Python深度学习实例--电影评论分类(二分类问题)
Python深度学习实例--电影评论分类(二分类问题)
- 1. Keras
-
- 1.1Keras简介
- 1.2Keras、TensorFlow、Theano 和 CNT
- 1.3Keras开发的工作流程
- 1.4安装Keras
- 2. IMDB数据集
- 3. 数据准备
- 4.构建网络
- 5.进行训练和测试
-
- 5.1 留出验证集
- 5.2 训练模型
- 5.3 绘制验证损失和训练损失
- 6.小结
1. Keras
1.1Keras简介
Keras 是一个 Python 深度学习框架,可以方便地定义和训练几乎所有类型的深度学习模型。
Keras 具有以下重要特性:
1.相同的代码可以在 CPU 或 GPU 上无缝切换运行。
2.具有用户友好的 API,便于快速开发深度学习模型的原型。
3.内置支持卷积网络(用于计算机视觉)、循环网络(用于序列处理)以及二者的任意组合。
4.支持任意网络架构:多输入或多输出模型、层共享、模型共享等。
1.2Keras、TensorFlow、Theano 和 CNT
Keras 是一个模型级(model-level)的库,为开发深度学习模型提供了高层次的构建模块。它不处理张量操作、求微分等低层次的运算。相反,它依赖于一个专门的、高度优化的张量库来完成这些运算,这个张量库就是 Keras 的后端引擎(backend engine)。Keras 没有选择单个张量库并将 Keras 实现与这个库绑定,而是以模块化的方式处理这个问题。因此,几个不同的后端引擎都可以无缝嵌入到 Keras 中。目前,Keras 有三个后端实现:TensorFlow 后端、Theano 后端和微软认知工具包(CNTK,Microsoft cognitive toolkit)后端。未来 Keras 可能会扩展到支持更多的深度学习引擎。
1.3Keras开发的工作流程
1.定义训练的数据
2.定义网络并向其中添加层
3.配置学习过程
4.调用model.fit进行训练
1.4安装Keras
安装Keras前需要下载Anaconda等软件,这里就不在赘述,有时间我会出一篇博客来详细说明Keras的安装步骤。
2. IMDB数据集
对于深度学习最重要的就是数据集了,一个数据集的好坏在很大程度上影响着你所要解决问题的难度。听过这样一句话,在解决深度学习这方面问题的时候,百分之八十的时间会花在准备数据上,而剩下的百分之二十就是在抱怨为什么收集的数据这样烂。
这个例子使用的是IMDB数据集,它包括来自互联网电影数据库(IMDB)的50000条严重两极分化的评论。数据集被分为用于训练的 25 000 条评论与用于测试的 25 000 条评论,训练集和测试集都包含 50% 的正面评论和 50% 的负面评论。IMDB 数据集内置于 Keras 库。它已经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
# 加载IMDB数据集
# train_data:训练数据
# train_labels:训练数据的标签
# test_data:测试数据
# test_labels:测试数据的标签。
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
num_words是函数imdb.load_data的一个参数,参数 num_words=10000 的意思是仅保留训练数据中前10000 个最常出现的单词。低频单词将被舍弃。这样得到的向量数据不会太大,便于处理。
我们来看一下数据以及标签的样子:
train_data[0]
输出:
[1,
14,
22,
16,
43,
530,
973,
1622,
1385,
65,
458,...
这是25000影评的第一条影评,其中每一个数字代表一个单词。
train_labels[0]
输出:
1
train_labels 和 test_labels 都是 0 和 1 组成的列表,其中 0代表负面(negative),1 代表正面(positive)。可以看出第一条影评是正面的。
train_data.shape
输出:
(25000,)
训练数据是一维张量,长度为25000,说明训练数据由25000条影评组成。
train_labels
train_labels.shape
输出:
array([1, 0, 0, ..., 0, 1, 0], dtype=int64)
(25000,)
训练数据的标签是一维张量,长度为25000,1代表正面,0代表负面。
3. 数据准备
- 对数据集进行 one-hot 编码,将其转换为 0 和 1 组成的向量。举个例子,序列 [3, 5] 将会被转换为 10 000 维向量,只有索引为 3 和 5 的元素是 1,其余元素都是 0。
# 将整数序列编码为二进制矩阵
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension)) # **构造二进制零矩阵大小为25000*10000**
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
# training_data
x_train = vectorize_sequences(train_data)
# 测试test_data
x_test = vectorize_sequences(test_data)
对于enumerate函数可能有的读者不了解,这里有对该函数的解释(点击超链接)
2. 对标签进行向量化
# 由于标签取值本来就是0或1,故只需要将其变成浮点数即可。
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
astype:可以用于把数据转换成其他类型的数据
我们来看一下处理后数据的样子:
x_train
x_train[0]
x_train.shape
结果:
array([[0., 1., 1., ..., 0., 0., 0.],
[0., 1., 1., ..., 0., 0., 0.],
[0., 1., 1., ..., 0., 0., 0.],
...,
[0., 1., 1., ..., 0., 0., 0.],
[0., 1., 1., ..., 0., 0., 0.],
[0., 1., 1., ..., 0., 0., 0.]])
array([0., 1., 1., ..., 0., 0., 0.])
