ChineseBERT Chinese Pretraining Enhanced by Glyph and Pinyin Information
文章目录
-
- ChineseBERT:中文预训练增强通过字形和拼音信息
-
- 摘要
- 1 - 介绍
- 2 - 相关工作
-
- 大规模预训练在NLP上
- 学习字形信息
- 3 - 模型
-
- 概述
- 输入
- 输出
- 4 - 预训练设置
-
- 数据
- 掩蔽策略
- 预训练细节
- 5 - 实验
-
- Machine Reading Comprehension(MRC)
- Natural Language Inference (NLI)
- Text Classification(TC)
- Sentence Pair Matching (SPM)
- Named Entity Recognition (NER)
- Chinese Word Segmentation(CWS)
- 6 - 消融研究
-
- 字形嵌入和拼音嵌入的影响
- 训练数据大小的影响
- 7 - 结论
ChineseBERT:中文预训练增强通过字形和拼音信息
摘要
最近预训练的模型关于中文的忽视了两个重要因素:字形和拼音。它们在语言理解上携带了重要的语法和语义信息。在本文的工作中,我们提出了ChineseBERT,结合汉字的字形和拼音信息。
- 字形嵌入是基于不同字体,能够从视觉特征捕获字符语义
- 拼音嵌入字符对汉字的发音进行了处理,处理了汉语中常见的同字异义现象(不同发音代表不同含义)
在大规模未标记的中文语料库上进行预训练,所提出的ChineseBERT模型有显著的性能提升,能以更少的训练步骤提高baseline,在一系列中文NLP任务上产生了新的SOTA性能,包括:机器阅读理解、自然语言推断、文本分类、句对匹配、实体识别上的竞赛表现、分词等
1 - 介绍
大规模预训练模型已经成为各种自然语言处理任务的支柱,例如自然语言理解、文本分类和问答,除了英语NLP任务,预训练模型也证明了它们对各种中文NLP任务的有效性
最初的预训练模型被设计是用于英语的,两个重要方面的因素对于中文缺失大规模预训练:字形和拼音信息。对于字形来说,一个关键因素使得中文不同于其他语言(例如:英文、德文),中国是语标语言,字符编码的语标信息的语标,例如,“液(liquid)”、"河(river)"和“湖(lake)”都有"氵(water)",表示它们都是语义上和水相关。直觉上,汉字字形背后的丰富语义应该增强中文NLP的表达能力,这个想法就哦了各种各样学习和融入中国字形到神经模型中,但还没有大规模预训练
对于拼音来说,一个中文汉字的音标表示其发音,对于语义建模是至关重要的,无法通过上下文或字形嵌入捕获其语法信息,这主要涉及到了汉语中常见的同字异义现象,同一个字有多种读音,每种读音下都与特定的含义相关联。在语义层面上,例如,汉字“乐”有两个明显的不同发音:“乐”可以发音"yue",意思是music;也可以发音"le",意思是happy。同一字符的不同发音不能通过字形嵌入来区分,因为标识是相同的,指向相同的char-ID,但是可以用拼音来表征
在这份工作中,我们提出了ChineseBERT,一个模型包含汉字的字形和拼音信息,进入大规模预训练的过程。字形嵌入是基于一个汉字的不同字体,能够从视觉表面捕获字符语义,拼音嵌入模型是具有相同字符形式却有不同语义,从而绕过了限制单个字符的交织语素。对于一个汉字,字形嵌入、拼音嵌入和字符嵌入结合起来形成一个融合嵌入,这个模型有独特的语义属性
所提出的ChineseBERT模型有显著的性能提升,能以更少的训练步骤提高baseline,在一系列中文NLP任务上产生了新的SOTA性能,包括:机器阅读理解、自然语言推断、文本分类、句对匹配、实体识别上的竞赛表现、分词等
2 - 相关工作
