5 用Pandas库处理数据(Series和DataFrame)
5.1 Pandas库功能简述
其实Pandas库是基于NumPy库构建的,并且专门用来处理数据。它主要构造了两种新的数据结构:Series(是NumPy库的ndarray包的一种数据结构)和DataFrame。
5.2 Series
Series的特征是允许存放各种基本的数据类型,如in、float等。它类似于字典,是一组键-值对。键和值可以是任意一种数据类型,而且保持一对一的映射关系,是无序的。但与字典不同的是,Series的index(键)和value(值)是独立的。也就是说,对index排序,只会改变index的排序而不会改变value中存放的数据的顺序。还有一个不同点是,Series的index和value都是可变的,而在字典中只有value是可变的,它的key实质上是元组,所以一旦创建就不可以改变。
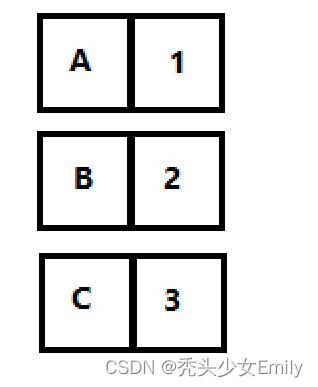 标Series数据结构示意图题
标Series数据结构示意图题
- Series的value属性为:
,也就是说是numpy的ndarray(多维度的数组对象) - Series的index属性为:
,并且index可以用来遍历比如:for i in series_1.index:print(i)
5.2.1 创建Series对象
from pandas import Series
import pandas as pd
import numpy
series_1 = pd.Series([1, 2, 3, 4, 5]) # 初始化单行Series的值
series_1.index = ['A', 'B', 'C', 'D', 'E'] # 初始化单行Series的键
print(series_1)
# 同时初始化两行Series的键与值
series_2 = Series(data=[1, 2, 3, 4, 5], index=('a', 'b', 'c', 'd', 'e'))
print(series_2)
'''
结果为:
A 1
B 2
C 3
D 4
E 5
dtype: int64
a 1
b 2
c 3
d 4
e 5
dtype: int64
'''还有一些方式创建
# 使用字典的方式创建
series_3 = pd.Series({'A': 1, 'B': 2, 'C': 3})
print(series_3)
'''
结果为:
A 1
B 2
C 3
dtype: int64
'''
print(pd.Series([1, 2])) # 系统自动分配隐式索引
'''
结果为:
0 1
1 2
dtype: int64
'''
print(pd.Series(np.arange(2), index=['a', 'b'])) # 使用np.arange()创建值
'''
结果为:
a 0
b 1
dtype: int32
'''
print(pd.Series(6, index=['a', 'b'])) # 索引个数就是索引(键)的元素个数,索引不同但是但是值都是6
'''
a 6
b 6
dtype: int64
'''5.2.2 索引与切片
Series对象也可以进行索引和切片的操作,不同的是Series对象因为内部维护了一个保护索引的数组。除了类似字符串的索引外,还可以通过自己设置的检索标签获取相对应的数据。先给出结论:不管是索引、切片或者是数组索引,其实series,dataframe,ndarray这些切片的规则都是一样的。比如:xxx可以是sereis, dataframe, ndarray,则xxx[“a”]表示单索引;xxx[[“a”, “b”]]表示标签数组,数组索引;xxx[[0,1,2]]表示下标(位置)数组,数组索引;xxx[0:3]表示切片的语法;xxx[[True, False]]表示布尔数组。
- 显示索引(标签索引):通过行索引 “Index” 中的具体值来取行数据(如取"Index"为"A"的行),格式为:Series对象.loc[](loc不是函数,所以不使用小括号()而是中括号,并且中括号是闭区间,也就是说可以取到左边,不是取左不取右)
- 隐式索引(位置索引):通过行号来取行数据(如取第2行的数据,从0行开始),格式为:Series对象.iloc[](loc不是函数,所以不使用小括号()而是中括号)
import pandas as pd
series_1 = pd.Series(('a', 'b', 'c', 'd', 'e'), index=[1, 2, 3, 4, 5])
print('显示索引:')
print(series_1.loc[3:5]) # 显示索引,可以取到5
print(series_1.loc[3]) # 显示索引
'''
结果为:
显示索引:
3 c
4 d
5 e
dtype: object
c
'''
print('隐式索引:')
print(series_1.iloc[3:5]) # 隐式索引,从第3行往后取(0行开始),可以取到5
print(series_1.iloc[3]) # 隐式索引,取第3行(0行开始)
'''
结果为:
隐式索引:
4 d
5 e
dtype: object
d
'''这里可能看的不明显,在DataFrame使用起来会更明显,在那部分再详细的说。
- 利用get()函数来索引:Series对象.get(object, defualt),object为要索引的index,defualt为,如果要索引的index存在,返回index对应的value,不存在则返回defualt值
import pandas as pd
series_1 = pd.Series(('a', 'b', 'c', 'd', 'e'), index=[1, 2, 3, 4, 5])
print(series_1.get(1, 10)) # 能在series_1中找到index = 1所对应的值则返回
print(series_1.get(6, 'f')) # series_1中没有index = 6,则给它赋值- 类似字符串的位置索引,在这里需要注意:1.如果创建series的时候没有指定索引,则生成从0开始的整数索引;如果创建series的时候指定了字符串索引,则生成指定字符串索引,同时也可以使用从0开始的整数索引进行数据访问;如果创建的series的时候指定了整数索引,则生成指定的整数索引,不可以使用从0开始的整数索引进行数据访问。(当索引为整数类型时,不能用负数做下标)
import pandas as pd
import numpy as np
# 没有指定索引,则生成从0开始的整数索引且索引时,下标不能为负数
s1 = pd.Series(range(1, 5)) # range()取左不取右,和loc[]、iloc[]不一样
print(s1)
'''
结果为:
0 1
1 2
2 3
3 4
dtype: int64
'''
print(s1[0]) # 结果为:1
print(s1[0:2])
'''
结果为:
0 1
1 2
dtype: int64
'''
# 指定了字符串索引,可以用从0开始的整数索引(下标)进行访问
s2 = pd.Series([1, 2, 3], index=('a', 'b', 'c'))
