机器学习基础概念总结
入门概念:
1、首先什么是机器学习?
人工智能包含机器学习,机器学习又包含深度学习,机器学习是人工智能的一个实现途径,深度学习是机器学习的一个方法发展而来。机器学习就是试图替代或者辅助人的智能行为。
2、机器学习的应用
- 传统预测
- 图像识别
- 自然语言处理
3、机器学习算法的理解
简单来说就是一种能够从数据中学习的算法
4、机器学习中向量的理解
可以简单地把向量理解成一维数组。
5、机器学习分类任务中的“精度”概念:
精度就是正确分类的数据和全部分类数据的比值。
机器学习分类任务中的“错误率”概念:
错误分类数据在全部数据中的比值。错误率也叫做“0-1损失期望”
6、查准率与查全率:
查准率:分类器预测的对的数据中,真正正确的数据所占的比率。
查全率:在所有真正正确的数据中,分类器预测出的对的数据所占的比率。
7.1、什么是监督学习:
试图将已知数据与该数据所对应的标记或类标(label)进行关联。
7.2、什么是非监督学习:
生活中的数据绝大部分是没有标记的,并且也缺少成本去标记数据。非监督学习就是在没有指导的前提下,学习数据集内部有用的结构。
为了统一描述,我们会将数据集称为数据矩阵,也可以简单的想象为二维矩阵,矩阵的列表示数据的不同特征,矩阵的行表示不同数据
绝大多数机器学习算法学习的过程,就是在调整数据特征的重要性,我们将这种刻画重要性的量称为“参数或权重”,参数控制机器学习系统的行为,我们要做的就是找到一组最优参数。
—————————————————————————————————
8、代价函数(损失函数)
衡量机器学习算法“预测值”与“实际值”之间误差的函数就是代价函数,也可以叫损失函数。
—————————————————————————————————
常见的两种代价函数:
- 均方误差函数
假设需要完成一个房屋价格预测任务:

在其中涉及:特征、机器学习算法、代价函数这些概念,要结合理解。
- 极大似然估计(最大可能性)

———————————————————————————————
代价函数既然是真实值和预测值之间的误差,那么我们只需要找到一组可以让代价函数取最小值的参数即可。又因为代价函数一定存在最小值,那么只需要函数的切线斜率为零的点,即代价函数导数为0的点,就是最小值点。
—————————————————————————————————
9、梯度下降算法
梯度下降法是用来计算函数最小值的。它的思路就是,在山顶放一个球,一松手他就会顺着山坡最陡峭的地方滚落到谷底。