大规模预训练在NLP上
近年来,已开展很多大规模预训练在NLP上,BERT建立于Transformer结构上,以Masked Language Model(MLM)和Next Sentenct Prediction(NSP)方式在大规模未标记文本语料库上预训练,顺应这一趋势,通过修改Mask策略取得了很大进展,预训练任务或模型主干,具体来说,RoBERTa提出移除NSP预训练任务,它被证明没有任何好处对于改善下游性能,GPT系列和其他BERT变体,调整了范式对机器翻译、文本摘要和对话生成等文本生成任务进行大规模无监督预训练,从而使生成模型可以享受大规模预训练的好处
不同于英语,汉字有其独特特征在语法、词汇和发音上。因此,预训练中文模型应该与中国特色相对应。李等人建议使用中文字符作为基本单位,而不是英语中使用的单词或子词。ERNIE应用了三种类型的屏蔽策略:字符级屏蔽、短语级屏蔽和实体级屏蔽去增强捕获多粒度语义的能力。崔等人使用Whole Word Masking策略去预训练模型,一个汉字的所有字符均被屏蔽了,用了这个方法,该模型正在学习解决更具挑战性的任务而不是预测单词组件。最近,张等人开发了迄今为止最大的中文预训练语言模型 date-CPM,它在100GB中文数据和2.6B参数上进行预训练,可媲美“GPT3 2.7B”。徐等人发布了首个大规模汉语理解评估基准CLUE,主助力大规模汉语预训练研究
学习字形信息
学习字形信息从表面的汉字字符格式获得自从深度神经网络的普及,灵感来源于词嵌入,阴等人使用索引 radical嵌入去捕获字符语义,提高了模型在各种中文NLP任务上的性能。另一种相关字形信息是以图像的方式查看字符,通过字形信息可以自然地通过图像建模。然而,早期在学习视觉特征上不是很流畅,戴等人用CNN从字符图像中提取字形特征,但没有实现所有任务性能的提升。陶等人在此类比和词相似性任务上获得了积极的结果,但它们没有进一步评估学习字形嵌入任务。孟等人讲字形嵌入应用于广泛的中文任务,它们设计了一个特定的CNN结构为字符特征提取和使用图像分类作为辅助目标来规范有限数量图像的影响。宣等显著提高了针对BERT模型的表现
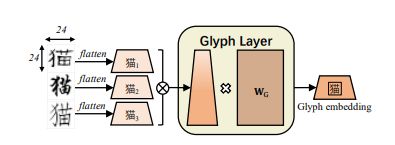
- 字形嵌入(Glyph Embedding):我们遵循孟等人使用的三种中文字体——仿宋、行楷、隶书,每一种都被实例化维一个24 * 24的图像,像素范围从0-255,不同于孟等人使用了CNNs去转换图像,我们用了FC层。我们首先将24 * 24 *3向量转化为2352向量,将扁平化向量输送给FC层以获得输出字形向量
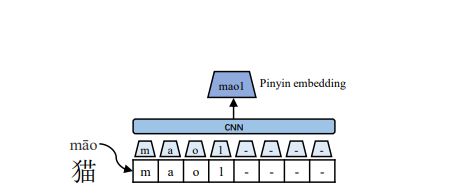
- 拼音嵌入(Pinyin Embedding):用于解耦同一字符形式的不能语义,如图3所示,我们使用开源的pypinyin包为其组成特征生成拼音序列,pypinyin是一个系统,结合机器学习模型与基于字典规则从上下文来推断字符拼音。我们使用特色标记来标识音调,它们被加到字符序列的结尾,我们在拼音序列上应用宽度为2的CNN模型,然后进行最大池化以得出拼音嵌入。这使得输出维度不受输入拼音序列长度的影响。输入拼音序列的长度固定为8,剩余槽位用特殊字母“-”填满
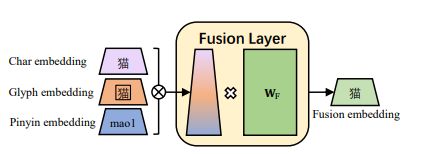
- 融合嵌入(Fusion Embedding):当我们有了字符嵌入、字形嵌入和拼音嵌入,我们可以连接它们形成一个3D维度向量,Fusion将3D维向量通过一个全连接层映射到D维,fusion嵌入增加了位置嵌入,输出到BERT层,插图显示在图4
3 - 模型
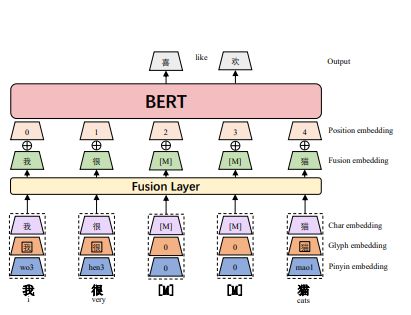
概述
