ACL2021相关论文阅读(之)语言模型
ACL2021最近放榜啦,找了一些比较熟悉的领域论文略读,主要是记录一下文章的思想(毕竟论文太多了一篇篇仔细看看不过来)。此篇文章是一个合集,并会不断更新,主要内容是有关语言模型的。接下来还会放记录一些情感分析、实体识别、文本表示学习等。
目录
- 1. ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
-
- Model
- 2. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
-
- Intrinsic Dimension
- INTRINSIC DIMENSIONALITY OF COMMON NLP TASKS
-
- SENTENCE PREDICTION
- ANALYSIS
- PRE-TRAINING INTRINSIC DIMENSION TRAJECTORY
- PARAMETER COUNT AND INTRINSIC DIMENSION
- 总结
- 3. What Context Features Can Transformer Language Models Use?
- 4. Selecting Informative Contexts Improves Language Model Finetuning
- 5. BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?
-
- Scoring Function
- 实验结果简述
1. ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information

本篇文章旨在通过汉语拼音和字形对预训练语言模型进行增强。关键的地方是如何引入拼音和字形?
Model
对每个汉字,先将其字符嵌入、字形嵌入和拼音嵌入串联起来,再通过全连通层映射到d维嵌入,形成融合嵌入。融合嵌入与位置嵌入一起被作为BERT模型的输入。
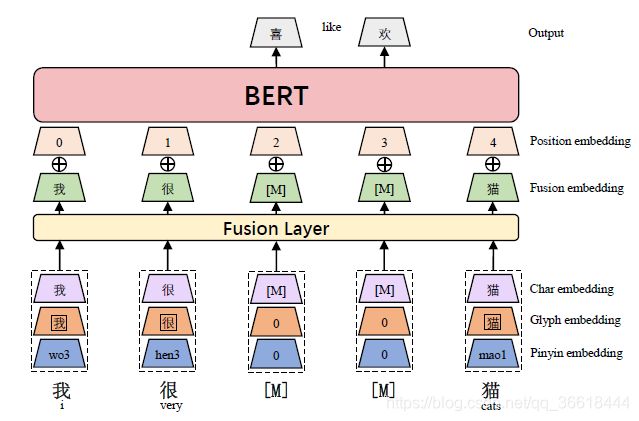
对于字形,使用仿宋、行楷、隶书三种类型的中文字体,每种字体都实例化为一个24×24像素的图像,浮点像素范围为0到255。之后把24×24×3向量转换成2352向量。该扁平向量被提供给FC层,以获得输出字形向量:
对于拼音,首先借助pypinyin将汉字转化为拼音,将宽度为2的CNN模型应用于拼音序列上,然后使用最大池化算法得到拼音嵌入结果。输入拼音序列的长度固定为8,当拼音序列的实际长度不达到8时,剩余的槽填充一个特殊的字母:

一旦有字符嵌入、字形嵌入和拼音嵌入字符,我们将它们连接起来形成一个三维向量。融合层通过一个完全连接的层将三维矢量映射到d维。融合嵌入加入位置嵌入,输出到BERT层。如图4所示:

2. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning

虽然预训练的语言模型可以进行微调,从而为非常广泛的语言理解任务产生最先进的结果,但这一过程的动态尚未被很好地理解。本文从内在维度(intrinsic dimension)的角度分析微调现象,为我们解释这一显著现象提供了经验和理论的直观依据。本文指出,一般的预训练模型具有非常低的内在维度;换句话说,存在一个低维重参数化,它与全参数空间的微调一样有效。所以在微调的时候,相当于在低维内在维度上进行调节,因此可以使用少量的下游任务数据得到很好的效果。
Intrinsic Dimension
目标函数的内在维数度量了达到各自目标的满意解所需的最小参数数。准确计算目标函数的内在维数是一个计算难题;因此,我们采用启发式方法来计算上界。首先让 θ D = [ θ 0 , . . . θ m ] \theta^D=[\theta_0,...\theta_m] θD=[θ0,...θm]是模型的一组参数,内在维度通过优化低维 d d d维的重参数化后的参数微调模型,而不是在 D D D维的原参数空间:
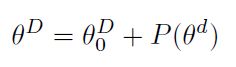
其中 P P P将参数从低维 d d d投射到高维 D D D。因为内在维度对应了一个较小的子空间,因此在其上的优化往往达不到原空间的精度,本文定义满足原空间90%的效果的子空间为 ( d 90 ) (d_{90}) (d90)。例如,如果我们训练一个包含所有参数的模型的准确率达到85%,目标是找到最小的 d d d使得0.9×85% = 76.5%。这里,省略原文中一些对内在维度的改进。
INTRINSIC DIMENSIONALITY OF COMMON NLP TASKS
SENTENCE PREDICTION
首先从GLUE Benchmark中对一组句子预测任务中各种预训练模型的内在维数进行了实证计算。下图显示了DID(内在维度)方法在两个数据集和四个模型上跨维d范围的评价精度。每个图中的水平线代表各自完整模型的90%解。这里可以看出在超过了 d 90 d_{90} d90的最低值之后,增加子空间的维度,其精度还会继续上升。

