训练 open-mmlab/mmclassification
代码下载:
github:
https://github.com/open-mmlab/mmclassification
确定模型 resnet18
点击configs->resnet18_8*b32_in1k.py
 说明:
说明:
模型文件:
base/models/resnet18.py
文件位置:在config/base/models/resnet18.py
数据处理文件:
base/datasets/imagenet_bs32.py
文件位置:在config/base/datasets/imaget_bs32.py
策略文件:
…/base/schedules/imagenet_bs256.py
文件位置在:
configs_base_\schedules\imagenet_bs256.py
基本配置文件:
…/base/default_runtime.py
文件路径:configs_base_\default_runtime.py
resnet.py`
# model settings
model = dict(
type='ImageClassifier',
backbone=dict(
type='ResNet',
depth=18,
num_stages=4,
out_indices=(3, ),
style='pytorch'),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='LinearClsHead',
num_classes=1000,
in_channels=512,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
topk=(1, 5),
))
训练模型:
参数设置:tools/train.py下面
将
C:\Users\ASUS\PycharmProjects\Torch\damo1\mmclassification\configs\resnet\resnet18_8xb32_in1k.py
复制到
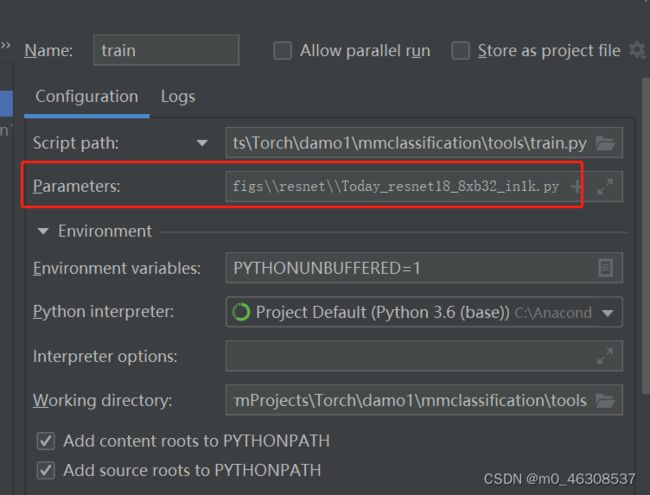 借着run train.py
借着run train.py
同时打开 tools/work_dirs/resnet18_8xb32_in1k.py
将这个文件复制到config/resent/resnet18_8xb32_in1k_0923.py
修改resnet18_8xb32_in1k——0923.py
model = dict(
type='ImageClassifier',
backbone=dict(
type='ResNet',
depth=18,
num_stages=4,
out_indices=(3, ),
style='pytorch'),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='LinearClsHead',
num_classes=102,#修改成自己种类
in_channels=512,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
topk=(1, 5)))
dataset_type = 'ImageNet'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', size=224),
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]
data = dict(
samples_per_gpu=32,
workers_per_gpu=2,
train=dict(
type='Mydatasets',#修改成自己的类名
data_prefix='../mmcls/data/train_filelist', #修改成自己的路径
ann_file=r'../mmcls/data/train.txt', #修改成自己的路径
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', size=224),
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label'])
]),
val=dict(
type='Mydatasets',
data_prefix='../mmcls/data/val_filelist',
ann_file=r'../mmcls/data/val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]),
test=dict(
type='Mydatasets',
data_prefix='../mmcls/data/val_filelist',
ann_file=r'../mmcls/data/val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]))
evaluation = dict(interval=1, metric='accuracy')
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
lr_config = dict(policy='step', step=[30, 60, 90])
runner = dict(type='EpochBasedRunner', max_epochs=100)
checkpoint_config = dict(interval=50)
log_config = dict(interval=100, hooks=[dict(type='TextLoggerHook')])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
work_dir = './work_dirs/resnet18_8xb32_in1k'
# work_dir = './work_dirs/resnet18_8xb32_in1k'
gpu_ids = [0]
数据准备
数据格式为:
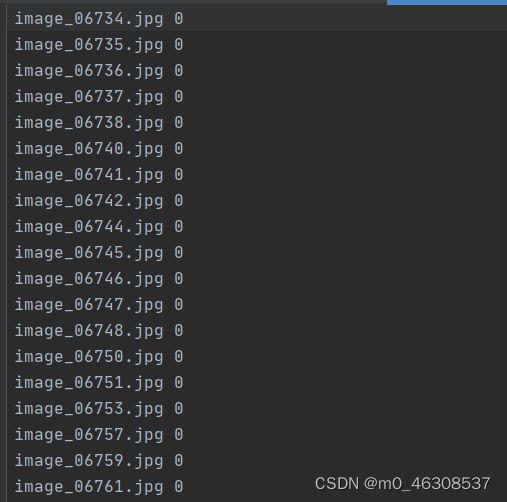
 数据格式生成代码
数据格式生成代码
import numpy as np
import os
import shutil
train_path = './train'
train_out = './train.txt'
val_path = './valid'
val_out = './val.txt'
data_train_out = './train_filelist'
data_val_out = './val_filelist'
def get_filelist(input_path,output_path):
with open(output_path,'w') as f:
for dir_path,dir_names,file_names in os.walk(input_path):
if dir_path != input_path:
label = int(dir_path.split('\\')[-1]) -1
