PyTorch - 15 - PyTorch数据集和数据加载器 - 深度学习和AI的训练集探索
PyTorch - 15 - PyTorch数据集和数据加载器 - 深度学习和AI的训练集探索
- PyTorch Datasets And DataLoaders For Deep Learning
- PyTorch Dataset: Working With The Training Set
- Exploring The Data
- Class Imbalance: Balanced And Unbalanced Datasets
- Accessing Data In The Training Set
- PyTorch DataLoader: Working With Batches Of Data
- How To Plot Images Using PyTorch DataLoader
- Building The Model Is Next
PyTorch Datasets And DataLoaders For Deep Learning
从高角度来看,我们仍处于深度学习项目的准备数据阶段。
准备数据建立模型训练模型分析模型的结果
在这篇文章中,我们将看到如何使用在上一篇文章中创建的数据集和数据加载器对象。 请记住,在上一篇文章中,我们有两个PyTorch对象,一个数据集和一个DataLoader。
1.train_set
2.train_loader
现在,我们准备看看如何使用这些对象,让我们开始吧。
PyTorch Dataset: Working With The Training Set
让我们先来看一些我们可以执行的操作,以更好地了解我们的数据。
Exploring The Data
要查看训练集中有多少张图片,我们可以使用Pythonlen()函数检查数据集的长度:
> len(train_set)
60000
根据我们在Fashion-MNIST数据集上的帖子中学到的知识,这个60000的数字是有意义的。 假设我们要查看每个图像的标签。 可以这样完成:
> train_set.targets
tensor([9, 0, 0, ..., 3, 0, 5])
第一个图像是9,接下来的两个是零。 请记住,过去的帖子中,这些值编码实际的类名称或标签。 例如,9是踝靴,而0是T恤。
如果要查看数据集中每个标签有多少个,可以使用PyTorch bincount()函数,如下所示:
> train_set.targets.bincount()
tensor([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000])
Class Imbalance: Balanced And Unbalanced Datasets
这向我们显示,Fashion-MNIST数据集在每个类别中的样本数量方面是统一的。 这意味着我们每个班级都有6000个样本。 结果,该数据集被认为是平衡的。 如果类的样本数量不同,我们将其称为不平衡数据集。
类不平衡是一个常见问题,但是在我们的案例中,我们刚刚看到Fashion-MNIST数据集确实是平衡的,因此我们不必为项目担心。
要了解有关减轻深度学习中不平衡数据集的方法的更多信息,请参阅本文:卷积神经网络中类不平衡问题的系统研究。
Accessing Data In The Training Set
要访问训练集中的单个元素,我们首先将train_set对象传递给Python的iter()内置函数,该函数会返回一个代表数据流的对象。
对于数据流,我们可以使用Python内置的next()函数来获取数据流中的下一个数据元素。我们希望由此得到一个样本,因此我们将相应地命名结果:
> sample = next(iter(train_set))
> len(sample)
2
将样本传递给len()函数后,我们可以看到样本包含两个项目,这是因为数据集包含图像标签对。我们从训练集中检索的每个样本都包含图像数据作为张量和相应的标签作为张量。
由于样本是序列类型,因此我们可以使用序列拆包来分配图像和标签。现在,我们将检查图像和标签的类型,看看它们都是Torch.Tensor对象:
> image, label = sample
> type(image)
torch.Tensor
> type(label)
int
我们将检查形状,以查看图像是1 x 28 x 28张量,而标签是标量值张量:
> image.shape
torch.Size([1, 28, 28])
> torch.tensor(label).shape
torch.Size([])
我们还将在图像上调用squeeze()函数,以了解如何删除尺寸为1的尺寸。
> image.squeeze().shape
torch.Size([28, 28])
同样,基于我们之前对Fashion-MNIST数据集的讨论,我们确实希望看到图像的28 x 28形状。我们在张量的第一维上看到1的原因是因为需要表示通道数。与具有3个颜色通道的RGB图像相反,灰度图像具有单个颜色通道。这就是为什么我们有一个1 x 28 x 28张量的原因。我们有1个颜色通道,尺寸为28 x 28。
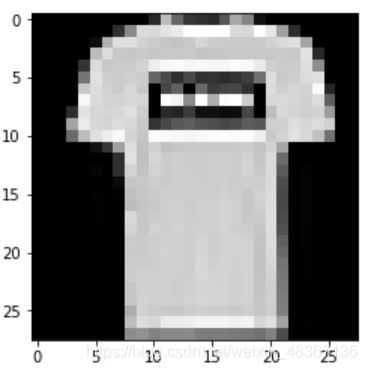
现在我们来绘制图像,我们将首先了解为什么要压缩张量。我们首先压缩张量,然后将其传递给imshow()函数。
> plt.imshow(image.squeeze(), cmap="gray")
> torch.tensor(label)
tensor(9)

