万字综述:行业知识图谱构建最新进展

作者|李晶阳[1],牛广林[2],唐呈光[1],余海洋[1],李杨[1],付彬[1],孙健[1]
单位|阿里巴巴-达摩院-小蜜Conversational AI团队[1],北京航空航天大学计算机学院[2]
摘要
行业知识图谱是行业认知智能化应用的基石。目前在大部分细分垂直领域中,行业知识图谱的 schema 构建依赖领域专家的重度参与,该模式人力投入成本高,建设周期长,同时在缺乏大规模有监督数据的情形下的信息抽取效果欠佳,这限制了行业知识图谱的落地且降低了图谱的接受度。
本文对与上述 schema 构建和低资源抽取困难相关的最新技术进展进行了整理和分析,其中包含我们在半自动 schema 构建方面的实践,同时给出了 Document AI 和长结构化语言模型在文档级信息抽取上的前沿技术分析和讨论,期望能给同行的研究工作带来一定的启发和帮助。
引言
从计算到感知再到认知的人工智能技术发展路径已经成为大多人工智能研究和应用专家的共识。机器具备认知智能,进而实现推理、归纳、决策甚至创作,在一定程度上需要一个充满知识的大脑。知识图谱 [4, 18, 19],作为互联网时代越来越普及的语义知识形式化描述框架,已成为推动人工智能从感知能力向认知能力发展的重要途径。
知识图谱的应用现在非常广泛:在通用领域,Google、百度等搜索公司利用其提供智能搜索服务,IBM Waston 问答机器人、苹果的 Siri 语音助手和 Wolfram Alpha 都利用图谱来进行问题理解、推理和问答;在各垂直领域,行业数据也在从大规模数据到图谱化知识快速演变,且基于图谱形式的行业知识,对智能客服、智能决策、智能营销等各类智能化服务进行赋能。
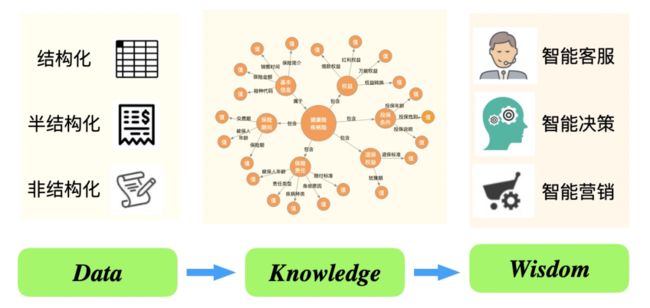
阿里巴巴云小蜜团队研发的知识图谱问答系统目前主要服务政务、运营商、保险、税务、教育、医疗等领域。在这些行业的知识图谱问答应用落地实践中,我们发现行业图谱构建面临如下挑战:
图谱schema构建困难:行业知识图谱 schema 构建往往由对业务更加熟悉的业务专家来承担。尽管业务专家对业务更加擅长,但其对图谱及 schema 概念的理解和使用却有不小的启动成本,这直接导致业务专家无法快速从自身业务知识中抽象组织归纳出满足应用需求的图谱 schema;
低资源信息抽取困难:区别于通用领域所积累的大规模有监督数据资源,大部分细分垂直领域所能提供用以进行信息抽取的有监督资源是有限的。如何在有监督资源有限的情况下,如何从模型和行业数据的角度来提升三元组抽取的效率和性能,是行业信息抽取的核心挑战。
此外,越来越多的垂直领域图谱应用场景是以文档为直接源数据来进行,如何有效的解析各种类型的文档数据,以及设计合理的文档级信息抽取模型,也在行业图谱构建的诸多挑战中占据越来越核心的的位置。
在后续部分(见下图),本文首先介绍 schema 构建所涉及到的关键技术和我们在 KBQA 落地中用于辅助业务专家进行 schema 构建的半自动 schema 构建方案的介绍;接着讲述实体识别模块所面临的挑战和相应的技术解决方案,主要从领域知识融入、半监督学习和复杂实体识别三个角度进行阐述;
关系抽取部分,本文从远程监督、小样本学习、实体关系联合抽取以及篇章级关系抽取等角度讲述其所面临的关键挑战和现有解决方案。结合业务的实际需求,文末本文还提出了文档级信息抽取的新挑战并给出了潜在解决方案的探讨。


schema构建
知识图谱 schema 构建是构建知识图谱的首要步骤,但同时也是非常影响项目快速推进的环节之一。在基于知识图谱的应用在各类行业中落地的进程中,大部分行业没有接触过知识图谱,因而没有沉淀行业内的知识 schema 用以构建行业图谱。
同时由于知识图谱的概念较新,行业业务专家需要一个从理解到熟练构建 schema 的过程,而此过程往往还需要算法人员的频繁介入。如此在一个新的行业中落地图谱相关的应用时,按照我们的项目经验,完整的 schema 构建往往需要消耗周级甚至月级的时间单位。
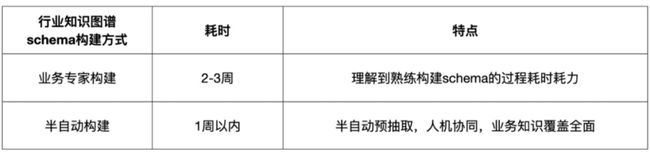
在新的行业落地图谱应用时,为了节省图谱 schema 构建的时间和人力成本,我们需要一套半自动 schema 构建的方案,从而将 schema 构建的时间复杂度降到天级的时间单位。从信息抽取技术上来讲,面对一个新的行业,其中的业务知识的特点在于其开放性以及与过往领域知识的独立性,因而我们借鉴了开放信息抽取领域(OpenIE)中的一些技术和想法来实现我们的需求。
因此,在本节后续部分,我们会讲述 OpenIE 中的一些技术进展,并且对我们在半自动 schema 构建的算法探索进行介绍。
1.1 开放信息抽取
1.1.1 简介
开放信息抽取(OpenIE)是指机器通过阅读、整合和梳理没有固定实体和关系类型的开放自由文本,自动从中抽取出结构化知识。一般来讲,OpenIE 包含开放实体识别和开放实体关系抽取。由于 schema 构建涉及实体和关系,因此,这里的 OpenIE 特指开放实体关系抽取。
举例来说,OpenIE 从句子“阿里巴巴是总部设立在中国杭州的一家科技公司”中抽取出(“阿里巴巴”,“总部设立在”,“中国杭州”)和(“阿里巴巴”,“是”,“科技公司”)两个三元组。通常,OpenIE 所抽取出的一般称 SPO 三元组,分别指 Subject, Predicate, Object。
此方向上的常用数据集包括 FewRel [1,2],NYT-FB [6],OIE2016 [3] 等,评价指标是以预测的准确率,召回率和 F1 值为评价指标。
1.1.2 模型介绍
(1)经典抽取系统
较为经典 OpenIE 系统基本都是基于句子的句法和语法规则加以相应的三元组判别器进行 SPO 抽取。以 TextRunner [5] 为例,其主要分为三个步骤:
1. 分类器训练:基于语法解析得到名词性短语,以短语之间的词语为关系并进行规则筛选构建三元组正样本,以随机替换等方式构建负样本,人工构建特征训练贝叶斯分类器;2. 初步抽取:如上对句子中的名词性短语和关系进行抽取,根据分类器判别所抽取的三元组是否可信;3. 三元组筛选:对所抽取出的关系进行基于规则的归一化,并统计三元组的频次。
随着深度学习的发展和相关数据集的不断丰富,近年来,OpenIE 方向也出现了一些基于深度学习的有监督和无监督的方法。
(2)无监督抽取
DRWE [7] 模型(见下图)采用无监督的方法进行开放关系识别。具体来说,其利用一些已有的工具识别出句子中的关键实体与实体对以及最短依存路径,之后结合预训练的词向量、实体对之间的最短依存路径和实体类型构建特征向量并进行 PCA 降维,进而通过层次聚类得到最终的关系聚类结果。

RSN 模型 [8] (见下图)在已有的关系标注数据上,基于 CNN 模型训练了句子之间的语义匹配模型,并将此模型用于计算测试数据中句子之间的相似度矩阵,进而利用基于图的聚类算法 Louvain 进行不固定聚类类别的聚类。RSN 模型在半监督、远程监督的关系识别任务上都取得了很好的效果。此类模型受限于已有的实体识别和句法分析工具或者需要先验的标注数据进行更加精准的聚类,且其仅对关系进行聚类但没有进行显式的抽取。

