Pix2Pix(2017)+CycleGAN+Pix2PixHD
GAN
常规的深度学习任务如图像分类、目标检测以及语义分割或者实例分割,这些任务的结果都可以归结为预测。图像分类是预测单一的类别,目标检测是预测Bbox和类别,语义分割或者实例分割是预测每个像素的类别。而GAN是生成一个新的东西如一张图片。
图像到图像的转换是一个图像合成任务,它要求生成一个对给定图像受控修改后的新图像。
图像到图像的转换是一种视觉图形问题,其目的是使用对齐图像对的训练集,学习输入图像和输出图像之间的映射。
GAN通过对抗的方式,去学习数据分布的生成式模型。GAN是无监督的过程,能够捕捉数据集的分布,以便于可以从随机噪声中生成同样分布的数据。
一般来说,GAN中包含两种类型的网络G和D。其中为Generator,它的作用是生成图片,即在输入一个随机编码(random code)z之后,它将输出一幅由神经网络自动生成的、假的图片G(z)。另一个网络D为Discriminator是用来判断的,它接受G输出的图像作为输入,然后判断这幅图像的真假,真的输出为1,假的输出为0。

在两个网络相互博弈的过程中,两个网络的能力都越来越高:G生成的图片越来越像真的图片,D也越来越会判断图片的真假。到了这一步,丢掉D不要了,把G拿来用作图片生成器。即在最大化D的能力的前提下,最小化D对G的判断能力,是一个最小最大值问题。它学习的目标是:

为了增强D的能力,分别考虑输入真的图像和假的图像的情况,第一项的D(G(z))处理的是假图像G(z),这时候评分D(G(z))要尽量的低;第二项处理的是真图像x,这时候评分要高。
GAN的局限性:
- 没有用户的控制能力
在传统的GAN里,输入一个随机噪声,就会输出一幅随机图像。要想输出的图像是我们想要的那种图像,使输出和输入是对应的、有关联的。比如输入一只猫的草图,输出同一形态的猫的真图,这里对形态的要求就是一种用户控制。 - 低分辨率(low resolution)和低质量(low quality)问题
尽管GAN生成的图片看起来很不错,但如果放大看,就会发现细节相当模糊。
为了提高GAN的用户控制能力和生成图片的分辨率和质量,分三步:
- Pix2Pix:有条件的使用用户输入,它使用成对的数据进行训练。
- CycleGAN:使用不成对的数据就能训练。
- Pix2PixHD:生成高分辨率、高质量的图像。

Pix2Pix对传统的GAN做的改动:输入用户给的图片,不再输入随机噪声。

该方式下的新问题:怎样建立输入和输出的对应关系。此时G的输出如果是下面这样,D会判断是真图:

如果G的输出是下面这样的,D也会认为是真图,即这样并不能训练出输入和输出对应的网络G,因为是否对应根本不影响D的判断。

为了体现这种对应关系,把G的输入和输出一起作为D的输入,于是优化目标变成这样:

Pix2Pix的核心是有了对应关系,这种网络的应用范围还是比较广泛的。
-
草图变图片

-
灰度图变彩色图

pix2pix必须使用成对的数据进行训练。

但很多情况下成对数据是很难获取到的,比如说,我们想把马变成斑马,现实生活中是不存在对应的真实照片的:

CycleGAN(Cycle-constraint Adversarial Network)就是解决这个问题,这种网络不需要成对的数据,只需要输入数据的一个集合(比如一堆马的照片)和输出数据的一个集合(比如一堆斑马的照片)就可以了。

但是直接使用不成对的数据是不奏效的,网络会直接忽略输入,随机产生输出。所以还得对网络增加限制才行。如果把马变成斑马,然后再变回马,那么最后的马和开始输入的马应该是一样的。
除了把马变成斑马的网络G,还需要一个把斑马变回马的网络F。那么一匹马x用G变成斑马s=G(x),然后再用F把它变回马F(s),得到的马和一开始的马应该是一样的,即x=F(G(x))。

反过来,斑马变马再变回斑马也要满足要求,注意这一步最好不要省略,虽然理论上只用一个条件是可以的,但是现实实现中,有很多因素,比如计算的准备度,优化的问题,应用中都是把所有约束都加上。