#print(label)
for filename in file_names:
f.write(filename +' '+str(label)+"\n")
def move_imgs(input_path,output_path):
for dir_path, dir_names, file_names in os.walk(input_path):
for filename in file_names:
#print(os.path.join(dir_path,filename))
source_path = os.path.join(dir_path,filename)
shutil.copyfile(source_path, os.path.join(output_path,filename))
get_filelist(train_path,train_out)
get_filelist(val_path,val_out)
move_imgs(train_path,data_train_out)
move_imgs(val_path,data_val_out)
借着重点制作自己的读取文件## 标题

 在mmcls下面新建一个文件mydatasets.py文件
在mmcls下面新建一个文件mydatasets.py文件
import numpy as np
from .builder import DATASETS
from .base_dataset import BaseDataset
@DATASETS.register_module()
class Mydatasets(BaseDataset):
CLASSES = [
'rule, ruler',
'running shoe',
'safe',
'safety pin',
'saltshaker, salt shaker',
'sandal',
'sarong',
'sax, saxophone',
'scabbard',
'scale, weighing machine',
'school bus',
'schooner',
'scoreboard',
'screen, CRT screen',
'screw',
'screwdriver',
'seat belt, seatbelt',
'sewing machine',
'shield, buckler',
'shoe shop, shoe-shop, shoe store',
'shoji',
'shopping basket',
'shopping cart',
'shovel',
'shower cap',
'shower curtain',
'ski',
'ski mask',
'sleeping bag',
'slide rule, slipstick',
'sliding door',
'slot, one-armed bandit',
'snorkel',
'snowmobile',
'snowplow, snowplough',
'soap dispenser',
'soccer ball',
'sock',
'solar dish, solar collector, solar furnace',
'sombrero',
'soup bowl',
'space bar',
'space heater',
'space shuttle',
'spatula',
'speedboat',
"spider web, spider's web",
'spindle',
'sports car, sport car',
'spotlight, spot',
'stage',
'steam locomotive',
'steel arch bridge',
'steel drum',
'stethoscope',
'stole',
'stone wall',
'stopwatch, stop watch',
'stove',
'strainer',
'streetcar, tram, tramcar, trolley, trolley car',
'stretcher',
'studio couch, day bed',
'stupa, tope',
'submarine, pigboat, sub, U-boat',
'suit, suit of clothes',
'sundial',
'sunglass',
'sunglasses, dark glasses, shades',
'sunscreen, sunblock, sun blocker',
'suspension bridge',
'swab, swob, mop',
'sweatshirt',
'swimming trunks, bathing trunks',
'swing',
'switch, electric switch, electrical switch',
'syringe',
'table lamp',
'tank, army tank, armored combat vehicle, armoured combat vehicle',
'tape player',
'teapot',
'teddy, teddy bear',
'television, television system',
'tennis ball',
'thatch, thatched roof',
'theater curtain, theatre curtain',
'thimble',
'thresher, thrasher, threshing machine',
'throne',
'tile roof',
'toaster',
'tobacco shop, tobacconist shop, tobacconist',
'toilet seat',
'torch',
'totem pole',
'tow truck, tow car, wrecker',
'toyshop',
'tractor',
'trailer truck, tractor trailer, trucking rig, rig, articulated lorry, semi', # noqa: E501
'tray',
'trench coat',
'tricycle, trike, velocipede',
'trimaran',
]
def load_annotations(self):
assert isinstance(self.ann_file, str)
data_infos = []
with open(self.ann_file) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for filename, gt_label in samples:
info = {'img_prefix': self.data_prefix}
info['img_info'] = {'filename': filename}
info['gt_label'] = np.array(gt_label, dtype=np.int64)
data_infos.append(info)
return data_infos

