分类-------决策树
决策树是一种基本的分类和回归方法。它可以被认为是if-then规则的一个集合,也可以被认为是定义在特征空间与类空间上的条件概率分布。
分类的决策树模型是一种描述对实例进行分类的树形结构模型。决策树由节点(Node)和有向边(Directed Edge)组成。开始构建根节点时,会将所有的训练数据都作为根节点的备选节点,从所有的训练数据中选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。如果这些子集已经能够被基本正确的分类,则构建叶子节点,并将这些子集分到所对应的叶子节点中去;如果还有子集不能够被基本正确的分类,则对这些子集选择新的最优特征,继续对其进行分割,构建相应的节点。如此递归地进行下去,直至所有训练数据子集都被正确分类,或者没有合适的特征位置。最后每个子集都会被分到叶子节点上,即所有的子集都会有明确的分类。此时,一棵决策树就生成了。
信息熵:是代表随机变量不确定性的一个度量,一个系统越是有序,信息熵就越低;反之,一个系统越混乱,它的信息熵就越高。所以,信息熵可以被认为是系统有序化程度的一个度量。熵只依赖于X的分布,与X的取值无关。
设X是一个取有限值的离散随机变量,其概率分布为:
P(X=x
) = p
随机变量熵的定义为: H(X) = -
p
p
信息熵可以用来判断对方是否具有分类能力,从而应用到特征选取。
信息增益:表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
在决策树的学习中,信息增益就等价于训练数据集中类与特征的互信息。
读取数据:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv(r"D:\Develop\Jupyter\网课\机器学习\data\Social_Network_Ads.csv")
data.head()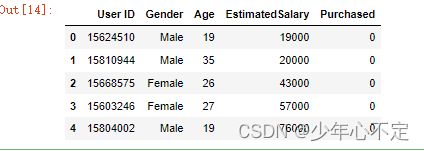
划分数据集:
X = data.iloc[:,[2,3]]
y = data.iloc[:,4]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test= train_test_split(X,y,test_size=0.20,random_state=155)
#数据集归一化
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)模型训练:
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(criterion = 'entropy', max_depth = 3, min_samples_leaf = 3, random_state = 0)
classifier.fit(X_train, y_train)
#模型评估----准确率(score)
classifier.score(X_test,y_test)模型评估(混淆矩阵):
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)可视化:
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Decision Tree Classification (Training set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()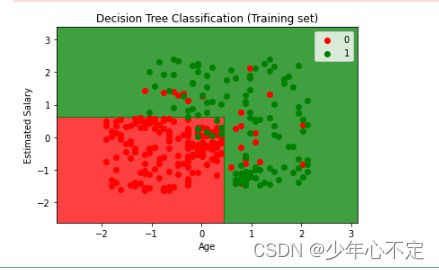
决策树可视化(树):
from sklearn.tree import export_graphviz
export_graphviz(classifier, feature_names = ['Age','EstimatedSalary'], out_file ='tree.dot')
!type tree.dot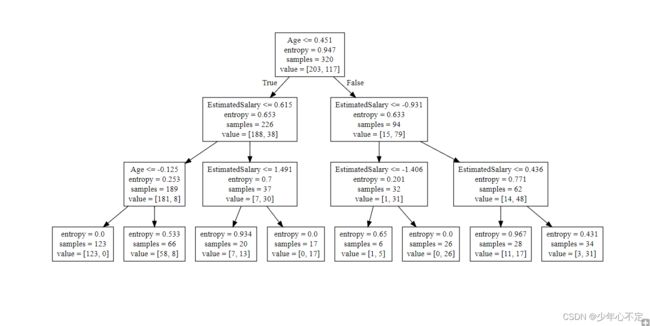
可视化途径:Viz.js