SSEGCN
目录
-
SSEGCN
-
论文内容
-
1.研究背景
-
2.相关方法
-
3.研究方法
-
Input and Encoding Layer
-
Attention Layer
-
Aspect-aware Attention
-
Self-Attention
-
-
Syntax-Mask Layer
-
GCN Layer
-
Training
-
-
4.实验效果
-
Datasets
-
Implementation Details
-
Baseline Comparisons
-
Main Results
-
Ablation Study
-
Case Study
-
Visualization
-
Effect of SSEGCN Layers
-
Effect of Syntax-Mask
-
-
5.研究结论
-
-
与我研究相关
-
精读笔记
SSEGCN
方面感知注意力机制;语法掩码矩阵
(题图)
年份:2022
标题:Syntactic and Semantic Enhanced Graph Convolutional Network for Aspect-based Sentiment Analysis(基于方面的情绪分析中的语法和语义增强的图卷积网络)
摘要:基于方面的情绪分析(ABSA)旨在预测句子中特定方面的情绪极性。近年来,基于依赖树的图神经网络传递了丰富的结构信息,被证明是ABSA的实用价值。然而,如何有效地利用依赖树中的语义和语法结构信息仍然是一个具有挑战性的研究问题。在本文中,我们提出了一种新的语义增强图卷积网络(SSEGCN)模型。具体地说,我们提出了一种结合自我注意的方面感知注意机制来获得句子的注意得分矩阵,该机制不仅可以学习与方面相关的语义关联,还可以学习句子的全局语义。为了获得全面的句法结构信息,我们根据单词间不同的句法距离构造了句子的语法掩码矩阵。此外,为了结合句法结构和语义信息,我们用语法掩码矩阵来装备注意分数矩阵。最后,我们利用图卷积网络增强了ABSA的节点表示。在基准数据集上的实验结果表明,我们提出的模型优于最先进的方法。
代码:
GitHub - zhangzheng1997/SSEGCN-ABSA: SSEGCN: Syntactic and Semantic Enhanced Graph Convolutional Network for Aspect-based Sentiment Analysis
论文内容
1.研究背景
基于方面的情绪分析(ABSA)旨在确定句子中给定方面术语的情绪极性,其中情绪极性包括积极、消极和中性。例如,在图1中,ABSA决定了人们对“食物”和“服务”这两个方面的情绪。对于方面术语“食物”,情绪的极性是消极的,而“服务”是积极的。也就是说,我们需要根据不同方面。大多数作品的主要思想是建模各方面及其相关的意见词之间的依赖关系。
前期研究利用注意机制来模拟方面项与上下文之间的相关性。然而,注意机制很容易受到句子中的噪声的影响,即不相关的单词。最近关于ABSA的研究利用图神经网络(GNNs)在句子的依赖树上利用句法结构。Zhang等人(2019)使用了图卷积网络(GCN)来整合句法信息。Sun等人(2019)提出了一个GCN模型来增强通过双向长短期记忆(Bi-LSTM)学习到的方面的特征表示。然而,这两项研究对图中当前节点的所有相邻节点处理对待,且缺乏有效的机制来区分相邻节点重要性的限制。因此,噪声节点可能导致模型误解情绪极性。为了解决这个问题,Huang和Carley(2019)设计了一个目标依赖的图注意网络(GAT),利用多头注意更新每个节点的表示。注意机制用于考虑每个邻居节点的语义相关性,但是它是只计算相邻节点重要性的局部注意,忽略了句子的全局信息。按照这条线,Chen等人(2020)和Li等人(2021)将一个句法结构图与一个潜在的语义图结合起来,但这两个图是独立构建的。