print(s2)
'''
结果为:
a 1
b 2
c 3
dtype: int64
'''
print(s2['a']) # 结果为:1
print(s2[2]) # 结果为:3
print(s2[-3]) # 结果为:1
print(s2['a': 'b'])
'''
结果为:
a 1
b 2
dtype: int64
'''
# 指定了整数索引,不能使用从0开始整数进行访问,下标也不能是负数
s3 = pd.Series(np.arange(3), index=[1, 2, 3])
print(s3)
'''
结果为:
1 0
2 1
3 2
dtype: int32
'''
print(s3[1]) # 结果为:0- 布尔索引:用来判断列表中数值的范围
import pandas as pd
import numpy as np
s4 = pd.Series(np.arange(5), index=['a', 'b', 'c', 'd', 'e'])
print(s4[s4 > 2])
'''
结果为:
d 3
e 4
dtype: int32
'''
print(s4[s4 != 2])
'''
结果为:
a 0
b 1
d 3
e 4
dtype: int32
'''5.2.3 Series对象的常用属性
| 属性 | 说明 |
| dtype/dtypes | 返回Series对象的数据类型 |
| hasnans | 判断Series对象中有无空值 |
| at/iat | 通过索引访问Series对象中的一组值 |
| loc[]/iloc[] | 通过索引访问Series对象中的值 |
| index | 返回行索引名 |
| values | 以ndarray的方式返回Series对象的data |
| size | 返回Series对象中元素个数 |
| axes | 返回行轴标签列表 |
| empty | 若为空,返回True |
| is_unique | 判断数据是否唯一 |
| is_monotonic | 判断Series对象是否单调 |
| is_monotonic_increasing | 判断Series对象是否单调递增 |
| is_monotonic_decreasing | 判断Series对象是否单调递减 |
| head(n) | 返回前n行 |
| tail(n) | 返回后n行 |
| nidm | 但会底层数据的位数,默认为1 |
5.2.4 Series对象的常用方法
| 方法 | 说明 |
| sum() | 求和 |
| mean() | 求平均值 |
| max() | 求最大值 |
| min() | 求最小值 |
| count() | 计数 |
| std() | 求标准差 |
| var() | 求方差 |
| median() | 求中位数 |
| describe() | 可以获得上述所有的描述性统计信息,如方差,标准差,中位数等,同时对于某一特定的值,也可以通过索引的方式获得 |
| value_counts() | 可以统计每个值重复的次数并返回一个Series对象。它的索引就是原来的Series对象中的值,而每个值出现的次数就是返回的Series对象中的数据,在默认情况下会按照出现次数做降序排列 |
| unique() | 如果Series对象有重复的值,使用unique()方法获得去重之后的Series对象,返回的是一个值的列表 |
| nunique() | 统计不重复Series对象值的数量 |
| isnull() | 用于判空值 |
| notnull() | 用于判空值 |
| dropna() |
删除空值 |
| fillna() | 填充空值,利用参数value赋值来填充 |
| mask() | 将满足条件的全部替换 |
| where() | 将不满足条件的替换 |
| duplicated() | 找出重复的数据,根据布尔值显示是否重复 |
| drop_duplicates() | 删除重复的数据 |
| map() | 不通过索引,直接通过内容来进行修改数据 |
| apply(func, convert_dtype=True, arges=(),**kwds) | 将原始值通过一定的计算,得到想要的数组,执行funcde的结果,返回Series对象 |
| sort_index() | 对索引进行排序,ascending参数用来控制升序还是降序,默认False为升序;kind参数控制排序算法:默认为quicksort,还有mergesort/heapsort;na_position参数:空值放在前还是在后,默认last |
| sort_values() | 对值进行排序,ascending参数用来控制升序还是降序,默认False为升序;kind参数控制排序算法:默认为quicksort,还有mergesort/heapsort;na_position参数:空值放在前还是在后,默认last |
| nlargest() | 找出元素中最大的“Top-N” |
| nsmallest() | 找出元素中最小的“Top-N” |
上表的这些方法其实在DataFrame部分属于数据处理的部分,因为DataFrame可以看作是多个Series对象组成,所以在Series这里也适用,但是两者使用方法是一致的,可能在DataFrame里不会这么详细的写运行过程和结果。
- describe():可以获得上述所有的描述性统计信息,如方差,标准差,中位数等,同时对于某一特定的值,也可以通过索引的方式获得
import pandas as pd
import numpy as np
s1 = pd.Series(np.arange(5), index=['a', 'b', 'c', 'd', 'e'])
print(s1.describe())
'''
结果为:
count 5.000000
mean 2.000000
std 1.581139
min 0.000000
25% 1.000000
50% 2.000000
75% 3.000000
max 4.000000
dtype: float64
'''
print(s1.describe()['count']) # 取特定的count值,结果为:5.0- value_counts():可以统计每个值重复的次数并返回一个Series对象。它的索引就是原来的Series对象中的值,而每个值出现的次数就是返回的Series对象中的数据,在默认情况下会按照出现次数做降序排列。
import pandas as pd
s2 = pd.Series(data=['a', 'b', 'a', 'c', 'a', 'c', 'd'])
print(s2.value_counts())
'''
结果为:
a 3
c 2
b 1
d 1
dtype: int64- unique():如果Series对象有重复的值,使用unique()方法获得去重之后的Series对象,返回的是一个值的列表
- nunique():统计不重复Series对象值的数量
import pandas as pd
