基于深度学习的图像分割算法
文章目录
- 前言
- 一、FCN
- 二、UNet
- 三、PSPNet
- 总结
前言
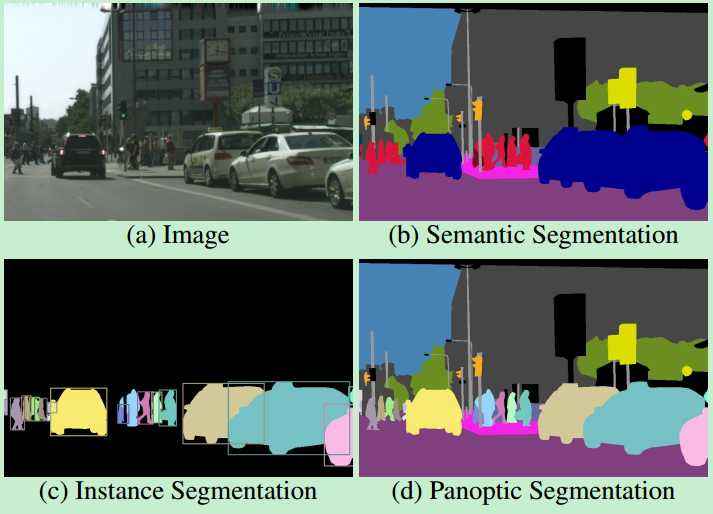
图像分割是计算机视觉的一个重要分支,本质上是对图像中每一个像素点的分类任务。随着深度学习的发展及引入,计算机视觉领域取得突破性进展,卷积神经网络成为图像处理的重要手段,因其可以充分利用图像的深层特征信息,完成图像的语义分割任务。一系列基于深度学习的图像分割方法被提出来,本文重点介绍经典的三种分割算法,FCN、UNet和PSPNet,以及使用飞桨复现的模型代码。
参考文献
① Fully Convolutional Networks for Semantic Segmentation
② U-Net: Convolutional Networks for Biomedical Image Segmentation
③ Pyramid Scene Parsing Network
一、FCN
FCN是Fully Convolutional Network的首字母缩写,顾名思义就是全卷积层,去全连接层,是一种对图像进行像素级别的分类模型,可以接受任意尺寸的图像输入。
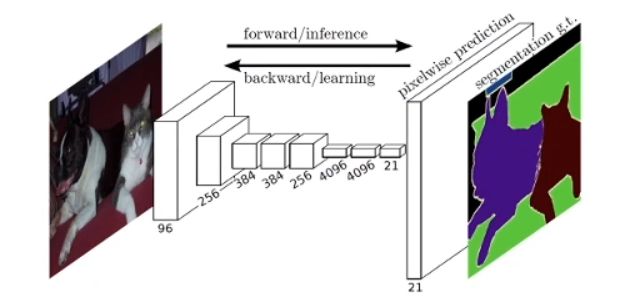
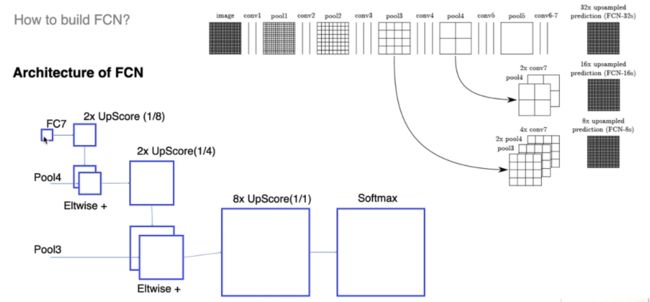
- 知识点1:1X1卷积,改变通道数,将feature map拉伸或压缩。
- 知识点2:反卷积(Conv2DTranspose)和上采样(Upsample)放大图像尺寸。
- 知识点3:卷积运算图像尺寸缩放,如下表所示。
| kernel | stride | padding | size |
|---|---|---|---|
| 1X1 | 1 | 0 | 1:1 |
| 2X2 | 1 | same | 1:1 |
| 2X2 | 2 | 0 | 2:1 |
| 3X3 | 1 | 1 | 1:1 |
| 7X7 | 2 | 3 | 2:1 |
"""
paddlepaddle-gpu==2.2.1
author:CP
backbone:FCN
"""
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.vision.models import vgg16
class VGG16(nn.Layer):
def __init__(self):
super(VGG16, self).__init__()
net = vgg16()#提取vgg16中所有的卷积层
self.stage1 = nn.Sequential(*[net.features[layer] for layer in range(0, 5)]) #两个卷积两个激活一个池化
self.stage2 = nn.Sequential(*[net.features[layer] for layer in range(5, 10)]) #两个卷积两个激活一个池化
self.stage3 = nn.Sequential(*[net.features[layer] for layer in range(10, 17)])#三个卷积三个激活一个池化
self.stage4 = nn.Sequential(*[net.features[layer] for layer in range(17, 24)])#三个卷积三个激活一个池化
self.stage5 = nn.Sequential(*[net.features[layer] for layer in range(24, 31)])#三个卷积三个激活一个池化
def forward(self, x):
C1 = self.stage1(x) #[1, 3, 600, 600]--->[1, 3, 300, 300]
C2 = self.stage2(C1) #[1, 64, 300, 300]--->[1,128, 150, 150]
C3 = self.stage3(C2) #[1,128, 150, 150]--->[1,256, 75, 75]
C4 = self.stage4(C3) #[1,256, 75, 75]--->[1,512, 37, 37]
C5 = self.stage5(C4) #[1,512, 37, 37]--->[1,512, 18, 18]
return C1, C2, C3, C4, C5
class FCN8s(nn.Layer):
def __init__(self, pretrained_net, n_class):
super(FCN8s, self).__init__()
self.n_class = n_class #类别
self.pretrained_net = pretrained_net #VGG16()
self.deconv1 = nn.Conv2DTranspose(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.relu1 = nn.ReLU()
self.bn1 = nn.BatchNorm(512)
self.deconv2 = nn.Conv2DTranspose(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.relu2 = nn.ReLU()
self.bn2 = nn.BatchNorm(256)