值得注意的是,现有的基于GCN的方法并没有充分利用语法结构,其中只考虑了邻居节点的信息。此外,一些hard-cases模糊地表达了方面词的情感,方面词与意见词之间没有直接的句法关系。如何一次捕获二阶节点、三阶节点甚至全局句法结构的信息仍然是一个挑战。近年来,大多数方法都采用多层gcn来推导出会带来潜在噪声的意见词的表达式。例如,考虑如图1所示的依赖树,在方面“食物”和意见词“good”之间存在依赖连接。然而,“好的”指的是另一个方面的“服务”。对于方面术语“食物”,利用“not”表示GCN。同时,对方面术语“服务”也得到了噪声词“not”。因此,简单地考虑依赖树的语法结构可能并不令人满意。有必要为不同的方面术语利用与方面相关的语义信息。

在本文中,我们提出了一种新的语法和语义增强图卷积网络(SSEGCN)模型,用于整合句子的语法和语义信息来解决上述问题。首先,SSEGCN用句子编码器捕获上下文化的单词表示。其次,为了对不同方面术语的特定语义相关性进行建模,我们提出了一种与自我注意相结合的方面感知注意机制。方面感知注意力机制学习了与方面相关的语义信息,而自我注意力机制学习句子的全局语义。我们将得到的注意力分数作为GCN的初始邻接矩阵。此外,为了充分利用句法结构来补充语义信息,而不仅仅是语法一阶邻域节点信息,我们构造了由句子句法依赖结构中单词之间的不同距离计算出的语法掩码矩阵,从局部到全局学习结构信息。然后,我们结合邻接矩阵和语法掩码矩阵来增强传统的GCN。最后,实现多层图卷积运算,获得用于方面项情绪分类的方面特定特征。我们在三个基准数据集上评估了我们的方法。结果表明,我们的模型比一系列的基线更有效,并取得了新的最先进的性能。
我们的贡献总结如下:
-
我们提出了一个有效地集成了语法结构和语义相关性的SSEGCN模型。
-
我们提出了一种结合自我注意的方面意识注意机制来学习与方面相关的语义相关性和句子的全局语义。同时,我们构造了语法掩码矩阵来补充语义信息。
-
在三个基准数据集上的实验结果表明,SSEGCN模型达到了最先进的性能。
2.相关方法
基于方面的情绪分析是一种细粒度的情绪分析任务,通常作为一个分类问题来处理。早期的方法手动定义了一些句法规则来预测方面项的情绪极性。最近的研究利用基于注意力的神经网络建模上下文和方面项之间的语义关联来解决基于方面的情绪分析。其中,(Wang et al.,2016)利用注意机制集中于句子的不同部分,生成用于方面情绪分类的注意向量。Chen等人(2017)提出了一个多层注意网络来推断该方面的情绪极性。Ma等人(2017)引入了一种交互式注意机制,分别生成各个方面和上下文的表示。Wang等人(2018)设计了一个层次的方面特定的注意模型。Hu等人(2018)采用了一个受限的注意网络同时采用正交正则化和稀疏正则化。
另一种趋势显式地利用了依赖树。语法信息可以在方面与相应的意见词之间建立关系联系,基于依赖树的GCN在ABSA中取得了显著的性能。(Zhang等人,2019;Sun等人,2019)堆叠一个GCN层,以在依赖树上提取丰富的表示。Liang等人(2020)构建了特定方面和特定的方面间图来学习特定方面的情绪特征。Zhang和Qian(2020)构建了一个全局词汇图来捕获单词的共现关系,并结合了一个全局词汇图和一个句法图。Liang等人(2021)通过整合SenteNet的情感知识,构建了情感增强图,考虑意见词与方面词之间的情感信息。Tian等et al.(2021)利用依赖类型区分不同的关系。然而,这些方法通常忽略了句法结构和语义相关性的有效融合,以获得更丰富的信息。