s2 = pd.Series(data=['a', 'b', 'a', 'c', 'a', 'c', 'd'])
print(s2.unique()) # 结果为:['a' 'b' 'c' 'd']
print(s2.nunique()) # 结果为:4- isnull():用于判空值
- notnull():用于判空值
首先我们先知道再Pandas中,用NaN(Not a Number,不是一个数字)表示空值,和None的区别在哪儿?None == None,但是NaN !=NaN,因为NaN是一个随机浮点数,所以NaN !=NaN。
import pandas as pd
import numpy as np
s3 = pd.Series(data=[1, 2, 3, np.NaN, 4, np.NaN])
print(s3.isnull())
'''
结果为:
0 False
1 False
2 False
3 True
4 False
5 True
dtype: bool
'''
print(s3.notnull())
'''
0 True
1 True
2 True
3 False
4 True
5 False
dtype: bool
'''
# 在这里看出来,np.NaN既不是空值也不是值- dropna():删除空值
- fillna():填充空值,利用参数value赋值来填充
dropna()和fillna()方法都有一个名为inplace的参数,它的默认值是False,表示删除空值或填充空值不会修改原来的Series对象,而是返回一个新的Series对象来表示删除或填充空值后的数据系列,如果将inplace参数的值修改为True,那么删除或填充空值会就地操作,直接修改原来的Series对象,那么方法的返回值是None。后面我们会接触到的很多方法,包括DataFrame对象的很多方法都会有这个参数,它们的意义跟这里是一样的。
import pandas pd
s3 = pd.Series(data=[1, 2, 3, np.NaN, 4, np.NaN])
print(s3.dropna())
'''
0 1.0
1 2.0
2 3.0
4 4.0
dtype: float64
'''
print(s3.fillna(value=50))
'''
结果为:
0 1.0
1 2.0
2 3.0
3 50.0
4 4.0
5 50.0
dtype: float64
'''- mask():将满足条件的全部替换
- where():将不满足条件的替换
import pandas as pd
import numpy as np
s4 = pd.Series(np.arange(5), index=[1, 2, 3, 4, 5])
print(s4.mask(s4 > 2, 10)) # s4>2的意思是s4的value大于2
'''
结果为:
1 0
2 1
3 2
4 10
5 10
dtype: int32
'''
print(s4.where(s4 > 2, 10))
'''
结果为:
1 10
2 10
3 10
4 3
5 4
dtype: int32
'''- duplicated():找出重复的数据,根据布尔值显示是否重复
- drop_duplicates():删除重复的数据
import pandas as pd
import numpy as np
s4 = pd.Series(np.arange(5), index=[1, 2, 3, 4, 5])
print(s4.mask(s4 > 2, 10)) # s4>2的意思是s4的value大于2
'''
结果为:
1 0
2 1
3 2
4 10
5 10
dtype: int32
'''
print(s4.where(s4 > 2, 10))
'''
结果为:
1 10
2 10
3 10
4 3
5 4
dtype: int32
'''- map():不通过索引,直接通过内容来进行修改数据
import pandas as pd
import numpy as np
s4 = pd.Series(np.arange(5), index=[1, 2, 3, 4, 5])
print(s4.mask(s4 > 2, 10)) # s4>2的意思是s4的value大于2
'''
结果为:
1 0
2 1
3 2
4 10
5 10
dtype: int32
'''
print(s4.where(s4 > 2, 10))
'''
结果为:
1 10
2 10
3 10
4 3
5 4
dtype: int32
'''- apply():将原始值通过一定的计算,得到想要的数组(在DataFrame部分详细介绍)
5.3 DataFrame
DataFrame与Series不同(DataFrame由多个series组成),它类似一张邻接表。这张邻接表的行被称为index,列被称为columns。其中,一列的数据结构必须相同,但是不同的列,其数据结构可以相同,也可以不同。
5.3.1 创建DataFrame对象
- 通过各种形式数据创建DataFrame对象,比如利用:ndarray(numpy中的多维数组),series,map(方法),lists,dict,constant和另一个DataFrame
- 读取其他文件创建DataFrame对象,比如CSV,JSON,HTML,SQL等
创建语法格式:DataFrame(data, index, columns, dtype, copy)
| 参数 | 描述 |
| data | ndarray,series,map,lists,dict,constant和另一个DataFrame |
| index | 行标签(类似Series的用法),不设置则自动从下标0开始 |
| columns | 列标签,可选的默认语法为:np.arange(n),不设置则自动从下标0开始 |
| dtype | 每列的数据类型(不同列的数据类型可以相同可以不同) |
| copy | 若默认值为:False,则可以用于复制 |
通过各种形式数据创建DataFrame对象:
import pandas as pd
import numpy as np
a = np.arange(1, 7).reshape(2, 3)
d1 = pd.DataFrame(a)
print(d1)
'''
结果为:
0 1 2
0 1 2 3
1 4 5 6
'''
print(type(d1)) # 结果为:
# d2与d1一样的结果
d1_1 = pd.DataFrame([[1, 2, 3], [4, 5, 6]])
print(d1_1)
column = ['一', '二', '三', '四', '五']
row = ['早', '中', '晚']
eat = np.random.randint(1, 10, (3, 5)) # 三行五列的随机矩阵
d2 = pd.DataFrame(data=eat, columns=column, index=row)
print(d2)
'''
结果为:
一 二 三 四 五
早 1 6 8 6 3
中 2 3 1 2 6
晚 5 2 6 2 2
'''