(3)有监督抽取
RnnOIE [9](见下图)采用有监督的方法,将 OpenIE 的 SPO 抽取建模为序列标注问题。具体来说,其将词的词向量和词性向量进行 concat,输入到 BiLSTM 中,最终以 softmax 输出进行标签分类。近几年随着 bert 的提出,大规模预训练模型带来了更好的泛化能力,Span Select 的方法,因为其可以利用更多语义信息,渐渐开始超越了传统 OpenIE 上基于 CRF 的相关方法。
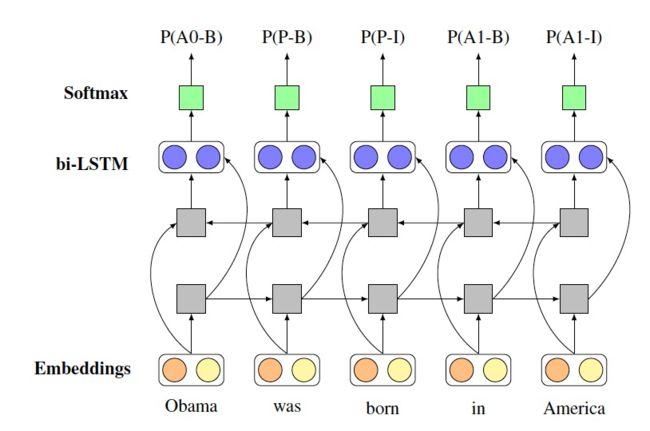
由于大规模标注数据很难获取,RnnOIE-SupervisedRL [73] 模型(见下图)首先基于句法和语义规则自动进行大规模抽取,在此数据上训练 RnnOIE 模型,得到初步的抽取模型。为了增强模型的准确性,RnnOIE-SupervisedRL 对前述初步抽取模型,采用强化学习的训练机制进行了进一步训练,其 reward 是由抽取结果的基于 head match 的句法满足度和基于 Bert 的预训练模型给出的语义匹配度的乘积得到。
实验证实,上述模型在 OIE2016 数据集上的 F1 值由 20.4% 提升到了 32.5%,两个子模型分别贡献了约 4% 和 8% 的提升。上述模型目前所考虑的 SPO 形式还较为简单,对于复杂情形(如包含一个 SP,多个 O 的句子)的处理还需进行深入研究。

(4)生成式模型
Neural OpenIE [11] 将 Encoder-Decoder 架构引入到 OpenIE 任务中来,从而将信息的抽取模式转化为信息的生成模式。此模式可以有效解决隐式 Predicate 抽取问题,比如从句子“张三,90 后,喜爱二次元”中抽取出(张三,出生年代,90 后),其中“出生年代”是隐式的 Predicate。此类方法面临和前述有监督方法相同的复杂信息抽取和信息归一的困难。

1.2 半自动schema构建
在基于知识图谱的问答(KBQA)中,我们实现了基于问句的半自动 schema 构建。以公积金场景为例,下图展示了公积金图谱 schema 的一部分,算法做的是从用户的大量问句中抽取“公积金”为 subject,“缴存”、“提取”、“启封”为 predicate。
同时由于实际中涉及一些复合类型属性(compound value type),比如“提取”属性是复合类属性,因其含有限制属性“提取地点”和“公积金用途”。如后面基于 GNN 的抽取图所示,算法是从问句集中抽取(公积金,抽取,租赁住房),再由业务方校验和进一步抽象为(公积金,抽取,公积金用途)。
因此,算法最终要从问句中抽取出 subject, predicate 和 constaint 三部分,分别对应前述例子中的 “公积金”,“抽取”和 “租赁住房”。

基于句法的 pipeline 式抽取
我们采用 subject-predicate-constraint 的 pipeline 抽取模型,方案逻辑大致为:首先对问句文本进行聚类(不固定聚类数目),然后从每个聚类簇中抽取一个三元组(实体,主属性,限制条件/子属性值),其中实体,主属性,限制条件/子属性值为词汇或者短语,例如三元组(公积金,提取,租赁住房)。
我们首先实现了以依存句法分析为核心的 Deductive 抽取流程(如下图所示),其中主要包括层次聚类,关键词/短语抽取与对齐,词性分布归纳,Subject、Predicate、Constraint 抽取等模块。
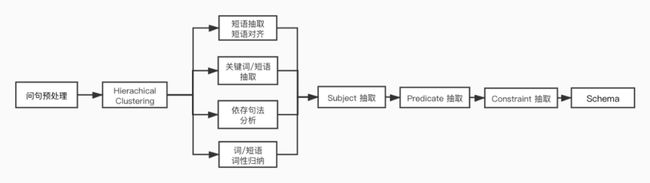
▲ 基于句法的pipeline式抽取图
基于 GNN 的抽取
我们发现上述方案没有很好的考虑各类依存句法逻辑之间的综合关系,且泛化性能有限。因此,在上述方案基础上,设计并实现了将聚类簇图结构化,并借鉴知识图谱上图卷积神经网络方法进行建模的方案。为了达到领域无关的效果,图结构中节点的 embedding 表示是基于词汇在簇词汇集中的位置 onehot 表示生成得到。
从实际效果来看,基于 GNN 的模型相较于第一个版本的模型具有更好的泛化性和准召率。下图给出和(公积金,提取,租赁住房)相关的聚类簇图结构化的展示例子。

▲ 基于GNN的抽取图
1.3 小结
从行业知识图谱的 schema 构建出发,本节介绍了开放信息抽取(OpenIE)与 schema 构建的之间的关系,并对 OpenIE 中的基于规则、基于监督数据以及基于生成式的模型进行了介绍。同时,本节还介绍了在 KBQA 场景下,由 OpenIE 启发,基于用户问句的半自动 schema 构建算法的简要介绍。
虽然我们实现了基于问句的半自动 schema 构建的初步版本,但在真实落地中还存在很多挑战和困难,后续我们可能在如下方向进行深入探索:
复杂样本,如一个聚类簇包含一个 SP,多个 O 的情形;
将行业预训练语言模型引入来提升模型的泛化性;
借助 OpenIE 中的生成式模型来抽取问句中隐含的属性或者条件信息,如“我今年 56 了,能购买康宁保险吗?”中“我今年 56”的隐含条件信息是“年龄”。
知识图谱 schema 的构建完成类似于关系型数据库中的表名和表中的栏位名确定了,之后就需要向表中填充真实的数据。由于知识图谱由(实体,关系,实体)三元组构成,因此后续构建的关键在于实体识别和关系抽取。

实体识别
2.1 简介
命名实体识别(Named Entity Recognition,简称 NER),是指识别文本中具有特定含义的实体,常用 NER 数据集中的实体类型主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。命名实体指的是可以用专有名词标识的事物,一个命名实体一般代表唯一一个具体事物个体,包括人名、地名等。
2.2 数据集和评测指标
常用的中文 NER 数据集包括,OntoNotes4.0 [12],MSRA [13] 和 Weibo [14] 等,前两个是由新闻文本中抽取得到,后一个是由社交媒体中抽取得到。常用的英文数据集有 CoNLL2003 [15],ACE 2004 [16] 和 OntoNotes 5.0 [17] 等。想了解更多数据集,建议参见 [74]。
在数据标注上,主要有 BIO(Beginning、Inside、Outside)和 BIOES(Beginning、Inside、End、Outside、Single)两种标注体系。此外,还有针对复杂实体抽取建立的改进版本的标注方法,将会在 2.4.4 部分进行介绍。
在模型评测上,由于命名实体的识别包括实体边界和类型的识别,因此只有一个实体的边界和类型都被正确识别时,才能被认为实体被正确识别。根据对实体边界预测的精准度的要求不同可以分为 Exact Match 或 Relaxed Match,并且使用准确率,召回率以及 F1 值来计算得分。目前,基于 Exact Match 的 micro 的准确率,召回率以及 F1 值最为常用。
2.3 面临的挑战
目前,命名实体识别在行业知识图谱构建方面主要面临如下挑战:
垂直领域标注语料少,导致模型效果不好
垂直领域细分类别很多,在进入一个新的垂直领域时,往往可用的监督数据是很有限的。在此基础上所训练得到的模型的识别效果是不尽人意的。
垂直领域先验知识未能有效利用
在有监督数据足够的前提下,行业内其他类型的先验知识的量相对来讲是更大的。但是这些行业数据却没有很合理的应用到 NER 任务中来更有效的提升模型性能。
垂直领域复杂实体难以识别
一般研究和落地中遇到的实体识别大多为连续实体的识别,但复杂实体识别在实际应用中的占比越来越高,特别是在医疗领域的实体抽取中。
2.4 主流NER深度学习模型
我们对和前述挑战相关的技术进展进行了调研,本节内容给出相应的汇报和分析。
2.4.1 经典模型
基于深度学习的 NER 模型,大都将 NER 任务建模为序列标注任务,并且以 Encoder-Decoder 架构来进行建模。
最先将深度学习应用于 NER 任务的模型当数 LSTM+CRF 模型 [20],不同于经典的人工特征设计,LSTM+CRF 模型基于数据来进行特征学习,且取得了很好的效果,极大推进了深度学习在 NER 中应用的进程。
之后,在模型设计中,BiLSTM [21] 取代了 LSTM 作为Encoder。除了以 LSTM 为代表的循环神经网络RNN模型作为 Encoder,也有以卷积神经网络 CNN 作为 Encoder 的实践。
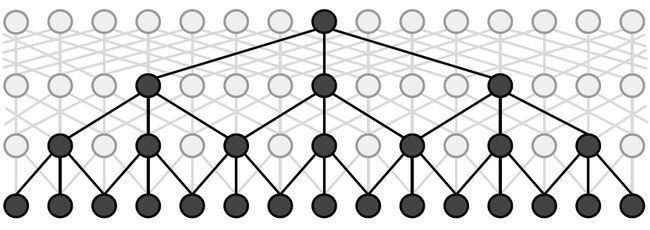
较新的,ID-CNNs [22] 利用 dilated CNN 模型(见下面示意图)解决了原本 CNN 感受野随着卷积层数的线性增长性的局限性,从而扩大了 Encoder 的感受野,进而能整合与利用更加长程的信息进行预测。
以 BERT [23] 为代表的预训练语言模型的出现,使得以 BERT 作为 Encoder 成为新的最强 Baseline,在应用落地中,往往借助知识蒸馏的技术来对 BERT 模型进行蒸馏,从而提升在线预测的效率。
2.4.2 知识增强的模型
(1)词汇增强
对于中文任务来说,句子中的词汇信息显然是重要的,但是先对句子进行分词,在词序列的基础上进行序列标注任务,这种 NER 模型架构的效果受限于分词的准确性。因此,如何将句子中的词汇信息合理的整合到基于字的序列标注模型中,是中文 NER 主流研究方向之一。
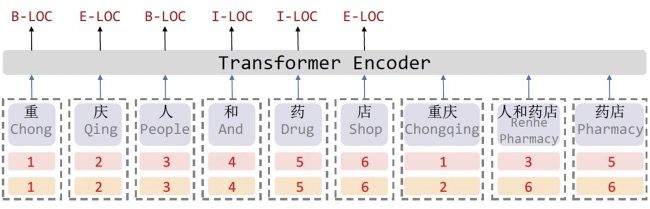
Lattice-LSTM [24] 将句子表示为由其中的词汇和字构成的 Lattice 结构(见下图)。在基于字序列的 LSTM 基础上,Lattice-LSTM 仿效 LSTM 的信息传递机制,将词汇的信息整合进该词汇的首尾字符的表示中。如此模型便将字符级信息和词汇级信息进行了有机的融合,既丰富了模型的语义表达,又使得模型对分词带来的噪声有很好的鲁棒性。
在中文数据集 MSRA [13] 和 WeiBo [14] 上,Lattice-LSTM 的 F1 值相较于基于字符和基于词汇的模型的最好性能均有 2% 以上的性能提升。