3.研究方法
在本节中,我们将描述SSEGCN模型,它主要由三个组件组成:输入层和编码层、注意层、语法掩码层和GCN层。接下来,将在其余部分中单独介绍SSEGCN的组件。

Input and Encoding Layer
给定一个句子方面对(s,a),其中s = {w1,w2,…,wn}。a = {a1,a2,…,am}是句子s的一个方面,也是一个子序列。我们利用BiLSTM或BERT(Devlin et al.,2019)作为句子编码器来提取隐藏的上下文表示。我们首先用嵌入矩阵将每个单词映射到一个低维的实值向量中E = R^{|V|*de},其中|V |是词汇表的大小,de表示单词嵌入的维数。因此,句子s具有相应的单词嵌入x = {x1,x2,…,xn}。通过句子的单词嵌入,BiLSTM被用来产生隐藏的状态向量H = {h1,h2,…,hn},其中hi∈R2d。H包含对应于方面项表示的子序列ha={ha1,ha2,…,ham}。以H作为SSEGCN中的初始节点表示。对于BERT编码器,我们采用“[CLS]sentence[SEP]aspect[SEP]”作为输入。
Attention Layer
注意机制是捕捉方面和上下文词之间相互作用的一种常见方法(Fan et al.,2018)。在本小节中,我们结合了方面感知注意和自我注意,以获得更好的语义特征。图2显示了多个注意邻接矩阵。在这里,我们构造p矩阵,p是一个超参数。
Aspect-aware Attention
与句子水平情绪分类任务不同,基于方面的情绪分类是判断上下文句子中一个特定方面术语的情绪,因此需要基于不同方面术语对特定的语义相关进行建模。我们提出了方面感知注意机制,它将方面术语作为对学习方面相关特征注意力计算的查询:
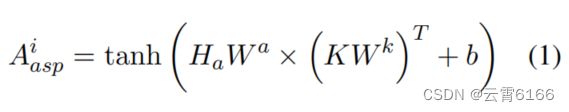
其中,K等于编码层产生的H。Wa∈R×R和Wk∈R×R是可学习的权重。我们在ha上应用平均池,然后复制n次,得到Ha∈Rn×d作为方面表示。注意,我们使用p头方面意识注意来获得一个句子的注意得分矩阵,Ai_asp表明它是通过第i个注意头获得的。
Self-Attention
类似地,这里可以利用p头自我注意(Vaswandatal.,2017)来构建自身,捕捉单个句子中两个任意单词之间的相互作用。该计算包括一个查询Q和一个键K:

其中,Q和K都等于编码层产生的H。WQ∈R{d×d}和WK∈R{d×d}是可学习的权重。然后,我们将方面意识注意得分与自我注意得分相结合:
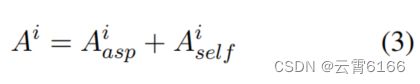
其中,Ai∈R^{n×n}被用作计算后面的语法掩码层的输入。对于每个Ai,它代表一个完全连通的图。
Syntax-Mask Layer
在本节中,我们首先介绍语法掩码矩阵,然后根据不同的语法距离来掩码每个全连通图。我们将语法依赖树视为一个无向图,并将每个标记视为一个节点。然后,我们将节点vi和vj之间的距离定义为d(vi,vj)。由于语法依赖树上的节点之间有多条路径,所以我们将最短路径的距离定义为D:
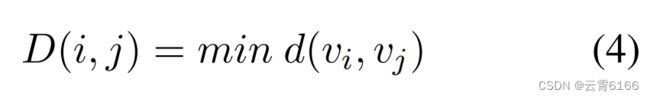
在前一部分中,p-头部注意机制可以得到p个邻接矩阵。因此,我们根据不同的句法距离将语法掩码矩阵的数量设置为与注意头的数量相同。当句法距离相对较小时,我们的模型可以学习局部信息;相反,如果句法距离相对较大,则会考虑全局结构信息。阈值为k的语法掩码矩阵Mk的计算可以表示为:
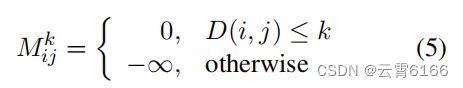
其中,k∈[1,p]。为了获得全局信息和局部特征,注意范围受到不同的语法距离的限制。
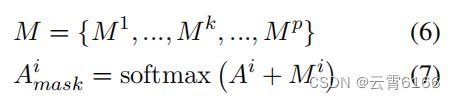
同样,基于距离i的语法掩码矩阵被表示为Ai掩码∈R^{n×n}。
GCN Layer
由于我们有p个不同的语法掩码矩阵,因此需要对Amask∈R{p×n×n}进行图卷积运算。如果我们将h{l-1}表示为输入状态,将h_l表示为第l层的输出状态,则h_0表示为句子编码层的输出。第l层GCN中的每个节点根据其邻域的隐藏表示进行更新:

其中Wl为线性变换权值,bl为偏置项,σ为非线性函数。l层GCN的最终输出表示是H^l = {hl_1,hl_2,…,h^l_n}
在从SSEGCN的每一层中聚合节点表示后,我们得到了最终的特征表示。我们屏蔽了由GCN层学习到的输出表示中的非方面词,以获得方面项表示。此外,还有一个平均池来保留方面术语表示h^l_a中的大部分信息。

其中,f(·)是一个应用于GCN层增强的方面表示上的平均池函数。然后,我们将h^l_a输入一个线性层,然后是一个softmax函数,得到一个在极性决策空间上的概率分布:

其中W_p和b_p为可学习的权重和偏差。
Training
最后,用标准的交叉熵损失作为我们的目标函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZDMBku0x-1669725544751)(image/image_8N46u3_qzR.png)]
其中D包含所有的句子-方面对,a表示句子s中出现的方面。θ表示所有的可训练的参数,C是情绪极性的集合。
4.实验效果
Datasets
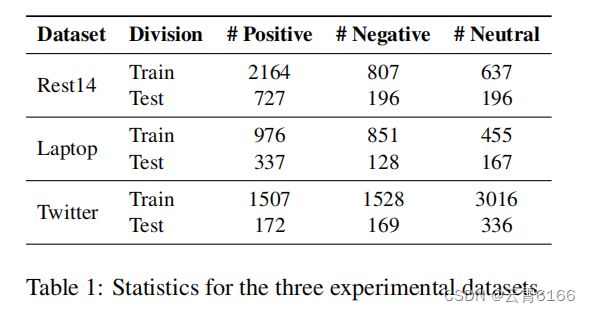
我们在三个基准数据集上进行了基于方面的情绪分析的实验,包括来自SemEval 2014任务4(Pontiki等人,2014)和来自Dong等人(2014)的Twitter(推特文章)的餐厅和笔记本电脑评论。每个方面都有三种情绪极性中的一种:积极、中性和消极。表1报告了三个数据集的统计数据。
Implementation Details
在我们的实验中,我们使用Penninnton等人(2014)提供的300维Glove向量初始化单词嵌入。此外,我们使用了30维词性(POS)嵌入和30维位置嵌入,这是每个单词相对于句子中的方面项的相对位置。然后,将词嵌入、POS嵌入和位置嵌入连接为输入词表示。所有的句子都由Stanford parser进行解析。所有模型的批处理大小设置为16,GCN层数为2。此外,对BiLSTM的输入字表示应用了辍学函数,并将辍学率设为0.3。我们的模型使用Adam优化器进行训练,学习率为0.002来优化参数。对于SSEGCN+BERT,我们使用了bert-base-uncased英文版本。
Baseline Comparisons
为了全面评估我们的模型的性能,我们与最先进的基线进行了比较:
-
IAN(Ma et al.,2017)交互式地学习方面与其背景之间的关系。
-
RAM(Chen et al.,2017)提出了一个循环注意记忆网络来学习句子表征。
-
TNet(Li et al.,2018)采用CNN模型,通过转换后的BiLSTM嵌入,从目标特定的嵌入中提取显著特征。
-
ASGCN(Zhang et al.,2019)提出构建GCN来学习ABSA的语法信息和单词依赖关系。
-
CDT(Sun et al.,2019)利用依赖树模型上的卷积来学习句子特征的表示。
-