我们返回了脚踝靴和标签9。我们知道标签9代表脚踝靴,因为它是在上一篇文章中查看的论文中指定的。
好的。让我们看看现在如何使用数据加载器。
PyTorch DataLoader: Working With Batches Of Data
我们将从创建一个新的数据加载器开始,该数据加载器的批量大小较小,为10,因此很容易演示发生了什么:
> display_loader = torch.utils.data.DataLoader(
train_set, batch_size=10
)
我们从装载机获得一批,就像在训练集中看到的一样。我们使用iter()和next()函数。
使用数据加载器时要注意一件事。如果shuffle = True,则每次调用next时批次将不同。如果shuffle = True,则在第一次调用next时将返回训练集中的第一个样本。随机播放功能默认情况下处于关闭状态。
# note that each batch will be different when shuffle=True
> batch = next(iter(display_loader))
> print('len:', len(batch))
len: 2
检查返回批次的长度,我们得到2就像训练集一样。让我们打开包装,看看两个张量及其形状:
> images, labels = batch
> print('types:', type(images), type(labels))
> print('shapes:', images.shape, labels.shape)
types: <class 'torch.Tensor'> <class 'torch.Tensor'>
shapes: torch.Size([10, 1, 28, 28]) torch.Size([10])
由于batch_size = 10,我们知道我们正在处理一批10张图像和10个相应的标签。这就是为什么我们在变量名称上使用复数形式的原因。
类型是我们期望的张量。但是,形状与我们在单个样品中看到的形状不同。我们没有一个标量值作为标签,而是拥有一个带有10个值的rank-1张量。张量中包含图像数据的每个维度的大小由以下每个值定义:
(批量大小,颜色通道数,图像高度,图像宽度)
批量大小为10,这就是为什么现在张量的前导尺寸为10,每个图像一个索引的原因。以下是我们之前看到的第一个踝靴:
> images[0].shape
torch.Size([1, 28, 28])
> labels[0]
9
要绘制一批图像,我们可以使用torchvision.utils.make_grid()函数创建一个可以如下绘制的网格:
> grid = torchvision.utils.make_grid(images, nrow=10)
> plt.figure(figsize=(15,15))
> plt.imshow(np.transpose(grid, (1,2,0)))
> print('labels:', labels)
labels: tensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5])

感谢Amit Chaudhary指出,可以使用permute()PyTorch张量方法代替np.transpose()。 就像这样:
> grid = torchvision.utils.make_grid(images, nrow=10)
> plt.figure(figsize=(15,15))
> plt.imshow(grid.permute(1,2,0))
> print('labels:', labels)
labels: tensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5])

回想一下,我们有下表显示了下面映射到类名的标签:
| 索引 | 标签 |
|---|---|
| 0 | T恤/上衣 |
| 1 | 裤子 |
| 2 | 头衫 |
| 3 | 礼服 |
| 4 | 外套 |
| 5 | 凉鞋 |
| 6 | 衬衫 |
| 7 | 运动鞋 |
| 8 | 包 |
| 9 | 踝靴 |
How To Plot Images Using PyTorch DataLoader
这是使用PyTorch DataLoader绘制图像的另一种方法。 此方法的灵感来自Barry Mitchell。 请享用!
how_many_to_plot = 20
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=1, shuffle=True
)
plt.figure(figsize=(50,50))
for i, batch in enumerate(train_loader, start=1):
image, label = batch
plt.subplot(10,10,i)
plt.imshow(image.reshape(28,28), cmap='gray')
plt.axis('off')
plt.title(train_set.classes[label.item()], fontsize=28)
if (i >= how_many_to_plot): break
plt.show()

Building The Model Is Next
现在,我们应该对如何探索数据集和数据加载器并与之交互有很好的了解。 当我们开始构建卷积神经网络和训练循环时,这两个都将被证明很重要。 实际上,数据加载器将直接在我们的训练循环中使用。
让我们继续前进,因为我们准备在下一篇文章中构建模型。 我会在那里见你!