【深度学习】pix2pix GAN理论及代码实现与理解
灵感:最近也是在看关于GAN方面的代码,也是看到了很多篇博客,都写的挺好的,让我醍醐灌顶,理解了GAN的原理以及代码实现。所以写一下来记载一下,最后有其他好文章的链接。
灵感来源:pix2pixGAN理论以及代码实现
目录
1.什么是pix2pix GAN
2.pix2pixGAN生成器的设计
3.pix2pixGAN判别器的设计
4.损失函数
5.代码实现
6.参考文献
1.什么是pix2pix GAN
它实际上就是一个CGAN,条件GAN,不过是改变了一般GAN的辨别器的输出。其他的都是输出一个概率,而pix2pixGAN或者也可以是patchgan,它的最终输出是一个矩阵,每一个块代表一个patch的概率而已。关于patch这一块的知识可以去其他地方补一下,文末也有入口。

图片x作为此cGAN的条件,需要输入到G和D中。G的输入是x(x是需要转换的图片),输出是生成的图片G(x)。D则需要分辨出(x,G(x))和(x,y)
pix2pixGAN主要用于图像之间的转换,又称图像翻译。
2.pix2pixGAN生成器的设计
对于图像翻译任务来说,输入和输出之间会共享很多信息。比如轮廓信息是共享的。如何解决共享问题?需要我们从损失函数的设计当中去思考。
如果使用普通的卷积神经网络,那么会导致每一层都承载保存着所有的信息。这样神经网络很容易出错(容易丢失一些信息)
所以,我们使用UNet模型作为生成器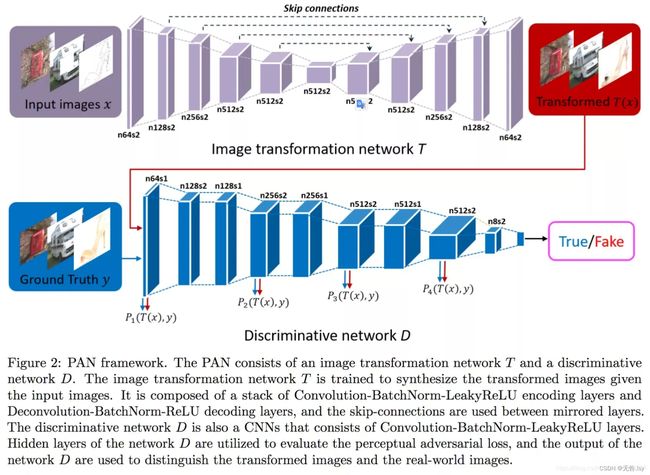
3.pix2pixGAN判别器的设计
D要输入成对的图像。这类似于cGAN,如果G(x)和x是对应的,对于生成器来说希望判别为1;
如果G(x)和x不是对应的,对于生成器来说希望判别器判别为0
pix2pixGAN中的D被论文中被实现为patch_D.所谓patch,是指无论生成的图片有多大,将其切分为多个固定大小的patch输入进D去判断。如上图所示。
这样设计的好处是:D的输入变小,计算量小,训练速度快
4.损失函数
D网络损失函数:输入真实的成对图像希望判定为1;输入生成图像与原图希望判定为0
G网络损失函数:输入生成图像与原图像希望判定为1
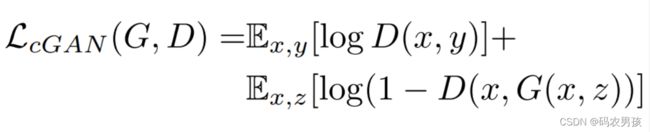
对于图像翻译任务而言,G的输入和输出之间其实共享了很多信息。因而为了保证输入图像和输出图像之间的相似度,还加入了L1loss,公式如下所示:
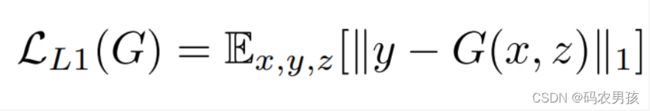
5.代码实现
代码实现的话有官方以及别人的实现,但是我有点不懂。然后看到这个链接的代码才懂。
全部代码在这:pix2pixGAN理论以及代码实现
我作为笔记记录,写一下我觉得关键的代码理解。
for step,(annos,imgs) in enumerate(dataloader):
imgs = imgs.to(device) #imgs 输入的图像
annos = annos.to(device) #标签,真实的应该生成的图片
#定义判别器的损失计算以及优化的过程
d_optimizer.zero_grad()
disc_real_output = dis(annos,imgs) #输入真实成对图片
d_real_loss = loss_fn(disc_real_output,torch.ones_like(disc_real_output,
device=device))
#上面是为了将我们输入的真实图像对都标为1,希望他接近1,因为真实嘛
d_real_loss.backward() #求梯度
gen_output = gen(annos) #通过输入图像生成图片
disc_gen_output = dis(annos,gen_output.detach()) #将我们输入的和生成的图片输入辨别器
d_fack_loss = loss_fn(disc_gen_output,torch.zeros_like(disc_gen_output,
