Yolov5口罩佩戴实时检测项目(模型剪枝+opencv+python推理)
目录
- 0. 前言
- 1. 训练
-
- 1.1 获取口罩佩戴检测数据集
- 1.2 训练环境配置
- 1.3 修改模型文件和数据集文件
-
- 1.3.1 使用的模型
- 1.3.2 下载yaml文件并修改
- 1.4 训练
-
- 1.4.1 修改训练参数
- 1.4.2 训练结果
- 1.5 转换为onnx格式
- 2. 使用口罩佩戴实时检测项目
-
- 2.1 cv2.dnn推理yolov5n
-
- 2.1.1 读取模型
- 2.1.2 letterbox函数
- 2.1.3 推理
- 2.1.3 NMS
- 2.1.4 待续
0. 前言
如果只是想体验项目,请直接跳转到本文第2节,或者跳转到我的facemask_detect。
第1章是讲述如何得到第2章用到的onnx格式的模型文件(我的项目里直接提供了这个文件)。
第2章开始讲述如何使用cv2.dnn加载onnx文件并推理yolov5n模型。
1. 训练
本节内容:下载mask_yolo数据集
1.1 获取口罩佩戴检测数据集
原数据集在FaceMaskDetection中有获取的方法。但是其是voc格式的数据集,用在yolov5中需要转成yolo格式的;而且有多处标注存在内容遗漏。
建议直接下载我生成的yolo格式的数据集,获取链接:mask_yolo。
1.2 训练环境配置
yolov5项目对pytorch的版本较为敏感,可能有些问题在某个特定版本会出现,有些问题则不会。
举例来说,pytorch 1.12版本调用yolov5中export.py文件生成onnx文件或者detect.py调用onnx文件,会出现问题,详见issue.
pytorch需要用1.11及更低的版本。
其余库参考yolov5的requirements.txt即可。
1.3 修改模型文件和数据集文件
本节内容:clone yolov5项目;下载yaml文件并修改。
1.3.1 使用的模型
本项目使用的是yolov5系列中最小的一个模型yolov5n,因为使用最常用的yolov5s会使得推理变慢,造成延时现象。并且只是检测是否佩戴口罩,可能并不需要太大的模型。
请前往github中clone最新的yolov5(当前为6.2版本)代码,地址:yolov5。
关于yolov5网络结构图可以参考我的另一篇博文:yolov5s 6.0结构图。
1.3.2 下载yaml文件并修改
-
下载数据集的yaml文件:mask.yaml,放入
yolov5/data文件夹,并修改path路径为你下载的数据集存放的位置。

-
下载模型的yaml文件:yolov5n_mask.yaml,放入
yolov5/models文件夹。
关键参数nc=2对应:不佩戴口罩(face)和佩戴口罩(face_mask)。
1.4 训练
本节内容:修改训练参数并训练
1.4.1 修改训练参数
以下三个参数分别对应预训练权重文件、模型文件、数据集文件,填上对应的路径即可。
默认yolov5n.pt程序会自动下载,如果下载失败,请使用该链接手动下载:yolov5n.pt, 然后放置在yolov5主目录下。
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5n.pt', help='initial weights path')
# 模型yaml
parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5n_mask.yaml', help='model.yaml path')
# 修改数据集yaml
parser.add_argument('--data', type=str, default=ROOT / 'data/mask.yaml', help='dataset.yaml path')
修改imgsz参数,这个参数表示训练时图片缩放到什么尺寸,默认为640,建议改小一些,以加快训练速度,本项目这里设置为320.
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=320, help='train, val image size (pixels)')
windows端则需要修改workers参数设置为0,否则加载数据集可能会报错。
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
epochs可以调小一些,比如100或者200.
parser.add_argument('--epochs', type=int, default=200, help='total training epochs')
其余参数可以参考我的train.py.
修改完毕后,运行train.py文件即可。
1.4.2 训练结果
训练结果可以在runs/train中查看,exp后面的数字最大的,就是当前训练对应的文件夹。
查看一下验证的结果,貌似还不错,用衣服遮住口鼻的也没有被误检为face_mask。

训练文件夹中的weights文件夹存放着权重文件,我们需要best.pt。
1.5 转换为onnx格式
使用yolov5中的export.py将pytorch模型转换为onnx格式(再次提示不要使用pytorch 1.12版本,使用1.11版本及更低版本)。
该py文件中用到了onnx,请使用pip install onnx安装。
使用如下命令转换,其中runs/train/exp3/weights/best.pt修改为你自己的训练权重路径。
python export.py --weights runs/train/exp3/weights/best.pt --include onnx
然后我们就在best.pt所在的文件夹得到了best.onnx文件
export会把三个检测头的输出合并到一起(以输入为640×640为例)
(80,80,255)->(3,80,80,85)->(19200,85)
(40,40,255)->(3,40,40,85)->(4800,85)
(20,20,255)->(3,20,20,85)->(1200,85)
(19200+4800+1200,85)=(25200,85)
因此export后的模型detect只会输出一个(25200,85)的矩阵。

