Python SVM分类器 XGBOOST分类器 文本情绪分析
Python SVM分类器 XGBOOST分类器 文本情绪分析 微博网民情绪识别比赛
目录
Python SVM分类器 XGBOOST分类器 文本情绪分析 疫情期间网民情绪识别比赛
一:比赛相关事项
二:使用工具PyCharm配合Anaconda3
三:文本处理
四:分类器使用
几个月前数据挖掘实验室的老师向我们介绍了这个比赛,选出了两个人去参加比赛,算是简单的了解下文本分类。
我和我的队友在比赛中尝试了了SVM分类器,XGBOOST分类器以及CNN卷积神经网络,其中我负责的工作是SVM分类器以及XGBOOST分类器。
比赛的A榜在2020.4.30结束A榜提交,在这里先Mark一下自己的思路,以后应该会用得到。
一:比赛相关事项
暂无
1.题目要求
给定微博ID和微博内容,设计算法对微博内容进行情绪识别,判断微博内容是积极的、消极的还是中性的。
2.数据说明
竞赛数据以csv格式进行存储,包括nCoV_100k.labled.csv和nCoV_900k.unlabled.csv两个文件,其中:nCoV_100k.labled.csv:包含10万条用户标注的微博数据,具体格式如下:[微博id,微博发布时间,发布人账号,微博中文内容,微博图片,微博视频,情感倾向]
微博id,格式为整型。
微博发布时间,格式为xx月xx日 xx:xx。
发布人账号,格式为字符串。
微博中文内容,格式为字符串。
微博图片,格式为url超链接,[]代表不含图片。
微博视频,格式为url超链接,[]代表不含视频。
情感倾向,取值为{1,0,-1}。
nCoV_900k.unlabled.csv为90万条未标注的微博数据,包含与“新冠肺炎”相关的90万条未标注的微博数据,具体格式如下:
[微博id,微博发布时间,发布人账号,微博中文内容,微博图片,微博视频]
1.微博id,格式为整型。
2.微博发布时间,格式为xx月xx日 xx:xx。
3.发布人账号,格式为字符串。
4.微博中文内容,格式为字符串。
5.微博图片,格式为url超链接,[]代表不含图片。
6.微博视频,格式为url超链接,[]代表不含视频。
3.数据截图
赛题数据-训练集:train_ dataset.zip
(nCoV_100k_train.labled.csv,nCoV_900k_train.unlabled.csv)
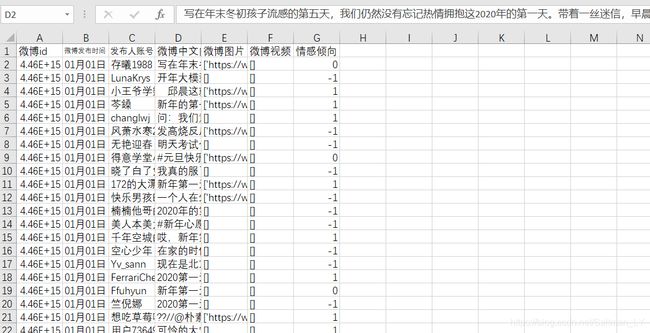
赛题数据-测试集:test_dataset.zip
(nCov_10k_test.csv)
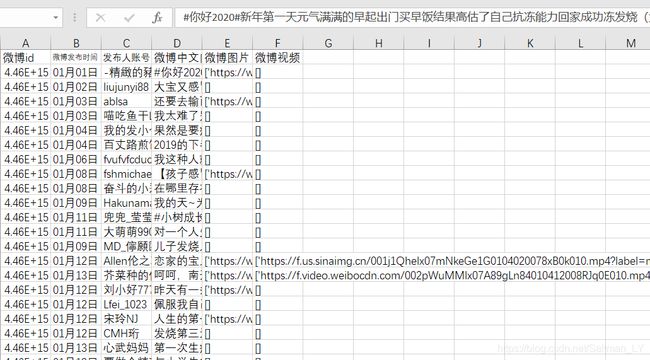
提交样例-提交样例:submit_example.csv
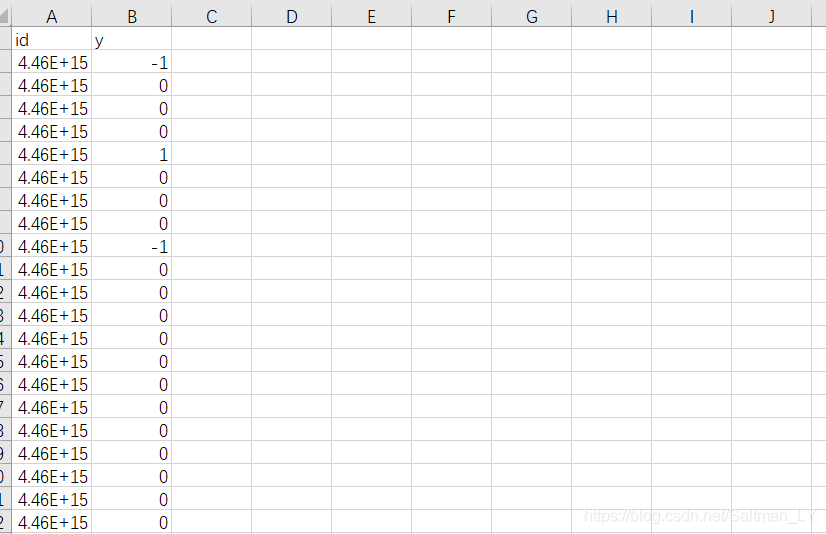
4.数据拿取
由于版权问题无法分享
二:使用工具
PyCharm配合Anaconda3
三:文本处理 (以train.csv为例子)
1.文本分词
文本使用了jieba分词工具,将每条博文去停用词之后分成一个个词语,由队友完成,截图如下。
2.文本数据处理
文本在分词之后有两种处理思路,一种是
(1)对文本使用tfidf(词频-逆文件频率)
将分词后的数据变成稀疏矩阵,然后使用SVM分类器进行训练。
这样只能对文本进行分类预测,微博其他的数据都被忽略了
在这里插入代码片,tfidf处理之后直接训练
# created by LiYing 5/22/2020
import csv
import sys
import datetime
from sklearn import preprocessing
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
import pandas as pd
import time
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import f1_score
from sklearn.preprocessing import StandardScaler
from sklearn import model_selection as ms, preprocessing
#pos=pd.read_csv('D:\\work_Competition\\alldata.csv',index_col=[0],lineterminator='\n')
starttime = datetime.datetime.now()
dataset = pd.read_csv('D:\\work_Competition\\alldata.csv',index_col=[0],encoding='utf-8-sig',lineterminator='\n')
data_samples = dataset['aa\r'] # data_samples是一个string list,'去停用词\r'是表头
# print(data_samples)
# print(data_samples.values)
max_df = 0.8 # 在超过这一比例的文档中出现的关键词(过于平凡),去除掉。
min_df = 3 # 在低于这一数量的文档中出现的关键词(过于独特),去除掉。
# token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b'#后面是正则表达式,剔除数字
tfi=TfidfVectorizer(max_features=1000,max_df = max_df,
min_df = min_df,
token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b')