图1展示了所提出的ChineseBERT模型概述,对于每个汉字,他的字符嵌入、字形嵌入、拼音嵌入首先被拼接,然后通过一个全连接层进行D维嵌入。将融入其阿努人于位置嵌入一起添加,作为BERT模型的输入。另外,由于我们不使用NSP预训练任务,我们省略段嵌入,同时使用Whole Word Masking(WWM)和Char Masking(CM)的字符掩码去预训练模型
输入
模型的输入是添加了可学习的绝对位置嵌入和融合嵌入。融合嵌入是相关字符的字符嵌入、字形嵌入、拼音嵌入,字符嵌入的执行方式类似于BERT中的token嵌入
输出
输出是每个输入汉字对应的上下文表示
4 - 预训练设置
数据
CommonCrawl(移除过多的英文文本和过滤html标签)数据集,大约10%的高质量数据被使用,含4B中文字符总数。使用LTP工具包去识别中文边界的Whole word masking
掩蔽策略
使用了两种掩码策略——Whole Word Masking(WWM)、Char Masking(CM)
李等人建议使用汉字作为基本的输入单元,能缓解汉语种的out-of-vocabulary问题,因此我们采用了在上下文种随机遮蔽一些字符,表示为CM。另一方面,大量中文单词由多个字符组成,CM策略可能对他们来说太容易了对于要预测的模型。例如,当输入内容“我喜欢逛紫禁[M](i like going to The Forbidden [M])”,模型很容易地预测masked字符是“城(City)”,因此,我们遵循崔等人用WWM,一种能屏蔽所选单词中的所有字符,能缓解CM易于预测的缺点。注意,对于WWM和CM,基本输入单元是汉字,WWM和CM的区别在于如何掩盖字符以及模型如何预测masked字符
预训练细节
崔等人预训练他们的模型是基于官方的中文BERT模型,我们训练ChineseBERT模型是从头开始,为了增强模型在学习长期、短期的依赖,我们建议在packed输入和single输入时交替进行预训练,packed输入是多个句子的串联,最大长度为512,single输入是单个句子。我们以0.9的概率packed输入和0.1的概率single输入,90%的时间用WWM和10%的时间用CM。每个word/char的masking可能性为15%,若第i个word/char被选择,我们将用80%的时间mask它,以10%的时间去替换它为随机的word/char和维持10%的时间。我们也使用动态mask策略去避免重复的训练示例,我们用了两种模型设置:
- 基本:12个Transformer层,输入维度768,12个维度层
- 大型:24个Tranformer层,输入维度1024,16个维度层
这使得我们模型和其他的BERT-style模型就模型大小而言有可比性,基于论文提交,我们已经训练
- 基本模型:500K步;最大学习率1e-4;预热20K步;一个batch3.2K,
- 大模型:280K步;最大学习率3e-4;预热90K步;batch大小8k
在预训练后,模型可以直接进行微调用于同BERT相同的方式去处理下游任务
5 - 实验

我们对各种类型的中文NLP任务进行了实验,模型在特定任务的数据集上单独微调进行评估,具体来说,我们使用了以下任务:
- Machine Reading Comprehension (MRC)
- Natural Language Inference (NLI)
- Text Classification (TC)
- Sentence Pair Matching (SPM)
- Named Entity Recognition (NER)
- Chinese Word Segmentation (CWS)
我们将ChineseBERT与当前sota的ERNIE、BERT、MacBERT进行比较。
- ERNIE采用了各种各样的掩码策略包括token-level、phrase-level、entity-level去预训练BERT在大规模异构数据上