同时优化G和F,最后就能得到一个想要的网络G。
CycleGAN成功的原因在于它分离了风格(Style)和内容(content),让神神经网络去自动保持内容而改变风格。
Pix2PixHD 是解决分辨率和图像质量的问题。假如输入一张高分辨率的草图,使用Pix2Pix,结果很差,Pix2PixHD采取金字塔式方法,先输出低分辨率的图片,将之前输出的低分辨率图片作为另一个网络的输入,然后生成分辨率更高的图片。

Pix2Pix
[paper]Image-to-Image Translation with Conditional Adversarial Networks(2018)
[code]pytorch-CycleGAN-and-pix2pix
图像处理的很多问题都是将一张输入的图片转变为一张对应的输出图片,比如灰度图、梯度图、彩色图之间的转换等。通常每一种问题都使用特定的算法,如使用CNN来解决图像转换问题时,要根据每个问题设定一个特定的loss function来让CNN去优化,而一般的方法都是训练CNN去缩小输入跟输出的欧式距离,但这样通常会得到比较模糊的输出。这些方法的本质其实都是从像素到像素的映射。Pix2Pix解决这类问题,通过Pix2Pix完成成对的图像转换,可以得到比价清晰的结果。
Pix2Pix是将GAN应用于有监督的图像到图像翻译的算法,有监督表示训练数据是成对的。
图像到图像翻译(Image-to-Image translation)是GAN很重要的一个应用方向,图像到图像的翻译时基于一张输入图像得到想要的输出图像的过程,可以看做是图像和图像之间的一种映射(mapping),常见的图像修复、超分辨率其实都是图像到图像翻译的例子。还包括从标签到图像的生成、图像边缘到图像的生成等过程。

上面展示了许多有趣的结果,比如分割图->街景图,边缘图->真实图。这个是怎么做到的呢?如果是我们,我们会如何设计这个网络。最直接的想法是,设计一个CNN网络,直接建立输入-输出的映射,就像图像去躁问题一样。可是对于上面的问题,这样做会带来一个问题:生成图像质量不清晰。
如下图所示的分割图->街景图,语义分割图的每个标签比如“汽车”可能对应不同样式、颜色的汽车。那么学习模型学到的会是所有不同汽车的平均,这样会造成模糊。下图第三列就是直接用L1 loss来学习得到的结果,相比于Ground truth,模糊很严重。

这里作者想了一个办法,即加入GAN的Loss去惩罚模型。GAN相比于传统生成式模型可以较好的生成高分辨率图片。思路很简单,在上述直观想法的基础上加入一个判别器,判断输入图片是否是真实样本。模型示意图如下:

上图模型和cGAN有所不同,但它是一个cGAN,只不过输入只有一个,这个输入就是条件信息。原始的cGAN需要输入随机噪声和条件。这里之所以没有输入噪声信息,是因为在实际实验中,如果输入噪声和条件,噪声往往被淹没在条件C当中,所以这里就直接省去了。
Pix2Pix基于GAN实现图像翻译,更准确的讲是基于cGAN(conditional GAN,也叫条件GAN),因为cGAN可以通过添加条件信息来指导图像生成,因此在图像翻译中可以将输入图像作为条件,学习从输入图像到输出图像之间的映射,从而得到指定的输出图像。而其他基于GAN来做图像翻译的,因为GAN算法的生成器是基于一个随机噪声生成图像,难以控制输出,因此基本上都是通过其他约束条件来指导图像生成,而不是利用cGAN,这是Pix2Pix和其他基于GAN做图像翻译的差异。
Pix2Pix是借鉴了cGAN的思想,cGAN在输入G网络的时候不仅会输入噪声,还会输入一个条件(condition),G网络生成的fake images会受到具体的condition的影响。那么如果把一幅图像作为condition,则生成的fake images就与这个condition images有对应关系,从而实现了一个Image-to-Image Translation的过程。

