Coursera吴恩达机器学习ML-week4-ex3多分类及神经网络-python实现
很多函数或者内部的一些计算其实没用,但是因为是对应matlab上的作业,所以有的部分会显得多余
不过对于图像的呈现就略过了,个人认为还是先熟悉算法为主,这样进度也快点
task1多分类
import numpy as np
import pandas as pd
#import matplotlib.pyplot as plt 不画图也就用不到了
#import matplotlib
from scipy.io import loadmat
from sklearn.metrics import classification_report
data = loadmat('ex3data1.mat')
#data['X'].shape=(5000, 400), data['y'].shape=(5000, 1)
#共5000张20*20的数字图片,y是对应的tag
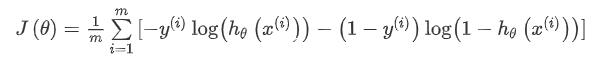
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def cost(theta, X, y, lr):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X * theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
return np.sum(first - second) / len(X)

def gradient(theta, X, y, lr):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
parameters = int(theta.ravel().shape[1])#theta总个数
error = sigmoid(X * theta.T) - y
grad = theta-((X.T * error) / len(X)).T + ((lr / len(X)) * theta)
grad[0,0] = theta[0,0]-np.sum(np.multiply(error, X[:,0])) / len(X)
return np.array(grad).ravel()
#from scipy.optimize import minimize
def one_vs_all(X, y, num_labels, lr):
rows = X.shape[0]
params = X.shape[1]
#还是添加偏置bias
all_theta = np.zeros((num_labels, params + 1))# shape = (10,401)
X = np.insert(X, 0, values=np.ones(rows), axis=1) #shape = (5000,401)
for i in range(1, num_labels + 1):
theta = np.zeros(params + 1)
y_i = np.array([1 if label == i else 0 for label in y])
y_i = np.reshape(y_i, (rows, 1))
#网上有种方法
#from scipy.optimize import minimize
#fmin = minimize(fun=cost, x0=theta, args=(X, y_i, learning_rate), method='TNC', jac=gradient)
#all_theta[i-1,:] = fmin.x
#这样预测得更好,但是不容易理解,下面5行容易理解
for j in range(1000):
a = gradient(all_theta[i-1,:], X, y_i, lr)
if(a==all_theta[i-1,:]).all():
break
all_theta[i-1,:]=a
return all_theta
rows = data['X'].shape[0]
params = data['X'].shape[1]
all_theta = np.zeros((10, params + 1))# shape = (10*401)每行对应一种数字的401个weight
#分别在x和theta添加bias
X = np.insert(data['X'], 0, values=np.ones(rows), axis=1)
theta = np.zeros(params + 1)
#y_0 = np.array([1 if label == 0 else 0 for label in data['y']])
#y_0 = np.reshape(y_0, (rows, 1)) 这两行没什么用,懂这样做的意义是实现对 数a与非数a的划分 就行
all_theta = one_vs_all(data['X'], data['y'], 10, 1)
#X.shape=(5000, 401), y_0.shape=(5000, 1), theta.shape=(401,)
def predict_all(X, all_theta):
rows = X.shape[0]
params = X.shape[1]
num_labels = all_theta.shape[0]# num_labels=10
#bias
X = np.insert(X, 0, values=np.ones(rows), axis=1)
X = np.matrix(X)
all_theta = np.matrix(all_theta)# shape = (10,401)
h = sigmoid(X * all_theta.T)#计算5000个样本中,每1个样本对应的10种数字的预测概率
#h_argmax返回最大值的索引
h_argmax = np.argmax(h, axis=1)#找出每行概率最大值对应的索引
h_argmax = h_argmax + 1#np的广播机制,每个索引加1,1对应的索引为1,0对应的索引为10
return h_argmax
#对比结果
y_pred = predict_all(data['X'], all_theta)
print(classification_report(data['y'], y_pred))
task2 神经网络
实现一个可以识别手写数字的神经网络。神经网络可以表示一些非线性复杂的模型。在已经预先训练好基础上,实现前馈神经网络。
输入是图片的像素值,20*20像素的图片有400个输入层单元,不包括需要额外添加的加上常数项。
θ1和θ2已提供,,有25个隐层单元和10个输出单元(10个输出)
weight = loadmat("ex3weights.mat")
theta1, theta2 = weight['Theta1'], weight['Theta2']
theta1.shape, theta2.shape
X2 = np.matrix(np.insert(data['X'], 0, values=np.ones(X.shape[0]), axis=1))
y2 = np.matrix(data['y'])
#X2.shape=(5000, 401), y2.shape=(5000, 1)
a1 = X2
z2 = a1 * theta1.T
#z2.shape=(5000, 25)
a2 = sigmoid(z2)
#a2.shape=(5000, 25)
a2 = np.insert(a2, 0, values=np.ones(a2.shape[0]), axis=1)
z3 = a2 * theta2.T
#z3.shape=(5000, 10)
a3 = sigmoid(z3)
y_pred2 = np.argmax(a3, axis=1) + 1
#y_pred2.shape=(5000, 1)
print(classification_report(y2, y_pred))
如果有疑问,可以加群讨论:484266833