在paddledetection上用YOLOX训练自己的数据集
paddledetection上自带yolox模型文件,修改一些设计即可训练。
安装paddledetection
参考之前的文章:https://blog.csdn.net/Efdmmh_233/article/details/124435126?spm=1001.2014.3001.5501
数据集准备
训练yolox模型需要的数据集格式为coco的格式。在paddledetection文件夹下的dataset下的coco文件夹中放好自己的数据集。


如果你的数据集是其他格式,例如VOC,tools文件夹下也提供了相应的转换代码。
python tools/x2coco.py \
--dataset_type voc \
--voc_anno_dir path/to/VOCdevkit/VOC2007/Annotations/ \
--voc_anno_list path/to/VOCdevkit/VOC2007/ImageSets/Main/trainval.txt \
--voc_label_list dataset/voc/label_list.txt \
--voc_out_name voc_train.json
具体参数说明参考官方文档:voc转为coco格式
生成的json文件按照上图的名字重命名,并放到相应的位置。
train2017和val2017里放对应的图片文件(按照trainval,test.txt来分的)
可以用下面的代码来分:
import os
from PIL import Image
'''
按照Main下面的trainval.txt,test.txt划分JPEGImages下的图片
划分为train2017,val2017
'''
def voc2yolo(train_txt_path, val_txt_path, image_dir_path, train_image_save_path, val_image_save_path):
'''
:param train_txt_path: trainval.txt文件路径
:param val_txt_path: test.txt文件路径
:param image_dir_path: VOC数据集下保存图片的文件夹路径
:param train_image_save_path: 训练图片需要保存的文件夹
:param val_image_save_path: 测试图片需要保存的文件夹
:return:
'''
#按照train.txt和val.txt将图片放到images文件夹下的train2017和val2017文件夹下
train_list = []
with open(train_txt_path,"r") as f:
for line in f:
train_list.append(line[:-1])
# print(train_list)
#
val_list = []
with open(val_txt_path, "r") as f:
for line in f:
val_list.append(line[:-1])
# print(val_list)
all_images_list = []
for image in os.listdir(image_dir_path):
new_image = image.split(".")[0]
all_images_list.append(new_image)
img = Image.open(os.path.join(image_dir_path, image))
if new_image in train_list:
if not os.path.exists(train_image_save_path):
os.makedirs(train_image_save_path)
img.save(os.path.join(train_image_save_path,image))
else:
if not os.path.exists(val_image_save_path):
os.makedirs(val_image_save_path)
img.save(os.path.join(val_image_save_path,image))
# print(all_images_list)
if __name__ == "__main__":
voc2yolo("C:\\VOCtrainval_11-May-2012\\VOCdevkit\\VOC2012\\ImageSets\\Main\\trainval.txt",
"C:\\VOCtrainval_11-May-2012\\VOCdevkit\\VOC2012\\ImageSets\\Main\\test.txt",
"C:\\VOCtrainval_11-May-2012\\VOCdevkit\\VOC2012\\JPEGImages",
"C:\\PaddleDetection-release-2.4\\dataset\\coco\\train2017",
"C:\\PaddleDetection-release-2.4\\dataset\\coco\\val2017")
这样训练需要的coco数据集就准备好了。
训练
1.先在configs文件夹下找到自己要训练的模型。