X = tfi.fit_transform(data_samples.values)#获得稀疏矩阵
term_matrix = pd.DataFrame(X.toarray(), columns=tfi.get_feature_names())
print(term_matrix.head())
print("tfidf yes")
result_label=(dataset)['情感倾向'].values
# 数据归一化处理,scale进行的操作是按列减去均值, 除以方差, 因此数据的均值为0, 方差为1
X = StandardScaler(with_mean=False).fit_transform(X)
term_matrix = pd.DataFrame(X.toarray(), columns=tfi.get_feature_names())
print(term_matrix.head())
print('scale yes')
#print(X)
#print(result_label)
#print(tfidf_model.vocabulary_)#得到了top1000的词语
#现在,我们已经有了待训练的数据X_train,y_train,待测试数据X_test,y_test。
#X是文本的特征,y是监督项,即label数据。X负责将特征输送进分类器,而result_label的作用
# 就是告诉机器什么样的X对应positive,什么样的X对应nagative,是这个意思。
#那为什么要构造测试集呢?其实与其叫测试集,不如叫验证集。我们拿到的数据是有
# review又有label的,我们用训练集做训练之后,为了检验机器学习的效果,用测
# 试集的特征做预测,预测结果准不准呢?我们并不知道,所以要和真实情况比较一下。
# 即现有学习过X_train,y_train的分类器,将X_test输入,预测测试集的label,
# 再用y_test进行比较。
X_train,X_test,y_train,y_test=ms.train_test_split(X,result_label,test_size=0.2,random_state=10)#test_size指的是测试集所占比例
print('split yes')
print("train_size:",X_train.shape)
print("test_size:",y_train.shape)
#print(y_train)
# 一种可能是占多数的类占的比重太大了,svm只是找到了使损失函数最小化的方法,即把所有样本都预测成多数类。
# 第二种可能是不平衡性并不严重,但是你的特征不够好,svm从你的特征里学不到有用信息,所以为了降低损失函
# 数还是只能全部预测成多数类。这种情况就暗示你要改进特征工程了。如果这两种情况都不是,那就要修改损失函数
# ,让少数类被误分的惩罚更大。一般这样会降低总准确率,但会提升少数类的准确率。如何取舍还是要看你实际问题
# 中真正的目标函数是什么了。对于其他分类器比如决策树还可以resampling,并对少数类的样本更多取样。不过对于
# svm这样做我不看好,因为svm的结果取决于少数support vector,而resampling是一个离散的过程,variance会
# 比较大。
#三种是要做数据归一化处理
#第四种是max_iter次数的设置,默认为-1,即无限制
from sklearn import svm #
clf = svm.SVC(C=10,kernel='linear',probability=True,gamma='auto',max_iter=5000,decision_function_shape='ovo')#时间和max_iter有很大关系
#gamma: 核函数系数,该参数是rbf,poly和sigmoid的内核系数;默认是'auto',那么将会使用特征位数的倒数,即1 / n_features。
# (即核函数的带宽,超圆的半径)。gamma越大,σ越小,使得高斯分布又高又瘦,造成模型只能作用于支持向量附近,可能导致过拟合;
# 反之,gamma越小,σ越大,高斯分布会过于平滑,在训练集上分类效果不佳,可能导致欠拟合。
print('build new svm yes')
#kernel=‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
clf.fit(X_train,y_train,sample_weight=None) # 训练模型。参数sample_weight
print('train svm yes')
endtime = datetime.datetime.now()
print('Train time: %s Seconds'%(endtime-starttime))
print("准确率",clf.score(X_train,y_train))#:返回给定测试集和对应标签的平均准确率
# 为每个样本设置权重。应对非均衡问题
result = clf.predict(X_test)
f1 = f1_score( y_test, result, average='macro' )
print('f1=',f1)
print(result)
endtime = datetime.datetime.now()
print('Running time: %s Seconds'%(endtime-starttime))
# sparse_result = tfidf_model.transform(data_samples)
# print(sparse_resusys.exit(0)lt)
sys.exit(0)
#惩罚系数5,迭代次数5000,49956行训练集,49956行测试集,linear核函数,前一千维,去除数字,f1=0.39,时间8分钟