接下来预测
# Copyright (c) OpenMMLab. All rights reserved.
from argparse import ArgumentParser
import mmcv
from mmcls.apis import inference_model, init_model, show_result_pyplot
def main():
parser = ArgumentParser()
parser.add_argument('--img',type=str, default="../mmcls/data/train/49/image_06203.jpg",help='Image file')
parser.add_argument('--config', type=str,default="../configs/resnet/resnet18_8xb32_in1k_0923.py",help='Config file')
parser.add_argument('--checkpoint',type=str,default="../tools/work_dirs/resnet18_8xb32_in1k/epoch_10.pth" ,help='Checkpoint file')
parser.add_argument(
'--show',
default=True,
action='store_true',
help='Whether to show the predict results by matplotlib.')
parser.add_argument(
'--device', default='cuda:0', help='Device used for inference')
args = parser.parse_args()
# build the model from a config file and a checkpoint file
model = init_model(args.config, args.checkpoint, device=args.device)
# test a single image
result = inference_model(model, args.img)
# show the results
print(mmcv.dump(result, file_format='json', indent=4))
if args.show:
show_result_pyplot(model, args.img, result,wait_time=1)
if __name__ == '__main__':
main()
test 测试模型
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os
import warnings
from numbers import Number
import mmcv
import numpy as np
import torch
from mmcv import DictAction
from mmcv.runner import (get_dist_info, init_dist, load_checkpoint,
wrap_fp16_model)
from mmcls.apis import multi_gpu_test, single_gpu_test
from mmcls.datasets import build_dataloader, build_dataset
from mmcls.models import build_classifier
from mmcls.utils import (auto_select_device, get_root_logger,
setup_multi_processes, wrap_distributed_model,
wrap_non_distributed_model)
#配置文件路径:C:\\Users\\ASUS\\PycharmProjects\\Torch\\damo1\\mmclassification\\configs\\resnet\\Today_resnet18_8xb32_in1k.py
#模型路径:C:\\Users\\ASUS\PycharmProjects\\Torch\\damo1\\mmclassification\\tools\\work_dirs\\resnet18_8xb32_in1k\\epoch_100.pth
def parse_args():
parser = argparse.ArgumentParser(description='mmcls test model')
parser.add_argument('--config', type=str,
default='C:\\Users\\ASUS\\PycharmProjects\\Torch\\damo1\\mmclassification\\configs\\resnet\\Today_resnet18_8xb32_in1k.py',
help='Config file')
parser.add_argument('--checkpoint', type=str,
default="C:\\Users\\ASUS\PycharmProjects\\Torch\\damo1\\mmclassification\\tools\\work_dirs\\resnet18_8xb32_in1k\\epoch_100.pth",
help='Checkpoint file')
parser.add_argument('--out', help='output result file')
out_options = ['class_scores', 'pred_score', 'pred_label', 'pred_class']
parser.add_argument(
'--out-items',
nargs='+',
default=['all'],
choices=out_options + ['none', 'all'],
help='Besides metrics, what items will be included in the output '
f'result file. You can choose some of ({", ".join(out_options)}), '
'or use "all" to include all above, or use "none" to disable all of '
'above. Defaults to output all.',
metavar='')
parser.add_argument(
'--metrics',
type=str,
nargs='+',
default=['recall',"mAP"],
help='evaluation metrics, which depends on the dataset, e.g., '
'"accuracy", "precision", "recall", "f1_score", "support" for single '
'label dataset, and "mAP", "CP", "CR", "CF1", "OP", "OR", "OF1" for '
'multi-label dataset')
parser.add_argument('--show', action='store_true', help='show results')
parser.add_argument(
'--show-dir',type=str,default="C:\\Users\\ASUS\\PycharmProjects\\Torch\\damo1\\mmclassification\\val_show",help='directory where painted images will be saved')
parser.add_argument(
'--gpu-collect',
action='store_true',
help='whether to use gpu to collect results')
parser.add_argument('--tmpdir', help='tmp dir for writing some results')
parser.add_argument(
'--cfg-options',
nargs='+',
action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. If the value to '
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
'Note that the quotation marks are necessary and that no white space '
'is allowed.')
parser.add_argument(
'--metric-options',
nargs='+',
action=DictAction,
default={},
help='custom options for evaluation, the key-value pair in xxx=yyy '
'format will be parsed as a dict metric_options for dataset.evaluate()'
' function.')
parser.add_argument(
'--show-options',
nargs='+',
action=DictAction,
help='custom options for show_result. key-value pair in xxx=yyy.'