self.deconv3 = nn.Conv2DTranspose(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.relu3 = nn.ReLU()
self.bn3 = nn.BatchNorm(128)
self.deconv4 = nn.Conv2DTranspose(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.relu4 = nn.ReLU()
self.bn4 = nn.BatchNorm(64)
self.deconv5 = nn.Conv2DTranspose( 64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.relu5 = nn.ReLU()
self.bn5 = nn.BatchNorm(32)
self.classifier = nn.Conv2D(32, n_class, kernel_size=1)
def forward(self, x):
x1, x2, x3, x4, x5 = self.pretrained_net.forward(x)
#x1[1/2] x2[1/4] x3[1/8] x4[1/16] x5[1/32]
score = self.relu1(self.deconv1(x5)) # size=[n, 512, x.h/16, x.w/16]
score = self.bn1(score + x4) # element-wise add, size=[n, 512, x.h/16, x.w/16]
#图像要修剪成固定尺寸,Conv2D和Conv2DTranspose处理的HW不一定相等
score = self.relu2(self.deconv2(score)) # size=[n, 256, x.h/8, x.w/8]
score = self.bn2(score + x3)
score = self.bn3(self.relu3(self.deconv3(score))) # size=[n, 128, x.h/4, x.w/4]
score = self.bn4(self.relu4(self.deconv4(score))) # size=[n, 64, x.h/2, x.w/2]
score = self.bn5(self.relu5(self.deconv5(score))) # size=[n, 32, x.h, x.w]
score = self.classifier(score) # size=[n, n_class, x.h, x.w]
return score
fcn8s = FCN8s(pretrained_net = VGG16(), n_class = 2)
paddle.summary(fcn8s, (1, 3, 224, 224))
二、UNet
U-Net网络结构因为形似字母“U”而得名,最早是在医学影像的细胞分割任务中提出,结构简单适合处理小数量级的数据集。比较于FCN网络的像素相加,U-Net是对通道进行concat操作,保留上下文信息的同时,加强了它们之间的语义联系。整体是一个Encode-Decode的结构,如下图所示。
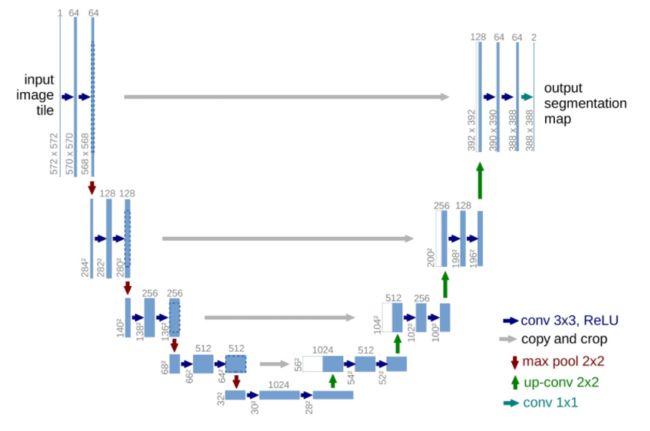
- 知识点1:下采样Encode包括conv和max pool,上采样Decode包括up-conv和conv。
- 知识点2:U-Net特点在于灰色箭头,利用通道融合使上下文信息紧密联系起来。
"""
paddlepaddle-gpu==2.2.1
author:CP
backbone:U-net
"""
import paddle
from paddle import nn
class Encoder(nn.Layer):#下采样:两层卷积,两层归一化,最后池化。
def __init__(self, num_channels, num_filters):
super(Encoder,self).__init__()#继承父类的初始化
self.conv1 = nn.Conv2D(in_channels=num_channels,
out_channels=num_filters,
kernel_size=3,#3x3卷积核,步长为1,填充为1,不改变图片尺寸[H W]
stride=1,
padding=1)
self.bn1 = nn.BatchNorm(num_filters,act="relu")#归一化,并使用了激活函数
self.conv2 = nn.Conv2D(in_channels=num_filters,
out_channels=num_filters,
kernel_size=3,
stride=1,
padding=1)
self.bn2 = nn.BatchNorm(num_filters,act="relu")
self.pool = nn.MaxPool2D(kernel_size=2,stride=2,padding="SAME")#池化层,图片尺寸减半[H/2 W/2]
def forward(self,inputs):
x = self.conv1(inputs)
x = self.bn1(x)
x = self.conv2(x)
x = self.bn2(x)
x_conv = x #两个输出,灰色 ->
x_pool = self.pool(x)#两个输出,红色 |
return x_conv, x_pool
class Decoder(nn.Layer):#上采样:一层反卷积,两层卷积层,两层归一化
def __init__(self, num_channels, num_filters):