LR-CNN [25] 模型通过利用 CNN 模型,以及在 CNN 中引入 Rethink 机制来解决 Lattice-LSTM 模型不能并行化以及句子中词汇之间的混淆的问题。具体的,LR-CNN 将不同 layer 的卷积结果看作不同 n-gram 字符组的向量表示,再将句子中中的词汇向量以 attention 的方式整合到其对应的 n-gram 字符组的向量表示中,以此来整合词汇信息。
为了解决词汇混淆的问题,LR-CNN 将 CNN 的最后一层的 feature 向量和 CNN 每一层的向量表示再次进行attention,从而达到利用最后一层的 feature 来调优 前面特征筛选和表达的效果,进而能够使得模型自适应的调节词汇之间的混淆。
在中文数据集 MSRA [13] 和 WeiBo [14] 上,LR-CNN 相较于 Lattice-LSTM 的 F1 值分别有 0.6% 和 1.2% 的性能提升。

FLAT [26] 在融合字符与词汇的 Lattice 结构上,引入 Transformer 来进行建模。相对于上面以 RNN 和 CNN 为基础架构的模型,FLAT 能整合更加长程的信息的同时,还能更充分的利用 GPU 资源进行并行化训练和推理。
其主要模型点在于:一、将 Lattice 结构按照字符的位置以及词汇的头尾字符的位置重构为序列结构;二、由于 Transformer 所利用的绝对位置向量编码无法很好的建模序列中的顺序信息,因此,FLAT 根据词汇之间的头尾,头头,尾头,尾尾字符距离定义了四种距离,并且对这四种距离进行向量编码。
考虑字符/词汇与其他字符/词汇的向量表示,以及距离的向量表示进行权重计算,最终得到相应的 attention。在中文数据集 MSRA [13] 和 WeiBo [14] 上,FLAT 相较于 LR-CNN 的 F1 值分别有 0.6% 和 3% 的性能提升。
(2)实体类型信息增强
BERT-MRC [27] 将所要预测的实体类型的描述信息作为先验知识输入到模型中,并且将 NER 问题建模为阅读理解问题(MRC),最终通过 BERT 来进行建模。
具体的,给定句子 S 和所要抽取的实体类型如“organization”,其通过问句生成模块将“organization”转换为问句Q“find organizations including companies, agencies and institutions”,将此 Q 和 S 作为两个句子输入到 BERT 中进行训练。
由于实体类型先验知识的加入,在中文数据集 OntoNotes4.0 一半训练数据的基础上,BERT-MRC 的模型效果就能达到单纯将句子 S 输入到 BERT 进行序列标注的模型在全量数据上训练的效果。
此外,由于把每类数据的识别进行了区分,因此,此类模型能有效的解决复杂实体识别中的实体交叉和嵌套问题(见2.4.4)。在中文数据集 MSRA [13] 上,BERT-MRC 相较于前述 FLAT 模型有 1.4% 的提升,达到 95.75% 的 F1 值。
TriggerNER [28] 同样是将实体的类型信息作为模型的输入的一部分,区别于 BERT-MRC,其实体类型信息来源于句子中的一部分词汇,称为 Trigger words。如下图例子所示,通过句子中蓝色字体的 Trigger 词汇,可以推断出 Rumble Fish是一个餐馆名称。在模型实现上,TriggerNER分为TriggerEncoder&Matcher 和 Trigger-Enhanced Sequence Tagging 两部分,此两部分都是基于同一个 BiLSTM 提供词汇的表示信息。
TriggerEncoder&Matcher 部分主要在于基于 Trigger 的表示进行实体类型的预测以及原句子表示与 Trigger 词汇序列表示的匹配,Trigger-Enhance 部分将 BiLSTM 提供的表示信息与 Trigger Encoding 提供的表示信息进行整合,最终通过 CRF 层进行模型输出。
在预测阶段,测试集中句子的 Trigger 词汇是来自于在训练集中整理得到的 Trigger 词典匹配得来。在 CONLL2003 英文数据集上,TriggerNER 在 20% 训练集上进行 Trigger 标注后训练得到的效果和 BiLSTM-CRF 在 70% 原始训练集上训练得到的效果相当。
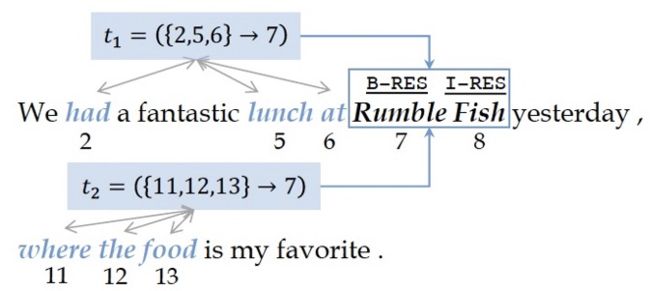
▲ Trigger词汇样例
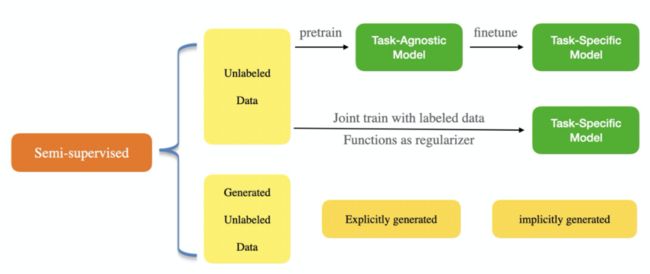
2.4.3 半监督模型
半监督算法旨在在有标签和无标签的数据集上对模型进行建模(整体模型分类见下图)。利用无标记数据进行神经网络半监督学习,在 NER 领域中得到了广泛的研究。
以 BERT [23] 为代表的预训练语言模型,基于大规模的无标签数据,利用 random mask 等机制对词序列的联合概率分布进行建模,从而进行自监督训练,最终能够很好的将文本知识整合到词向量的表示中。在此基础上,在有标签的数据上进行 fine-tune,即可得到效果不错的 NER 模型。
NCRF-AE [29] 将 label 信息建模为隐变量,进而利用 autoencoder 的模型来同时对有标签和无标签数据进行建模训练。具体来说,通过将 label 信息建模为隐变量y, 进而将原本需要预测的概率分布 P(y|x) 替换为如下带隐变量的 encoder-decoder 模型,进而可以利用无标签数据的重构损失来增强标签信息的建模。

