达摩院文档级关系抽取新数据集和五元组抽取新任务

©PaperWeekly 原创 · 作者 | 邴立东、谭清宇等
单位 | Alibaba DAMO, NUS, SUTD
关系抽取(RE)是 NLP 的核心任务之一,是构建知识库、事件抽取等下游应用的关键技术。多年来受到研究者的持续关注。
本文将介绍达摩院语言实验室多语言 NLP 算法团队的两篇 EMNLP 2022 主会论文。第一篇论文针对文档级关系抽取任务中普遍存在的假负类样本(False Negative Example)问题,进行了深入的分析,并对 DocRED 数据进行了大幅度修正后,发布了 Re-DocRED 数据集。第二篇论文针对三元组关系没有考虑限定信息(例如时间)的问题,我们提出了五元组关系抽取的新任务,并发布了新数据和基线模型。

Re-DocRED: 解决DocRED数据集中的假负例问题
本小节工作来自 EMNLP 2022 主会论文:Revisiting DocRED - Addressing the False Negative Problem in Relation Extraction

论文标题:
Revisiting DocRED -- Addressing the False Negative Problem in Relation Extraction
论文链接:
https://arxiv.org/abs/2205.12696
数据代码:
https://github.com/tonytan48/Re-DocRED
1.1 背景介绍
关系抽取,Relation Extraction from Text,简称 IE,是从自然语言文本中,抽取出实体之间的关系。传统的关系抽取方法主要是抽取单个句子间两个实体的关系,这一任务被称为句子级别关系抽取。然而,在真实的应用场景中,大量的实体关系是由多个句子联合表达的,因此,文档级别的关系抽取相对于句子级别更加具有应用价值 [1]。

▲ 图1.1 Re-DocRED 文章样本
具体的任务定义为:给定一个文档 D,其中的实体数目为 N,模型需要预测所有实体对之间的关系,总共需要做 N(N-1)个实体对的关系分类。DocRED 数据集是文档级关系抽取任务中最被广泛应用的数据集,自 2019 年发布以来已经有相当多的工作基于该数据集提出了许多文档级关系抽取的模型,然而文档级关系抽取这一任务的 SOTA 却一直在 60 - 65F1 左右。
在我们的初步研究中发现,DocRED 数据集中存在大量漏标的实体关系,并且同时存在于训练和测试集中,这些漏标的实体对被称为假负类样本(False Negative Example)。假如一个实体对存在特定关系,但在测试集中未被标注,即便模型预测出了该关系也会被判为错误。如图 1 所示,从高亮的句子中可以推测出 Max Martin 与 Shellback 都是流行歌曲 I knew you were trouble 的制作人, 但是 DocRED 数据集中仅标注了 Max Martin。
这些假负类样本不仅影响模型的训练过程,测试集中的假负类样本更是直接影响数据集本身的合理性。我们在初步的实验中发现,尽管 DocRED 数据集包含 96 种关系,但是区分这 96 种关系本身对于目前的 SOTA 模型(KD-DocRE [2])并不困难,其表现可以达到 90F1 以上,而由于假负类样本的存在,在包含 ‘no_relation’ 的关系分类任务中仅能取得 64 左右的 F1。
这说明目前文档集关系抽取的瓶颈并不在于区分多种关系,而在于判断关系是否存在,这部分的实验请在原文中的第二章节,由于篇幅所限,本文中不对其展开赘述。由于假负类问题同时存在于 DocRED 的训练集以及测试集中,我们认为有必要对 DocRED 进行重新标注,以对文档级别关系抽取提供更高质量的评估。
1.2 方法介绍
文档集关系抽取数据集的标注任务是成本高昂并且十分复杂的标注任务。因为长文本中存在多个实体,而需要标注的实体对与实体数目成平方关系。以 DocRED 数据集为例,该数据集存在 96 种关系,并且同一实体对可以有多个关系,平均一个文档有大约 20 个实体,如果对这些实体间所有有可能的关系进行标注,标注员需要进行 20*19*96=36480 个标注,无疑带来非常高的成本。
鉴于此,我们采用了多轮次基于机器推荐与人工标注相结合的标注方式。首先,我们将 DocRED 的原有数据分为了 4 个子集以用于交叉验证,并训练了原 DocRED 排行榜上前三名的模型:1)KD-DocRE [2] ;2)DocUNET [3] 以及;3)ATLOP [4]。
在第二步,我们将所有模型的预测的三元组进行并集处理,这一做法主要是尽可能地提高机器推荐三元组的范围,使其尽可能地包含文章中所有可能的正确关系。第三步,我们对机器推荐的三元组进行人工标注,标注员需要判断机器推荐的三元组正确与否。
我们将原有的 DocRED 训练集进行了一轮标注,由于 DocRED 测试集不公开,我们将 DocRED 原有的开发集(1,000 个文档)分为了相同大小的开发集与测试集,并对其进行了两轮的标注。这一做法主要是为了确保在新数据集中开发集和测试集的完备性。
在人工标注后我们还对所有的三元组进行了逻辑填充 (原文附录 E)。我们将重标过后的数据集命名为 Re-DocRED。通过我们两轮的标注发现,Re-DocRED 的开发集和测试集平均每篇文章存在约 34.7 个三元组,而原有的 DocRED 数据集每篇仅有约 12.5 个三元组标注,这说明 DocRED 原有数据集的漏标比例约在 64% 左右。如此高的漏标比例也说明原有 DocRED 数据集并不适合作为关系抽取的测试数据。