打开这个yml文件。
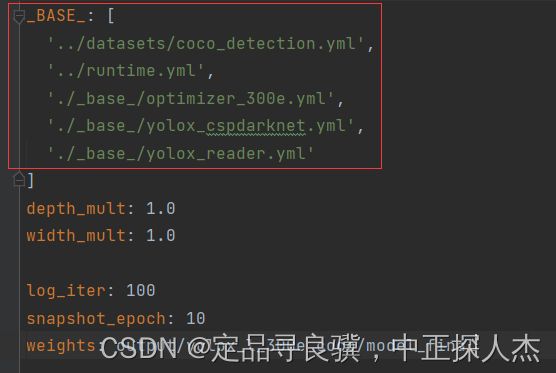
这个文件中没有什么参数要修改。需要修改的是红框中的yml文件。根据路径依次找到它们。
1.1coco_detection.yml
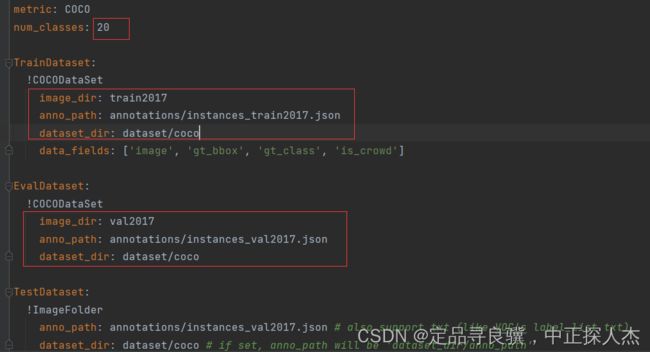
num_classes改成自己的类别数,有背景的类别数+1,如(fasterrcnn,detr等),yolo系列的就不用了。
下面两个红框中都是数据集的路径,按我上面说的放数据集,这边就不需要修改了。
1.2 runtime.yml 不管它。
1.3 optimizer_300e.yml

主要就是训练的epoch次数,下面是优化器的一些参数,这就需要根据具体的数据集来修改了。
1.4 yolox_reader.yml
主要worker_num,在window下训练要设置为0,linux下可以大于1.(cpu越多,内存越大,num_worker可以适当设置的大一点,是程序时间优化的一个方法)。
还有batch_size的设置,不多说。
训练命令:
python tools/train.py -cconfigs/yolox/yolox_l_300e_coco.yml --eval --use_vdl=true --vdl_log_dir=vdl_dir/scalar -o use_gpu=true
--eval #边训练边验证 吃GPU
--use_vdl #类似于tensorboard,true开启,训练完loss可视化
--vdl_log_dir #log文件保存路径,和上面一句一起使用
-o use_gpu #是否使用gpu训练
不出意外就开始训练了。。
小插曲
想训练VOC格式的数据集,要通过\dataset\voc下的creat_list.py生成最终的trainval.txr和test.txt。下面这个效果。

但是运行完creat_list.py后trainval.txt里面为空。
解决:ppdet\utils\voc_utils.py下,修改代码:
修改之前:
if re.match(r'[a-z]+_trainval\.txt', fname):
img_ann_list = trainval_list
elif re.match(r'[a-z]+_test\.txt', fname):
img_ann_list = test_list
修改之后:
if re.match(r'trainval.txt', fname): #[a-z]+_trainval\.txt
img_ann_list = trainval_list
elif re.match(r'test.txt', fname): #[a-z]+_test\.txt
img_ann_list = test_list
解决。。
但是问题又来了,我把文件搬到paddle平台去训练的时候,trainval.txt又生成为空的。。我图省事,就把在windows本地生成的trainval.txt上传了上去,接着的问题就是:windows下生成的路径是左斜杠,linux下生成的应该是右斜杠。creat_list.py会判断你的OS环境来生成相应的路径。
这里想写个脚本(让左斜杠变成右斜杠。。又感觉指标不治本)。
最后通过调试发现,creat_lists.py需要导入ppdet文件夹,而他没有导入paddledetection下的ppdet,而是导入了虚拟环境下的ppdet。
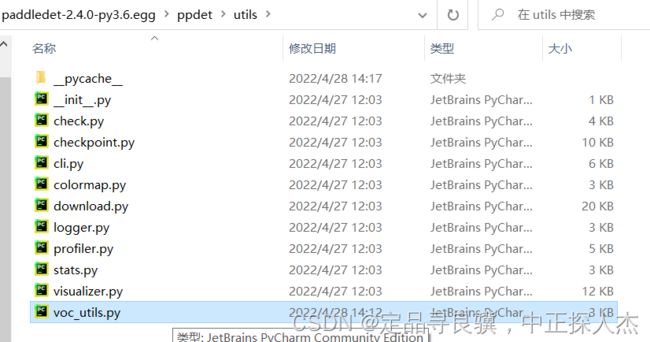
将这里面的voc_utils.py也进行了修改,即[a-z]+_test.txt改成test.txt就可以了。
同理,在paddle训练平台上:
在根目录下查找ppdet:
cd /
find -name ppdet
![]()
找到ppdet的位置,按上面对里面的内容进行修改。就可正常生成trainval.txt和test.txt了~。