- BERT-wwm/RoBERTa-wwm继续在官方的中国BERT/RoBERTa预训练模型,使用WWM掩码策略
- 除非特殊,我们用BERT/RoBERTa来表示BERT-wwm/RoBERTa-wwm并省略“wwm”
- MacBERT在RoBERTa的基础上使用了MLM-As-Correlation(MAC)预训练策略以及sentence-order-prediction(SOP)任务
值得注意的是,BERT和BERT-wwm没有在线提高大版本,因此我们省略了相应的展示,这些模型比较如表1所示,值得注意的是,提出的模型明显小于baseline模型,不同于BERT-wwm,MacBERT是被预训练的BERT初始化,而ChineseBERT是从来开始。由于额外考量字形和拼音,过程不能直接使用vanilla BERT模型初始化,模型架构不同,甚至初始化也要从头开始,所提出的模型训练不是少于BERT-wwm和MacBERT
Machine Reading Comprehension(MRC)
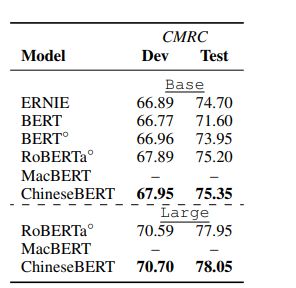
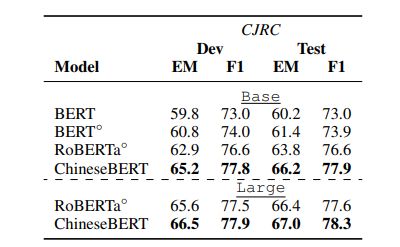
MRC:模型能根据给定的上下文回答问题的能力
两个数据集:CMRC、CJRC
- CMRC:一种跨度提取数据集,包含10k、3.2K、4.9K的训练、开发、测试数据实例
- CJRC:有yes/no 问题和没有答案问题,包含39k、6K、6K的训练、开发、测试数据实例
结果如表2表3所示,ChineseBERT在两个数据集上都产生了显著的性能提升,并且在CJRC数据集上,EM的提升比F1多。这表面ChineseBERT是更擅长检测准确的答案跨度
Natural Language Inference (NLI)
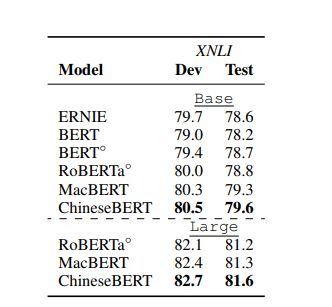
NLI:目标是缺点假设和前提之间的蕴含关系
数据集:XNLI(Cross-lingual Natural Language Inference)
- XNLI:语料库是一个crowd-sourced集合,5k测试、2.5k开发对于MultiNLI语料库
每个句子对都有包含“entailment”、“neutral”、“contradication”标签,我们使用官方机器翻译中文数据去训练,结果列于表4,这表明Chinese能够再base和lagre设置中实现最佳性能
Text Classification(TC)
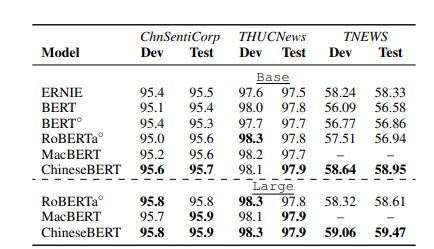
TC:将一段文本分类为指定的文本类
数据集:ChnSentiCorp、THUCNews、THEWS
- ChnSentiCorp:有一个二元情感分类数据,包含9.6K/1.2K/1.2K数据,分别是训练/开发/测试
- THUCNews:是THUCTC的一个字节,含50K/5K/10K的数据,分别是训练/开发/测试,数据包含10个领域
- THEWS:是15类短新闻文本分类数据集,包含53K/10K/10K,分别是训练/开发/测试
前两个数据集相较而言比较简单,在普通的BERT上准确率达95%以上,最后一个比较难,是CLUE的数据集。如表5所示,在CHunSenitCorp、THUCNews上,ChineseBERT比较之下提示不明显,因为baselines已经相当高了,但在THEWS上,ChineseBERT优于其他型号。
另外,我们可以看到ERNIE模型性能略差于ChineseBERT,这是因为ERNIE受过训练在额外的网络数据上,有利于建模哪些涵盖广泛领域的网络新闻文本
Sentence Pair Matching (SPM)
