PyTorch深度学习实践概论笔记8-加载数据集
在第七讲PyTorch深度学习实践概论笔记7-处理多维特征的输入中讲解了如何处理多维特征的输入。接下来第八讲,来介绍在pytorch里面怎么构造数据集和DataLoader,它们都是帮助我们来加载数据的,处理之后的数据支持索引。

Dataset 和 DataLoader是加载数据的两个工具类。有时间有可以看看官方教程的这篇文章PyTorch-Tutorials【pytorch官方教程中英文详解】- 3 Datasets&DataLoaders。
- Dataset:构造数据集(数据集应该支持索引,能够用下标操作快速把数据拿出来)。
- DataLoader:主要目标是拿出一个MiniBatch(一组数据)供我们训练的时候快速使用。
0 Revision:Manual data feed

在上面的代码中,训练时每次给Model做forward的时候都是把所有的数据(x_data)传进去的。在做梯度下降的时候有两种选择:
①全部的数据都用(全部Batch)
②随机梯度下降(只用一个样本)
优点:只用一个样本可以得到比较好的随机性,可以帮助我们跨越在优化中所遇到的鞍点;而用Batch(所有数据)的优点是可以最大化地利用向量计算的优势提升计算速度。缺点:都用一个样本的随机梯度下降训练出的模型效果可能会比其他模型都更好,但是会导致优化用的时间更长,因为每次一个样本没法使用cpu或gpu的并行能力,训练的时间会很长;而使用Batch计算速度快,但是在求得性能上会遇到一些问题,所以在深度学习中我们使用MiniBatch来平衡训练时间和训练速度上的要求。
1 Terminology:Epoch,Batch-Size,Iterations
看看使用MiniBatch时的常用概念。

使用MiniBatch之后训练循环要写成嵌套循环。最外层循环每一次循环是一个Epoch,Epoch里面每一次Iteration迭代执行一个MiniBatch。
- Epoch:所有样本都参与了训练,Epoch表示一个训练周期,所有的样本都进行了正向传播和反向传播。
- Batch-size:批量大小,指每次训练所用的样本数量,进行一次前馈,一次反馈,一次更新用的样本数量。
- Iteration:表示Batch分出来多少个MiniBatch,内层的循环一共执行多少次。例如,如果有10000个样本,每个batch-size是1000,那么迭代次数Iteration=10。
2 DataLoader: batch_size=2,shuffle=True
接下来看看DataLoader能帮我们做什么?需要确定一些参数,例如batch_size=2。为了提高数据集的随机性,设置shuffle=True,将数据集打乱。

第一步是shuffle,第二步是loader,如何分成4个Batch进行迭代。
3 How to define your Dataset
接下来看代码层面如何实现Dataset和DataLoader。

上述导入的两个类中:
- Dataset是抽象类,不能实例化,只能被子类继承。
- DataLoader类用来加载数据,可以实例化,自动完成shuffle,batch-size。
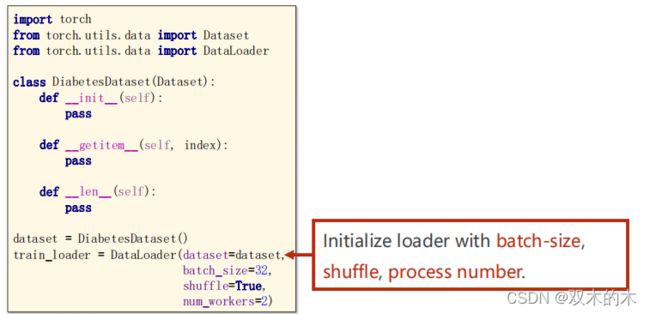
代码分析:
import numpy as np
import torch
from torch.utils.data import Dataset #Dataset是抽象类
from torch.utils.data import DataLoader #用来载入数据的类
class DiabetesDataset(Dataset): #该类继承自Dataset
def __init__(self):
pass
def __getitem__(self, index): #magic function魔法方法,支持下标操作
pass
def __len__(self):#返回数据集的长度
pass
dataset = DiabetesDataset()#实例化类
#初始化加载器
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2) #num_workers参数指读取mini-batch时是不是用多线程,要不要并行化处理数据时有两种方法:
- 读取all data,数据从__init__加载进来,都读到内存里面,然后每一次调用__getitem__方法的时通过index[i]索引,适合小数据集。
- 对于大数据集,几十G,通常把文件名放在列表中,再调用__getitem__方法去文件中读取数据,这样能保证内存的高效使用。
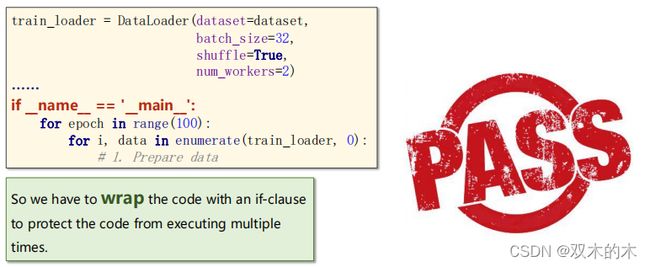
3.1 Extra: num_workers in Windows