(25000, 10000)
从结果可以看出,训练数据和测试数据已经被向量化。
4.构建网络
输入数据是向量矩阵,而标签1 或 0。有一类网络在这种问题上表现很好,就是带有 relu 激活的全连接层(Dense)的简单堆叠。对于这种 Dense 层的堆叠,你需要确定以下两个关键架构:
(1)网络有多少层
(2)每层有多少个隐藏单元,即为神经元的个数
隐藏单元越多(即更高维的表示空间),网络越能够学到更加复杂的表示,但网络的计算代价也变得更大,而且可能会导致学到不好的模式(过拟合)。因此我们需要选取合适的网络结构,这里我们选取下列网络结构:
(1)两个中间层,每层都有 16 个隐藏单元
(2)第三层输出一个标量,预测当前评论的情感
# 模型定义
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
中间层使用 relu 作为激活函数,最后一层使用 sigmoid 激活以输出一个 0~1 范围内的概率值(表示样本的目标值等于 1 的可能性,即评论为正面的可能性)。relu(rectified linear unit,整流线性单元)函数将所有负值归零,而 sigmoid 函数则将任意值“压缩”到 [0, 1] 区间内(见下图),其输出值可以看作概率值。


# 模型编译
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
上述代码将优化器、损失函数和指标作为字符串传入,这是因为 **rmsprop、binary_crossentropy 和 accuracy** 都是 Keras 内置的一部分。
5.进行训练和测试
5.1 留出验证集
由于模型不能读取与测试集有关的任何信息,但要在训练过程中检控模型在前所未见的数据上的精度,我们要将训练数据分离一部分出来作为验证集。
# 留出验证集
x_val = x_train[:10000] #前**10000**个训练数据为验证数据
partial_x_train = x_train[10000:] #后**15000**个训练数据为实际上的训练数据
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
5.2 训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
model.fit函数返回一个History的对象,即记录了loss和其他指标的数值随epoch变化的情况
model.fit(x, y, batch_size, epochs, verbose, validation_split, validation_data, validation_freq)
batch_size:每一个batch的大小(批尺寸),即训练一次网络所用的样本数
epochs:迭代次数,即全部样本数据将被“轮”多少次,轮完训练停止
verbose:0:不输出信息;1:显示进度条(一般默认为1);2:每个epoch输出一行记录;
validation_split:(0,1)的浮点数,分割数据当验证数据,其它当训练数据
validation_data:指定验证数据,该数据将覆盖validation_spilt设定的数据
validation_freq: 指定验证数据的epoch
5.3 绘制验证损失和训练损失
history_dict = history.history # 将model.fit()返回的History对象的成员history,它是一个字典定义为history_dict
history_dict.keys() # 输出该字典的key值
history_dict.get('loss') # 输出该字典'loss'的value值
结果:
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy']) # val_binary_accuracy为验证数据精确度,val_loss为验证数据损失,binary_accuracy为训练数据精确度,loss为训练数据损失。
[0.5116540193557739,
0.31131452322006226,
0.22715742886066437,
0.177445188164711,
0.14659076929092407,
0.11973749846220016,
0.10006918013095856,
0.0847877711057663,
0.06847935914993286,
0.05795466899871826,
0.046551600098609924,
0.0376567505300045,
0.03152570500969887,
0.02527175471186638,
0.01926599256694317,
0.01855255663394928,
0.010066471062600613,
0.01339575182646513,
0.008250921033322811,
0.004806698299944401]
上面输出的是20迭代过程中每一次的训练数据损失值
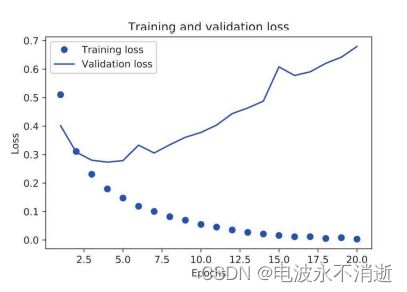
# 绘制训练损失和验证损失
import matplotlib.pyplot as plt
loss_values = history_dict['loss']
val_loss_values=history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
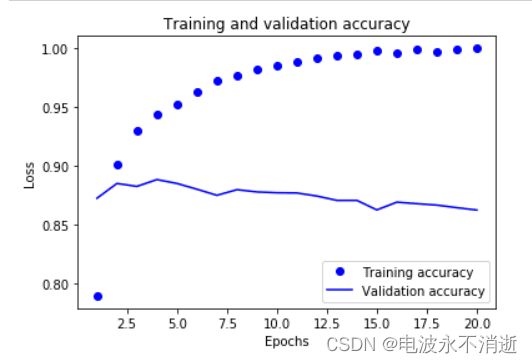
# 绘制训练精度和验证精度
plt.clf()
acc_values = history_dict['binary_accuracy']
val_acc_values = history_dict['val_binary_accuracy']
plt.plot(epochs, acc_values, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc_values, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
6.小结
(1)通常需要对原始数据进行大量预处理,以便将其转化为张亮输入到神经网络中。单词序列可以编码为二进制向量。但也有其他编码方式。
(2)带有relu激活的Dense层堆叠,可以解决很多种问题(包括情感分类)
(3)对于二分类问题(两个输出类别),网络的最后一层应该是只有一个单元并使用sigmoid激活的Dense层,网络输出应该是0~1范围内的标量,表示概率值。
(4)对于二分类问题的sigmoid标量输出,应该使用binary_crossentropy损失函数。
(5)无论需要解决的问题是什么,rmsprop优化器通常都是足够好的选择。
(6)随着神经网络在训练数据上的表现越来越好,模型最终会过拟合,并在前所未有的数据上得到越来越差的结果。一定要一直监控模型在训练数据集之外的数据上的性能。