在机器学习问题中,基本上都是基于特定的损失函数,来迭代优化这个函数值,既然是损失函数,代表的是损失的多少,所以通常是寻找最小值,梯度下降法在机器学习中即是一种不断寻找函数极值点的方法,
详细解释链接
重要解释说明:
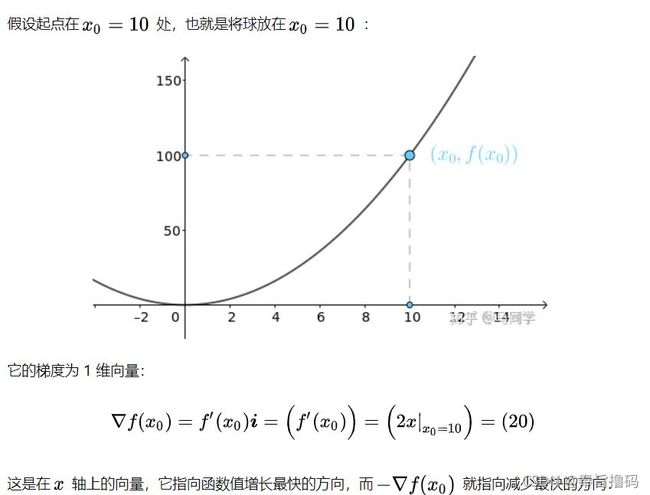
梯度:就是某个点对应的导数值
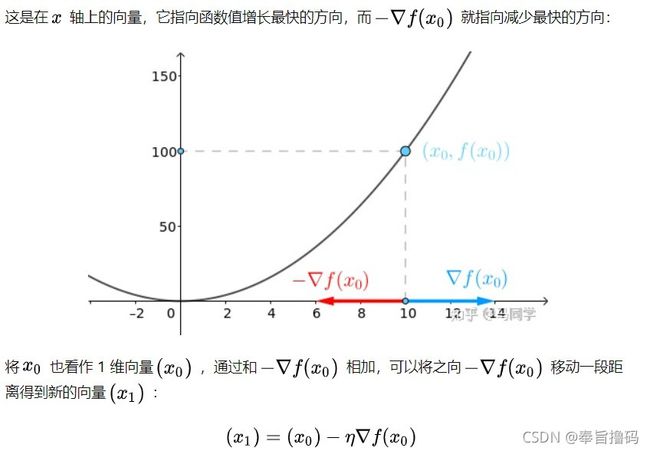
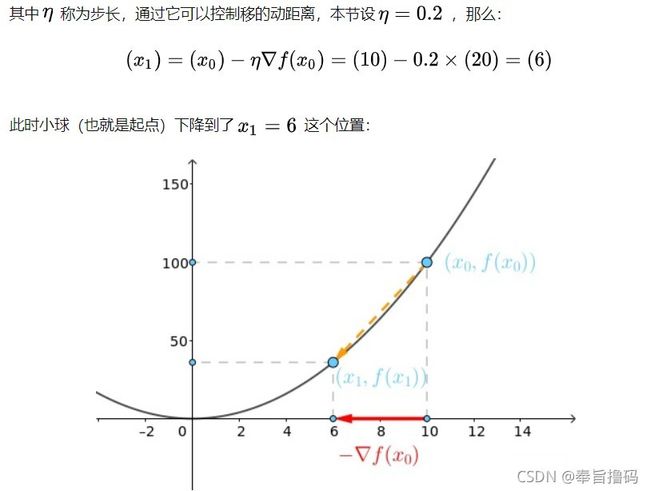
梯度下降:是指让x轴上的点通过减去前一个点的导数值(梯度)与步长的乘积找到下一个接近最小值对应的x坐标点。


'''
给定数据集X={x(1),x(2),x(3),...x(n)},这里x(i)中包含3个特征x1,x2,x3。数据集标记Y={y(1),y(2),y(3),...y(n)}
学习器f(x;w)=w1x1+w2x2,学习步长为α。
for(足够多次循环):
wi=wi+α1/m求和公式(y(j)-f(x(j);w))x(i,j)
'''
9.1、批量梯度下降算法:
详细解释批量梯度算法(不完美)
随机梯度下降算法:
梯度下降算法大全
—————————————————————————————————
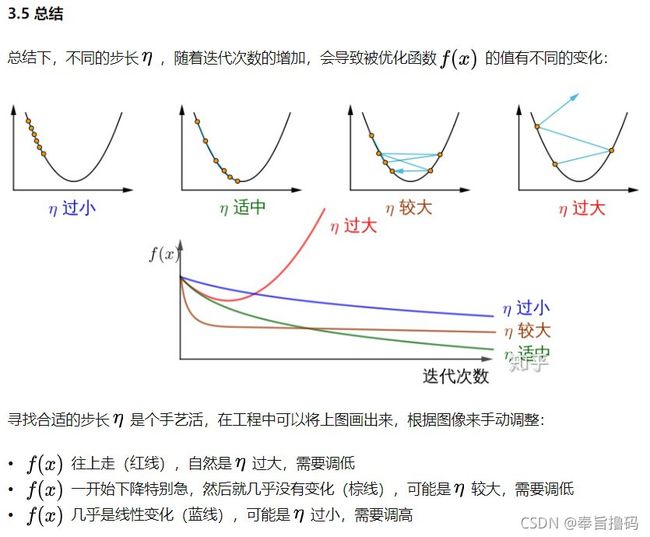
关于梯度下降算法的理解:
梯度下降算法其实就是针对高维函数不太容易求导而设计的求解函数最小值的方法。代价函数就是设计好的算法得到的预测值与真实值之间的误差之和,我们要使代价函数最小,就要通过合适的梯度下降算法来迭代多次,不断更新设计好的算法(学习器)中的不同特征对应的权重。然后找到代价函数取最小值时候的权重。
对于批量梯度下降在每次更新时用所有样本,要留意,在梯度下降中,对于 权值的更新,所有的样本都有贡献,也就是参与调整 .其计算得到的是一个标准梯度,对于最优化问题,凸问题,也肯定可以达到一个全局最优。因而理论上来说一次更新的幅度是比较大的。如果样本不多的情况下,当然是这样收敛的速度会更快啦。但是很多时候,样本很多,更新一次要很久,这样的方法就不合适啦。
总的来说,随机梯度下降一般来说效率高,收敛到的路线曲折,但一般得到的解是我们能够接受的,在深度学习中,用的比较多的是mini-batch梯度下降。
—————————————————————————————————10、过拟合与欠拟合
泛化能力:
机器学习的核心是在新的未知的数据中执行得好,这种在未知数据中执行的能力,我们称为泛化能力。
