【文献阅读】ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
Abstract
最近的中文预训练模型忽略了中文特有的两个重要方面:字形和拼音,它们携带重要的句法和语义信息,用于语言理解
我们提出了 ChineseBERT,它将汉字的字形和拼音信息结合到语言模型预训练中
字形:汉字的不同字体
字音:汉语拼音(处理多音字)
Introduction
由于预训练模型最初是为英语设计的,因此在当前的大规模预训练中缺少两个特定于中文的重要方面:基于字形的信息和基于拼音的信息
对于前者,使中文与英语、德语等语言区分开来的一个关键方面是汉语是一种表意语言。 字符的语标对语义信息进行编码。 例如,“液(液)”、“河(河)”、“湖(湖)”都有部首“氵(水)”,表示它们在语义上都与水有关。 直观地说,汉字字形背后丰富的语义应该增强中文 NLP 模型的表达能力。
关于字形
这个想法激发了学习和将汉字字形信息整合到神经模型中的各种工作
Y aming Sun, Lei Lin, Nan Y ang, Zhenzhou Ji, and Xiaolong Wang. 2014. Radical-enhanced chinese character embedding. In International Conference on Neural Information Processing, pages 279–286.Springer.
Xinlei Shi, Junjie Zhai, Xudong Y ang, Zehua Xie, and Chao Liu. 2015. Radical embedding: Delving deeper to Chinese radicals. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (V olume 2: Short Papers), pages 594–598, Beijing, China. Association for Computational Linguistics.
Frederick Liu, Han Lu, Chieh Lo, and Graham Neubig. 2017. Learning character-level compositionality with visual features. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, V ancouver , Canada, July 30 - August 4, V olume 1: Long Papers, pages 2059–2068.
Falcon Z Dai and Zheng Cai. 2017. Glyph-aware embedding of chinese characters. In Proceedings of the First Workshop on Subword and Character Level Models in NLP , Copenhagen, Denmark, September 7, 2017, pages 64–69.
Tzu-Ray Su and Hung-Yi Lee. 2017. Learning chinese word representations from glyphs of characters. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, EMNLP 2017, Copenhagen, Denmark, September 911, 2017, pages 264–273.
Y uxian Meng, Wei Wu, Fei Wang, Xiaoya Li, Ping Nie, Fan Yin, Muyu Li, Qinghong Han, Xiaofei Sun, and Jiwei Li. 2019. Glyce: Glyph-vectors for chinese character representations. In Advances in Neural Information Processing Systems, volume 32, pages 2746–2757. Curran Associates, Inc.
关于字音
多音字问题
同一个字符的不同发音不能通过字形嵌入来区分,因为它是相同的,或者 char-ID 嵌入,因为它们都指向相同的字符 ID,但可以用拼音来表征。
本文计划
我们提出了 ChineseBERT,一种将汉字的字形和拼音信息融入到大规模预训练过程中的模型。
字形嵌入基于汉字的不同字体,能够从视觉表面字符形式中捕捉字符语义。
拼音嵌入模拟了共享相同字符形式的不同语义含义,从而绕过了单个字符后面的缠绕词素的限制。
对于一个汉字,将字形嵌入、拼音嵌入和字符嵌入结合起来形成一个融合嵌入,该融合嵌入对该字符的独特语义属性进行建模。
达到SOTA,state of the art
Related work
大规模预训练模型
对bert模型的修改
修改掩蔽策略
Zhilin Y ang, Zihang Dai, Yiming Y ang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in neural information processing systems, pages 5753–5763.
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. 2020. Spanbert:Improving pre-training by representing and predicting spans. Transactions of the Association for Computational Linguistics, 8:64–77.修改预训练任务
Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao. 2019a. Multi-task deep neural networks for natural language understanding. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4487–4496, Florence, Italy. Association for Computational Linguistics.
Kevin Clark, Minh-Thang Luong, Quoc V . Le, and Christopher D. Manning. 2020. Electra: Pretraining text encoders as discriminators rather than generators. In International Conference on Learning Representations.模型主体
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. Albert: A lite bert for self-supervised learning of language representations. In International Conference on Learning Representations.