▲ 表1.1 Re-DocRED和DocRED的比较
1.3 实验结果
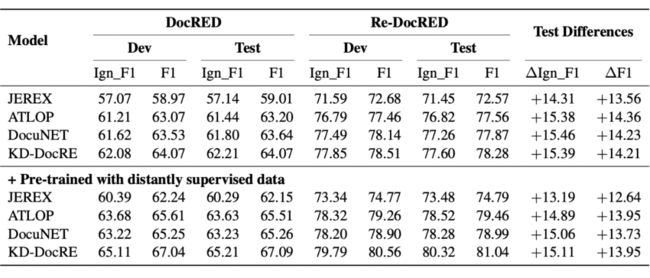
▲ 表1.2 相同模型在Re-DocRED 与DocRED上表现对比
我们在不同模型上对 Re-DocRED 进行了实验,在上小节提到的三个模型(KD-DocRE, DocUNET, ATLOP)之外,还在 JEREX [5] 上进行了验证实验,我们发现在 Re-DocRED 上训练与测试所有模型,表现相对于 DocRED 有着显著的提升,并且提升的幅度高达 13 F1 左右,这一差别说明制约文档级别关系抽取研究的主要原因是基准数据集存在的漏标问题,尤其是测试集中的漏标问题。而这一问题让研究人员无法正确地评估文档级别关系抽取任务。
1.4 训练中的假负例问题
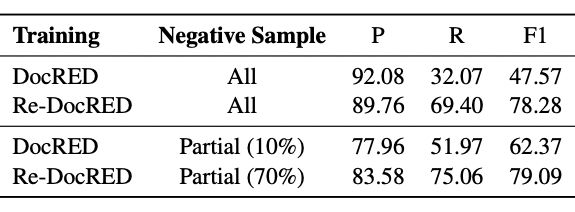
▲ 表1.3 负采样在不同训练数据下的表现,测试数据均采用Re-DocRED
由 1.3 节可知,尽管 Re-DocRED 缓解了假负例的问题,由于成本限制,其训练集仅经历了一轮的重新标注,这说明 Re-DocRED 训练集中同样存在少量的漏标样本。如果假负例仅存在于训练数据中,在训练过程中进行负采样 [6] 可以显著提高模型的表现。
如果我们将原有的 DocRED 用作训练集,而所训练的模型(KD-DocRE)在 Re-DocRED 的测试集上测试,其表现仅能达到 47.57 F1,而如果仅随机采用 10% 的负类样本进行训练,其模型表现可以达到 62.37 F1。后续的研究可以继续探索如何克服训练数据中的假负例问题。
1.5 总结
我们发现了文档级关系抽取的基准数据集 DocRED 中的假负类问题,该问题为正确评估关系抽取任务带来了相当大的挑战。为了解决这一问题,我们将 DocRED 数据集进行了高质量的重新标注,得到了质量更高的 Re-DocRED 数据集。同时,我们将 Re-DocRED 数据集在第一时间进行了开源,以便于关系抽取任务的后续研究:
https://github.com/tonytan48/Re-DocRED

