《鼠鼠被逐出下水道后邂逅最强桥洞蟑螂》之mmpose,pphuman跑通入门级教程
如果大家之前没有做过mmlab系列的项目,有可能会不知道如何配置,mmlab系列相关的环境,这里我再单独介绍一遍,如何配置mmlab系列的基础环境。
首先,你需要配置一下基础环境,python,pytorch之类的,这里我的配置是windows11+python3.9+pytorch1.12.0 如果大家不知道如何配置这些基础环境的话,请移步我的第一篇博客
《关于我被车创④,转生到异世界以后什么都不会,于是从零开始搞深度学习这回事》之 yolov7保姆级教学_深度学习鲨我的博客-CSDN博客
基础环境安装完毕以后,首先我们需要安装openmim,这个是mmlab所有项目的统一入口,非常的方便,类似于python环境里的“pip”,具体安装代码如下
pip install -U openmim下一步,就是要安装mmcv-full,这个是mmlab所有项目都需要使用的一个工具包,具体安装代码如下
mim install mmcv-full如果这两步的安装没有问题的话,那么大家的基础开发环境也搭建完毕了,这里大家可以打开interpreter setting查看你的工具包是否安装完成。

这里,大家可以看到我安装好的mmcv-full版本是1.7.0的版本,说明我的工具包已经安装完毕了,接下来就正式开始mmpose的教程。
首先,就是克隆代码,安装依赖包,这里我就不一一解释了,大家直接按照下面的代码一条一条执行即可, 这里需要注意的是,由于有的依赖包会从外网下,所以下载较慢,或者超时报错都是正
常的,大家多执行几遍,或者科学上网都可以
git clone https://github.com/open-mmlab/mmpose.git
cd mmpose
pip install -r requirements.txt
pip install -v -e .
pip install mmpose安装完毕以后,大家首先需要下载一些配置文件和权重文件,代码如下
mim download mmpose --config associative_embedding_hrnet_w32_coco_512x512 --dest .如果运行无误,那么你应该会得到如下结果

这一步完成以后,我们输入以下代码来验证推理以下,检查一下我们的环境是否搭建完成
python demo/bottom_up_img_demo.py associative_embedding_hrnet_w32_coco_512x512.py hrnet_w32_coco_512x512-bcb8c247_20200816.pth --img-path tests/data/coco/ --out-img-root vis_results如果运行无误,大家应该可以在根目录里找到vis_results这个文件夹里看到如下图片

看到上述图片,说明你的环境已经搭建完毕了,最后,只要输入以下代码,就可以打开摄像头进行实时的姿态估计啦
python C:\Users\20105\Desktop\mmps\mmpose\demo\webcam_demo.py --config C:\Users\20105\Desktop\mmps\mmpose\demo\webcam_cfg\pose_estimation.py这里你需要注意的是,我用的都是绝对寻址,大家只要找到自己的这个文件的地址就可了,一个在demo里面,一个在demo里的webcam_cfg里面,这个--config后面的文件是可以修改的,大家如果打开webcam_cfg文件夹,会发现里面有四个文件,大家都可以尝试一下,分别是姿态估计,目标跟踪,手部检测等,这里我只运行了一下姿态估计,给大家看一下效果。
在进行pphuman的教学之前,首先要更正之前博客里面的一个误区,也是我之前没做过这个项目,所以没想到这个问题

paddle paddle的所有项目,最好为他单独创建一个环境,因为paddle paddle不知道为啥,他会修改你gpu的id,导致你其他的项目根本找不到你的gpu,我之前大杂烩的时候,把我的pytorch的版本都改成cpu的了,环境直接爆炸。
在开始pphuman的教学之前,首先要强调一下,我用的版本是release2.4版本的paddledetection!重要的事情说三遍!release2.4!release2.4!release2.4!
因为大家如果是直接用git下载的话,大概率会下载到最新的版本,也就是2.5的版本,但是2.5的版本文件结构变了,所以不能适用本次教程。
这里我建议大家,打开github以后,直接下载压缩包,用压缩包打开,不然很容易下错版本,具体如下。
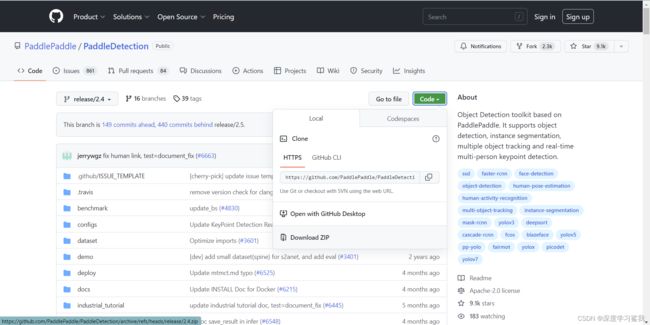
下载完成以后,打开压缩包,然后在根目录创建一个心的文件夹,叫output_inference
然后下载目标检测,目标跟踪,关键点识别,属性识别四个预测 部署模型,链接如下
PaddleDetection/deploy/pphuman at release/2.4 · PaddlePaddle/PaddleDetection · GitHub