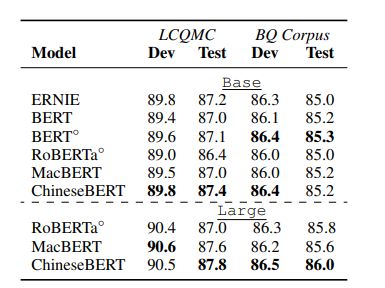
SPM:模型要求对给定的句子对表达相同的语义
数据集:LCQMC、BQ
- LCQMC:用于判断两个给定问题使用具有相同意图的大规模中文问题匹配语料库,包含23.9K/8.8K/12.5K,用于训练/开发/测试的句子对
- BQ:另一个大规模的中文数据集,包含100K/10K/10K句子对,用于训练/开发/测试的句子对
结果如表6所示,ChineseBERT在总体上优于MacBERT,但略逊于BERT-wwm在LCQMC数据集上。
我们假设这是因为BQ的语料库比ChineseBERT更适合于BERT-wwm的预训练数据
Named Entity Recognition (NER)
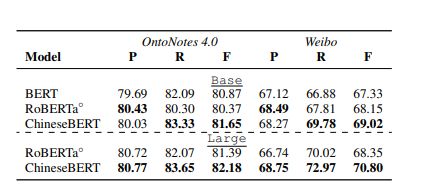
NER:模型识别一段文本中的命名实体,形式化为序列标记任务
数据集:OntoNotes 4.0、Weibo
- OntoNotes 4.0:有18中命名实体类型,包含15K/4K/4K的训练/开发/测试实例
- Weibo:有4种命名实体类型,包含1350/270/270的训练/开发/测试实例
结果显示在表7种,ChineseBERT在术语方面明显优于BERT和RoBERTa在F1上,尽管精度对于基础班略有下降,召回收益提高明显,最终F1性能提升
Chinese Word Segmentation(CWS)
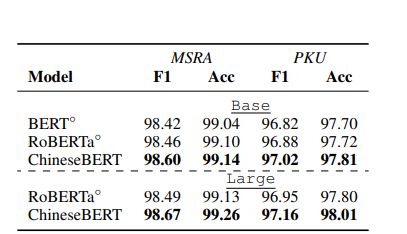
CWS:将文本分成单词并形式化,其作为字符的序列标记任务
数据集;PKU、MSRA数据集
- PKU:19K/2K个句子组成,用于训练/测试
- MSRA:87K/4K个句子组成,用于训练/测试
输出字符被送到softmax函数以进行最终的预测,结果如表8所示,其中ChineseBERT在两个数据集上优于BERT-wwm和RoBERTa-wwm
6 - 消融研究
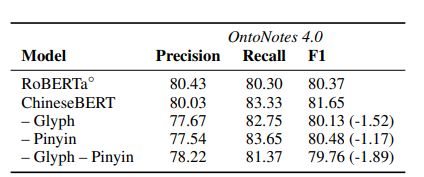
字形嵌入和拼音嵌入的影响
我们想探讨字形嵌入和拼音嵌入的效果,为了公平比较,我们在相同的模型上预训练了不同的模型数据集,具有相同数量的训练步骤,以及具有相同的模型尺寸,包括设置”-glyph“、”-pinyin“、"-glyph-pinyin",我们微调不能的模型在NER数据集的OntoNotes数据集上,结果如表9所示:
- 删除字形嵌入或拼音嵌入会导致性能下降
- 去除两者的负面影响最大
这验证了两者的重要性,另外,在"-glyph-pinyin"上表现比RoBERTa差的是我们在这里使用针对较小规模的数据进行训练,使用比较小的训练步骤
训练数据大小的影响
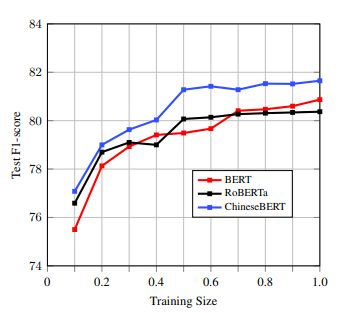
我们还假设字形和拼音嵌入作为文本语义的强正则化,这意味着提出的ChineseBERT模型能够以更少的训练表现更好,我们随机抽取10%-90%的训练数据,同时保持样本同实体w.r.t,样本没有实体。
我们每个实验进行5次得出F1均值在测试集上,如图5所示,ChineseBERT执行在所有设置中更好,不到30%的训练数据,ChineseBERT的改进是轻微的,但有超过30%的训练数据,性能提升明显。这是因为ChineseBERT仍然需要足够的训练数据全民训练字形和拼音嵌入,训练数据不足会导致训练不够充分
7 - 结论
在本文中,我们介绍了ChineseBERT,一种大规模预训练中文NLP模型,它利用汉字的字形和拼音信息,增强模型的捕捉能力从表面字符形式和消除汉语多音字中。
所提出的ChineseBERT模型在广泛的中文NLP任务中表现优异,表明引入字形嵌入和拼音嵌入服务在中文上将作为语义建模的强大正则化工具。未来的工作训练ChineseBERT的尺寸