深度学习-多分类问题- Softmax Classifier-自用笔记8
深度学习-多分类问题 -Softmax Classifier-自用笔记8
回顾上一讲我们讲的手动加载文件中的糖尿病数据集的二分类的问题
https://blog.csdn.net/qq_42764492/article/details/112750673
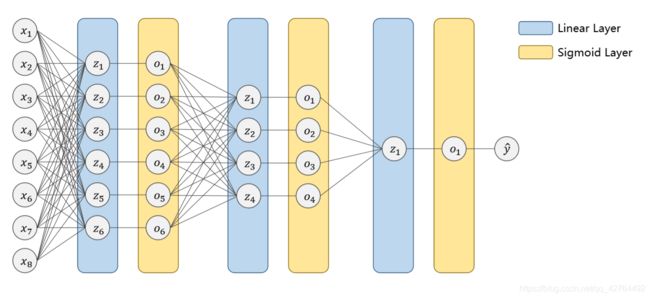
糖尿病数据集一共有8个feature,输出的y^为是糖尿病的概率p
训练了一个模型如下图:
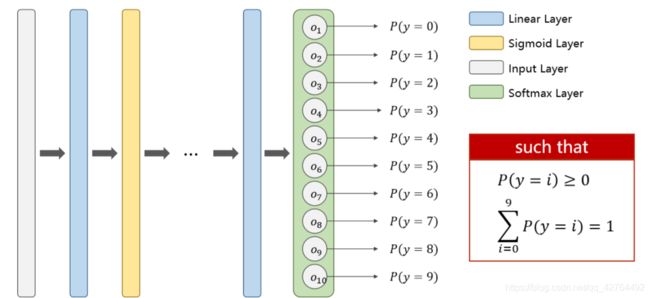
基于MNIST Dataset介绍多分类的Softmax
There are 10 labels in MNIST dataset,Output a Distribution of prediction with Softmax
最后一层输出用Softmax来输出十个类的每个类的概率值
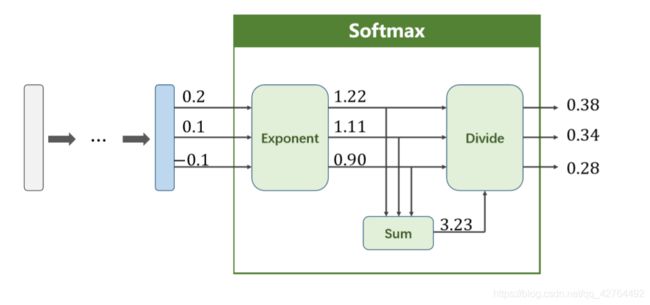
Softmax激活函数的计算公式和计算过程图

