Mask-RCNN论文阅读笔记
1. Introduction
实例分割的挑战性在于它需要正确地检测出图像中物体的位置的同时对每一个实例精确地分割。因此这是一个结合了CV领域中目标检测(分类并且定位图片中的物体)和实例分割(将图像中每一个像素点分类,且同一个实例中的像素点是一类)的任务。
Mask-RCNN对Faster-RCNN做了扩展,增加了一条分支用于为每一个roi预测分割mask掩模。这个mask分支就是应用在每一个roi上的小型FCN网络,这个mask分支在像素级别上预测出了一个分割mask。这条新增的分支只会增加很少的计算量。
直觉上来说Mask-RCNN只是对Faster-RCNN的一个扩展,然而恰当地建立这个mask分支对于得到好的结果至关重要。更重要的是,Faster-RCNN并没有对网络的输入和输出设计像素点到像素点的对齐。这也是为什么ROIpool只为实例分割提供了粗糙的空间特征。为了解决这种对齐错位,我们提出了一个简单的,无量化的层(quantization-free layer),名叫RoIAlign。它能够忠实地保留确切的空间位置信息。

RoiAlign将mask的准确率从10%提升到了50%,提供了严格的位置度量。其次,我们发现将mask和分类预测解耦很重要:我们为每一个类别独立地预测一个二值化mask,而不是在各个类别中预测,并使用网络的RoI的分类分支预测类别。作为对比,FCN们通常表现出每一个像素点的多类别,这将分割和分类耦合在了一起,这在实例分割任务上表现得不好。
通过在COCO数据集上的人体关键点检测任务,我们展示了此模型的通用化能力。通过将每一个关键点看作是一个one-hot编码的二值mask,经过很小的改动,该模型能被应用在实例化的姿态检测中,打败了2016COCO关键点竞赛的冠军,在GPU上速度为5fps。
2. Related Work
实例分割:许多实例分割的方法基于segment proposal。早期的方法借助于自底向上的分割。DeepMask及其后续的工作学习着提取出分割候选,之后由Fast-RCNN对其分类。在这些方法中,分割precedes识别,这样子很慢且不准确。类似的方法还有先从目标候选框很脏的到候选的分割,之后再分类。而我们的方法基于平行同步的mask预测和类别预测,这种方式简单且灵活。
近期Li将分割候选和目标检测结合,命名为FCIS(fully convolutional instance segmentation),它的想法是通过全卷积网络预测一系列的位置敏感输出通道,这些通道同时还标出了物体的类别,位置框,mask,这样的方法很快速。但是这个模型在有重叠的实例上会出错,输出虚假的边界。这表明了分割实例的基础难点的挑战性。

3. Mask R-CNN
Mask-RCNN理论上很简单,就是给Faster-RCNN增加了一个分支,用于输出目标的mask。但是mask的输出与类别和框的输出的区别在于,它需要提取出目标更加细致的空间信息。
此模型是独立于分类和定位来预测出二值mask,这与前面提到的其他方法不同,他们是分类依赖于mask的预测。
训练时定义每个roi上的损失函数为L = Lcls + Lbox + Lmask。前面的两个loss与FRCNN中的相同。mask分支的维度是每个roi的一个输出为Km^2,这编码了K个分辨率为m * m的二值mask,代表了K个类。此处用单像素点的sigmoid并定义Lmask为平均二值交叉熵损失。对于每一个与真值第K类相关的RoI,Lmask只由第K个mask定义(其他mask的输出不贡献loss)。
我们定义的Lmask使得网络在类内没有竞争的情况下为每一个类生成mask。我们希望专门的分类分支预测类别标签,这些类别标签将用于选择输出的mask。这样就解耦了mask和class的预测。这与常规的将FCN用在分割的方式不同,因为它是针对每个像素点使用softmax和多项式交叉熵损失。这种情况下,不同类间的mask会产生竞争;而我们的方法使用的像素点sigmoid和二值损失则不会。我们通过实验证明这个方程是好的实例分割结果的关键。
Mask Representation:一个mask编码了一个输出物体的空间布局。因此不同于类别标签和框offset,这两个最终会由全连接层得到一个短的输出向量,而提取mask的空间结构很自然地落到了由卷积得到的像素与像素之间的关联性上。
特别地,我们使用FCN从每一个roi上预测m * m大小的mask,这使得mask分支的每个层都保持了m * m的物体空间布局,而不是衰减成为了缺乏空间维度的向量。与前人的使用fc层预测mask的方法不同,我们的全卷积表征方式需要的参数量更少,并且更准确。
这种像素点到像素点的表现就要求我们的roi特征图良好地对齐,忠实地保留每个像素的空间关联性(因为roi本身也是小的特征图)。这启发了我们发明了如下的RoIAlign层,它在mask的预测中起到了关键作用。
RoIAlign:ROIpool是针对每个roi提取小的特征图(例如7*7)的标准方法。RoIPool首先将一个浮点数的RoI分割量化为特征图的离散形式,这个量化后的RoI被细分为多个小格子,最终每个小格子上的特征的值被聚合(通常使用最大值池化)。例如上述的量化可以通过计算[x/16]来应用在连续的坐标x上,其中16为特征图的stride,[.]操作为取约等于;与此相似的量化方式可以用在7*7的格子上。这种方法会导致roi和特征图之间的不对齐性。尽管这对于鲁棒性很好的分类没什么影响,但是对于预测要精确到像素点的mask来说就有很大的负面影响了。
为了解决这个问题,我们提出RoIAlign层来消除上述粗糙的量化结果,将提取的特征与输入恰当地对齐。方法:我们避免对roi的边界或者每个小格子进行量化(例如我们使用x/16取代[x/16])。在每个RoI格子上我们使用双线性插值,由四个常规的采样位置的值来计算输入特征的确切值,之后将结果集成(最大值或均值)。如图3.