# ---------------更好的理解DataFrame中的列
df1 = pd.DataFrame([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29]])
for col in df1.columns:
print(df1[col])
'''
0 0
1 10
2 20
Name: 0, dtype: int64
0 1
1 11
2 21
Name: 1, dtype: int64
0 2
1 12
2 22
Name: 2, dtype: int64
0 3
1 13
2 23
Name: 3, dtype: int64
0 4
1 14
2 24
Name: 4, dtype: int64
0 5
1 15
2 25
Name: 5, dtype: int64
0 6
1 16
2 26
Name: 6, dtype: int64
0 7
1 17
2 27
Name: 7, dtype: int64
0 8
1 18
2 28
Name: 8, dtype: int64
0 9
1 19
2 29
Name: 9, dtype: int64
''' 通过读取其他文件创建DataFrame对象:
| 格式类型 | 数据描述 | 读取 | 写入 |
| text | CSV | read_csv() | to_csv() |
| text | JSON | read_json() | to_json() |
| text | local clipboard | read_clipboard() | to_clipboard() |
| binary | Ms Excel | read_excel() | to_excel() |
| binary | HDF5 Format | read_hdf() | to_hdf() |
| binary | Feather Format | read_feather() | to_feather() |
| binary | Parquet Format | read_parquet() | to_parquet() |
| binary | Msgpack | read_msgpack() |
to_msgpack() |
| binary | Stata | read_stata() | to_stata() |
| binary | SAS | read_sas() | to_sas() |
| binary | Python Pickle Format | read_pickle() | to_pickle() |
| SQL | SQL | read_sql() | to_sql() |
| SQL | Google Big Query | read_gbq() | to_gbq() |
read_csv()的参数非常多,比较重要的参数有这些:
- filepath_or_buffer:用来指定数据的路径
- sep:用来指定数据中列之间的分隔符的,接收一个str对象。默认分隔符为逗号
- delimiter:用来指定分隔符的,和参数sep功能相同,但默认值为None
- delim_whitespace:用来设置数据中的分隔符的。接收一个布尔值,表示是否将空白字符作为分隔符
- header:如果数据中包含表头,或者说列名,这个参数用来指定表头在数据中的行号。接收一个int对象或者由int构成的列表对象。默认值是infer。infer的行为如下:如果没有指定names参数,infer就等价于header=0;如果指定了names参数,此时的infer等价于header=None
- names:用来指定列名
- index_col:若想把数据中的某一列数据作为index,就可以使用这个参数。默认值为None
- usecols:一个文件中的数据可能有很多列,有时候只需要部分列,这时候可以使用usecols参数
- squeeze:如果读取的数据只有一列,默认返回的是DataFrame,如果我们希望返回Series,可以使用这个参数。参数接收的是布尔值,默认为False,表示返回DataFrame,如果是True,则返回Series
- prefix:指定一个前缀,则列的序号会和这个前缀拼接到一块构成列名
- mangle_dupe_cols:这个参数接收一个布尔值,如果是True,若数据中存在同名列,如有两个name列,则第一个列名保持不变,第二个name列将被重命名为name.1。如果是FALSE会抛出ValueError异常。
- skiprows:来指定在读取数据时,我们想跳过哪些行
- skipfooter:表示不读取数据的最后n行
- nrows:指定pandas一次性从文件中读取多少行数据,这在读取海量数据中很有用
- na_filter:控制pandas在读取数据时是否自动检测数据中的缺失值。这个参数就是用来控制这个行为的。默认为True表示检测缺失值,如果设置为False,表示不检测缺失值
- skip_blank_lines:判断是否跳过空行。如果指定为True,表示跳过空行。指定为False,不跳过空行,空行数据正常读取但被全部转换为缺失值nan。默认值为True
- encoding:指定读取文件时使用的编码,通常是utf-8,可以根据自己文件的实际编码进行设置
import pandas as pd
df = pd.read_csv(r'test.csv', encoding='utf-8')
print(df)
'''
结果为:
姓名 年龄 学号
0 aaa 18 101
1 bbb 18 102
2 ccc 19 103
3 ddd 18 104
4 eee 18 105
5 fff 19 106
6 ggg 19 107
7 hhh 18 108
'''
df_1 = pd.read_csv(r'test.csv', encoding='utf-8', nrows=2) # 显示前两行
print(df_1)
'''
结果为:
姓名 年龄 学号
0 aaa 18 101
1 bbb 18 102
'''导入文件后,好像会默认index值从0开始。
pandas read_sql 和 to_sql 读写Mysql的参数详解
excel文件的函数请看:read_excel 和 to_excel 读写Excel的参数详解这篇文章
5.3.2 DataFrame的属性/方法
| 属性/方法 | 说明 |
| at/iat | 通过标签获取DataFrame中的单个值 |
| columns | 获取列的索引 |
| values | 获取数据对应的二位数字 |
| index | 获取行的索引 |
| dtypes | 获取每一列的数据类型 |
| empty | 对象是否为空 |
| loc[]/iloc[](行)/loc[[]]/iloc[[]](列) | 通过标签获取行组值 |
| ndim | 获取维度 |
| shape | 获取形状(行和列数) |
| size | 获取元素个数 |
| info() | 获取DataFrame相关信息 |
| head() | 获取头部数据,默认参数是5 |
| tail() | 获取尾部数据,默认参数是5 |
| describe() | 获取数据的描述性统计信息 |
- 获取DataFrame的values值