基于MNIST Dataset介绍多分类的Loss function - Cross Entropy交叉熵损失函数
方法一:
将Softmax激活函数的计算结果取对数在送入NLLLoss得出损失函数
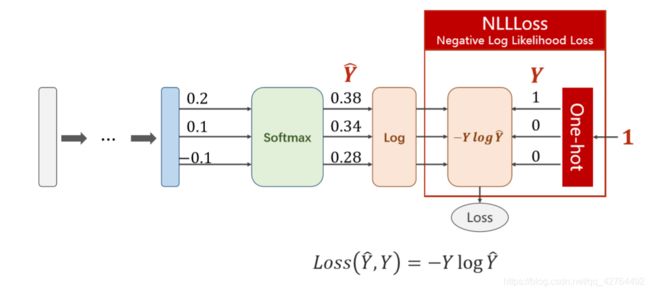
下图有一个简单的例子
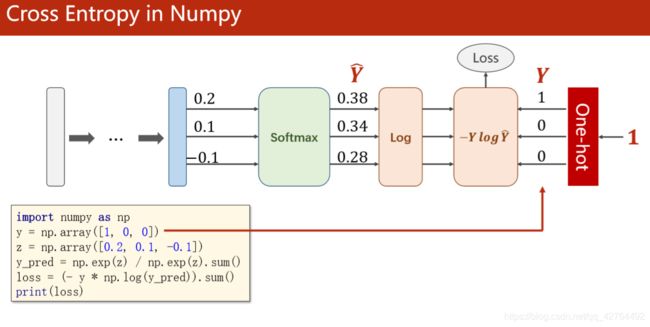
方法二:
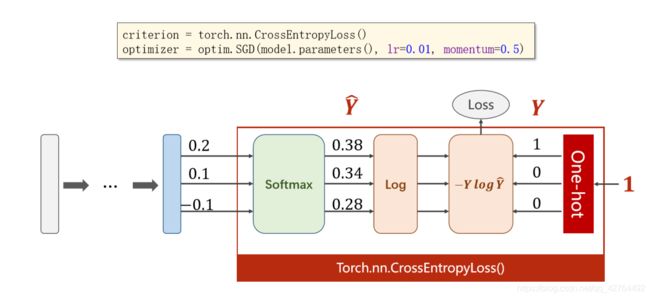
又因为pytorch中有一个函数将Softmax、log、NLLLoss这些计算过程都封装在一个函数中Torch.nn.CrossEntropyLoss()
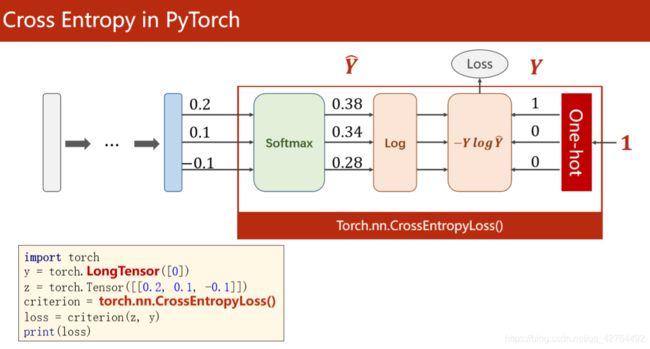
如上图,先取最后一层的的输出函数的值改为tensor类型,然后再将分类定义为LongTensor类型
举例子
Y有三个样本,第一个样本是第二类,第二个样本是第0类,第三个样本是第1类

CrossEntropyLoss vs NLLLoss
• What are the differences?
• Reading the document:
• https://pytorch.org/docs/stable/nn.html#crossentropyloss
• https://pytorch.org/docs/stable/nn.html#nllloss
• Try to know why:
• CrossEntropyLoss <==> LogSoftmax + NLLLoss
基于MNIST Dataset介绍多分类的实现程序
每一张照片都是一个通道,28 ∗ 28 = 784个像素点,像素值为0-256,经过映射到0-1之间

- Import Package
- Prepare Dataset
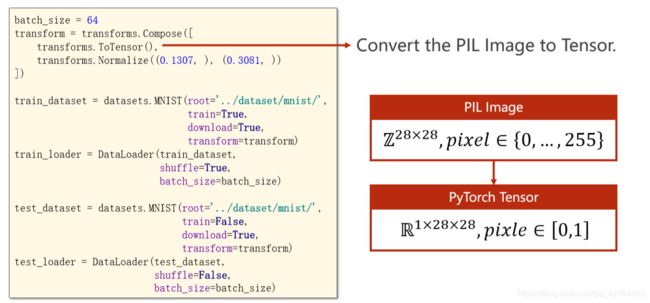

- Design Model


- Construct Loss and Optimizer
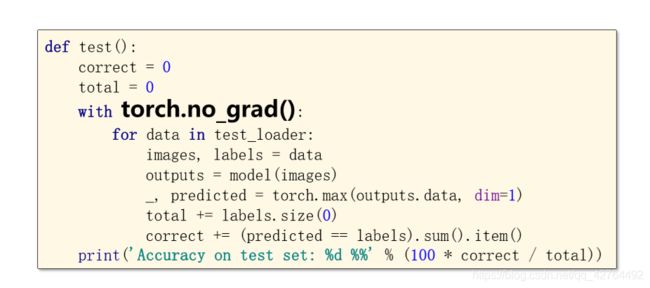
- Train and Test

- 调用

代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),#将0-256的像素值的图片格式类型转换成tensor类型
transforms.Normalize((0.1307, ), (0.3081, ))#将0-256的数值映射到0-1的数值,0.1307代表均值,0.3081代表平方差
])
train_dataset = datasets.MNIST(root='F:\实验室\刘二老师\dataset\mnist',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='F:\实验室\刘二老师\dataset\mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
print_hi('plant electricity')
for epoch in range(10):
train(epoch)
#if epoch % 10 == 9:
test()