#惩罚系数5,迭代次数5000,19982行训练集,79928行测试集,linear核函数,前一千维,去除数字,f1=0.43,时间1分钟33秒
#惩罚系数5,迭代次数5000,79930行训练集, 行测试集,linear核函数,前一千维,去除数字,f1=0.38,时间11分钟35秒,decision_function_shape='ovo'
(2)对整体数据使用onehot编码
onthot编码的定义是一种比较复杂的概念,我使用的是比较简单的方式,使用出现率为前1000的词语构建1000的onehot向量。
每条微博发言都可以变成为一个1000维数组,初始化为[0,0,0,0,......,0],若前1000个词语出现,该词语下标就会由0变为1。
还可以考虑加入其他的数据作为onehot编码,一星期从周一到周日有7维,一天之内的24小时制有24维,发布的微博是否包含图片有1维,发布的微博是否包含视频有1维。
在这里插入代码片
#对数据进行处理,一共有1035=1000(高频词)+24(一天的时间day)+7(一周的时间week)+1(含视频video)+1(照片picture)+2(情感特征,总和为一emotion)
# created by LiYing 5/22/2020
import sys
import pandas as pd
import numpy as np
import math
import datetime
def day_index(str):#返回星期几
dict = {1:1, 2:2, 3:3, 4:4, 5:5, 6:6, 0:7}
y=2020
m=int(str[0:2])
d=int(str[3:5])
allday=math.floor((y-1)+(y-1)/4-(y-1)/100+(y-1)/400+13*(m+1)/5+(m-1)*28-7+d)
x=allday%7
return dict.get(x)
def find(list,a):#发现有词在词库里面,返回词语的下标,下标范围0-999
for i in range(0,len(list)):
if list[i]==a and i四:分类器使用
1. SVM分类器:
支持向量机,是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。
是一种比较经典的分类器;
基于onehot编码使用分类器:
对于train.csv进行onehot处理并且保存成文件,进行svm训练并且保存下模型。
代码如下:
import csv
import sys
import datetime
from sklearn import model_selection as ms, preprocessing
from imblearn.over_sampling import RandomOverSampler
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.externals import joblib
import numpy as np
import pandas as pd
from sklearn.metrics import f1_score, accuracy_score
from sklearn.preprocessing import StandardScaler
def sparse (a):
pos = neg = mid = 0
for i in a:
if i == 1: pos = pos + 1
if i == 0: mid = mid + 1
if i == -1: neg = neg + 1
print("pos", pos)
print("neg", neg)
print("mid", mid)
starttime = datetime.datetime.now()
dataset = pd.read_csv('D:\\work_Competition\\alldata.csv',encoding='utf-8-sig',lineterminator='\n')
result_label=(dataset)['情感倾向'].values#得到标签集
open_path="D:\\work_Competition\\onehot_transion_data\\new_1009.csv"
onehot = np.loadtxt(open(open_path,"rb"),delimiter=",",skiprows=0)#得到训练数据
print(open_path)
# print(onehot)
#onehot = StandardScaler(with_mean=False).fit_transform(onehot)#归一化处理
X_train,X_test,y_train,y_test=ms.train_test_split(onehot,result_label,test_size=0.8,random_state=8)#test_size指的是测试集所占比例
# ros = RandomOverSampler(random_state=0)
# X_train,y_train=ros.fit_sample(X_train,y_train)
from sklearn import svm #
clf = svm.SVC(C=100,cache_size=200,kernel='linear',probability=True,gamma='auto',max_iter=2000,decision_function_shape='ovo')