在windows系统下,多进程和linux系统是不一样的,用spawn函数替代fork函数。所以左边的代码会出现“RuntimeError”运行时错误,解决这个问题的方式为:将代码封装起来,例如下面的形式:
4 Example: Diabetes Dataset
具体看一个例子。
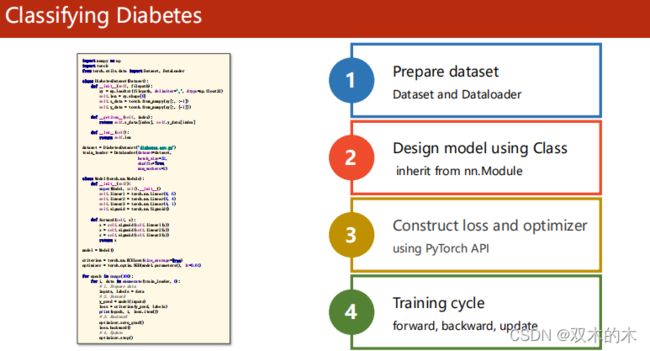
完整代码分析(还是上面的4个步骤):
import numpy as np
import torch
from torch.utils.data import Dataset,DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32) #加载数据集
self.len = xy.shape[0] #xy是N行9列,shape是元组(N,9),shape[0]=第0个元素N
self.x_data = torch.from_numpy(xy[:, :-1]) #最后一列不取
self.y_data = torch.from_numpy(xy[:, [-1]]) #取最后一列
def __getitem__(self, index):
#getitem实例化对象支持下标操作
return self.x_data[index], self.y_data[index]
def __len__(self):
#返回数据集的长度
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,
batch_size=32, shuffle=True, num_workers=2)
#构建模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#训练周期
for epoch in range(100):
#循环对train_loader做迭代,用enumerate是为了获得当前是第几次迭代
#把从train_loader拿出来的(x,y)元组放到data里面
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = data #inputs和labels都自动被转换成张量,如果上述data换成(inputs, labels)的话这行可以去掉
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()这一讲的主要改进是步骤一(加载数据采用mini-Batch)和步骤四(循环改成嵌套循环)。
5 The following dataset loaders are available
接下来看看torchvision内置的一些数据集。官网链接为torchvision.datasets — Torchvision 0.11.0 documentation (pytorch.org)。

上述提到的这些数据集都是torch.utils.data.Dataset的子类,也有__getitem__和__len__方法,可以使用DataLoader加载数据和多进程加速。
官网代码:
imagenet_data = torchvision.datasets.ImageNet('path/to/imagenet_root/')
data_loader = torch.utils.data.DataLoader(imagenet_data,
batch_size=4,
shuffle=True,
num_workers=args.nThreads)5.1 Example: MINST Dataset

MINST Dataset是手写数据集。如下你想使用数据集,你需要怎么做?
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
train_dataset = datasets.MNIST(root='../dataset/mnist',
train=True,
transform= transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
transform= transforms.ToTensor(),
download=True)
train_loader = DataLoader(dataset=train_dataset,
batch_size=32,
shuffle=True) #训练数据一般打乱
test_loader = DataLoader(dataset=test_dataset,
batch_size=32,
shuffle=False)
for batch_idx, (inputs, target) in enumerate(train_loader):
……后续有时间会出一篇识别手写数据集的文章。
6 Exercise 8-1
留下一个练习:使用kaggle上的Titanic数据集,使用DataLoader类进行分类。特征包含下面这些:
训练目标是预测某位乘客是否活下来(Survived)。练习的解答之后会更新。
说明:记录学习笔记,如果错误欢迎指正!写文章不易,转载请联系我。