以基于图像边缘生成图像为例,介绍Pix2Pix的工作流程:
- 首先输入图像用y表示,输入图像的边缘图像用x表示,Pix2Pix在训练时需要成对的图像(x和y)。
- x作为生成器G的输入(随机噪声z在图中并未画出,去掉z不会对生成效果有太大影响,但假如将x和z合并在一起最为G的输入,可以得到更多样的输出)得到生成图像G(x)。
- 然后将G(x)和x基于通道维度合并在一起,最后作为判别器D的输入得到预测概率值,该预测概率值表示输入是否是一对真实图像,概率值越接近1表示判别器D越肯定输入是一对真实图像。
- 真实图像y和x也基于通道维度合并在一起,作为判别器D的输入得到概率预测值。因此判别器D的训练目标就是在输入不是一对真实图像(x和G(x))时输出小的概率值(比如最小是0),在输入是一对真实图像(x和y)时输出大的概率值(比如最大值是1)。
- 生成器G的训练目标就是使得生成的G(x)和x作为判别器D的输入时,判别器D输出的概率值尽可能大,这样就相当于成功欺骗了判别器D。

训练大致过程如上图所示,图片x作为此cGAN的条件,需要输入到G和D中。G的输入是{x,z}(其中,x是需要转换的图片,z是随机噪声),输出的是生成的图片G(x,z)。D则需要分辨出{x,G(x,z)}和{x,y}。
Pix2Pix的优化目标包含两个部分:一部分是cGAN的优化目标;另一部分是L1距离,用来约束生成图像和真实图像之间的差异。这部分借鉴了基于GAN做图像翻译的思想,只不过这里用L1而不是L2(L1 loss相比于L2 loss保边缘,L2 loss基于高斯先验,L1 loss基于拉普拉斯先验),目的是减少生成图像的模糊。

cGAN的优化目标如公式1所示,z表示随机噪声,判别器D的优化目标是使得公式1的值越大越好,而生成器G的优化目标是使得公式1的 l o g ( 1 − D ( x , G ( x , z ) ) ) log(1-D(x, G(x,z))) log(1−D(x,G(x,z)))越小越好,这就是公式4中min和max的含义。但是公式1有时候训练容易出现饱和现象,即判别器D很强大,但是生成器G很弱小,导致G基本上训练不起来,因此可以将生成器G的优化目标从最小化 l o g ( 1 − D ( x , G ( x , z ) ) ) log(1-D(x, G(x,z))) log(1−D(x,G(x,z))),修改为最大化 l o g ( D ( x , G ( x , z ) ) ) log(D(x, G(x,z))) log(D(x,G(x,z))),Pix2Pix算法采用修改后的优化目标。

为了测试输入的条件x对于D的影响,也训练了一个普通的GAN,判别器D只用于判别生成的图像是否真实。

L1距离如公式3所示,用来约束生成图像 G ( x , z ) G(x,z) G(x,z)和真实图像y之间的差异。

Pix2Pix对DCGAN的生成器和判别器的结构做了改进。生成器采用U-Net,这是在图像分割领域应用非常广泛的网络结构,能够重分融合特征,而原本GAN中最常用的生成器结构是encoder-decoder类型,二者的对比如图3所示。

U-Net是德国Freiburg大学模式识别和图像处理组提出的一种全卷积结构。和常见的先降采样到低维度,再升采样到原始分辨率的编解码(Encoder-Decoder)结构的网络相比,U-Net的区别是加入skip-connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼(concatenate)在一起,用来保留不同分辨率下像素级的细节信息。U-Net对提升细节的效果非常明显。