区别于 NCRF-AE 将标签信息直接建模为隐变量的方式,VSL-G [30] 通过引入纯粹的隐变量及隐变量之间的层次化结构,并且利用 variational lower bound 来构建重构损失函数,从而将有监督损失和无监督损失函数独立开来。此模型的重要意义在于引入并设计了隐变量之间的层次化结构,在此基础上引入的 VAE 下界损失对于有监督模型中参数起到了很好的正则化作用,从而达到了在小型数据集上就训练就有很好的泛化性能。
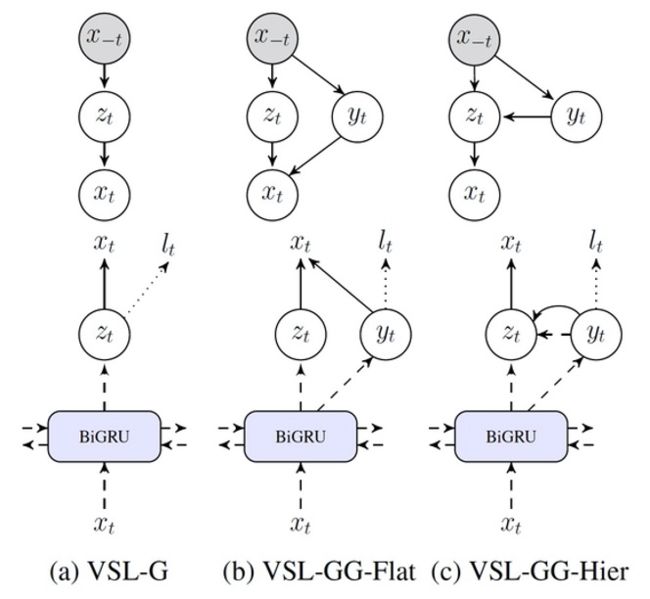
将一个语种中的句子 A 翻译成另一个语种的句子 B,再将其翻译回来 C,从而得到(A, C)平行语料。LADA [31] 发现 A 和 C 中大都包含相同数目的目标类别实体。基于此发现,LADA 将模型在无标签句子 A,C 的每个 token 上的输出向量进行加和,得到的向量为该句子所包含的每类实体的数目向量,将此两个向量的差值的 l2_ 范数作为在无监督样本上的损失。从而可以利用大规模的无监督数据进行模型训练,在数据量较少的情况下,达到了提升模型准确率的效果。
更多的,LADA [31] 将图像领域中用于数据增强的 Mixup 方法引入到 NER 中来。Mixup 方法的核心在于对特征向量进行插值,从而得到新的训练数据。由于 NER 属于序列标注问题,因此需要合理的设计多个 token 的的隐向量的插值方式。LADA [31] 采用将原句子 token 序列进行重新排列组合以及对训练句子集进行 KNN 聚类的方式,得到了句内和句间两种插值方式,实验证明这种插值方式在 NER 上是有效果的。

相比于 LADA 在隐向量层面进行数据增强,ENS-NER [32] 模型采用在词向量上添加高斯噪声的统计学数据增强手段,以及随机掩盖 token 和同义词替换的语言学数据增强手段,从而达到数据增强效果。在相关数据集上的实验证实此类数据增强对于 NER 是有增益的,而且语言学数据增强和统计学数据增强手段的效果相当的。
值得注意的是,除 BERT 等语言模型之外,以上几类半监督模型在原有标签数据量占原有训练集较小比例时,如 10% 左右,其效果是明显的,但是当原有标签训练数据占比变大时,非原有标签数据给模型带来的增益并不明显。
2.4.4 复杂实体
前述模型主要针对连续实体的抽取进行建模,在实际应用中还存在部分复杂实体的识别问题。这里的复杂指的是存在不连续的单实体以及多实体之间的覆盖和交叉关系。下图分别给出不连续实体(discontinuous entity),嵌套实体(nested entities)和 交叉实体(overlapping entities)的例子。
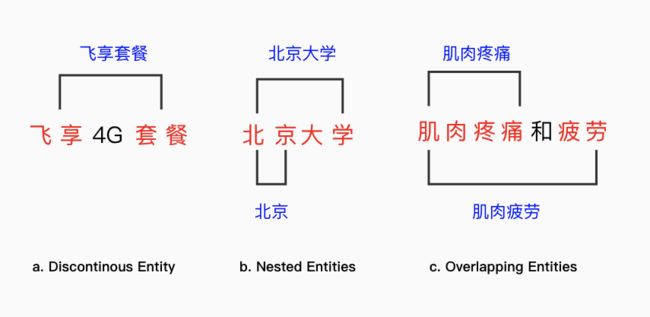
[33] 为解决含有不连续实体的 overlapping 实体识别问题,引入了 BIO 标注体系的变体,即在 BIO 的基础上,增加了 BD,BI,BH,IH 四个指标,分别代表Beginning of Discontinuous body, Inside of Discontinuous body, Beginning of Head 和 Inside of Head。以上面图 c 为例,在新的标注体系下,标注结果为:肌(BH)肉(IH)疼(B)痛(I)和(O)疲(BD)劳(ID)。此类方法的缺陷在于,如果同一句子中出现多个不连续的实体,则会出现实体混淆问题。
[34] 基于 transition-based 方法,引入更加丰富的 action 类别来解决不连续实体 overlapping 识别的问题。具体的,其使用 stack 存储处理过的 span,并使用 buffer 存储未处理的 token。NER 可以重塑为如下过程:给定解析器的状态,预测一个用于更改解析器状态的 action,重复此过程,直到解析器达到结束状态(即 stack 和 buffer 均为空)为止(图下图所示)。显然,此类方法不仅能解决不连续实体识别,也能解决实体嵌套和部分重叠,因此尽管此类方法相较于前述标注方法设计更加复杂,但其给出了解决连续和复杂实体识别的统一框架。此外,此方法属于序列决策问题,因而一个可能的方向是利用深度强化学习的方法来重塑目标函数和优化过程。

更多地,[35] 引入句子的 hypergraph 结构表示来解决多类别实体嵌套和不连续识别问题,相较于经典模型的序列预测,其以局部子图的预测为最终目标。
2.5 小结
本节围绕实体识别任务所面临的三个挑战:标注数据少,行业知识未充分利用以及复杂实体难抽取,对相关技术进展进行介绍,主要包括以 Bi-LSTM+CRF 为代表的经典模型,知识增强的模型,半监督模型和复杂实体识别模型。
从实际应用来看,在经典模型的基础上结合行业词典或实体关系描述的方法得到了广泛的应用,但是在复杂实体的识别上,目前还没有很好的模型结构或者简洁有效的解决方案。

关系抽取
3.1 简介
关系抽取指的是对给定的实体对之间的关系类型进行分类。相较于 OpenIE 中的不固定类型的关系抽取,本部分所讲的关系抽取统指固定关系类别集合的关系抽取。
3.2 数据集和评测指标
目前,关系抽取的 benchmark 数据集主要包括:
句子级关系抽取数据集:ACE-2005 [36],SemEval 2010 Task-8 数据集 [37], TACRED [38]
远程监督关系抽取数据集:NYT 数据集(NYT10)[39]
小样本关系抽取数据集:FewRel [1],FewlRel 2.0 [2];
文档级关系抽取数据集:DocRED 数据集 [40]
在评测指标上,对于有监督的关系抽取任务,使用标准精度,召回率和 F 量度进行评估。对于远程监督的关系抽取模型,将进行保留和/或手动评估。具有知识库的对齐文本的标签不是 golden 的。因此,在持续评估中,只有来自知识库的关系事实才被认为对测试集是正确的,而新预测的关系则被认为是错误的。
由于此假设不能表达现实,因此有时需要人工进行评估。在小样本关系抽取中,以 N-way K-shot 的形式进行配置,N 表示关系(类)的数量,K 表示每个关系的带标注的实例数量。根据不同的数据配置对模型进行测试,并说明测试集上模型的准确性结果。
3.3 面临的挑战
目前,关系抽取是知识图谱自动化构建中最重要也是难度最大的任务之一,在实际应用和算法研究方面主要面临如下挑战:
数据标注成本高:因为从文本中抽取关系需要考虑上下文信息,对人来说本来也是较难的任务,得到高质量的标注数据需要耗时较长,因此人工标注数据的成本很高。
长尾关系效果不佳:在现实场景中,不可避免存在很多的长尾分布的关系,这些关系只有很少量的训练数据,一般的关系抽取方法尤其是基于深度学习的关系抽取方法难以训练。
复杂场景关系抽取困难:实际场景中往往涉及两类复杂的关系抽取,存在较大技术挑战:
(1) 段落级关系抽取:实体间的关系无法从单一句子直接得到,需要阅读整个段落中的多个句子以机器阅读理解的方式才能抽取关系。
(2) 文本中包含多个关系:对于文本中包含多个关系的情况,当前的方法是借助图神经网络捕捉整个文本的拓扑结构信息,同时,有时也需要从句子中的多个关系推理出实体间隐式的关系。
实体识别到关系抽取的误差传播:采用先实体识别再关系抽取的这种 Pipeline 的方式容易造成对关系抽取的误差传播。采用实体关系联合抽取的方法可以有效避免这种误差传播,其中一类有效的方法是可以将实体识别和关系抽取看成一个序列标注任务来实现对整体三元组的建模。
3.4 主流关系抽取深度学习模型
我们调研了近期和以上挑战相关的科研进展,本节后续部分主要包括对这些进展的汇报和我们自己的一些思考,整体上以下图来概括后续主要内容。