2. 使用口罩佩戴实时检测项目
本节内容:项目介绍和使用。
我的项目地址:facemask_detect
从github中clone下来,并根据对应的requirements.txt安装项目的虚拟环境。
该项目中的模型使用opencv-python进行onnx格式的模型推理,摆脱了对pytorch库的依赖,同时使用onnx格式会比pytorch格式进行推理速度要更加快。
项目的具体使用步骤参照项目中的README.md。
项目界面如下所示:
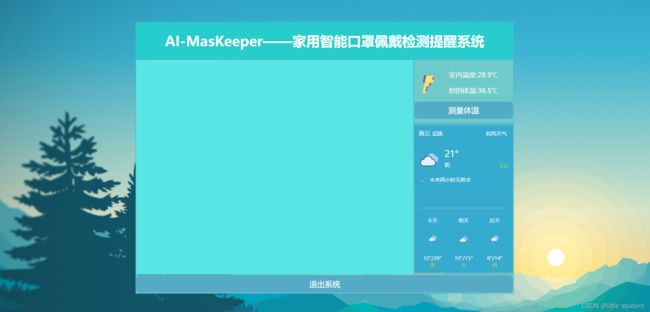
项目中的yolov5n_mask.onnx就是在1.4小节得到的best.onnx文件。
2.1 cv2.dnn推理yolov5n
如果只是想体验项目,本文到上面就结束了。
下面讲解如何使用cv2.dnn模块使用得到的onnx格式的模型文件。
这部分代码在项目中的controller/utils/yolo_inference.py中,
该部分可以大致分为
- 加载模型:cv2.dnn.readNetFromONNX
- 数据预处理:包括letterbox、BGR2RGB、归一化等
- 推理:net.forwad()
- 后处理操作:NMS、scale_boxes
- 绘制标注信息:cv2.rectangle
下面讲解其中的一些内容。
2.1.1 读取模型
opencv-python读取onnx格式的模型,需要使用cv2.dnn.readNetFromONNX函数。
net = cv2.dnn.readNetFromONNX('models/yolov5s_mask.onnx')
第三次提示之前pytorch的版本不要使用1.12版本,因为使用这个版本得到的onnx模型,上边的代码加载时会报错,请换成1.11或者更低的版本。
2.1.2 letterbox函数
yolov5在将图像数据输入到模型之前需要进行缩放操作,同时cv2.dnn中进行forward时输入的尺寸也要和训练时用到的尺寸保持一致,因为上边训练用到的是320×320的,所以模型的输入也得是320×320的,否则会报错:
cv2.error: OpenCV(4.5.5) D:\a\opencv-python\opencv-python\opencv\modules\dnn\src\layers\reshape_layer.cpp:107: error: (-215:Assertion failed) total(srcShape, srcRange.start, srcRange.end) == maskTotal in function 'cv::dnn::computeShapeByReshapeMask'
然而直接进行缩小,可能会导致图标中的目标变形,影响目标检测效果。
所以yolov5采用如下图的缩放技巧,以(750,500)缩放到(640,640)为例。
- 计算高度和宽度缩放比
- 使用最小的缩放比,保持缩放后高度和宽度仍是等比的
- 对于不足640的边,以灰色填充两边使得其达到640
通过这样的技巧既能够保持高宽比,又能达到正方形缩放的效果。

2.1.3 推理
img_trans = cv2.dnn.blobFromImage(image=img_data, scalefactor=1 / 255., swapRB=True)
net = cv2.dnn.readNetFromONNX('models/yolov5n_mask.onnx')
net.setInput(img_trans)
# 输入数据,并获得输出,yolov5中将三个检测头的输出合并到了一起
outputs = net.forward()
使用opencv读取的图片数据需要进行预处理操作:
img_trans = cv2.dnn.blobFromImage(image=img_data, scalefactor=1 / 255., swapRB=True)
- 归一化,将数据从0-255缩放至0-1:
scalefactor=1 / 255. - 将RGB转换为BGR:
swapRB=True
在推理之前需要设置输入数据:net.setInput(img_trans)
然后直接使用net.forward()得到最后一层(即Detect层)的输出。
2.1.3 NMS
2.1.4 待续
后续还有些内容需要更新,待续。当前日期:2022年10月18日