CRAFTS:端对端的场景文本检测器
CRAFTS
场景文本检测器由文本检测和识别模块组成。许多研究已经将这些模块统一为一个端到端可训练的模型,以获得更好的性能。一个典型的体系结构将检测和识别模块放置到单独的分支中,通常使用RoI pooling来让这些分支共享一个视觉特征。然而,当采用使用基于注意力的解码器和表示字符区域空间信息的检测器时,仍然有机会在模块之间建立更互补的连接。这是可能的,因为这两个模块共享一个共同的子任务,即查找字符区域的位置。
在此基础上,构建了一个紧密耦合的单管道模型。该体系结构是通过利用识别器中的检测输出并通过检测阶段传播识别损失而形成的。字符得分图的使用有助于识别器更好地关注字符中心点,并且将识别损失传播到检测器模块,增强了字符区域的定位。此外,一个加强的共享阶段允许对任意形状的文本区域进行特征校正和边界定位。大量的实验证明了在公开可用的水平基准集和弯曲基准数据集的最先进的性能。
CRAFTS算法原理:
CRAFTS可以分成3个阶段:检测阶段、共享阶段和识别阶段,详细的网络结构如图所示。
检测阶段
获取一个输入图像,并定位面向方向的文本框。共享阶段,然后汇集backbone的高级特性和检测器输出。然后使用校正模块对合并后的特征进行校正,并连接在一起形成一个角色参与特征。在识别阶段,基于注意力的解码器使用字符参与的特征来预测文本标签。最后,一种简单的后处理技术可选地用于更好的可视化。
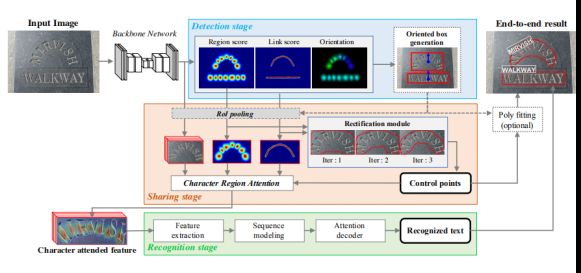
检测阶段
CRAFT检测器作为基础网络,因为它能够表示特征区域的语义信息。工艺网络的输出代表了特征区域的中心概率和它们之间的联系。CRAFTS认为这个以字符为中心的信息可以用来支持识别器中的注意模块,因为这两个模块都旨在定位字符的中心位置。在这项工作中,对原始工艺模型进行了三个修改;backbone替换、链路表示和方向估计。
共享阶段
该阶段主要包含二大模块,文本纠正模块和字符区域注意力(text region attention, CRA)模块,使用 薄板样条(TPS)变换去纠正任意形状的文本区域,文本纠正模块使用 迭代-TPS,以获得更好的文本区域表示。
典型的TPS模块输入一张单词图片,但在这里提供字符区域映射和链接映射,因为它们包含了文本区域的几何信息,使用二十个控制点来紧紧覆盖弯曲的文本区域,将这些控制点作为检测结果,转换为原始输入图像坐标。可以选择执行二维多项式拟合来平滑边界多边形,迭代-TPS和最终平滑多边形输出的例子如图4所示。

CRA模块是紧密耦合检测和识别模块的关键部件,过简单地将修正后的字符得分映射与特征表示连接起来,该模型建立了以下优势。在检测器和识别器之间创建一个链接,允许识别损失在检测阶段传播,这提高了字符得分地图的质量。此外,将字符区域映射附加到特征上,有助于识别器更好地关注字符区域。
识别阶段
识别阶段有三个组成部分:特征提取、序列建模和预测。特征提取模块比单独的识别器更轻,因为它以高层语义特征作为输入。 该模块的详细体系结构如表1所示。提取特征后,采用双向LSTM进行序列建模,并对基于注意的解码器进行最终的文本预测。

在每个时间步骤中,基于注意力的识别器通过屏蔽注意力输出到特征来解码文本信息。虽然注意模块在大多数情况下都能很好地工作,但当注意点不对齐或消失时,它无法预测字符。图5展示了使用CRA模块的效果,合适的注意点能够稳健的进行文本预测。