Pix2Pix用重建来解决低频成分,用GAN来解决高频成分。使用传统的L1 loss来让生成的图片跟训练的图片尽量相似,用GAN来构建高频部分的细节。
判别器采用马尔可夫性的PatchGAN,使用PatchGAN来判别是否是生成的图片。PatchGAN的思想是,既然GAN只用于构建高频信息,那么就不需要将整张图片输入到判别器中,让判别器对图像的每个大小为NxN的patch做真假判别就可以了。因为不同的patch之间可以认为是相互独立的。Pix2Pix对一张图片切割成不同的NxN大小的patch,判别器对每一个patch做真假判别,将一张图片所有的patch的结果取平均作为最终的判别器输出。PatchGAN对输入图像的每个区域(patch)都输出一个预测概率值,相当于从判断输入是真还是假演变成判断输入的N*N大小区域是真还是假。假设判别器的输入是1x6x256x256,N设置为8,判别器的输出大小是1x1x32x32,其中32x32大小的输出中的每个值都表示输入中对应8x8区域是真实的概率。
具体实现的时候,作者使用的是一个NxN输入的全卷积小网络,最后一层每个像素过sigmoid输出为真的概率,然后用BCEloss计算得到最终loss。这样做的好处是因为输入的维度大大降低,所以参数量少,运算速度也比直接输入一张快,并且可以计算任意大小的图。
GAN loss为LSGAN的最小二乘loss,并使用PatchGAN(进一步保证生成图像的清晰度)。PatchGAN将图像划分成很多个Patch,并对每一个Patch使用判别器进行判别(实际代码实现有更取巧的办法,实际是这样实现的:假设输入一张256x256的图像到判别器,输出的是一个4x4的confidence map,每一个像素值代表当前Patch是真实图像的置信度。感受野就是当前的图像Patch),将所有Patch的loss求平均作为最终的loss。
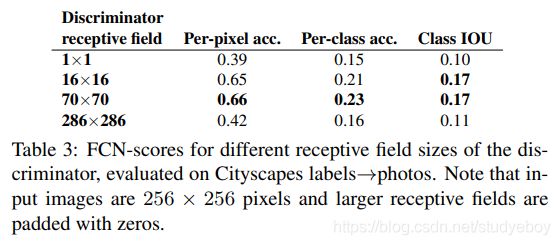
实验结果,Table1是关于不同损失函数的组成效果对比,采用的是基于分割标签得到图像的任务。评价时采用语义分割算法FCN对生成器得到的合成图像做语义分割得到分割图,假如合成图像足够真实,那么分割结果也会更接近真实图像的分割结果,分割结果的评价主要采用语义分割中常用的基于像素点的准确率和IoU等。

Table2是关于不同生成器的效果,主要是encoder-decoder和U-Net的对比。
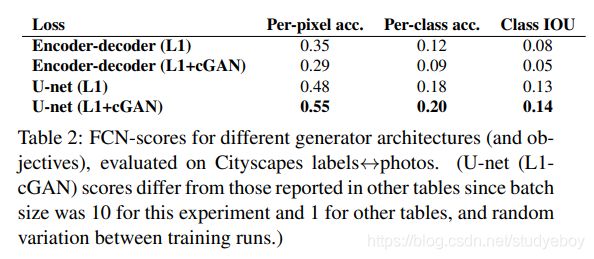
Table3是关于判别器PatchGAN采用不同大小N的实验结果,其中1x1表示一像素点为单位判断真假,显然这样的判断缺少足够的信息,因此效果不好,286x286表示常规的以图像为单位判断真假,这是比较常规的做法,从实验来看效果也一般。中间2行是介于前两者之前的PatchGAN的效果,可以看到基于区域来判断真假效果较好。
Pix2Pix的生成图像,可以基于图像边缘得到图像、基于语义分割的标签得到图像、背景去除、图像修复等。









CycleGAN(2020)
[paper] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
[code]pytorch-CycleGAN-and-pix2pix
CycleGAN本质上和GAN是一样的,是学习数据集中潜在的数据分布。GAN是从随机噪声生成同分布的图片,CycleGAN是在有意义的图上加上学习到的分布从而生成另一个领域的图。CycleGAN假设Image-to-Image的两个领域存在的潜在的联系。
CycleGAN 是一种无需成对示例便可自动进行图像到图像转换的技术。这些模型是采用一批无需关联的来自源域和目标域的图像,以一种无监督的方式训练的。
CycleGAN可以让两个domain的图片互相转化。传统的GAN是单向生成,CycleGAN是互相生成,网络是个环形,所以命名为Cycle。并且输入的两张图片可以是任意的两张图片,即unpaired。

GAN的映射函数很难保证生成图片的有效性,CycleGAN利用cycle consistency来保证生成的图片与输入图片的结构上一致性。
CycleGAN本质上是两个镜像对称的GAN,构成一个环形网络。理解一半的单向GAN就等于理解了整个CycleGAN。