Guillaume Lample, Alexandre Sablayrolles, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2019. Large memory layers with product keys. Advances in Neural Information Processing Systems (NeurIPS).
Krzysztof Choromanski, V alerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamás Sarlós, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, and Adrian Weller. 2020. Rethinking attention with performers. CoRR.Roberta(提议移除 NSP 预训练任务)
GPT系列
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI Blog, 1(8).
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners.其他bert模型变体
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, V es Stoyanov, and Luke Zettlemoyer. 2019. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and TieY an Liu. 2019. Mass: Masked sequence to sequence pre-training for language generation. In International Conference on Machine Learning, pages 5926–5936.
Guillaume Lample and Alexis Conneau. 2019. Crosslingual language model pretraining. Advances in Neural Information Processing Systems (NeurIPS).
Li Dong, Nan Y ang, Wenhui Wang, Furu Wei, Xiaodong Liu, Y u Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. 2019. Unified language model pre-training for natural language understanding and generation. In Advances in Neural Information Processing Systems, volume 32, pages 13063– 13075. Curran Associates, Inc.
Hangbo Bao, Li Dong, Furu Wei, Wenhui Wang, Nan Y ang, Xiaodong Liu, Y u Wang, Songhao Piao, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. 2020. Unilmv2: Pseudo-masked language models for unified language model pre-training.
Jinhua Zhu, Yingce Xia, Lijun Wu, Di He, Tao Qin, Wengang Zhou, Houqiang Li, and Tieyan Liu. 2020. Incorporating bert into neural machine translation. In International Conference on Learning Representations.
针对汉语的修改
提出以汉字为基本单位,而不是英文中使用的单词或子词
Xiaoya Li, Y uxian Meng, Xiaofei Sun, Qinghong Han, Arianna Y uan, and Jiwei Li. 2019b. Is word segmentation necessary for deep learning of Chinese representations? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3242–3252, Florence, Italy. Association for Computational Linguistics.Y onghui Wu, Mike Schuster, Zhifeng Chen, Quoc V . Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Y uan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Y oshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Y oung, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, and Jeffrey Dean. 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation.
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 1715– 1725, Berlin, Germany. Association for Computational Linguistics.
ERNIE应用了三种类型的掩码策略——字符级掩码、短语级掩码和实体级掩码——以增强捕获多粒度语义的能力
Y u Sun, Shuohuan Wang, Y ukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, and Hua Wu. 2019. Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223.使用 Whole Word Masking 策略预训练模型,其中一个中文单词中的所有字符都被完全屏蔽。
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Y ang, Shijin Wang, and Guoping Hu. 2019a. Pre-training with whole word masking for chinese bert. arXiv preprint arXiv:1906.08101.开发了迄今为止最大的中文预训练语言模型——CPM
Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Y uxian Gu, Deming Y e, Y ujia Qin, Y usheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Y anan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, and Maosong Sun. 2020. Cpm: A large-scale generative chinese pre-trained language model.发布首个大规模汉语理解评估基准CLUE,促进大规模汉语预训练研究。
Liang Xu, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Y udong Li, Y echen Xu, Kai Sun, Dian Y u, Cong Y u, Yin Tian, Qianqian Dong, Weitang Liu, Bo Shi, Yiming Cui, Junyi Li, Jun Zeng, Rongzhao Wang, Weijian Xie, Y anting Li, Yina Patterson, Zuoyu Tian, Yiwen Zhang, He Zhou, Shaoweihua Liu, Zhe Zhao, Qipeng Zhao, Cong Y ue, Xinrui Zhang, Zhengliang Y ang, Kyle Richardson, and Zhenzhong Lan. 2020. CLUE: A Chinese language understanding evaluation benchmark. In Proceedings of the 28th International Conference on Computational Linguistics, pages 4762–4772, Barcelona, Spain (Online). International Committee on Computational Linguistics.