super(Decoder,self).__init__()
self.up = nn.Conv2DTranspose(in_channels=num_channels,
out_channels=num_filters,
kernel_size=2,
stride=2,
padding=0)#图片尺寸变大一倍[2*H 2*W]
self.conv1 = nn.Conv2D(in_channels=num_filters*2,
out_channels=num_filters,
kernel_size=3,
stride=1,
padding=1)
self.bn1 = nn.BatchNorm(num_filters,act="relu")
self.conv2 = nn.Conv2D(in_channels=num_filters,
out_channels=num_filters,
kernel_size=3,
stride=1,
padding=1)
self.bn2 = nn.BatchNorm(num_filters,act="relu")
def forward(self,input_conv,input_pool):
x = self.up(input_pool)
h_diff = (input_conv.shape[2]-x.shape[2])
w_diff = (input_conv.shape[3]-x.shape[3])
pad = nn.Pad2D(padding=[h_diff//2, h_diff-h_diff//2, w_diff//2, w_diff-w_diff//2])
x = pad(x) #以下采样保存的feature map为基准,填充上采样的feature map尺寸
x = paddle.concat(x=[input_conv,x],axis=1)#考虑上下文信息,in_channels扩大两倍
x = self.conv1(x)
x = self.bn1(x)
x = self.conv2(x)
x = self.bn2(x)
return x
class UNet(nn.Layer):
def __init__(self,num_classes=59):
super(UNet,self).__init__()
self.down1 = Encoder(num_channels= 3, num_filters=64) #下采样
self.down2 = Encoder(num_channels= 64, num_filters=128)
self.down3 = Encoder(num_channels=128, num_filters=256)
self.down4 = Encoder(num_channels=256, num_filters=512)
self.mid_conv1 = nn.Conv2D(512,1024,1) #中间层
self.mid_bn1 = nn.BatchNorm(1024,act="relu")
self.mid_conv2 = nn.Conv2D(1024,1024,1)
self.mid_bn2 = nn.BatchNorm(1024,act="relu")
self.up4 = Decoder(1024,512) #上采样
self.up3 = Decoder(512,256)
self.up2 = Decoder(256,128)
self.up1 = Decoder(128,64)
self.last_conv = nn.Conv2D(64,num_classes,1) #1x1卷积,softmax做分类
def forward(self,inputs):
x1, x = self.down1(inputs)
x2, x = self.down2(x)
x3, x = self.down3(x)
x4, x = self.down4(x)
x = self.mid_conv1(x)
x = self.mid_bn1(x)
x = self.mid_conv2(x)
x = self.mid_bn2(x)
x = self.up4(x4, x)
x = self.up3(x3, x)
x = self.up2(x2, x)
x = self.up1(x1, x)
x = self.last_conv(x)
return x
model = UNet(num_classes=59)
paddle.summary(model,(1,3,250,250))
三、PSPNet
Pyramid Scene Parsing Network(PSPNet)网络结构形似金字塔而被命名,能够聚合不同尺度下的上下文信息,在场景解析上有很好的效果。PSPNet的精髓在于pyramid parsing module的构建,能够增大深层区域的感受野。
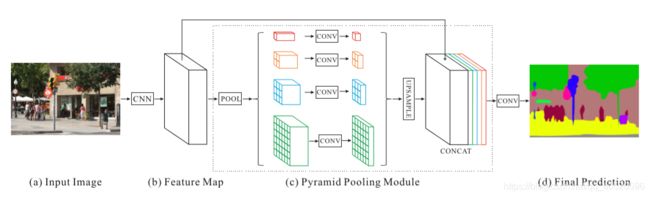
- 知识点1:多尺度特征融合可以提高模型性能,深层网络中包含更多的语义信息和较小的位置信息。
- 知识点2:input image需要通过CNN网路提取特征,这里使用的是飞桨预训练的resnet50网络。
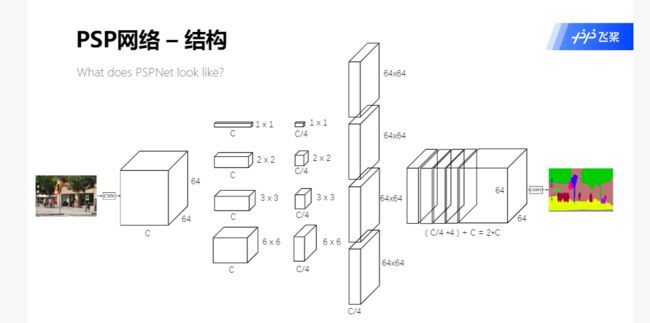
- 知识点3:PSPmodule将CNN的输出划成四个通道,然后进行上采样,全局特征和局部特征进行融合得到2C通道。
"""
paddlepaddle-gpu==2.2.1
author:CP
backbone:PSPnet
"""
import paddle