训练集:
训练机器学习模型所使用的数据集称为训练集。
训练错误
使用训练集产生的错误。
测试集:
用于测试的数据集。
测试错误(泛化错误):
在测试数据上的误差,机器学习的目的就是降低泛化错误。
当机器学习算法在训练数据上错误率较高,我们说这是欠拟合现象,当机器学习算法在测试错误率与训练错误率上差距较大时,我们就说是过渡拟合现象。
模型的能力
就是拟合各种函数的能力
假设空间
控制算法中可以使用的函数的数量。
什么是没有免费午餐理论?
答:这个理论说明所有可能的数据分布,所有分类算法在未知数据中都有着相同的错误率。但是这个理论说的是所有情况下的平均性能,在特定任务中,特定的算法会比较优秀。所以机器学习的目标不是寻找通用的学习算法,而是寻找我们关心的特定领域的特定算法。
—————————————————————————————————
—————————————————————————————————
总结
1、什么是机器学习?
答:机器学习粗浅理解就是通过一些优化手段去调整数据权重w(参数);梯度下降算法中的学习率α(步长)和正则化中权重衰减的惩罚因子λ,都对机器学习算法的最终性能产生着巨大影响,在学习过程中要不停地调整学习率与惩罚因子,从而找到最佳权重w。
2、什么是超参数?
答:学习率(步长)和惩罚因子可以帮我们找到最佳权重,所以这些设置就叫做超参数。
注意:参数和超参数都需要调整,但是参数调整叫做“学习”,超参数的调整叫做“选择”。一般情况在训练数据集中不修改超参数。
简单来说,我们将已知数据分成两大部分,一部分用于学习参数,我们称为训练数据集;一部分用于选择超参数,我们称为验证数据集。最终性能测试的数据,称为测试数据集。例如:老师让:a同学、b同学、c同学都学习爬树,他们使用同一棵树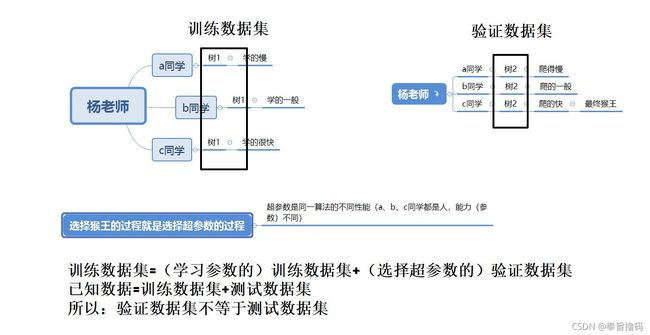
要记住:验证数据是帮助我们选择超参数的,80%数据用于训练,20%数据用于验证,当配置出了最佳的超参数时,再用测试数据集去验证训练结果。
3、什么是K折交叉验证?
有时候我们机器学习的算法性能挺好,但是由于验证数据的问题,导致训练数据结果和验证数据结果偏差很大。所以产生了K折交叉验证。
第一步:将数据分割成k组大小相同的数据集。
第二步:然后用第1组验证数据,先试用2~k组数据训练;
第三步:使用第2组验证数据,其余k-1组数据训练;
第四步:一直遍历,直到所有小组都做过验证数据;
第五步:将这k组数据的错误率取平均值。