李宏毅机器学习学习笔记:Self-attention
Self-attention
输入无论是图像、音频、单词,embedding成向量vector的形式
传统方式将这些向量组成的sequence输入一个model,得到一系列输出,每个向量对应一个输出点
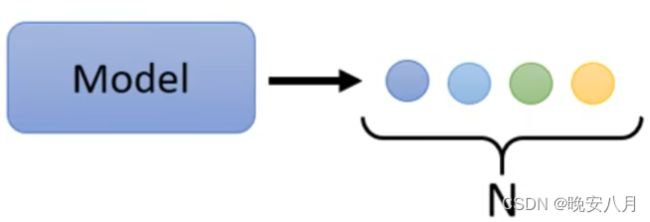
此时向量之间的关联,某个向量对另一个向量的影响并不能被体现出来,采用直接相加或cantenate的方法,体现了向量间的影响,但无法量化某个向量受不同向量影响的大小程度不同。采用Window的形式,无法决定window的大小。
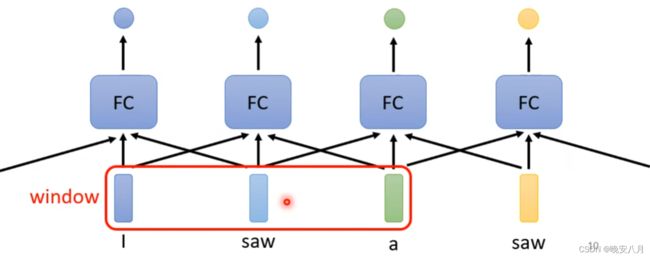
因此提出self-attention,所有向量进入一个self-attention层,这样就能体现所有向量两两之间产生的影响
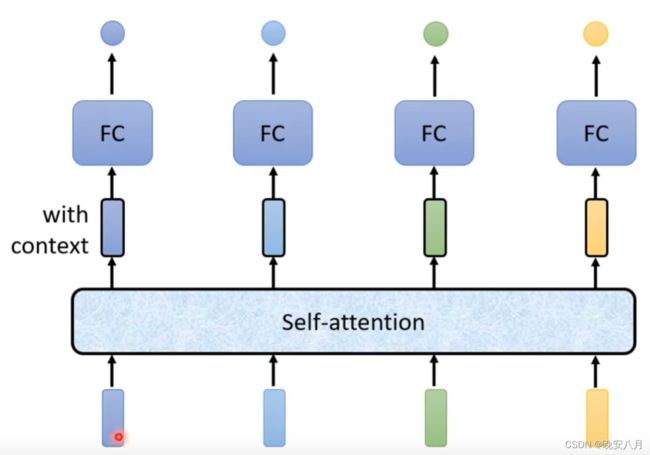
Self-attention的Q、K、V机制
Q、K、V分别指Query查询、Key键、Value值。
假设输入Sequence Input:a1、a2、a3、a4。(可能是hidden layer的output)
为了考虑a1、a2、a3、a4对a1产生的影响,进行以下步骤:
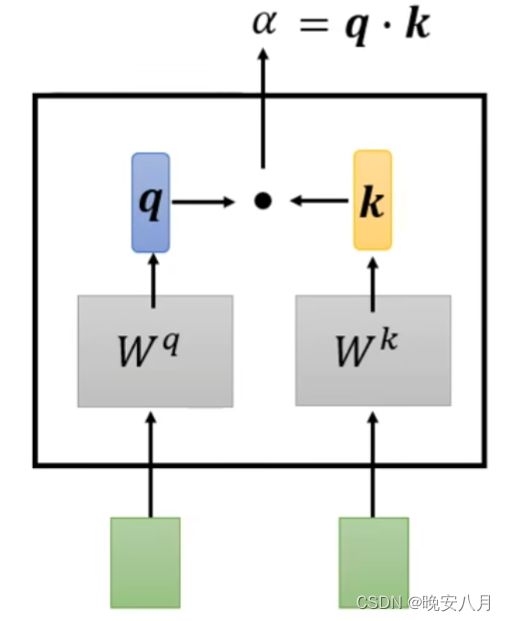
1、根据a1,找出(查询、query)Input Sequence中与a1相关的输入,即找出每一个向量与a1的关联性,记作α(1,i)。
具体实施该步骤的方法有很多,transformer中使用a1与ai,分别乘上Wq矩阵与Wk矩阵,获得q与k,二者点乘获得α(1,i)
将α(1,1)、α(1,2)、α(1,3)、α(1,4)连接成新的向量α1,相同方法获得α2、α3、α4。
通过一个softmax做normalization,获得α1'、α2'、α3'、α4',每个向量(αi')体现了其他位置输入向量与该位置输入向量(ai)的相关性
2、将a1、a2、a3、a4分别与矩阵Wv相乘,获得v1、v2、v3、v4,连接成v向量,该向量体现了每个输入向量自身的特征。
将v与α1'相乘,即将各个向量的值与它们对a1输入的相关性相乘,即考虑了各输入的值对a1的影响,相加后获得b1
b1即为a1的输出向量。

Self-attention的向量化实现
1、输入矩阵I(a1,a2,a3,a4),分别乘Wq、Wk、Wv得到Q(q1,q2,q3,q4),K(k1,k2,k3,k4),V(v1,v2,v3,v4)