#clf = joblib.load("D:\\work_Competition\\svm_model\\3.m")#C=5,max_iter=500,decision_function_shape='ovo',linear
time2 = datetime.datetime.now()
clf.fit(X_train,y_train,sample_weight=None) # 训练模型。参数sample_weight
print('train svm yes')
model_path="D:\\work_Competition\\svm_model\\0_6.m"
joblib.dump(clf, model_path)
print('save svm yes',model_path)
time3 = datetime.datetime.now()
print("cost time",time3-time2)#训练完成
# 为每个样本设置权重。应对非均衡问题
result = clf.predict(X_test)
print("准确率",accuracy_score(y_test, result))#:返回给定测试集和对应标签的平均准确率
f1 = f1_score(y_test, result, average='macro' )
print('f1',f1)
print('0.2 result',result)
# print('f1=',f1)
# print(result)
endtime = datetime.datetime.now()
print("all cost time",(endtime-starttime))
sys.exit(0)
2. XGBClassifier:
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。
根据导师说XGBoost可以用来组合模型,不过比赛的时间有限,自己和队友有点拖延症(笑),查找了一些资料和视频之后只学会用XGBClassifier了;
3.模型训练测试集
使用保存下的模型对test.csv的onehot编码训练,生成结果进行提交。
代码如下:
import csv
import sys
import datetime
import xgboost as xgb
from sklearn import model_selection as ms, preprocessing
from sklearn.externals import joblib
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
import pandas as pd
from sklearn.metrics import f1_score
from sklearn.preprocessing import StandardScaler
starttime = datetime.datetime.now()
test_onehot = np.loadtxt(open("D:\\work_Competition\\onehot_transion_data\\new_1009_test.csv","rb"),delimiter=",",skiprows=0)
time1 = datetime.datetime.now()
print("test_onehot.shape",test_onehot.shape)
print("get data cost time",time1-starttime)#得到数据所用的时间
from sklearn import svm #
#clf = svm.SVC(C=10,kernel='linear',probability=True,gamma='auto',max_iter=3000,decision_function_shape='ovo')
#clf = joblib.load("D:\\work_Competition\\svm_model\\new_read_sigmoid.m")
model = xgb.Booster(model_file='D:\\work_Competition\\svm_model\\init_xgb.model')
time2 = datetime.datetime.now()
print('get model yes')
# 为每个样本设置权重。应对非均衡问题
result = model.predict(xgb.DMatrix(test_onehot))
print('result:')
print(result)
#将结果输出到文件
data_test =pd.read_csv("D:\\work_Competition\\1\\nCov_10k_test.csv",encoding='ansi',lineterminator='\n')
data_id =data_test['微博id']
# print(data_id.head())
data_id=np.array(data_id)
data_result=np.array(result)
result_push ={'id':data_id,'y':data_result}
result =pd.DataFrame(result_push)
result=result.astype({'y':'int'})
print(result)
result.to_csv("D:\\work_Competition\\1\\result\\onehot_submit.csv",index=False)
#result=pd.DataFrame(result)
endtime = datetime.datetime.now()
print("all cost time",(endtime-starttime))
sys.exit(0)