此外,我们在 2020 年发表出来的论文中,通过 dblp 搜索关系抽取的论文,按照题目中的关键词进行统计,得到下图所示数据,从中可以看出相关研究的热度分布。

3.4.1 经典模型
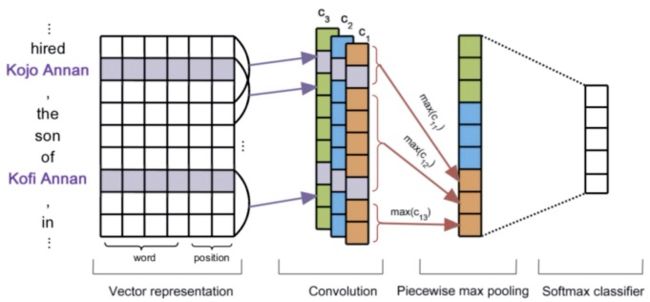
在关系抽取中,提取句子中关系的全局特征是非常关键的。卷积神经网络(CNN)能够组合局部特征来取得能够表示全局的特征。[41] 最早将 CNN 结合 max pooling 和 word embedding 对整个句子进行编码,并将句子编码表示用于关系分类,性能超过了传统的关系抽取方法。
较新的,[42] 提出了多层注意力卷积神经网络(Multi-level Attention CNN),将注意力机制引入到 CNN 中,对反映关系更重要的词语赋予更大的权重,以此来提高关系抽取的效果。
由于 CNN 只能提取局部特征,无法很好的应用于一句话中两个实体之间的距离较远的情况。循环神经网络(RNN)尤其是长短期记忆网络(LSTM)能够学习实体之间的长距离依赖关系,[43] 采用 RNN 进行关系抽取并取得了比基于 CNN 的关系抽取更好的效果。
因此,[44] 发现实体之间的最短依赖路径最能体现实体间的关系特征(在句法依存树中,两实体到公共祖先节点的最短路径),并将其用 LSTM 编码实现了关系抽取。
2018年,预训练语言模型 BERT [23] 在多项 NLP 任务中显示出强大的性能,一个很自然的想法就是用 BERT 模型代替 CNN 或 RNN 对句子进行编码来实现关系抽取。
2019 年,[45] 最早将 BERT 应用在关系抽取中,提出了基于 BERT 的关系抽取 R-BERT 模型,通过将一个句子输入到 BERT,并将 BERT 得到的结果输入到全连接层进行多分类,完成关系抽取任务,这个方法在当时取得了超过所有基于深度学习的关系抽取的效果。
[46] 提出 EPGNN 模型(下图),其结合用 BERT 模型提取的句子特征与用图神经网络提取的实体对在知识图谱中的子图的拓扑特征,以进行关系抽取。

3.4.2 远程监督模型
基于深度学习的关系抽取需要大量的训练数据,但是人工标注这些训练数据非常费时昂贵。为了解决这一问题,[47] 在 2009 年最早使用远程监督技术将输入文本中的句子与 Freebase 知识图谱中的三元组对齐,这时三元组提供了监督信息。然而,使用远程监督的关系抽取方法面临两个主要问题:
无法建模重叠关系:两个实体之间可能存在多个不同的关系,例如(马云,建立,阿里巴巴)和(马云, CEO,阿里巴巴),因此无法确定知识图谱中实体间的哪个关系应该是当前句子需要抽取的关系。
噪声(错误)标签:知识图谱中的三元组对有的句子中的实体对提供的关系标签是错误的,这给模型的训练带来了混淆和错误。
为了解决上述问题,目前主要是从多实例多标签学习、引入更多有效知识和去噪这三个角度实现远程监督的关系抽取。
(1)多实例多标签学习(MIML)
为了解决重叠关系的问题,可以将多实例多标签学习应用于关系抽取任务中。单实例学习模型是从一个句子中预测一个关系类别,而多实例多标签学习方法放宽了这一条件,其从一个句子袋中预测其包含的多个关系类别。下图是一个多实例多标签的典型例子。可以看出,上图中(奥巴马,美国)这对实体对应多个实例(句子),同时知识图谱中(DB)为这对实体提供 2 个标签。

[48] 最早提出基于多实例多标签学习的关系抽取方法 MIML-RE,通过使用概率图模型来表示实体对的“多个实例”和“多个标签”。多实例多标签方法已经能够较好地解决重叠关系的问题,因此,更多的远程监督的方法主要用来解决噪声标签的问题。在多实例学习任务中,如何从一个句子袋中找到与当前关系最相关的句子显得尤为重要。
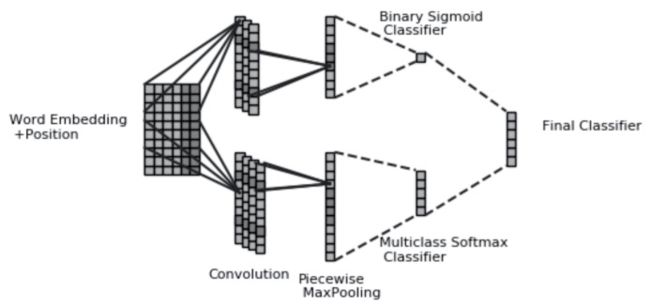
PCNN [49] 在抽取句子特征向量表示时考虑了实体的位置,采用分段池化操作编码每个句子,并选择在一个句子袋中正确预测出关系标签概率最大的一个句子进行参数更新。
考虑到一个句子袋中不同句子表达关系的不同重要性,[50] 引入了句子级别的 Attention 机制,权重更大的句子对参数的更新贡献就大,反之,权重更小的句子对参数更新贡献小,这样能够充分利用所有训练数据。由于关系抽取需要考虑一个句子中实体对的上下文信息,因此依存结构信息对于关系抽取非常重要。
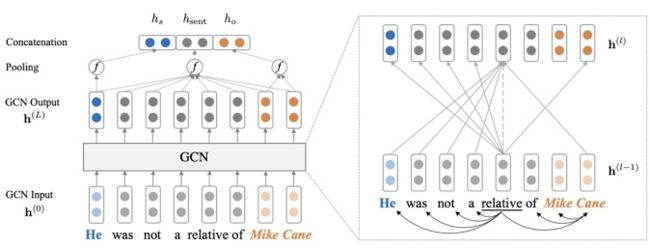
C-GCN [51] 利用 GCN 编码句子的依存树,从而实现关系抽取,其中设计了一个以路径为中心的剪枝方法,移除一个句子的依存树中与关系无关的路径。
(2)引入外部知识的方法
为了能改善实体表示并为关系抽取提供更多语义信息,从而降低噪声信息对关系抽取的影响, APCNN [52] 在 PCNN [49] 中引入了外部实体描述,实体描述为改善实体表示和进一步预测关系能够提供更多语义信息。同时,从知识图谱表示学习的 TransE 模型 [53] 中得到启发,使得关系表示满足:关系表示=头实体表示-尾实体表示的三元组约束,进一步将关系表示用于关系抽取的句子级注意力机制中。
以往的研究将不同的关系之间是独立的,但其实关系集自带结构化的高层语义信息,例如在 Freebase 知识图谱中,关系是用层次结构来表示的,每个关系的最高层表示一般性的关系类型。因此可以从关系层次来捕捉不同关系之间的语义相关性。
基于这一特性,[54] 利用关系的层次结构知识,设计了层次注意力机制,在每个句子袋中关注关系之间的相关性信息,实现从粗到细的实例选择,提升远程监督的关系抽取效果。[55] 将 GCN 用于知识图谱嵌入中得到关系的嵌入表示,并提出了一种由粗到细的知识感知注意力机制,将关联的知识集成到关系抽取模型中。
(3)去除噪声标签的方法
另一个解决远程监督中噪声标注的更为直接的解决方法是去除噪声标签,目前主要有强化学习和对抗训练两类方法。
强化学习去噪
对于远程监督关系抽取,对于错误标记的候选句子最理想的方式是用一个确定性的决策来对待,而不是使用以往的研究中靠注意力权重去处理。为此,[56] 提出了一个根本的解决方案,通过训练深度强化学习策略来生成假阳性指标,能够动态识别每种关系类型的假阳性样本,并将假阳性样本重新分布到真正负样本中,以减轻噪声数据的影响。
类似的,[57,58] 都采用基于强化学习的关系抽取,其将关系抽取问题分解为两个任务:实例选择和关系分类。实例选择器是一种强化学习智能体,它使用关系分类器的弱监督来选择实例。基于强化学习的关系抽取的优点是关系抽取模型与基于强化学习的实例选择模型解耦,因此可以很容易地将这类方法适应于任何基于神经网络的关系抽取模型。
对抗训练去噪
[59] 最早提出采用对抗训练的方法将对抗噪声添加到词嵌入中,以在多实例多标签学习(MIML)的框架下基于 CNN 和 RNN 的方法进行关系抽取。DSGAN [60] 通过学习句子级真实正样本的生成器和判别器来消除远程监督关系抽取中的噪声数据。
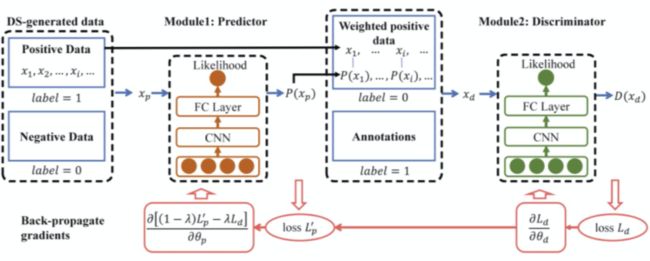
[68] 针对当下噪声数据消除模型的两个不足:(1) 缺乏将显式监督引入去噪过程的有效方法;(2)采样操作对去噪结果造成的优化困难评价,提出了一个对抗性的去噪框架,该框架提供了一种有效的方式来引入人工监督,并在统一的框架中利用该监督以及嘈杂数据背后潜在的有用信息(模型见下图)。
3.4.3 小样本关系抽取
在大多数据集中,关系的分布具有长尾性,对于这些长尾关系可用的训练数据往往数量较少。清华大学刘知远老师团队最早提出小样本关系抽取任务并构建了第一个大型小样本关系抽取数据集 FewRel [1],并且在 2019 年发布了考虑领域迁移和“以上都不是”检测任务的 FewRel 2.0 版本 [2]。
绝大多数小样本关系抽取的研究都会在这两个数据集上进行测试。通常,实现小样本学习的方法分为度量学习和元学习这两个方法,因此,目前的小样本关系抽取也是基于这两类方法。
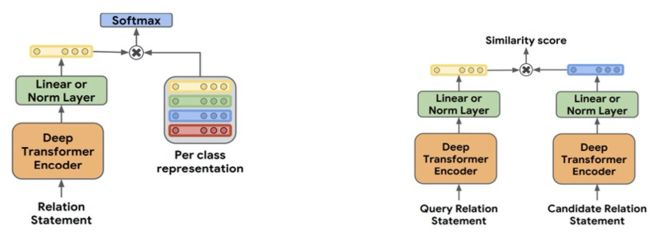
度量学习模型
最新的基于度量学习的方法是谷歌提出的 MTB 模型 [61],其采用对比学习的思想,引入 matching the blanks 目标:如果两个句子中包含相同的实体对,那么它们关系表示的相似度尽可能高,反之相似度应尽可能低。同时其将句子中的实体以一定的概率(论文中是 p=0.7)进行 mask,从而提升模型在实体缺失的情形对句子中关系语义的表示能力。
在过去的一年半时间里,此模型在 FewRel [1] 数据集的全部评测指标上依然处于 SOTA 状态,且在其中两项指标上超越人类的表现。但值得商榷的是,MTB 模型依赖其基于 Wikipedia 自行构建的包含 6 亿句子对的数据集,且其在低资源有监督关系抽取任务如 SemEval 2010 Task-8 [37],TACRED [38] 上的表现还比不上其 Based 模型在全量数据上训练得到的效果。
元学习模型
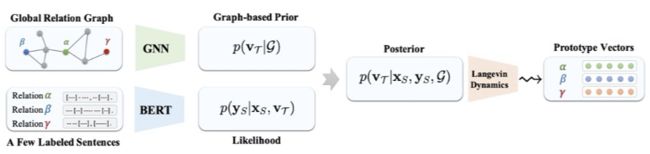
[62] 通过采用一种贝叶斯元学习方法来有效地学习关系原型向量的后验分布,其中关系原型向量的初始参数是通过对全局关系图上用图神经网络学习得到的,然后采用与无模型的元学习算法 MAML 相关的 SGLD 方法对关系原型向量进行优化,接着用优化后的关系原型向量预测关系。
3.4.4 实体关系联合抽取
以上介绍的关系抽取方法都需要首先利用命名实体识别技术确定实体提及及其实体类型,再接着便应用关系抽取技术。这种 Pipeline 的方法容易造成误差传播,也就是如果命名实体识别出现误差,在关系抽取阶段会将这一误差放大进而影响关系抽取的效果。采用实体关系联合抽取的方法可以有效避免这种误差传播。同时,实体识别和关系抽取的目的都是需要自动构建三元组知识,因此这两个任务本来就应是一体的。
(1)基于序列标注的模型
[63] 提出了一个新颖的标注方案(见下图),其将实体关系联合抽取任务当作一个序列标注任务来处理,简化了任务的复杂性,且其模型性能优于之前的 Pipeline 和联合抽取方法,这项工作也取得了 2017 年 ACL 的杰出论文奖。然而,这种方法无法解决重叠关系的问题。