2、Q和K进行inner product,得到α的矩阵A(attention的分数) ,通过normalization获得A'。

3、A'乘矩阵V得到输出矩阵O(b1,b2,b3,b4)
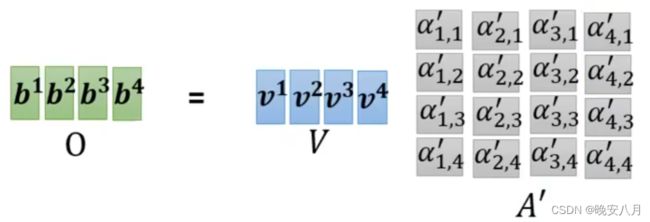
4、总结
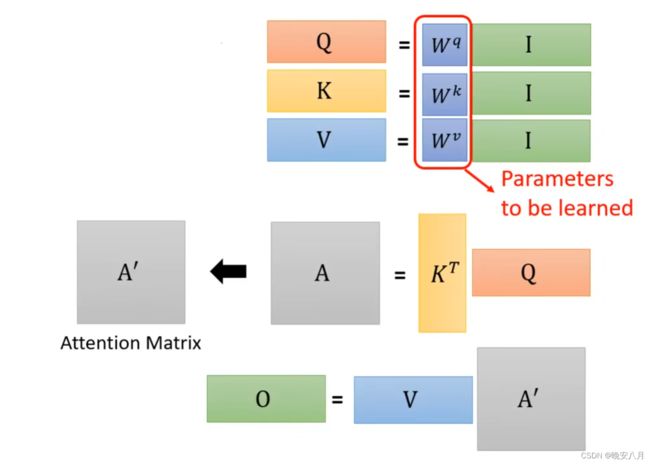
整个过程中需要训练学习的未知参数只有Wq,Wk,Wv
Multi-head Self-attention
相关性的度量由q体现,而相关性的度量方式有多种,因此需要使用Multi-head体现多种不同的相关性
假设有四个head来体现四种不同的相关性,依据以下步骤:
1、使用Wq,Wk,Wv获得Q、K、V之后,再使用Wq1、Wq2、Wq3、Wq4与Q做点积,获得Q1、Q2、Q3、Q4
同理,使用Wk1、Wk2、Wk3、Wk4与Wvv1、Wv2、Wv3、Wv4获得K1、K2、K3、K4与V1、V2、V3、V4
2、使用对应的Qi、Ki、Vi执行Self-attention(上一节步骤2、3),获得Bi即为第i个Head对应的输出。
Position Encoding
Self-attention的过程中缺少了一个重要的信息,输入向量之间的位置关系,向量在Sequence中的位置信息。
为每个位置设定一个向量,位置向量ei,将ei加在输入向量ai上。
产生ei的方法很多,目前有相应的研究Learning to Encode Position for Transformer with Continuous Dynamical Model
Self-attention的应用
语音识别:Truncated Self-attention,人为设定一个小的范围做Self-attention,不用去判断一整句的相关性,加快计算速度
图像处理:将一张图像看作一个很长的向量
Self-attention与CNN的差异与关联
CNN可以看作一种简化版的Self-attention,CNN只关注感受野receptive field内的咨询。
Self-attention可以看作复杂化的CNN,它关注整张图像内的咨询,通过计算像素之间的相关性,自动划定感受野receptive field的范围和大小。
CNN是Self-attention的特例,通过特定的参数,Self-attention可以做到CNN的感受野On the Relationship between Self-Attention and Convolutional Layers
Self-attention需要更多的data(更flexible的模型需要的data更多,小的、有限制的model更不容易overfitting)
在数据量较小时,CNN可以获得比Self-attention更好的结果。An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Self-attention与RNN的差异与关联
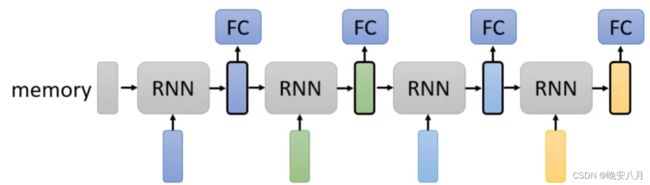
RNN只考虑左侧,当前Input向量之前的Input向量,双向的RNN可以考虑整个Sequence。Self-attention直接考虑整个Sequence。
RNN最开始的输入向量随着多层模型对最后的输入向量产生影响。Self-attention在输入时就将各个向量之间的影响通过Q和V存储。
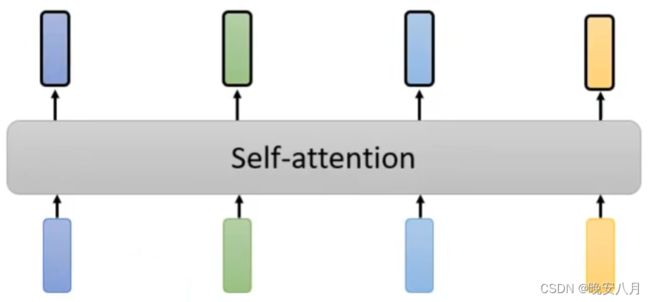
RNN无法平行化处理(nonparallel),四个输出向量同时产生,因此Self-attention运算速度更快。
Self-attention for Graph
Graph咨询已经包含了node之间的相关性信息,可以直接计算attention分数矩阵A——GNN Graph Neural Network。