- 获取DataFrame的index值
- 获取DataFrame的columns值
- 修改行/列的名称(修改行/列需要修改全部的名字,不然会报错)
import pandas as pd
import numpy as np
a = np.arange(1, 7).reshape(2, 3)
d1 = pd.DataFrame(a)
print(d1)
'''
结果为:
0 1 2
0 1 2 3
1 4 5 6
'''
# 获取values
print(d1.values)
'''
结果为:
[[1 2 3]
[4 5 6]]
'''
print(type(d1.values)) # 结果为:
# 获取index
print(d1.index) # 结果为:RangeIndex(start=0, stop=2, step=1)
# 获取columns
print(d1.columns) # 结果为:RangeIndex(start=0, stop=3, step=1)
# 修改行/列
dmodify = pd.DataFrame(a, index=['行0', '行1'], columns=['列0', '列1', '列2'])
print(dmodify)
'''
结果为:
列0 列1 列2
行0 1 2 3
行1 4 5 6
''' - 转置
- 添加一行:DataFrame.loc[] = value,多行用concat()
import pandas as pd
import numpy as np
# 添加一行DataFrame.loc[要添加的index位置(默认为整型,也可以自定义赋值)] = 对应的值
# loc适合对空DataFrame对象进行循环添加行
df_loc = pd.DataFrame(data=[[101, 'xxx'], [102, 'yyy']], columns=['id', 'name'])
print(df_loc)
'''
id name
0 101 xxx
1 102 yyy
'''
df_loc.loc[2] = [103, 'zzz']
print(df_loc)
'''
id name
0 101 xxx
1 102 yyy
2 103 zzz
'''- 添加一列:DataFrame[] = value,多列用多行用concat()
import pandas as pd
# 利用DataFrame.[要添加的columns位置(默认为整型,也可以自定义赋值)] = 对应的值
df_col = pd.DataFrame(data=[[101, 'xxx'], [102, 'yyy']], columns=['id', 'name'])
print(df_col)
'''
id name
0 101 xxx
1 102 yyy
'''
df_col['sex'] = ['女', '男']
print(df_col)
'''
id name sex
0 101 xxx 女
1 102 yyy 男
'''5.3.3 DataFrame的索引与切片
DataFrame对象可以看作是由多个Series对象组成的,所以索引、切片方式和Series的索引、切片方式类似
列索引:
import pandas as pd
import numpy as np
a = np.arange(1, 7).reshape(2, 3)
d1 = pd.DataFrame(a)
d2 = pd.DataFrame(data=np.random.randint(0, 100, size=(3, 5)), columns=list("ABCDE"))
print(d1)
'''
0 1 2
0 1 2 3
1 4 5 6
'''
print(d2)
'''
A B C D E
0 4 31 12 56 51
1 77 15 64 90 64
2 65 89 42 71 47
'''
print(d1[1]) # 字典访问(使用整数索引),结果为第1列
'''
0 2
1 5
Name: 1, dtype: int32
'''
print(d1[[1, 2]]) # 花式索引,得到的结果为第1列和第2列
'''
1 2
0 2 3
1 5 6
'''
print(d2['A']) # 使用自定义的标签索引,和下面的结果一样
print(d2.A) # 通过属性访问(注意属性不能为数字),得到A那列
'''
0 4
1 77
2 65
Name: A, dtype: int32
'''
print(d1[d1 < 1]) # 布尔索引,因为元素比1大,所以得出的结果都被赋予NaN值
'''
0 1 2
0 NaN NaN NaN
1 NaN NaN NaN
'''行索引:
import pandas as pd
import numpy as np
d3 = pd.DataFrame(data=np.random.randint(0, 100, size=(3, 5)), columns=list("ABCDE"), index=[0, 2, 4])
print(d3)
'''
A B C D E
0 7 32 33 53 79
2 36 81 54 12 96
4 2 29 6 10 87
'''
# loc[[]]:根据index来索引。
# iloc[[]]:根据行号来索引,行号从0开始,逐次加1。
print(d3.loc[[2]])
'''
A B C D E
2 36 81 54 12 96
'''
print(d3.iloc[[2]]) # 行号从0开始算,取行号为2的一行数据,对应的是index=4的一行数据
'''
A B C D E
4 2 29 6 10 87
'''元素索引(类似a[1][1]这样的访问):
import pandas as pd
import numpy as np
d1 = pd.DataFrame(np.arange(1, 7).reshape(2, 3))
print(d1)
d3 = pd.DataFrame(data=np.random.randint(0, 100, size=(3, 5)), columns=list("ABCDE"), index=[0, 2, 4])
print(d3)
'''
d1 =
0 1 2
0 1 2 3
1 4 5 6
d3 =
A B C D E
0 78 53 57 1 2
2 55 32 57 87 7
4 61 93 19 14 64
'''
print(d1.loc[0, 0]) # 结果为:1,先行后列
print(d3.loc[0, 'A']) # 结果为:78,第index = 0行第'A'列的元素
print(d1.iloc[0, 0]) # 结果为:1,先行后列
print(d3.iloc[2, 1]) # 结果为:93,第2行第1列的元素切片:
loc直接用中括号时:索引时表示的是列索引,切片时表示的是行切片
import pandas as pd
# 行切片
'''
d3 =
A B C D E
0 16 74 16 78 44
2 58 34 49 19 87
4 66 51 86 73 13
'''
print(d3.loc['0':'2']) # 按照index值来的
'''
A B C D E