CycleGAN就是一个 A → B A \rightarrow B A→B单向GAN加上一个 B → A B \rightarrow A B→A单向GAN。两个GAN共享两个生成器,然后各自带一个判别器,所以加起来总共有两个判别器和两个生成器。一个单向GAN有两个loss,而CycleGAN加起来总共有四个loss。
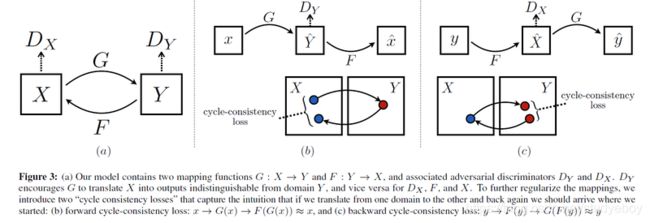

CycleGAN示意图:
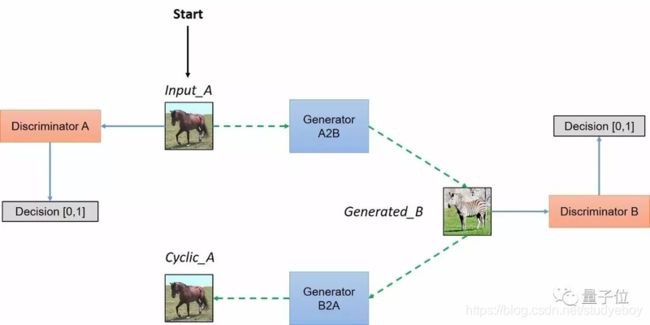
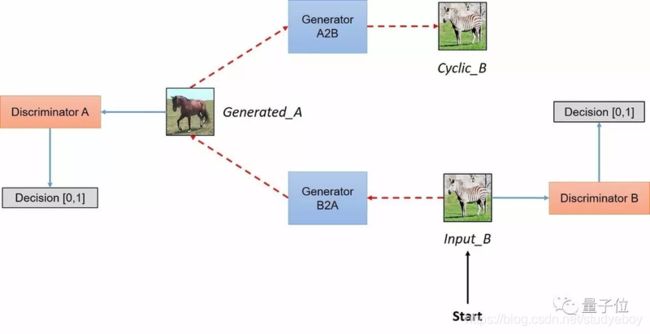
生成器由编码器、转换其和解码器构成。

- 编码:第一步利用卷积神经网络从输入图像中提取特征。将图像压缩成256个64x64的特征向量。
- 转换:通过组合图像的不相近特征,将图像在DA域中的特征向量转换成DB域中的特征向量。作者使用了6层ResNet模块,每个ResNet模块是由两个卷积层构成的神经网络层,能够达到在转换时同时保留原始图像特征的目标。
- 解码:利用反卷积层(Deconvolution)完成从特征向量中还原出低级特征的工作,最后得到生成图像。
鉴别器将一张图像作为输入,并尝试预测其为原始图像或是生成器的输出图像。
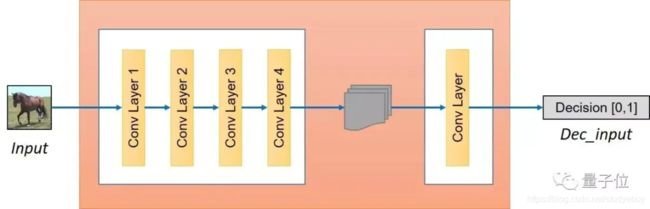
鉴别器本身属于卷积网络,需要从图像中提取特征,再通过添加产生一维输出的卷积层来确定提取的特征是否属于特定类别。
CycleGAN的效果:


CycleGAN是直接进行转换(direct transformation)的方法, 也就是图片不会进行encode之后再进行转换. 这样做会导致其实生成器生成前后的内容不会差太多。
所以我们一般会使用CycleGAN来进行风格转换之类的, 而不会直接进行图像的生成, 如头像的生成之类的工作。
Pix2PixHD(2018)
[paper]High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
[code]NVIDIA/pix2pixHD

Pix2PixHD是Pix2Pix的升级版,Pix2Pix本质上是一个condition GAN,可以很好的在有监督情况下将一个域的图像转化成另一个域的图像。但是生成的图像分辨率仅为256x256,而使用GAN生成高分辨率图片也是一个挑战。Pix2PixHD可以生成2k的高清图片,可以将语义分割+实例分割信息转化成真实的图片,可认为是语义分割、实例分割的逆操作。
Pix2PixHD可以实现:
- 生成十分真实的2K高清图片,解决GAN难以生成高清图片的问题。
- 可以通过调整语义分割图片以及选取不同的特征,自由生成图片。
- 使用多尺度的生成器以及判别器等方式从而生成高分辨率图像。
- 使用了一种非常巧妙的方式,实现了对于同一个输入,产生不同的输出。并且实现了交互式的语义编辑方式,这一点不同于Pix2Pix中使用dropout保证输出的多样性。
为了生成高分辨率图像,作者主要从三个层面做了改进:
- 模型结构