我们注意到只要不做近似量化,结果就不在对确切的采样位置或者采样个数敏感。
Network Architecture:
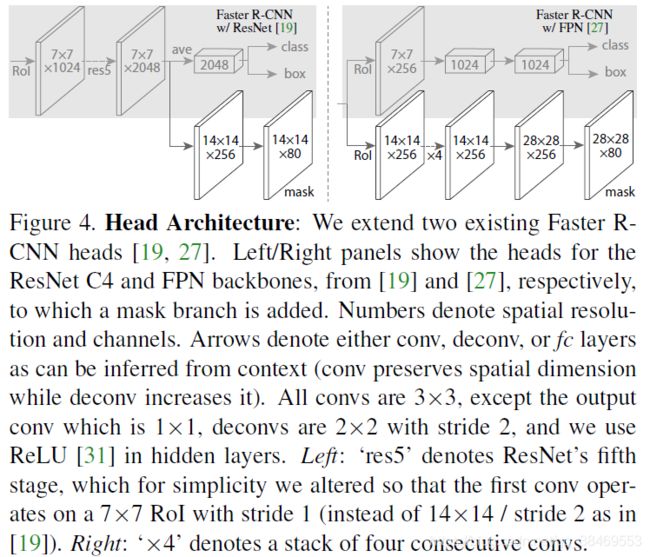
Implementation Details:训练阶段,mask的loss Lmask只定义在正样本的roi上,roi与GT box的IoU大于0.5则为正样本,否则为负样本。使用图像中心化的训练方式:图片被缩放到短边为800的尺度。每一个mini-batch每一个GPU为2张图,每张图采样得到N个RoI,正负RoI比例为1:3。N is 64 for the C4 backbone (as in [12, 36]) and 512 for FPN (as in [27]). We train on 8 GPUs (so effective minibatch size is 16) for 160k iterations, with a learning rate of 0.02 which is decreased by 10 at the 120k iteration. We use a weight decay of 0.0001 and momentum of 0.9. With ResNeXt [45], we train with 1 image per GPU and the same number of iterations, with a starting learning rate of 0.01.
RPN anchor为3种尺度3中宽高比,且RPN单独训练,不与MRCNN共享特征(除了特殊说明外)。本文RPN与MRCNN共用同样的主干结构backbone。
预测阶段:At test time, the proposal number is 300 for the C4 backbone (as in [36]) and 1000 for FPN。在这些建议框上预测框坐标且进行NMS。接着将mask预测分支应用于得分最高的100个预测框上。尽管这与训练阶段的同步并行计算方式不同,但是此方法加速了预测过程并且提高了准确率(是因为使用了更少且更准确的RoI)。mask分支能在每一个ROI上预测K个mask,但是只使用第k个mask,这里k代表了由分类分支预测的第k类。m*m大小的浮点数mask输出被resize到ROI的大小,并且以0.5的阈值做二值化处理。由于我们只计算top100个box的mask,因此MRCNN只在FRCNN的基础上增加了一点小的开销。