0 16 74 16 78 44
2 58 34 49 19 87
'''
print(d3.iloc[0:3]) # 因为是从0开始,所以不包括第3行即取不到第3行,从第0行一直到第2行
'''
A B C D E
0 16 74 16 78 44
2 58 34 49 19 87
4 66 51 86 73 13
'''
# 列切片
print(d3.loc['0':'2', 'A':'B'])
'''
A B
0 16 74
2 58 34
'''
print(d3.loc[:, 'A':'B'])
'''
A B
0 16 74
2 58 34
4 66 51
'''
print(d3.iloc[:, 0:3]) # 因为是从0开始,所以不包括第3行即取不到第3行,从第0列到第2列
'''
A B C
0 16 74 16
2 58 34 49
4 66 51 86
'''5.3.4 DataFrame的常用方法
重塑数据就是数据合并,即把多分不在一起数据合并在一起。①concat(object,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verify_integrity=False)
参数说明:
- object:series,dataframe或是panel构成的序列list
- axis:需要合并连接的轴,0是行,1是列
- join:连接的方式inner,或者outer;如果是 inner 得到的是两表的交集,如果是outer,得到的是两表的并集
- join_axes:如果是join_axes的参数传入,可以指定根据那个轴来对齐数据
- append:append是series和dataframe的方法,使用他就是默认沿着行(axis=0,列对齐)
- ignore_index:使用ignore_index参数,为true时,合并的两个表就根据列字段对齐,合并,最后整理新的index
import pandas as pd
index1 = [0, 1, 2, 3]
data1 = {
'A': ["A0", "A1", "A2", "A3"],
'B': ["B0", "B1", "B2", "B3"],
'C': ["C0", "C1", "C2", "C3"],
'D': ["D0", "D1", "D2", "D3"],
}
d1 = pd.DataFrame(data=data1, index=index1)
index2 = [2, 3, 4, 5]
data2 = {
'B': ["B2", "B3", "B4", "B5"],
'D': ["D2", "D3", "D4", "D5"],
'F': ["F2", "F3", "F4", "F5"],
}
d2 = pd.DataFrame(data=data2, index=index2)
res1 = pd.concat([d1, d2], axis=1) # 按列合并
print(res1)
'''
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3
4 NaN NaN NaN NaN B4 D4 F4
5 NaN NaN NaN NaN B5 D5 F5
'''
res2 = pd.concat([d1, d2], axis=0) # 按行合并
print(res2)
'''
A B C D F
0 A0 B0 C0 D0 NaN
1 A1 B1 C1 D1 NaN
2 A2 B2 C2 D2 NaN
3 A3 B3 C3 D3 NaN
2 NaN B2 NaN D2 F2
3 NaN B3 NaN D3 F3
4 NaN B4 NaN D4 F4
5 NaN B5 NaN D5 F5
'''②merge( left, right, how="inner", on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=("_x", "_y"), copy=True, indicator=False, validate=None)
参数说明:
- left:要连接的左表
- right:要连接的右表
- how:连接方式,inner(将左、右两表中主键一致的行保留下来,然后合并列)、left(保留左表未匹配的数据,填补空值)、right(保留左表未匹配的数据,填补空值)、outer(不会仅仅保留主键一致的行,还会将不一致的部分填充缺失值NaN,然后保留下来),默认为inner。(参考这篇博客:
【星光01】pandas 中 merge 函数的参数 how 超详细解释_杨丝儿的博客-CSDN博客_merge函数how
) - on:用于连接的列名称
- left_on: 左表用于连接的列名
- right_on:右表用于连接的列名
- left_index:是否使用左表的行索引作为连接键,默认False
- right_index:是否使用右表的行索引作为连接键,默认False
- sort:默认为False,将合并的数据进行排序
- copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能
- suffixes:存在相同列名时在列名后面添加的后缀,默认为(’_x’, ‘_y’)
- indicator:显示合并数据中数据来自哪个表
'''
d1
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
d2
B D F
2 B2 D2 F2
3 B3 D3 F3
4 B4 D4 F4
5 B5 D5 F5
'''
# inner,只显示交集部分,将左、右两表中主键一致的行保留下来,然后合并列
res3 = pd.merge(d1, d2, how='inner')
print(res3)
'''
A B C D F
0 A2 B2 C2 D2 F2
1 A3 B3 C3 D3 F3
'''
# left,保证左表不变(不变的表格记为目标表格),然后右表格(记为信息表格)向目标表格添加信息
res4 = pd.merge(d1, d2, how='left')
print(res4)
'''
A B C D F
0 A0 B0 C0 D0 NaN
1 A1 B1 C1 D1 NaN
2 A2 B2 C2 D2 F2
3 A3 B3 C3 D3 F3
'''
# right,保证右表不变(不变的表格记为目标表格),然后左表格(记为信息表格)向目标表格添加信息
res5 = pd.merge(d1, d2, how='right')
print(res5)
'''
A B C D F
0 A2 B2 C2 D2 F2
1 A3 B3 C3 D3 F3
2 NaN B4 NaN D4 F4
3 NaN B5 NaN D5 F5
'''
# outer,保留主键一致的行,将不一致的部分填充缺失值NaN,然后保留下来
res6 = pd.merge(d1, d2, how='outer')
print(res6)
'''
A B C D F
0 A0 B0 C0 D0 NaN
1 A1 B1 C1 D1 NaN
2 A2 B2 C2 D2 F2
3 A3 B3 C3 D3 F3