生成器由两部分组成,G1和G2,其中G2又被分成两个部分。G1和Pix2Pix的生成器没有区别,就是一个end2end的U-Net结构。G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加融合信息,把融合后的信息送人G2的后半部分输出高分辨率图像。
判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。判别的三个尺度为:原图,原图的1/2降采样,原图的1/4将采样(实际做法为在不同尺度的特征图上进行判别,而非对原图进行降采样)。显然,越粗糙的尺度感受野越大,越关注全局一致性。
生成器和判别器均使用多尺度结构实现高分辨率重建,思路和PGGAN类似,但实际做法差别比较大。 - loss设计
- GAN loss:和Pix2Pix一样,使用PatchGAN
- Feature matching loss:将生成的样本和Ground truth分别送入判别器提取特征,然后对特征做Element-wise loss。
- Content loss:将生成的样本和Ground truth分别送人VGG16提取特征,然后对特征做Element-wise loss。

使用Feature matching loss和Content loss计算特征的loss,而不是计算生成样本和Ground truth的MSE,主要在于MSE会造成生成的图像过度平滑,缺乏细节。Feature matching loss和Content loss只保证内容一致,细节则由GAN去学习。
- 使用Instance-map的图像进行训练
Pix2Pix采用语义分割的结果进行训练,可是语义分割结果没有对同类物体进行区分,导致多个同一类物体排列在一起的时候出现模糊,这在街景图中尤为常见。作者使用个体分割(Instance-level segmentation)的结果来进行训练,因为个体分割的结果提供了同一类物体的边界信息。具体的做法是:- 根据个体分割的结果求出Boundary map
- 将Boundary map与输入的语义标签concatnate到一起作为输入Boundary map求法很简单,直接遍历每一个像素,判断其4邻域像素所属语义类别信息,若果有不同,则置为1。

如果希望对于同一张语义分割图,希望生成不同的图片,比如把路面从柏油马路变成石头路,黑车变成白车需要做如下的工作。
不同于Pix2Pix实现多样性的方法(使用Dropout),这里采用了一个非常巧妙的方法,即学习一个条件(Condition)作为条件GAN的输入,不同的输入条件就得到了不同的输出,从而实现了多样化的输出。而且还是可编辑的。具体做法如下:

- 首先训练一个编码器
- 利用编码器提取原始图片的特征,然后根据labels信息进行Average pooling,得到特征(上图的Features)。这个Features的每一类像素的值都代表了这类标签的信息。
- 如果输入图像有足够的多,那么Features的每一类像素的值就代表了这类物体的先验分布。对所有输入的训练图像通过编码器提取特征,然后进行k-means聚类,得到k个聚类中心,以k个聚类中心所代表不同的颜色、纹理等信息。k种特征就包含了黑车、白车、柏油路和石头路的信息。
- 实际生成图像时,除了输入语义标签信息,还要从k个聚类中心随机选择一个,即选择一个颜色/纹理风格。即对每个instance选择特征就可以得到相应的图片。
这个方法总的来说非常巧妙,通过学习数据的隐变量达到控制图像纹理风格信息。
Pix2PixHD效果:


参考资料
pix2pix算法笔记
[GAN笔记] pix2pix
一文读懂GAN, pix2pix, CycleGAN和pix2pixHD
【论文笔记】CycleGAN
CycleGAN原理与例子-Pytorch实现
CycleGAN生成对抗网络图像处理工具
无需成对示例、无监督训练,CycleGAN生成图像简直不要太简单
CycleGAN原理及实验(TensorFlow)
cgan与pix2pix的区别。。
深度学习之Pix2PixHD
CycleGAN算法笔记
利用GAN合成以假乱真的 2K 高清图
深度学习之Pix2PixHD
Perceptual Loss: 提速图像风格迁移1000倍
图像翻译三部曲:pix2pix, pix2pixHD, vid2vid