通过阅读此论文,本人进一步加深了对于计算机视觉领域的认知,了解到了多模态学习的重要性以及广泛的应用前景,也加深了对于Transformer与多模态编码器的了解以及对于Transformer的几个不同的预训练模型也有了一定程度上的认识,同时通过探寻模型存在的缺点与寻找创新点,本人阅读了大量同类论文,也收获颇丰。
参 考 文 献
- Baltrušaitis T, Ahuja C, Morency LP. Multimodal machine learning: A survey and taxonomy. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2018,41(2):423−443.
- 李 睿,郑顺义,王西旗.Application Research of Computers:视觉—语言—行为: 视觉语言融合研究综述* 1001-3695( 2020) 11-002-3206-07
- 杜鹏飞,李小勇,高雅丽.多模态视觉语言表征学习研究综述.软件学报,2021,32(2):327−348.http://www.jos.org. cn/1000-9825/6125.htm
- 刘建伟,丁熙浩,罗雄麟.Application Research of Computers:多模态深度学习综述* 1001-3695( 2020) 06-001-1601-14
- Jiasen Lu, Dhruv Batra, Devi Parikh, Stefan Lee.Computer Vision and Pattern Recognition:ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks 2019
- W Su,X Zhu,Y Cao,B Li,L Lu,F Wei,J Dai.VL-BERT: Pre-training of Generic Visual-Linguistic Representations 2020
- A Radford,JW Kim,C Hallacy,A Ramesh,G Goh,S Agarwal,G Sastry,A Askell,P Mishkin,J Clark.Learning Transferable Visual Models From Natural Language Supervision openai 2021