4 NaN B4 NaN D4 F4
5 NaN B5 NaN D5 F5
'''在使用完cancat和merge函数时,索引会重复或者达不到想要的效果,就可以使用reset_index函数或者set_index函数。
- reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=''):重置行索引名,并且新加了index列。1.level:可以是int, str, tuple, or list, default None等类型。作用是只从索引中删除给定级别。默认情况下删除所有级别;2.drop:bool, default False。不要尝试在数据帧列中插入索引。这会将索引重置为默认的整数索引;3.inplace:bool, default False。修改数据帧(不要创建新对象);4.col_level:int or str, default=0,如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一层;5.col_fill:object, default。如果列有多个级别,则确定其他级别的命名方式。如果没有,则复制索引名称;6.返回:DataFrame or None。具有新索引的数据帧,如果inplace=True,则无索引;
- set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False):将某一列设为索引名。append添加新索引;drop为False,inplace为True时,索引将会还原为列。
import pandas as pd
index1 = [0, 1, 2, 3]
data1 = {
'A': ["A0", "A1", "A2", "A3"],
'B': ["B0", "B1", "B2", "B3"],
'C': ["C0", "C1", "C2", "C3"],
'D': ["D0", "D1", "D2", "D3"],
}
d1 = pd.DataFrame(data=data1, index=index1)
print(d1)
'''
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
'''
# 修改行索引
d1.index = ('行' + str(i) for i in range(4))
d1.columns = ('列' + i for i in ['A', 'B', 'C', 'D'])
print(d1)
'''
列A 列B 列C 列D
行0 A0 B0 C0 D0
行1 A1 B1 C1 D1
行2 A2 B2 C2 D2
行3 A3 B3 C3 D3
'''
print(d1.reset_index()) # 重置行索引名,并且新加了index列
'''
index 列A 列B 列C 列D
0 行0 A0 B0 C0 D0
1 行1 A1 B1 C1 D1
2 行2 A2 B2 C2 D2
3 行3 A3 B3 C3 D3
'''
print(d1.set_index('列A')) # 将列A那一列设置为行索引名
'''
列B 列C 列D
列A
A0 B0 C0 D0
A1 B1 C1 D1
A2 B2 C2 D2
A3 B3 C3 D3
'''5.3.5 数据处理
我理解的数据处理“三步走”:拿到数据需要对数据进行数据清洗的到我们希望的数据,接着进行数据转换,转换成真正的目标数据之后,进行数据分析。
对有些方法中axis参数的理解(Pandas中关于axis参数的理解 - 知乎这篇文章解释的很清楚):
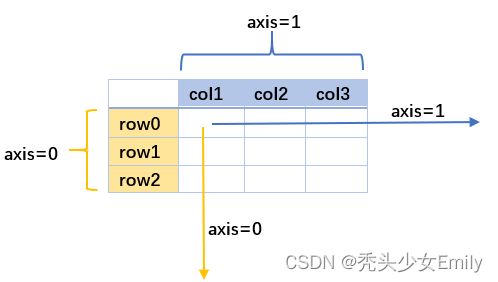
- axis = 0,指的就是跨行,也就是沿着行index垂直向下执行,有点index所在的那一列的味道
- axis = 1,指的是跨列,也就是沿着列名水平方向执行,index=某个值的那一行,比如index=row0那一行
但是如果在操作中指定了某个index名或某个conlumns名,它就不会跨行(axis=0)或跨列(axis=1)。
(1)数据清洗
| 方法 | 说明 |
| isnull() | 用于判空值 |
| notnull() | 用于判空值 |
| dropna() |
删除空值。axis:默认为0或者index(作用于列),1或者columns(作用于行);how:{‘any’,‘all’},默认为any指缺失的所有行,all指清楚全是缺失值;thresh:int,保留含有int个非空值的行;subset:对特定的列进行缺失值处理;inplace:True表示直接在原数据上更改 |
| fillna(value=None, method=None, axis=None, | inplace:True:直接修改原对象,False:创建一个副本,修改副本,原对象不变(默认值);method:{‘pad’,‘ffill’,‘backfill’,‘bfill’,None},默认为None。pad/ffill:用前一个非缺失值取填充该缺失值,backfill/bfill:用下一个非缺失值填充该缺失值,None:指定一个值去替换缺失值;limit:限制填充个数;axis:修改填充方向,默认为0或者index(作用于列),1或者columns(作用于行) |
| duplicated(subset=None, keep='first') | 找出重复的数据,根据布尔值显示是否重复。subset:用于识别重复的列标签或列标签序列,默认所有列标签;keep='first':除了第一个出现外,其余相同的被标记为重复、keep='last':除了最后一个出现外,其余相同的被标记为重复、keep=False:所有相同的被标记为重复 |
| drop_duplicates(subset=None, keep='first',inplace=False) | 删除重复的数据。subset:用于识别重复的列标签或列标签序列,默认所有列标签;keep='first':除了第一个出现外,其余相同的被标记为重复、keep='last':除了最后一个出现外,其余相同的被标记为重复、keep=False:所有相同的被标记为重复 |
| drop(labels, axis=0, level=None, inplace=False, error='raise) | 删除某行某列数据。labels:标签或列表;columns:列名;axis:默认为0或者index(作用于列),1或者columns(作用于行) |
| replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad', axis=None) | 替换全部或某一行的值 |
(2)数据转换
| 方法 | 说明 |
| apply(func, raw=False, result_type=None, arges=(),**kwds) | func:传入的函数或lambda表达式;axis:0(index)作用于列,1(columns)作用于行;raw:默认False,表示把每列行或列作为Sereis传入函数中,True则表示接受的时ndarray数据类型;result_type:返回值为Series或DataFrame沿数据的给定轴应用func的结果 |