TD-GAT(Huang和Carley,2019)提出了一种用于方面级情绪分类的目标依赖图注意网络,该网络明确利用了单词之间的依赖关系。
-
BiGCN(Zhang and Qian,2020)在句法图和词汇图上构建了一个用于情感预测的概念层次结构。
-
kumaGCN(Chen et al.,2020)结合了来自依赖图和潜在图的信息来学习语法特征。
-
R-GAT(Wang et al.,2020)提出了一种关系图注意网络,对由普通依赖解析树重塑的新树进行编码。
-
DGEDT(Tang et al.,2020)提出了一种依赖图增强的双变压器网络,通过联合考虑来自变压器的平面表示和来自依赖图的基于图的表示。
-
DualGCN(Li et al.,2021)设计了一个SynGCN模块和一个具有正交和微分正则化器的SemGCN模块。
-
BERT(Devlin et al.,2019)是普通的BERT模型,它采用了“[CLS]句子[SEP]方面[SEP]”作为输入。
-
R-GAT+BERT(Wang et al.,2020)是基于预训练的BERT的RGAT模型。
-
DGEDT+BERT(Li等人,2021年)是基于预先训练过的BERT的DGEDT模型
-
BERT4GCN(Zhang and Qian,2020)整合了BERT PLM的语法顺序特征和依赖图的语法知识。
-
T-GCN(Tian et al.,2021)利用依赖类型来区分图中的不同关系,并使用注意层集成从不同的GCN层学习上下文信息。
Main Results
为了证明SSEGCN的有效性,我们将我们的模型与之前使用准确性和宏观平均f1作为评价指标的工作进行了比较,并在表2中报告了结果。实验结果表明,SSEGCN模型在三个数据集上的性能最好。特别是,基于GCN的模型考虑了句子的句法结构,并捕获了方面词和意见词之间的长期句法依赖性,因此优于所有基于注意力的方法。在基于GCN的模型中,我们的SSEGCN从局部到全局学习结构信息,考虑与方面相关的语义信息,性能明显优于之前的基于GCN的模型(CDT、TD-GAT、BiGCN、KuamGCN、an、R-GAT、DGEDT和DualGCN),这些模型验证了语法和语义信息融合的有效性。另一方面,我们可以观察到,基本的BERT已经明显优于大多数ABSA模型。将我们的SSEGCN与BERT相结合,结果表明,这个强大的模型的有效性进一步提高,证明了SSEGCN学习更多的句法和语义知识可以增强ABSA。

Ablation Study
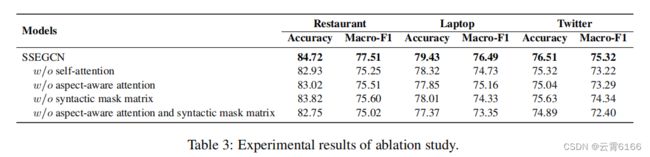
如表3所示,我们进一步进行了消融研究,以检验SSEGCN中不同模块的有效性。基本的SSEGCN被认为是一个基线模型。首先,我们观察到去除自我注意会降低性能,从而验证了句子的全局语义对于ABSA是必要的。我们还可以注意到,没有方面意识注意的模型表现不令人满意,这表明该模型缺乏捕获方面相关语义的能力,导致餐厅、笔记本电脑和Twitter的准确率分别降低了1.70%、1.58%和1.47%。这表明方面意识注意对于获取方面和上下文词之间的相关语义信息至关重要。其次,去除语法掩码矩阵在餐厅、Laptop和Twitter上的准确率分别下降了0.90%、1.42%和0.88%,说明语法掩码矩阵可以帮助GCNs在原始依赖树中学习更好的语法结构信息。此外,去除语法掩码矩阵和方面感知注意导致性能显著下降,这进一步表明这两个成分在ABSA任务的SSEGCN中起着至关重要的作用。综上所述,消融实验结果表明,各成分对我们的整个模型都有贡献。
Case Study
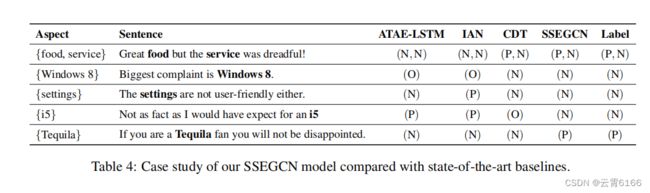