学习字形信息
使用带索引的部首嵌入来捕获字符语义,从而提高模型在各种中文 NLP 任务上的性能
另一种融入字形信息的方式是以图像的形式查看字符,通过图像建模可以自然地学习到字形信息。
不再一 一展开
model
overview
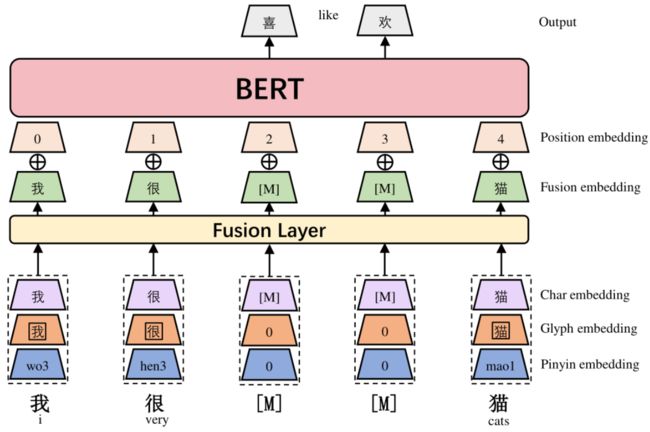
对于每个汉字,首先将其字符嵌入char embedding、字形嵌入glyph embedding和拼音嵌入pinyin embedding串联起来,然后通过一个全连接层映射到一个D维的embedding,形成 Fusion embedding。
然后将融合嵌入与position embedding一起添加,作为 BERT 模型的输入,由于我们不使用 NSP 预训练任务,因此我们省略了segment embedding
我们在训练前同时使用全词掩蔽(WWM)(Cui等人,2019a)和字符掩蔽(CM)
input
位置嵌入position embedding + 融合嵌入 fusion embedding
字符嵌入char embedding:类似token embedding
字形嵌入glyph embedding:将各个字体(仿宋、行楷、隶书)图片24*24通过cnn向量化
拼音嵌入pinyin embedding:我们在拼音序列上应用宽度为 2 的 CNN 模型,然后进行最大池化以得出最终的拼音嵌入。
这使得输出维度不受输入拼音序列长度的影响
输入的拼音序列长度固定为 8,当拼音序列的实际长度未达到 8 时,剩余槽位用特殊字母“-”填充。
融合嵌入fusion embedding:上面三个向量拼接成三维的
最后加上position embedding
图示见原文
output
输出是每个输入汉字对应的上下文表示,见bert模型文章
预训练设置
Data
从 CommonCrawl 收集了我们的预训练数据
经过预处理(如去除英文文本过多的数据,过滤html标注器)后,保留了约10%的高质量数据进行预训练,总共包含4B个汉字
https://commoncrawl.org/
使用 LTP toolkit (Che et al., 2010) 来识别中文单词的边界以进行全词掩蔽。(LTP提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作)
http://ltp.ai/
掩码策略
我们使用两种掩码策略——ChineseBERT 的全词掩码 (WWM) 和字符掩码 (CM)
基本输入单位都是汉字 可以缓解汉语中的词汇外问题
使用 WWM,一种屏蔽所选单词中所有字符的策略,减轻 CM 策略易于预测的缺点。
WWM 和 CM 之间的主要区别在于它们如何掩盖字符以及模型如何预测被掩盖的字符。
预训练细节
为了强制模型同时学习长期和短期依赖关系,我们建议在打包输入(0.9的概率)和单个输入(0.1的概率)之间交替进行预训练,其中打包输入是最大长度为 512 的多个句子的串联,单个输入是单句,每个单词/字符的掩蔽概率为 15%。
90% 的时间应用全字屏蔽,10% 的时间应用字符屏蔽。每个单词/字符的掩蔽概率为 15%。
参考
https://blog.csdn.net/sunshine_10/article/details/119574810
https://blog.csdn.net/GrinAndBearIt/article/details/122566577
https://github.com/ShannonAI/ChineseBert