device=device)) #辨别器希望生成的和我们输入的图像最终的判断为0,也就是假的嘛
d_fack_loss.backward()
disc_loss = d_real_loss+d_fack_loss#判别器的损失计算,由两个之和
d_optimizer.step() #梯度更新
#定义生成器的损失计算以及优化的过程
g_optimizer.zero_grad()
disc_gen_out = dis(annos,gen_output) #辨别器辨别输入图像和生成图像的匹配度
gen_loss_crossentropyloss = loss_fn(disc_gen_out,
torch.ones_like(disc_gen_out,
device=device)) #生成器和辨别器相反,他希望生成的图像和输入的图像匹配为真实,也就是造假嘛
gen_l1_loss = torch.mean(torch.abs(gen_output-imgs)) #L1损失
gen_loss = gen_loss_crossentropyloss +LAMBDA*gen_l1_loss
gen_loss.backward() #反向传播
g_optimizer.step() #优化
#累计每一个批次的loss
with torch.no_grad():
D_epoch_loss +=disc_loss.item()
G_epoch_loss +=gen_loss.item()
上面用到的loss_fn是BCE损失。因为我们的辨别器输出值为概率嘛,0到1,所以算得上是二分类,可以使用BCE。
6.参考文献
GAN系列之 pix2pixGAN 网络原理介绍以及论文解读 https://blog.csdn.net/m0_62128864/article/details/124026977
https://blog.csdn.net/m0_62128864/article/details/124026977
一文看懂PatchGAN_明月几时有.的博客-CSDN博客_patchgan最近看到PatchGAN很是好奇原理是什么,发现网上很多介绍的并不清楚.故墙外墙内来回几次,大概是清楚了.PatchGAN其实指的是GAN的判别器,将判别器换成了全卷积网络.这么说并不严谨,PatchGAN和普通GAN判别器是有区别的,普通的GAN判别器是将输入映射成一个实数,即输入样本为真样本的概率.PatchGAN将输入映射为NxN的patch(矩阵)X,XijX_{ij}Xij的值代表...https://blog.csdn.net/weixin_35576881/article/details/88058040
pix2pix算法笔记_AI之路的博客-CSDN博客_pix2pix算法论文:Image-to-Image Translation with Conditional Adversarial Networks论文链接:https://arxiv.org/abs/1611.07004代码链接:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix这篇论文发表在CVPR2017,简称pix2pix,是将GAN应用...https://blog.csdn.net/u014380165/article/details/98453672
Pix2Pix-基于GAN的图像翻译_张雨石的博客-CSDN博客_pix2pix算法语言翻译是大家都知道的应用。但图像作为一种交流媒介,也有很多种表达方式,比如灰度图、彩色图、梯度图甚至人的各种标记等。在这些图像之间的转换称之为图像翻译,是一个图像生成任务。多年来,这些任务都需要用不同的模型去生成。在GAN出现之后,这些任务一下子都可以用同一种框架来解决。这个算法的名称叫做Pix2Pix,基于对抗神经网络实现。https://blog.csdn.net/stdcoutzyx/article/details/78820728