| transform(func, axis=0, **kwargs) | 对DataFrame对象行列处理 |
| applymap() | 参数为一个函数,函数会作用于DataFrame中的每一个元素 |
| get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False) | 将分类变量转换为虚拟/指标变量。data:arrat-like/series/DataFrame;prefix:string/list of strings/dic of strings/default None;columns:list-like,默认为None,指定需要实现类别转换的列名;dummy_na:默认为False,增加一列表示空缺值,如果False就忽略空缺值;drop_first:默认值为False,获得k中的k-1个类别值,去掉第一个 |
(3)数据分析
| 方法 | 说明 |
| sum() | 求和 |
| mean() | 求平均值 |
| max() | 求最大值 |
| min() | 求最小值 |
| count() | 计数 |
| std() | 求标准差 |
| var() | 求方差 |
| median() | 求中位数 |
| describe() | 可以获得上述所有的描述性统计信息,如方差,标准差,中位数等,同时对于某一特定的值,也可以通过索引的方式获得 |
| value_counts() | 可以统计每个值重复的次数并返回一个Series对象。它的索引就是原来的Series对象中的值,而每个值出现的次数就是返回的Series对象中的数据,在默认情况下会按照出现次数做降序排列 |
| unique() | 如果Series对象有重复的值,使用unique()方法获得去重之后的Series对象,返回的是一个值的列表 |
| sort_values() | 对值进行排序,ascending参数用来控制升序还是降序,默认False为升序;kind参数控制排序算法:默认为quicksort,还有mergesort/heapsort;na_position参数:空值放在前还是在后,默认last |
| nlargest() | 找出元素中最大的“Top-N” |
| nsmallest() | 找出元素中最小的“Top-N” |
| groupby() | 分组。常用参数:by,分组字段,可以是列名/series/字典/函数;axis,指定切分方向,默认为0或者index(作用于列),1或者columns(作用于行);as_index,是否将分组列名作为输出的索引,默认为True,当设置为False时相当于reset_index功能;sort,与SQL中的groupby操作默认执行排序一致,也可以通过sort参数指定是否对输出结果按索引排序 |
| pivot_table() | 生成透视表,根据A列对B列进行统计 |
有些方法在前面Series讲过,用法差不多就不举例子了。
举例子:
- apply():这个函数作用范围很广非常灵活,最常用的三处,:1.需要对每条记录进行遍历去函数计算出一个值;2.需要对某一列进行相关操作,比如求和;3.利用groupby方法后,对每个group后的列表进行操作
(详细了解apply()的作用我觉得可以看看这两篇博客:pandas 的apply() 函数 - xujiale - 博客园、如何在Pandas中使用Apply方法 - 简书)
import pandas as pd
# 统计每个同学的总分
def sum_score(e, m, p, o):
return e + m + p + o
df = pd.read_csv(r'test.csv', encoding='utf-8')
print(df)
'''
姓名 年龄 学号 英语 数学 Python 面向对象
0 aaa 18 101 90 80 90 85
1 bbb 18 102 62 90 85 88
2 ccc 19 103 85 87 75 98
3 ddd 18 104 75 65 65 69
4 eee 18 105 86 63 88 78
5 fff 19 106 74 84 96 86
6 ggg 19 107 60 60 67 66
7 hhh 18 108 76 95 78 70
'''
# 统计每个学科的总分
print(df[['英语', '数学', 'Python', '面向对象']].apply(lambda x: x.sum()))
'''
英语 608
数学 624
Python 644
面向对象 640
dtype: int64
'''
# axis=1表示跨列,也就是统计每一行
print(df.apply(lambda x: sum_score(x['英语'], x['数学'], x['Python'], x['面向对象']), axis=1))
'''
0 345
1 325
2 345
3 274
4 315
5 340
6 253
7 319
dtype: int64
'''
# 应用于Series数据
print(df['数学'].apply(lambda x: x * 2))
'''
0 160
1 180
2 174
3 130
4 126
5 168
6 120
7 190
Name: 数学, dtype: int64
'''- get_dummies()
import pandas as pd
df1 = pd.DataFrame({'A': ['a', 'b', 'a'], 'B': ['b', 'a', 'c'],
'C': [1, 2, 3]})
print(df1)
print(pd.get_dummies(df1, prefix=['col1', 'col2']))
# 把要虚拟的字符串列换成col1_字符串值,比如col1_a。以此类推形成一个矩阵,但数字列不动
'''
A B C
0 a b 1
1 b a 2
2 a c 3
C col1_a col1_b col2_a col2_b col2_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
2 3 1 0 0 0 1
'''- groupby()
import pandas as pd
df = pd.read_csv(r'test.csv', encoding='utf-8')
print(df)
print(df.groupby(['学号']).英语.sum())
'''
学号
101 90
102 62
103 85
104 75
105 86
106 74
107 60
108 76
Name: 英语, dtype: int64
'''从Python数据分析从小白到专家_百度百科、pandas中Series的使用_菜鸟长安的博客-CSDN博客_pandas series、Pandas的应用---Series_Yi Ian的博客-CSDN博客_pandas series
Pandas的应用---DataFrame_Yi Ian的博客-CSDN博客_pandasdataframe上学习到的一些知识!