ANALYSIS
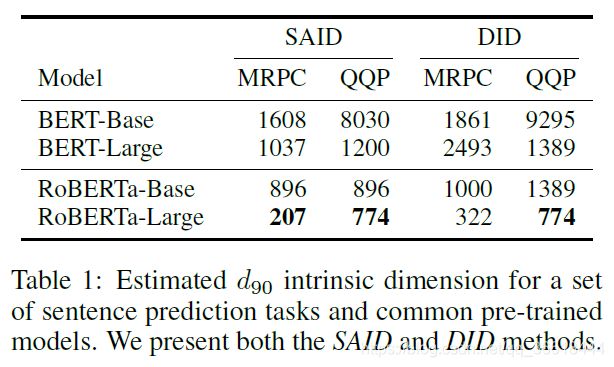
SAID(改进的内部维度计算方法)与DID下 d 90 d_{90} d90的维度。
PRE-TRAINING INTRINSIC DIMENSION TRAJECTORY
从无开始重新训练了一个RoBERTa-Base,并在不同的检查点上使用SAID方法测量了各种NLP任务的内在维度。
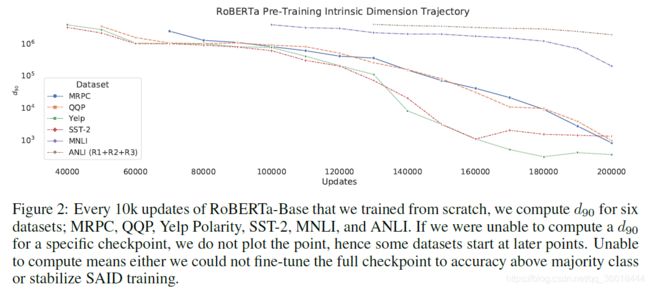
预训练模型预训练得越好, d 90 d_{90} d90点所需的参数空间就越小。
PARAMETER COUNT AND INTRINSIC DIMENSION
测量任意预训练模型的参数计数和下游NLP任务的内在维度之间的关系。随着参数数量的增加,MRPC微调的内在维度下降:

总结
还有一些结论就不列举了,感兴趣的可以看原文。本文提供了一种研究预训练语言模型的思路,其拓展性其实是一般的,不过这些结论可能会给相关的研究者启发。
3. What Context Features Can Transformer Language Models Use?
本文试图回答Long Context中的哪些信息对Transform为基础的语言模型有效。实验测量了增加LM上下文大小时所增加的可用信息的数量,然后试图通过消除所增加上下文的特征(通过混洗和单词删除)来确定这些信息的来源,并测量模型预测能力的损失。
为了衡量可用信息,给出如下定义:
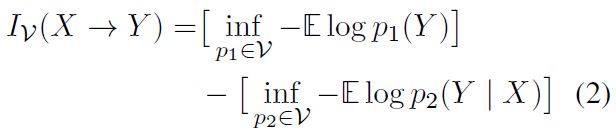
这个定义度量了预测结果为V的预测器可以从X中提取多少关于Y的额外信息。这里 V V V是一类,其概率分布为 p p p。在语言建模中,我们将Y作为目标词,X是上下文,V是一个类比的参数模型。我们应该训练一个没有访问X的模型 p 1 p_1 p1,训练一个有访问X的模型 p 2 p_2 p2,并比较它们预测的准确性。
举一个典型的例子,假设超过五个token远,模型就只能从名词中提取有用的信息。那么对于下述的句子,如果想要根据上下文预测‘director’这个词,就只能看之前的五个词,也就是 p 2 p_2 p2、公式(4)中给出的ordinary context。此外,还可以从超过5个token的上文的名词中获益,所以有noun-only context。但实际上,本文假设的Long context要远比5大的。