'Check available options in `model.show_result`.')
parser.add_argument(
'--gpu-ids',
type=int,
nargs='+',
help='(Deprecated, please use --gpu-id) ids of gpus to use '
'(only applicable to non-distributed testing)')
parser.add_argument(
'--gpu-id',
type=int,
default=0,
help='id of gpu to use '
'(only applicable to non-distributed testing)')
parser.add_argument(
'--launcher',
choices=['none', 'pytorch', 'slurm', 'mpi'],
default='none',
help='job launcher')
parser.add_argument('--local_rank', type=int, default=0)
parser.add_argument('--device', help='device used for testing')
args = parser.parse_args()
if 'LOCAL_RANK' not in os.environ:
os.environ['LOCAL_RANK'] = str(args.local_rank)
assert args.metrics or args.out, \
'Please specify at least one of output path and evaluation metrics.'
return args
def main():
args = parse_args()
cfg = mmcv.Config.fromfile(args.config)
if args.cfg_options is not None:
cfg.merge_from_dict(args.cfg_options)
# set multi-process settings
setup_multi_processes(cfg)
# set cudnn_benchmark
if cfg.get('cudnn_benchmark', False):
torch.backends.cudnn.benchmark = True
cfg.model.pretrained = None
if args.gpu_ids is not None:
cfg.gpu_ids = args.gpu_ids[0:1]
warnings.warn('`--gpu-ids` is deprecated, please use `--gpu-id`. '
'Because we only support single GPU mode in '
'non-distributed testing. Use the first GPU '
'in `gpu_ids` now.')
else:
cfg.gpu_ids = [args.gpu_id]
cfg.device = args.device or auto_select_device()
# init distributed env first, since logger depends on the dist info.
if args.launcher == 'none':
distributed = False
else:
distributed = True
init_dist(args.launcher, **cfg.dist_params)
dataset = build_dataset(cfg.data.test, default_args=dict(test_mode=True))
# build the dataloader
# The default loader config
loader_cfg = dict(
# cfg.gpus will be ignored if distributed
num_gpus=1 if cfg.device == 'ipu' else len(cfg.gpu_ids),
dist=distributed,
round_up=True,
)
# The overall dataloader settings
loader_cfg.update({
k: v
for k, v in cfg.data.items() if k not in [
'train', 'val', 'test', 'train_dataloader', 'val_dataloader',
'test_dataloader'
]
})
test_loader_cfg = {
**loader_cfg,
'shuffle': False, # Not shuffle by default
'sampler_cfg': None, # Not use sampler by default
**cfg.data.get('test_dataloader', {}),
}
# the extra round_up data will be removed during gpu/cpu collect
data_loader = build_dataloader(dataset, **test_loader_cfg)
# build the model and load checkpoint
model = build_classifier(cfg.model)
fp16_cfg = cfg.get('fp16', None)
if fp16_cfg is not None:
wrap_fp16_model(model)
checkpoint = load_checkpoint(model, args.checkpoint, map_location='cpu')
if 'CLASSES' in checkpoint.get('meta', {}):
CLASSES = checkpoint['meta']['CLASSES']
else:
from mmcls.datasets import ImageNet
warnings.simplefilter('once')
warnings.warn('Class names are not saved in the checkpoint\'s '
'meta data, use imagenet by default.')