为了解决实体关系联合抽取中的关系重叠的问题,Wei 等人提出了一个新颖的级联二进制标记框架 CasRel [64],不同于传统的关系抽取模型都是为实体预测关系标签,CasRel 的核心思想是把关系建模为从头实体映射到尾实体的函数,也就是在给定关系和头实体的条件下识别出所有可能的尾实体。CasRel 巧妙解决了关系重叠的问题,并在公开数据集上取得了显著的性能提升。

(2)基于文本span的动态图模型
DyGIE [65](见下图)提出将实体识别和关系抽取问题建模为句子中 span 图构建和图节点分类问题,其中图的节点是句子中的 span。此模型跳出了前述序列标注式的一维标注和预测体系,而在二维的图结构上进行标注和预测。

DyGIE++ [66] 在 DyGIE 模型的基础上添加了事件元素识别的任务,并将多个图信息传递之后的节点表示整合后进行最终的预测,更重要的是,此模型用 Bert 替换了原有的 BiLSTM 进行底层的表示。

此类模型可以有效的解决实体识别中的实体嵌套问题,但是对于不连续实体、重叠关系的问题尚未进行充分研究。
3.4.5 段落级关系抽取
现有的大多数关系抽取方法主要面向句子级的关系抽取,然而,在实际场景中,很多实体间的关系需要通过一段文本中的多个句子才能表达。
例如这样的一段文本:“阿里巴巴达摩院成立于 2017 年 10 月 11 日,是一家致力于探索科技未知,以人类愿景为驱动力的研究院,院长是张剑锋。”这段文本包含多个实体,尤其是“阿里巴巴达摩院”和“张剑锋”这一对实体间的关系“院长”需要由多个句子才能得到。针对这类实体间跨多个句子的关系抽取,需要依据类似于机器阅读理解的方式对整个文档中的多个句子联合抽取关系。
[67] 考虑到文档的句子之间存在不同的关联方式,例如共指关系,语义依存树等,提出 GCNN 模型为 5 种不同的关联方式建立不同的图单独进行图卷积操作,然后将各图的结果相加,将文档内句子间多种关联特征组合进行关系抽取。

为了增强段落级关系抽取的通用性,清华刘知远老师团队姚远等人在 2019 年提出了 DocRED 数据集 [40],其是基于维基百科正文和 WikiData 知识图谱构建的,是一个大规模的人工标注的段落级关系抽取数据集。其中,DocRED 中超过 40% 的关系事实只能从多个句子中抽取,因此需要模型具备较强的综合理解文章中信息的能力,尤其是跨句抽取关系的能力。
论文中在 DocRED 数据集上使用当前最新的关系抽取方法,并对这些方法进行评测,当前方法均难以取得较好的效果,说明段落级关系抽取是一个值得深入研究的方向。
3.5 小结
本节从关系抽取的几个主要挑战:小样本,远程监督数据质量难保证,实体关系联合抽取以及文档级关系抽取出发,进行了相关技术方法的介绍。可以看出,相对来说,远程监督和实体关系联合抽取的研究方向吸引了更多的研究,两者在落地上也的确得到了很好的效果。但在小样本和文档级关系抽取问题在实际应用中也越来越凸显其重要性。特别的,越来越多的实际抽取任务是以整篇文档作为任务的输入,而这方面的研究却鲜有出现。

新的挑战
4.1 文档级信息抽取难题
在实际项目中,除了从句子和段落中进行实体和关系抽取之外,我们还面临从文档中进行信息抽取的新挑战。下面两图是保险合同相关的 pdf 文档的截图。在此类文档的处理上,我们面对两个任务:
(1)文档结构抽取
在很多垂直行业中,如例图所示的半结构化文档大量存在。如何很好的按照文档内容本身的层次化结构进行数据解析,进而针对其层级结构来归纳整理知识图谱 schema 是当下面临的新的巨大挑战。行业文档的格式多样,有 pdf,word,txt 等多种格式,pdf 格式中又分为标准 pdf,可搜索 pdf 和扫描版 pdf,word 文档的版本也是不尽相同。
文档内部的格式更是千变万化,比如有单栏的,双栏的,横版的,竖版的(较少),标题明显的,标题不明显的,有些 segment 如标题是有价值的,有些 segment 如附注是相对价值小的等等。当然,除此之外,还面临其中嵌入大量的表格、图片等信息的识别混淆等各类问题。
(2)给定schema的信息抽取
在知识图谱 schema 给定的前提下,从此类文档中进行特定信息的抽取,比如抽取保险的投保年龄。由于文档格式和行业表述的多样性以及文档内的交叉引用,使得从文档中直接抽取此类信息变得十分困难,比如第一份文档中的“投保范围”对应投保年龄,第二份文档中的“投保年龄”的真实内容引用了文档 10.1 节的内容。这些需要文档级的语义理解能力和逻辑推理能力,才能很好的进行此类信息抽取。


4.2 前沿研究
面对文档级信息抽取的挑战,我们发现新近出现的两类技术有可能进行整合最终给出文档级信息抽取的一个解决方案。下面分别对其进行简介:
4.2.1 Document AI
面对前述文档级信息抽取任务,首先需要考虑的是此类文档的数据解析问题,即如何将文档中的数据按照其原有的结构进行抽取。其中涉及多源文档读取,segment/paragraph 判别,segment/paragraph 之间关系判别等多种任务。显然,此类文档的视觉信息(Layout information)对于数据解析是至关重要的。
Document Intelligentce(也称 Document AI)是一个专门分析文档 Layout 信息和内部 structure 的研究领域 [69],其旨在将文档或图片化的文档分解为独立的 region(Phisical Layout),并结构出 region 的角色(如标题或者段落)和相互关系(Logical Structure),如标题与子标题关系,标题与内容关系。因此,Document AI 领域的模型能用来解决前述文档数据结构化抽取的难题。