将单词转化为公式,就得到一个更加抽象的概述(上文 X 0 : n X_{0:n} X0:n对 X n X_n Xn的贡献信息大小):
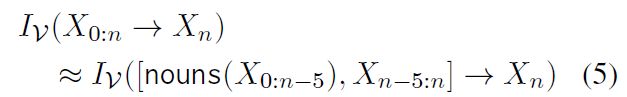
那么,假如长上下文中管用的信息不仅仅是名词,就需要一个更加抽象的公式来描述对上文进行的操作(删除、重排序等),文中叫做ablated context:
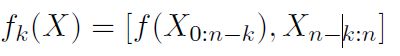
其中, f f f代表一个ablation(比如noun就是一个ablation), k k k表示偏移量,用于固定上文的最远窗口。在此基础上又定义ablated negative log-likelihood:
![]()
这样就就能测量每个ablation对可用信息的影响:

A ( f , k ) A(f,k) A(f,k)表示消融上文后的信息衰减,如果接近于0,则表示ablation几乎不删除任何信息;如果接近于1,则几乎所有信息都被删除。
实验部分探究了不同的ablation对信息的影响。包括:不同的词序重排、不同词性的词删除等;(这里以词序为例子)。下图中不同bar的代表不同的shuffle操作,比如对整个句子进行混洗、混洗trigrams等。


4. Selecting Informative Contexts Improves Language Model Finetuning

本篇文章的思路和上一篇差不多,都是使用信息增益来进行模型效果的衡量。不同的是,本文通过信息增益训练一个次级学习器,试图量化微调每个给定的例子的好处,并用于决定是否应该对每个给定的例子进行训练或跳过。
首先,对于语言模型 L L L,以及参数 θ \theta θ,其目标是估计给定token序列 X X X下的下一个token的概率分布:
![]()
使用困惑度定义测试集 T \Tau T上的损失函数 Λ \Lambda Λ:

当遇到一个新的训练例子 ( X ; Y ) (X;Y) (X;Y),模型有两个行动可以选择:进行反向传播并得到新的参数 θ ′ \theta' θ′;跳过当前实例。次级学习器通过量化这个新的实例 ( X ; Y ) (X;Y) (X;Y)的信息增益并决定选择哪种动作。为了学习次级学习器,选取训练数据集的一个目标集(objective set),计算在给定示例 ( X ; Y ) (X;Y) (X;Y)训练之前和之后,该目标集测量的困惑的差异,以量化该示例的信息增益【information gain (IG)】:
![]()
为了选择动作,有必要设立一个阈值:

I G ( X ) IG(X) IG(X)是信息增益(简写的), T S K I P T_{SKIP} TSKIP是自由“阈值”参数,用于决定哪个IG(x)带来的信息增益不足,对应的样本需要被跳过。把这种技术简称为信息增益过滤IGF(information gain filtration)。通过测量从我们的训练集中随机选取的一组训练例子的IG(X)来为我们的次级学习器构建一个训练数据集:
![]()
这个次级学习器是以训练token样本以及其可能的信息增益之间的参数的。在语言模型微调过程中,我们以一种贪婪的策略来应用训练的学习器:
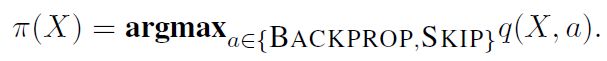
5. BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?

这篇文章的想法有点意思,探究了预训练模型学习类比的能力。什么是类比?比如,中国首都是北京,英国首都是伦敦,模型应该能够学习这种潜在的关系。类比任务的定义如下:首先给定一个查询的单词对 ( h q , t q ) (h_q, t_q) (hq,tq),需要模型从给定的候选集 { ( h i , t i ) } i = 1 n \{(h_i,t_i)\}_{i=1}^n {(hi,ti)}i=1n中选出最为相似的答案单词对。
实际上,对于预训练LM来说,输入应该是一个句子或是段落,而类别识别的任务则是输入一个单词对。因此,需要通过单词对生成一个Prompt,将单词转化为句子,可以通过LM学习上下文的关系。本文中,定义prompt为一个四元组:
![]()
比如给定一个query “word:language”以及一个候选“note:music”,生成的prompt为:
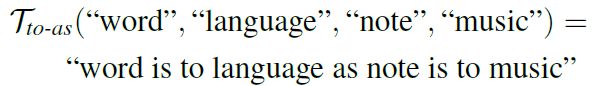
这样就得到了本任务的输入。之后,还需要制定类比学习效果的得分函数。
Scoring Function
首先给出困惑度(perplexity)的定义:
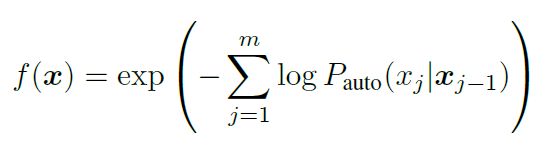
也就是给定一个token的前 j − 1 j-1 j−1个词,预测第 j j j个词的概率的likelihood。当然,对于GPT这种单向的LM,可以使用这种方式;而对于Bert系列的双向模型,提出了一个伪困惑度(pseudo-perplexity)去评价LM的好坏。使用 p m a s k ( x j ∣ x / j ) p_{mask}(x_j|x_{/j}) pmask(xj∣x/j)去代替 p a u t o p_{auto} pauto,这里 x / j x_{/j} x/j表示 j j j的上下文:
![]()
这里原文有一个小错误,是 x j − 1 x_{j-1} xj−1,我看的是预印本,正式发表的版本应该会改正。在困惑度的基础上,可定义point-wise mutual information (PMI):条件似然和边际似然之间的差,具体写作:

概率可以使用困惑度去估计:
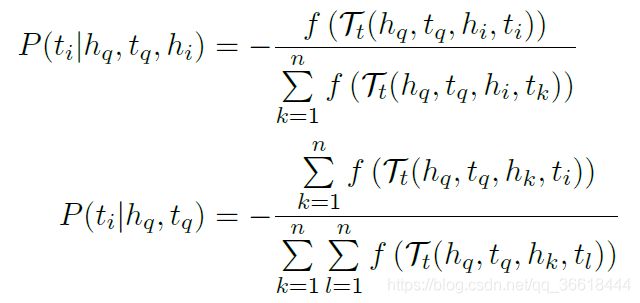
其中 n n n是候选的单词对的个数。从理论来说,这些概率应该是对称的,比如 P ( h i ∣ h q , t q ) = = P ( t i ∣ h q , t q ) P(h_i|h_q,t_q)==P(t_i|h_q,t_q) P(hi∣hq,tq)==P(ti∣hq,tq),因为候选集实际上是一个pair,因此估计head和tail都没有差别。但是实际上,由于借助了困惑度得到的概率是估计值,所以并不对称,因此需要使用一个聚合函数去得到 P ( h i ∣ h q , t q ) P(h_i|h_q,t_q) P(hi∣hq,tq)以及 P ( t i ∣ h q , t q ) P(t_i|h_q,t_q) P(ti∣hq,tq)合并之后的结果:
![]()
这里的 A g A_g Ag是聚合函数,通常采用都是最大最小平均之类的操作, r r r为:
![]()
是由本应对称的概率值组成的一个列表。
mPPL。marginal likelihood biased perplexity,是评分函数的进一步改进:

S P P L S_{PPL} SPPL是一个标准化的perplexity:

跟PMI的定义差不多。
实验结果简述
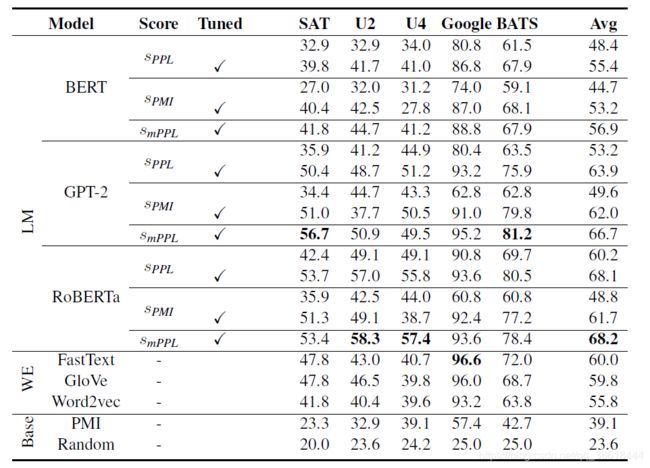
本文借助提出的评价函数评价了不同模型在不同数据集上识别类比的能力。在LM之间的比较中,RoBERTa和GPT-2的性能始终优于BERT。在AP变体中,smPPL几乎在所有情况下都比sPMI或sPPL取得了明显更好的结果。我们还观察到,单词嵌入的表现惊人地好,FastText和GloVe在大多数数据集上的表现优于BERT,当使用默认超参数值时,GPT-2和RoBERTa的表现也优于BERT。FastText在谷歌数据集上取得了最好的整体准确性,这证实了该数据集特别适合单词嵌入。