CLASSES = ImageNet.CLASSES
if not distributed:
model = wrap_non_distributed_model(
model, device=cfg.device, device_ids=cfg.gpu_ids)
if cfg.device == 'ipu':
from mmcv.device.ipu import cfg2options, ipu_model_wrapper
opts = cfg2options(cfg.runner.get('options_cfg', {}))
if fp16_cfg is not None:
model.half()
model = ipu_model_wrapper(model, opts, fp16_cfg=fp16_cfg)
data_loader.init(opts['inference'])
model.CLASSES = CLASSES
show_kwargs = args.show_options or {}
outputs = single_gpu_test(model, data_loader, args.show, args.show_dir,
**show_kwargs)
else:
model = wrap_distributed_model(
model,
device=cfg.device,
device_ids=[int(os.environ['LOCAL_RANK'])],
broadcast_buffers=False)
outputs = multi_gpu_test(model, data_loader, args.tmpdir,
args.gpu_collect)
rank, _ = get_dist_info()
if rank == 0:
results = {}
logger = get_root_logger()
if args.metrics:
eval_results = dataset.evaluate(
results=outputs,
metric=args.metrics,
metric_options=args.metric_options,
logger=logger)
results.update(eval_results)
for k, v in eval_results.items():
if isinstance(v, np.ndarray):
v = [round(out, 2) for out in v.tolist()]
elif isinstance(v, Number):
v = round(v, 2)
else:
raise ValueError(f'Unsupport metric type: {type(v)}')
print(f'\n{k} : {v}')
if args.out:
if 'none' not in args.out_items:
scores = np.vstack(outputs)
pred_score = np.max(scores, axis=1)
pred_label = np.argmax(scores, axis=1)
pred_class = [CLASSES[lb] for lb in pred_label]
res_items = {
'class_scores': scores,
'pred_score': pred_score,
'pred_label': pred_label,
'pred_class': pred_class
}
if 'all' in args.out_items:
results.update(res_items)
else:
for key in args.out_items:
results[key] = res_items[key]
print(f'\ndumping results to {args.out}')
mmcv.dump(results, args.out)
if __name__ == '__main__':
main()
细节展示
预处理模型下载
https://github.com/open-mmlab/mmclassification/tree/master/configs/resnet
在imageNET-1中找到
配置文件
model = dict(
type='ImageClassifier',
backbone=dict(
type='ResNet',
depth=18,
num_stages=4,
out_indices=(3, ),
style='pytorch'),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='LinearClsHead',
num_classes=102,#修改成自己种类
in_channels=512,
#损失函数可以自定义为我们自己的损失函数
'''
具体操作步骤
在mmcls/loss
添加my_loss
具体代码如下
import torch
import torch.nn as nn
from ..builder import LOSSES
from .utils import weighted_loss
@weighted_loss
def l1_loss(pred, target):
target = nn.functional.one_hot(target,num_classes=102)
# print(f"损失函数种目标的种类为:{torch.max(target, 1)[0]}")
# print(f"损失函数种目标的种类为:{pred.max(pred, 1)[0]}")
assert pred.size() == target.size() and target.numel() > 0
loss = torch.abs(pred - target)
return loss
@LOSSES.register_module()
class L1Loss(nn.Module):
def __init__(self, reduction='mean', loss_weight=1.0):
super(L1Loss, self).__init__()
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None):
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
loss = self.loss_weight * l1_loss(
pred, target, weight, reduction=reduction, avg_factor=avg_factor)
return loss
紧接着在__init__.py
#todo
# Copyright (c) OpenMMLab. All rights reserved.
from .My_loss import L1Loss
__all__ = [
'L1Loss'
]
'''
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
topk=(1, 5)),
#这里可以根据相应的配置文件进行修改 例如先找到
'''
先找到config/resnet
代码如下
_base_ = [
'../_base_/models/resnet50_mixup.py',
'../_base_/datasets/imagenet_bs32.py',
'../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
]
紧接着在config/__base__/models/resnet50_mixup.py
代码如下
# model settings
model = dict(
type='ImageClassifier',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(3, ),
style='pytorch'),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='MultiLabelLinearClsHead',
num_classes=1000,
in_channels=2048,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0, use_soft=True)),
train_cfg=dict(
augments=dict(type='BatchMixup', alpha=0.2, num_classes=1000,
prob=1.)))
最后发现train_cfg有用
'''
train_cfg=dict(
augments=dict(type='BatchMixup', alpha=0.2, num_classes=102,
prob=1.))
)
dataset_type = 'ImageNet'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', size=224),
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(type='ColorJitter', brightness=0.5, contrast=0.5,saturation=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]
data = dict(
samples_per_gpu=64,
workers_per_gpu=2,
train=dict(
type='Mydatasets',#修改成自己的类名
data_prefix='../mmcls/data/train_filelist', #修改成自己的路径
ann_file=r'../mmcls/data/train.txt', #修改成自己的路径
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', size=224),
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label'])
]),
val=dict(
type='Mydatasets',
data_prefix='../mmcls/data/val_filelist',
ann_file=r'../mmcls/data/val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]),
test=dict(
type='Mydatasets',
data_prefix='../mmcls/data/val_filelist',
ann_file=r'../mmcls/data/val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]))
evaluation = dict(interval=1, metric='accuracy')
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
lr_config = dict(policy='step', step=[30, 60, 90])
runner = dict(type='EpochBasedRunner', max_epochs=100)
checkpoint_config = dict(interval=10)
log_config = dict(interval=10, hooks=[dict(type='TextLoggerHook')])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = '../mmcls/data/resnet18_8xb32_in1k_20210831-fbbb1da6.pth'
resume_from = None
workflow = [('train', 1)]
work_dir = './work_dirs/resnet18_8xb32_in1k'
# work_dir = './work_dirs/resnet18_8xb32_in1k'
gpu_ids = [0]