但现有较为先进的 Document AI 模型,如 LayOut(见下图)[70] 等,主要用于处理票据内容的结构化识别。最为前沿的数据集是 DocBank [71],其是根据 arxiv 网站大量的论文 pdf 文档与其 latex 代码之间的对应关系而自动化构建出的 Document AI 训练数据,但其仅对论文中的 region 进行识别,如识别 Abstract, Introduction, caption, table 等内容,但缺少对 region 之间的 logical structure 的识别,而 region 的 logical structure 识别,对于前述文档的信息结构化是至关重要的。
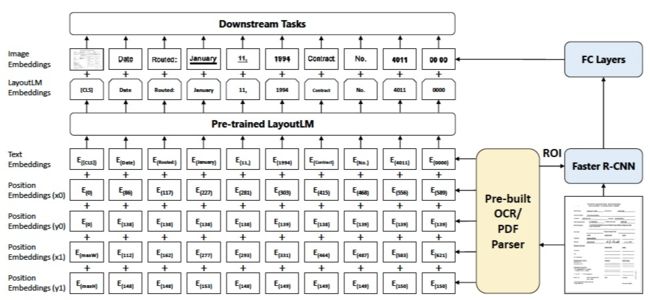
因此,在此方面的研究上,无论是大规模数据集构建还是综合 Physical Layout 和 Logical Structure 的联合抽取模型,相关文献目前都还是鲜有出现,亟需得到更多的关注和深入的研究。
4.2.2 长结构化语言模型
只有在文档的 segment 的表示中融合文档的整体信息,才能做好以文档基础的信息抽取任务。因此,在前述文档得到有效结构化抽取的前提下,如何编码和表示此类结构化数据的宏观和局部信息,也我们面临的第二大挑战。
最近出现的用于编码长句子(1w 字符- 10w 字符级别)的语言模型或许能有效解决上述挑战。具体的,ETC 模型 [72](见下图)利用 Global-local 的 Attention 机制实现了对于长且结构化语句的预训练表示,并在基于网页的层次结构数据的关键短语抽取上验证了其有效性。但是 ETC [72] 在多层级结构的语句的编码上仍然没有得到很好的设计,而且 Global-local 的稀疏 Attention 机制也面临信息损失的缺陷。
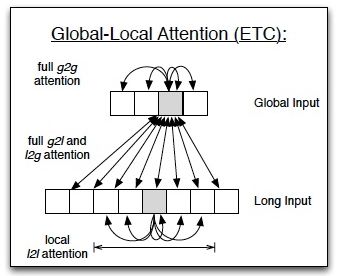
因此,如何基于前述文档结构,在最近出现的长句子语言模型上进行新的架构设计,使得语言模型能更加有效的编码文档的结构化信息和文本信息,同样亟需得到更多的关注和深入研究。
4.3 小结
本节介绍了我们在实际业务中面临的文档级信息抽取的新挑战,同时作为潜在的解决方案,本节也介绍了 Document AI 和 长句子语言模型两个技术模块。总结来看,Document AI 和 语言模型都无法直接适配当下的抽取任务,面向前述文档级信息抽取的新挑战,目前还没有一项成体系的解决方案,因此,此研究方向值得更多的研究人员和工程同行的关注和研究。