import paddle.nn as nn
class PSPModule(nn.Layer):
"""
num_channels:输入通道数为C
num_filters :输出通道数为C/4
bin_size_list=[1,2,3,6]
get1:
nn.LayerList创建一个空列表的层
.append拼接“层”的列表
get2:
paddle.nn.AdaptiveMaxPool2D输出固定尺寸的image_size[H,W]
paddle.nn.functional.interpolate卷积操作后,还原图片尺寸大小
paddle.concat [H,W]同尺寸的图片,合并通道[C]
"""
def __init__(self, num_channels, bin_size_list):
super(PSPModule,self).__init__()
num_filters = num_channels // len(bin_size_list) #C/4
self.features = nn.LayerList() #一个层的空列表
for i in range(len(bin_size_list)):
self.features.append(
paddle.nn.Sequential(
paddle.nn.AdaptiveMaxPool2D(output_size=bin_size_list[i]),
paddle.nn.Conv2D(in_channels=num_channels, out_channels=num_filters, kernel_size=1),
paddle.nn.BatchNorm2D(num_features=num_filters)
)
)
def forward(self, inputs):
out = [inputs] #list
for idx, layerlist in enumerate(self.features):
x = layerlist(inputs)
x = paddle.nn.functional.interpolate(x=x, size=inputs.shape[2::], mode='bilinear', align_corners=True)
out.append(x)
out = paddle.concat(x=out, axis=1) #NCHW
return out
from paddle.vision.models import resnet50
class PSPnet(nn.Layer):
def __init__(self, num_classes=59, backbone='resnet50'):
super(PSPnet, self).__init__()
"""
https://github.com/PaddlePaddle/Paddle/blob/release/2.1/python/paddle/vision/models/resnet.py
重复利用resnet50网络模型:
1.初始化函数关键词——backbone
2.神经网络模型实例化
3.源代码查找层的变量名
"""
# resnet50 3->2048
res = resnet50()
self.layer0 = nn.Sequential(res.conv1, res.bn1, res.relu, res.maxpool)
self.layer1 = res.layer1
self.layer2 = res.layer2
self.layer3 = res.layer3
self.layer4 = res.layer4#输出通道为2048
#pspmodule 2048->4096
num_channels = 2048
self.pspmodule = PSPModule(num_channels, [1,2,3,6])
num_channels *= 2
#cls 4096->num_classes
self.classifier = nn.Sequential(
nn.Conv2D(num_channels,512,3,1,1),
nn.BatchNorm(512,act='relu'),
nn.Dropout(),
nn.Conv2D(512,num_classes,1))
#aux:1024->256->num_classes
#单独分离出一层来计算函数损失
def forward(self,inputs):
x = self.layer0(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.pspmodule(x)
x = self.classifier(x)
x = paddle.nn.functional.interpolate(x=x, size=inputs.shape[2::], mode='bilinear', align_corners=True)
return x
paddle.summary(PSPnet(), (1, 3, 600, 600))
总结
网络结构的搭建直接决定模型训练精度的上限,本文介绍的三种网络模型各有特色,FCN可以算是全卷积神经网络解决图像分割任务的开山之作,受其启发的U-Net将下采样和上采样环节的feature map相加,使得上下文信息联系起来。如果说UNet是横向的concat,PSPNet就是纵向的concat,以此增加深层的感受野,使得其包含更多的语义信息。当然,图像分割算法发展至今,精度最高的应该属于DeepLab,由于模型过于复杂,下一篇博客单独介绍。欢迎关注一波~