实验结果:
实验采用如下几种数据集作为实验数据集:
英语数据集IC13数据集由高分辨率图像组成,229个用于训练和233个用于测试。矩形框用于注释单词级文本实例。
IC15由1000张训练图像和500张测试图像组成。四边形框用于注释单词级文本实例。
Total-Text拥有1255张培训图片和300张测试图片。与IC13和IC15数据集不同,它包含曲线文本实例,并使用多边形点进行注释。
多语言数据集IC19数据集包含10000个训练和10000个测试图像。该数据集包含7种不同语言的文本,并使用四边形点进行注释。
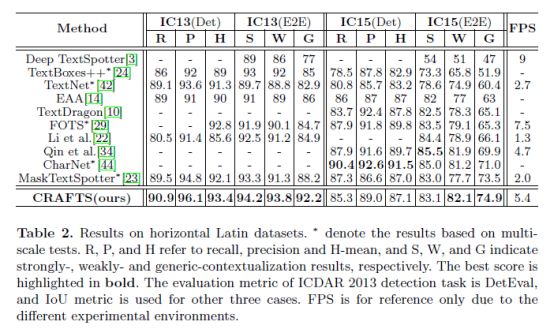
在水平数据集(IC13, IC15)上取得的实验结果如下表:
水平数据集(IC13、IC15)为了针对IC13基准,采用在SynthText数据集上训练的模型,并对IC13和IC19数据集进行微调。在推断过程中,我们将输入的长边调整为1280。结果表明,与之前最先进的作品相比,其性能没有显著提高。
然后,在IC13数据集上训练的模型在IC15数据集上进行微调。在评估过程中,模型的输入大小设置为2560x1440。请注意,在没有通用词汇集的情况下执行通用评估。表2列出了IC13和IC15数据集的定量结果。
CRAFTS的方法在一般任务和弱上下文化端到端任务中都优于以前的方法,并在其他任务中显示出类似的结果。通用性能是有意义的,因为在实际场景中没有提供词汇集。请注意,CRAFTS在IC15数据集上的检测分数略低,在强语境化结果中也观察到低性能。检测性能相对较低的主要原因是粒度差异,稍后将进一步讨论。
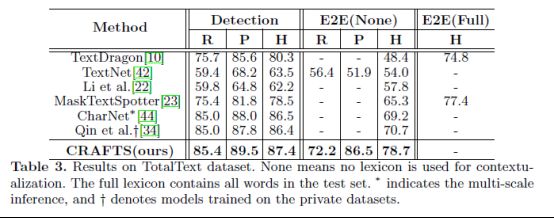
在曲边数据集(TotalText)上取得的实验结果如下表:
曲线数据集(TotalText)从IC13数据集上训练的模型,实验进一步在TotalText数据集上训练模型。在推断过程中,CRAFTS将输入的长边调整为1920,整流模块的控制点用于检测器评估。定性结果如图7所示。字符区域图和链接图用热图表示,加权像素角度值在HSV颜色空间中可视化。如图所示,该网络成功地定位了多边形区域,并识别了曲线文本区域中的字符。左上角的两幅图显示了完全旋转和高度弯曲文本实例的成功识别。
TotalText数据集的定量结果如表3所示。DetEval评估探测器的性能,修改的IC15评估方案测量端到端性能。CRAFTS的方法大大优于以前报道的方法。

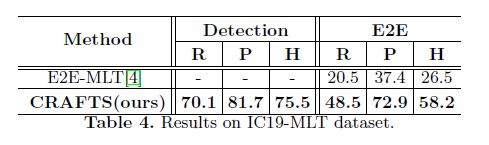
在多语言数据集数据集(IC19)上取得的实验结果如下表
多语言数据集(IC19)使用IC19-MLT数据集对多种语言进行评估。识别器预测层的输出通道扩展到4267,以处理阿拉伯语、拉丁语、中文、日语、韩语、孟加拉国语和印地语中的字符。但是,数据集中出现的字符并不是均匀分布的。在训练集中的4267个字符中,1017个字符在数据集中出现一次,这使得模型很难做出准确的标签预测。为了解决类别不平衡问题,CRAFTS首先在检测阶段冻结权重,并使用其他公开的多语言数据集(SynthMLT、ArT、LSVT、ReCTS和RCTW)在识别器中预训练权重。然后,CRAFTS让损失流经整个网络,并使用IC19数据集对模型进行调整。由于没有论文报告性能,结果与E2E-MLT进行比较。IC19数据集中的样本如图8所示。

结论:
CRAFTS中提出了一个端到端可训练的单pipeline模型,它紧密地耦合了检测和识别模块,共享阶段的字符区域注意充分利用字符区域映射,帮助识别器纠正和更好地关注文本区域。同时,设计了识别损耗通过检测阶段传播,提高了检测器的字符定位能力。此外,在共享阶段的纠正模块使弯曲文本的精细定位,并避免了手工设计后处理的需要。 实验结果验证了CRAFTS在各种数据集上的最新性能。
参考文献:
Liu C Y, Chen X X, Luo C J, Jin L W, Xue Y and Liu Y L. 2021. Deep learning methods for scene text detection and recognition. Journal of Image and Graphics,26(06):1330-1367(刘崇宇,陈晓雪,罗灿杰,金连文,薛洋,刘禹良. 2021. 自然场景文本检测与识别的深度学习方法. 中国图象图形学报,26(06):1330-1367)[DOI:10. 11834 / jig. 210044]
Liu X B, Liang D, Yan S, Chen D G, Qiao Y and Yan J J. 2018c.
FOTS: fast oriented text spotting with a unified network //Proceedings of 2018 IEEE/ CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE: 5676-5685 [DOI: 10. 1109 / CVPR. 2018. 00595]
Liu Y L, Chen H, Shen C H, He T, Jin L W and Wang L W. 2020. ABCNet: real-time scene text spotting with adaptive bezier-curve network / / Proceedings of 2020 IEEE/ CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE: 9809-9818 [DOI: 10. 1109 / CVPR42600. 2020. 00983]
Baek Y, Shin S, Baek J, Park S, Lee J, Nam D and Lee H. 2020. Character region attention for text spotting / / Proceeding of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 504-521 [DOI: 10. 1007 / 978-3-030-58526-6_30]