直接点击下载链接即可,下载完毕后,解药到刚才创建的output_inference文件夹里。
在我的上一个博客里面有教大家如何搭建paddledetection的环境,如果还不不知道如何搭建环境,如何安装paddle paddle的话,请移步我的上一篇博客,链接如下
《平成的超级偶像金牌舔狗》之mmdetection,paddle detection安装,demo跑通,训练跑通,保姆级教学_深度学习鲨我的博客-CSDN博客
解压完毕以后,大家可以先运行以下代码,来测试自己的环境是否搭建完毕
python tools/infer.py -c configs/ppyolo/ppyolo_r50vd_dcn_1x_coco.yml -o use_gpu=true weights=https://paddledet.bj.bcebos.com/models/ppyolo_r50vd_dcn_1x_coco.pdparams --infer_img=demo/000000014439.jpg
如果得到以下结果,说明环境搭建完成。

你需要自己选择一张图片,和一段视频,图片和视频里面一定要有人,然后放到根目录里,这里注意,我建议大家用手机自己拍,因为拍出来以后就是mp4,jpg格式,免得大家再去转格式。以上工作完毕以后,直接输入以下代码,就可以开始预测啦
目标检测
python deploy/pphuman/pipeline.py --config deploy/pphuman/config/infer_cfg.yml --image_file=test_det.jpg --device=gpu #这里的image——file记得改成自己的图片的名字,下面的代码都一样,都改成自己的目标跟踪
python deploy/pphuman/pipeline.py --config deploy/pphuman/config/infer_cfg.yml --video_file=test_track.mp4 --device=gpu行人属性检测
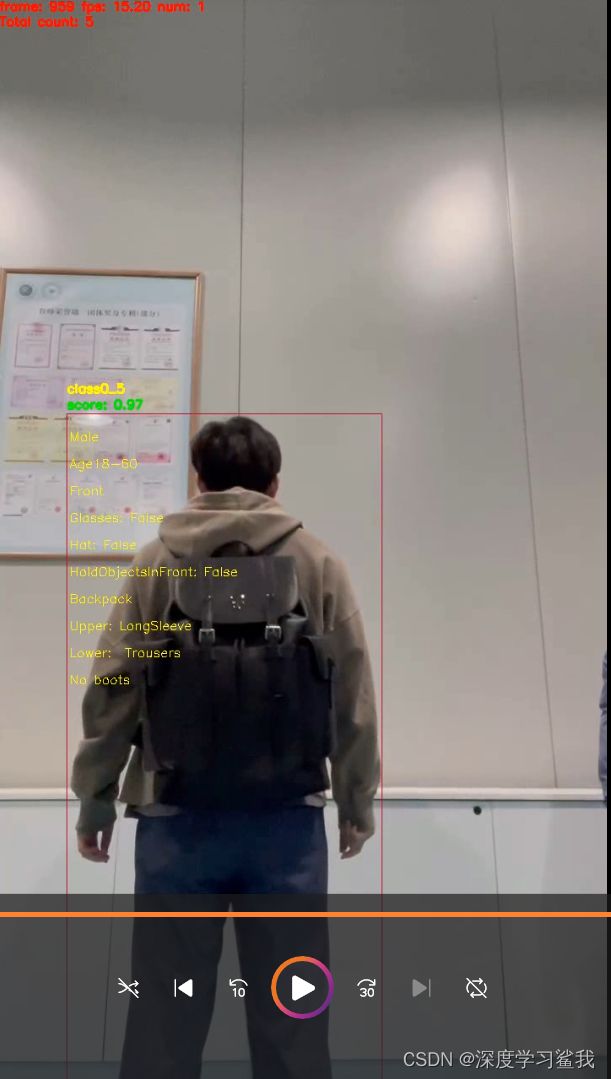
python deploy/pphuman/pipeline.py --config deploy/pphuman/config/infer_cfg.yml --video_file=test_attr.mp4 --device=gpu --enable_attr=True行为识别
python deploy/pphuman/pipeline.py --config deploy/pphuman/config/infer_cfg.yml --video_file=test_action.mp4 --device=gpu --enable_action=True最后,附上我的运行结果