总结和展望
本文围绕行业知识图谱构建,对 schema 构建、实体识别和关系抽取相关技术和最新进展进行了介绍和分析。同时介绍了我们遇到的文档级信息抽取的新挑战,并分析讨论了 Document AI 和长结构化文档语言模型在此新挑战上的前沿技术进展。
随着知识图谱作为认知底层的不断发展和完善,应用领域也从互联网渗透进各类垂直行业,基于各行业知识的高效图谱构建将会是知识图谱应用到 ToB 市场的关键。从我们的角度看,行业知识图谱构建未来有以下几个趋势:
schema 构建自动化:行业知识图谱构建领域会发展出一套有效的 schema 构建相关的标准和规范,从而为 schema 自动构建算法提供明晰的优化迭代目标和合理的架构设计参考。随着 nlp 领域的快速蓬勃发展,schema 构建所涉及的信息抽取和抽象整合的能力短板也会得到很大提升。因此,行业图谱 scema 构建中的人机投入比会从 7:3 不断发展到 5:5,3:7 甚至完全实现自动 schema 构建。
信息抽取的统一性和低资源化:信息抽取方案,会越来越偏向信息的综合抽取,统一涵盖实体、关系、事件等综合信息,这必将给算法模型架构设计和数据工程链路建设带来巨大变化。同时,除大规模语言模型的不断发展外,隐式数据资源生成和显式行业先验知识资源的融入技术也将不断发展成熟,这些都会推进低资源化的信息抽取模型将成为主流解决方案。
从句子级、段落级到文档级:以其数据的大规模性、知识的结构性和宏观性以及内容的多模态性,文档级信息抽取必将得到越来越多的研究,从而使得以大规模行业结构化甚至无结构化文档为输入,直接输出图谱化行业知识的端到端的图谱构建链路成为未来的流行。
最后,希望本篇进展研究可以对读者的研究工作带来一定的启发和帮助,同时也感谢各位读者的耐心研读,本文若有纰漏或不妥之处,请不吝赐教。
附注:本文中和算法模型相关的架构图和公式均来自原论文,其他图片由本文作者提供。
参考文献
[1] Han, Hao Zhu, Pengfei Yu, ZiyunWang, Yuan Yao, Zhiyuan Liu, and Maosong Sun. 2018d. Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. In Proceedings of EMNLP, pages 4803–4809.
[2] Tianyu Gao, Xu Han, Hao Zhu, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. 2019. FewRel 2.0: Towards more challenging few-shot relation classification. In Proceedings of EMNLP-IJCNLP, pages 6251–6256.
[3] https://github.com/gabrielStanovsky/oie-benchmark
[4]《知识图谱: 方法,实践与应用》,王昊奋 / 漆桂林 / 陈华钧 主编,电子工业出版社, 2019
[5] Yates, A.; Banko, M.; Broadhead, M.; Cafarella, M.; Etzioni,O.; and Soderland, S. 2007. Textrunner: Open information extraction on the web. In Proceedings of Human Language Technologies: The Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), 25–26.
[6] Diego Marcheggiani and Ivan Titov. 2016. Discretestate variational autoencoders for joint discovery and factorization of relations. Transactions of ACL.
[7] Elsahar, H., Demidova, E., Gottschalk, S., Gravier, C., & Laforest, F. (2017, May). Unsupervised open relation extraction. In European Semantic Web Conference (pp. 12-16). Springer, Cham.
[8] Wu, R., Yao, Y., Han, X., Xie, R., Liu, Z., Lin, F., ... & Sun, M. (2019, November). Open relation extraction: Relational knowledge transfer from supervised data to unsupervised data. In EMNLP-IJCNLP (pp. 219-228).
[9] Stanovsky, G., Michael, J., Zettlemoyer, L., & Dagan, I. (2018, June). Supervised open information extraction. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) (pp. 885-895).
[10] Zhan, J., & Zhao, H. (2020, April). Span model for open information extraction on accurate corpus. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 05, pp. 9523-9530).
[11] Cui, L., Wei, F., & Zhou, M. (2018). Neural open information extraction. arXiv preprint arXiv:1805.04270.
[12] Sameer Pradhan, Mitchell P. Marcus, Martha Palmer, Lance A. Ramshaw, Ralph M. Weischedel, and Nianwen Xue, editors. 2011. Proceedings of the Fifteenth Conference on Computational Natural Language Learning: Shared Task, CoNLL 2011, Portland, Oregon, USA, June 23-24, 2011. ACL.
[13] Gina-Anne Levow. 2006. The third international Chinese language processing bakeoff: Word segmentation and named entity recognition. In Proceedings of the Fifth SIGHANWorkshop on Chinese Language Processing, pages 108–117, Sydney, Australia. Association for Computational Linguistics.
[14] Nanyun Peng and Mark Dredze. 2015. Named entity recognition for Chinese social media with jointly trained embeddings. In EMNLP. pages 548–554.
[15] Erik F. Tjong Kim Sang and Fien De Meulder. 2003. Introduction to the conll-2003 shared task: Language-independent named entity recognition. In Proceedings of the Seventh Conference on Natural Language Learning, CoNLL 2003, Held in cooperation with HLT-NAACL 2003, Edmonton, Canada, May 31 - June 1, 2003, pages 142–147.
[16] George R Doddington, Alexis Mitchell, Mark A Przybocki, Stephanie M Strassel Lance A Ramshaw, and Ralph M Weischedel. 2005. The automatic content extraction (ace) program-tasks, data, and evaluation. In LREC, 2:1.
[17] Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, Hwee Tou Ng, Anders Bj¨orkelund, Olga Uryupina, Yuchen Zhang, and Zhi Zhong. 2013. Towards robust linguistic analysis using OntoNotes. In Proceedings of the Seventeenth Conference on Computational Natural Language Learning, pages 143–152, Sofia, Bulgaria. Association for Computational Linguistics.
[18] 阮彤, 王梦婕, 王昊奋, & 胡芳槐. (2016). 垂直知识图谱的构建与应用研究. 知识管理论坛(3).
[19] Wu, T.; Qi, G.; Li, C.; Wang, M. A Survey of Techniques for Constructing Chinese Knowledge Graphs and Their Applications. Sustainability 2018, 10, 3245.
[20] Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). Natural language processing (almost) from scratch. Journal of machine learning research, 12(ARTICLE), 2493-2537.
[21] Huang, Z., Xu, W., & Yu, K. (2015). Bidirectional LSTM-CRF models for sequence tagging. arXiv preprint arXiv:1508.01991.
[22] Strubell, E., Verga, P., Belanger, D., & McCallum, A. (2017). Fast and accurate entity recognition with iterated dilated convolutions. arXiv preprint arXiv:1702.02098.
[23] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[24] Zhang, Y., & Yang, J. (2018). Chinese ner using lattice lstm. arXiv preprint arXiv:1805.02023.
[25] Gui, T., Ma, R., Zhang, Q., Zhao, L., Jiang, Y. G., & Huang, X. (2019, August). CNN-Based Chinese NER with Lexicon Rethinking. In IJCAI (pp. 4982-4988).
[26] Li, X., Yan, H., Qiu, X., & Huang, X. (2020). FLAT: Chinese NER Using Flat-Lattice Transformer. arXiv preprint arXiv:2004.11795.
[27] Li, X., Feng, J., Meng, Y., Han, Q., Wu, F., & Li, J. (2019). A unified mrc framework for named entity recognition. arXiv preprint arXiv:1910.11476.
[28] Yuchen Lin, B., Lee, D. H., Shen, M., Moreno, R., Huang, X., Shiralkar, P., & Ren, X. (2020). TriggerNER: Learning with Entity Triggers as Explanations for Named Entity Recognition. arXiv, arXiv-2004.
[29] Zhang, X., Jiang, Y., Peng, H., Tu, K., & Goldwasser, D. (2017). Semi-supervised structured prediction with neural crf autoencoder. Association for Computational Linguistics (ACL).
[30] Chen, M., Tang, Q., Livescu, K., & Gimpel, K. (2019). Variational sequential labelers for semi-supervised learning. arXiv preprint arXiv:1906.09535.
[31] Chen, J., Wang, Z., Tian, R., Yang, Z., & Yang, D. (2020). Local Additivity Based Data Augmentation for Semi-supervised NER. arXiv preprint arXiv:2010.01677.
[32] Lakshmi Narayan, P. (2019). Exploration of Noise Strategies in Semi-supervised Named Entity Classification.
[33] Alejandro Metke-Jimenez and Sarvnaz Karimi. 2015. Concept extraction to identify adverse drug reactions in medical forums: A comparison of algorithms. CoRR abs/1504.06936.
[34] Xiang Dai, Sarvnaz Karimi, Ben Hachey, Cécile Paris. An Effective Transition-based Model for Discontinuous NER. ACL 2020: 5860-5870
[35] Wei Lu and Dan Roth. 2015. Joint mention extraction and classification with mention hypergraphs. In Conference on Empirical Methods in Natural Language Processing, pages 857–867, Lisbon, Portugal.
[36] Walker, C., Strassel, S., Medero, J., and Maeda, K. 2005. ACE 2005 multilingual training corpus-linguistic data consortium.
[37] Szpakowicz, S. 2009. Semeval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals. In Proceedings of the Workshop on Semantic Evaluations: Recent Achievements and Future Directions, pages 94–99. Association for Computational Linguistics.
[38] Zhang, Yuhao and Zhong, Victor and Chen, Danqi and Angeli, Gabor and Manning, Christopher D. 2017. Position-aware Attention and Supervised Data Improve Slot Filling. In Proceedings of EMNLP. Pages 35-45.
[39] Riedel, S., Yao, L., and McCallum, A. 2010. Modeling relations and their mentions without labeled text. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 148-163. Springer.
[40] Yuan Yao, Deming Ye, Peng Li, Xu Han, Yankai Lin, Zhenghao Liu, Zhiyuan Liu, Lixin Huang, Jie Zhou, and Maosong Sun. 2019. DocRED: A large-scale document-level relation extraction dataset. In Proceedings of ACL, pages 764–777.
[41] Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via convolutional deep neural network. In Proceedings of COLING, pages 2335–2344.
[42] Linlin Wang, Zhu Cao, Gerard De Melo, and Zhiyuan Liu. 2016. Relation classification via multi-level attention cnns. In Proceedings of ACL, pages 1298–1307.
[43] Dongxu Zhang and Dong Wang. 2015. Relation classification via recurrent neural network. arXiv preprint arXiv:1508.01006.
[44] Xu, Y., Mou, L., Li, G., Chen, Y., Peng, H., and Jin, Z. 2015. Classifying relations via long short term memory networks along shortest dependency paths. In proceedings of EMNLP, pages 1785–1794.
[45] Shanchan Wu and Yifan He. 2019. Enriching pre-trained language model with entity information for relation classification.
[46] Zhao, Y., Wan, H., Gao, J., and Lin, Y. 2019. Improving relation classification by entity pair graph. In Asian Conference on Machine Learning, pages 1156–1171.
[47] Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky. 2009. Distant supervision for relation extraction without labeled data. In Proceedings of ACL-IJCNLP, pages 1003–1011.
[48] Mihai Surdeanu, Julie Tibshirani, Ramesh Nallapati, and Christopher D Manning. 2012. Multi-instance multi-label learning for relation extraction. In Proceedings of EMNLP, pages 455–465.
[49] Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. 2015. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of EMNLP, pages 1753–1762.
[50] Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. 2016. Neural relation extraction with selective attention over instances. In Proceedings of ACL, pages 2124–2133.
[51] Yuhao Zhang, Peng Qi, and Christopher D. Manning. 2018. Graph convolution over pruned dependency trees improves relation extraction. In Proceedings of EMNLP, pages 2205–2215.
[52] Guoliang Ji, Kang Liu, Shizhu He, Jun Zhao, et al. 2017. Distant supervision for relation extraction with sentence-level attention and entity descriptions. In AAAI, pages 3060–3066.
[53] Bordes A, Usunier N, Garcia-Duran A, et al. 2013. Translating embeddings for modeling multi-relational data. Advances in neural information processing systems. pages 2787-2795.
[54] Xu Han, Pengfei Yu, Zhiyuan Liu, Maosong Sun, and Peng Li. 2018. Hierarchical relation extraction with coarse-to-fine grained attention. In Proceedings of EMNLP, pages 2236–2245.
[55] Ningyu Zhang, Shumin Deng, Zhanlin Sun, Guanying Wang, Xi Chen, Wei Zhang, and Huajun Chen. 2019. Long-tail relation extraction via knowledge graph embeddings and graph convolution networks. In Proceedings of NAACL-HLT, pages 3016–3025.
[56] Qin, P., Xu, W., and Wang, W. Y. 2018b. Robust distant supervision relation extraction via deep reinforcement learning. arXiv preprint arXiv:1805.09927.
[57] Xiangrong Zeng, Shizhu He, Kang Liu, and Jun Zhao. 2018. Large scaled relation extraction with reinforcement learning. In Proceedings of AAAI, pages 5658–5665.
[58] Jun Feng, Minlie Huang, Li Zhao, Yang Yang, and Xiaoyan Zhu. 2018. Reinforcement learning for relation classification from noisy data. In Proceedings of AAAI, pages 5779–5786.
[59] Yi Wu, David Bamman, and Stuart Russell. 2017. Adversarial training for relation extraction. In Proceeding of EMNLP, pages 1778–1783.
[60] Pengda Qin, Weiran Xu, William Yang Wang. 2018. DSGAN: Generative Adversarial Training for Distant Supervision Relation Extraction. In Proceeding of ACL, pages 496–505.
[61] Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, and Tom Kwiatkowski. 2019. Matching the blanks: Distributional similarity for relation learning. In Proceedings of ACL, pages 2895–2905.
[62] Meng Qu, Tianyu Gao, Louis-Pascal Xhonneux, Jian Tang. 2020. Few-shot Relation Extraction via Bayesian Meta-learning on Task Graphs. In Proceedings of ICML.
[63] Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao,Peng Zhou, Bo Xu. 2017. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1227–1236.
[64] Wei, Zhepei and Su, Jianlin and Wang, Yue and Tian, Yuan and Chang, Yi. 2020 A Novel Cascade Binary Tagging Framework for Relational Triple Extraction}. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics}, pages 1476—1488.
[65] Luan, Y., Wadden, D., He, L., Shah, A., Ostendorf, M., & Hajishirzi, H. (2019). A general framework for information extraction using dynamic span graphs. arXiv preprint arXiv:1904.03296.
[66] Wadden, D., Wennberg, U., Luan, Y., & Hajishirzi, H. (2019). Entity, relation, and event extraction with contextualized span representations. arXiv preprint arXiv:1909.03546.
[67] Sahu, S. K., et al. 2019. Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: 4309–4316.
[68]mLiu, B., Gao, H., Qi, G., Duan, S., Wu, T., & Wang, M. (2019, April). Adversarial Discriminative Denoising for Distant Supervision Relation Extraction. In International Conference on Database Systems for Advanced Applications (pp. 282-286). Springer, Cham.
[69] Namboodiri, A. M., & Jain, A. K. (2007). Document structure and layout analysis. In Digital Document Processing (pp. 29-48). Springer, London.
[70] Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., & Zhou, M. (2020, August). Layoutlm: Pre-training of text and layout for document image understanding. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 1192-1200).
[71]mLi, M., Xu, Y., Cui, L., Huang, S., Wei, F., Li, Z., & Zhou, M. (2020). DocBank: A Benchmark Dataset for Document Layout Analysis. arXiv preprint arXiv:2006.01038.
[72] Ainslie, J., Ontanon, S., Alberti, C., Cvicek, V., Fisher, Z., Pham, P., ... & Yang, L. (2020, November). ETC: Encoding Long and Structured Inputs in Transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 268-284).
[73] Tang, J., Lu, Y., Lin, H., Han, X., Sun, L., Xiao, X., & Wu, H. (2020, November). Syntactic and Semantic-driven Learning for Open Information Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings (pp. 782-792).
[74] https://paperswithcode.com/task/named-entity-recognition-ner
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