为了检验SSEGCN是否能够捕获语法和语义信息来改进ABSA,我们对一些样本句子进行了案例研究。特别是,我们将表4中的SSEGCN与ATAE-LSTM、IAN和CDT进行了比较,其中包含了他们的预测和这些句子上对应的真实标签。表中的符号P、N、O分别代表积极、消极和中性情绪。第一个样品是“食物很棒,但服务却很糟糕!”有两个方面(“食物”和“服务”)与对比的情感极性,这可能会干扰注意力模型的预测。第二个样本“最大的投诉是Windows8”。有干扰词“最大的”,这可能会中和“投诉”一词的极性。在第三个样本中,关键是捕获否定的语义,这是大多数方法往往忽略和容易做出错误的预测。最后两个例子没有明确的情感表达。对于“不像我所期望的那样事实”这句话,CDT不能从句法的角度获得关键字“not”的表示,从而产生错误的预测。因此,学习句子积分语义的能力是ABSA任务的一个重要因素。我们的SSEGCN正确地预测了所有的样本,结果表明SSEGCN有效地结合了句法结构和语义信息。此外,在处理具有内隐情绪表达的复杂句子时,我们的SSEGCN可以获得更好的表现。
Visualization
为了进一步演示我们的SSEGCN如何改进ABSA任务,我们使用了图3中的两个测试示例来可视化注意力分数。对于句子“员工们应该更友好一点。,我们的模型正确地将方面术语“员工”的情绪识别为消极情绪。我们的SSEGCN模型考虑了句子的语义,通过句法距离掩码和方面意识注意,减少了“友好”一词的注意权重。对于具有不同情绪极性的多个方面的较难的例子,我们的模型也表现良好。这句话“很好吃,但服务很糟糕!”,我们的模型通过引入方面感知注意和结合语法掩码矩阵来考虑与方面相关的语义相关性。因此,SSEGCN可以准确地找到各方面项对应的意见词。

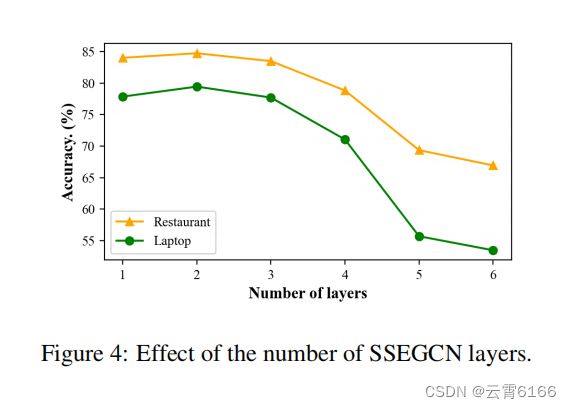
Effect of SSEGCN Layers
在本节中,我们将研究范围从1到5的层数对餐厅和笔记本电脑数据集的影响。如图4所示,实验结果表明,我们的模型在2层实验中达到了最好的性能。首先,如果GCN层数设置为1,SSEGCN只能学习语法距离为1的局部节点信息。其次,当GCN层数较大时,节点表示会过于平滑,从而获得更多的冗余信息,从而导致模型的性能较差。
Effect of Syntax-Mask
在本节中,我们进一步分析了多种不同的语法掩码矩阵对餐厅和笔记本电脑数据集的SSEGCN性能的影响。我们从1到7进行不同数量的语法掩码矩阵,结果如图5所示。我们观察到,当语法掩码矩阵的数量小于5时,所提出的SSEGCN随着数量的增加而呈上升趋势。其中一个主要原因可能是,当句法距离增大时,SSEGCN可以从局部到全局学习结构信息,并在5个语法掩码矩阵上取得了显著的效果。然而,增加了语法掩码的数量从5到7会导致SSEGCN的性能下降。当句法距离大于5时,多个语法掩码矩阵为全连通矩阵,并导致噪声的引入和模型性能的下降。

5.研究结论
在本文中,我们提出了一种将语义信息和语法结构相结合的SSEGCN架构。具体来说,我们首先设计了一种方面感知注意机制,它负责学习点化语义信息。然后,我们将其与自我注意相结合,构成了注意层。此外,我们根据学习局部到全局结构信息的不同语法距离,构造了一个句子的语法掩码矩阵。因此,我们将注意得分矩阵与语法掩码矩阵相结合来融合语义和句法信息。实验结果证明了我们的方法在三个公共数据集上的有效性。
与我研究相关
-
回答了我为什么要读的问题了吗?
内容
-
同意/反对
内容
-
准备正面/负面的引用吗?
内容
-
准备深度的讨论吗?
内容
精读笔记
-
Note that… 注意:…
-
内容
-
内容