HyperRED: 用于超关系抽取的数据集与一种立方体关系抽取方法
本小节工作来自 EMNLP 2022 主会论文:A Dataset for Hyper-Relational Extraction and a Cube-Filling Approach

论文标题:
A Dataset for Hyper-Relational Extraction and a Cube-Filling Approach
论文链接:
https://arxiv.org/abs/2211.10018
数据代码:
https://github.com/declare-lab/HyperRED
2.1 问题提出
关系抽取(Relation Extraction)能帮助构建大规模知识图谱 [7],但目前的方法没有考虑每个关系三元组的限定信息 (Qualifier),例如时间、数量或地点。限定信息形成了超关系事实 [8](Hyper-Relational Fact),可以更好地代表丰富而复杂的知识图谱结构。例如,关系三元组(Leonard Parker,Educated At,Harvard University)可以通过限定信息(End Time,1967)变成更完整。
因此,我们提出了超关系抽取(Hyper-Relational Extraction)的任务,以从文本中抽取更具体和完整的事实。为了支持这项任务,我们标注了 HyperRED,一个大规模的数据集。现有模型无法执行超关系抽取,因为它需要一个模型来考虑三个实体之间的交互。
因此,我们提出了立方体关系抽取(CubeRE)模型,这是表格填空 [9](Table-Filling)方法启发的模型,并明确考虑了关系三元组和限定信息之间的交互。为了提高模型效率并减少负类的不平衡,我们进一步提出了一种立方体剪枝(Cube-Pruning)方法。我们的实验表明,CubeRE 优于其他基线模型,并指出未来研究的可能方向。
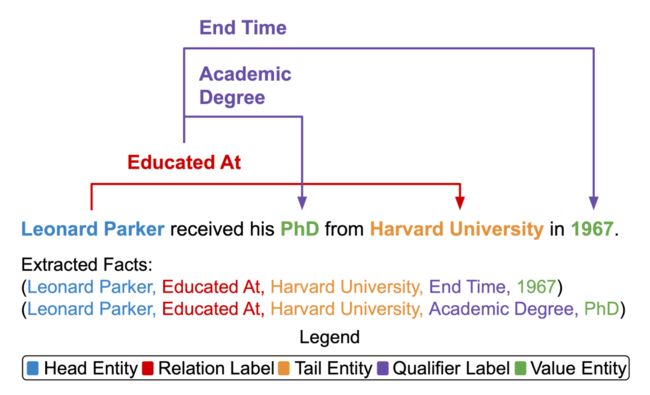
▲ 图2.1 超关系抽取任务。
2.2 相关方法的局限
据我们所知,目前没有支持超关系事实抽取的数据集。因此,我们标注了 HyperRED,一个大规模与多领域的数据集。与现有的关系抽取数据集 [10] 相比,HyperRED 能够实现更丰富的信息抽取,因为它包含每个关系三元组的限定信息。虽然用于多元组(N-ary )关系抽取的数据集 [11] 仅限于生物医学领域,但 HyperRED 覆盖了多个领域,并具有与知识图谱兼容的超关系事实结构。
由于没有能支持超关系抽取的现有模型,我们实现了两个利用预训练语言模型的基线。受生成模型在信息抽取任务的启发 [12],我们实现了一种用于超关系抽取的生成方法(Generative Baseline)。该模型不需要特定任务的模块即可以端到端地执行超关系抽取。
与现有的关系抽取生成式方法,我们使用 BART [13],它将句子作为输入并输出结构化文本,然后解码以形成超关系事实。然而,该模型将超关系事实代表为一个平面序列,没有明确考虑关系三元组和限定信息的结构。
另一方面,生成模型的可解释性和可控性较差,因为它不能分别提供每个预测的事实的分数,而且无法控制预测事实的数量。 由于两阶段方法可以作为信息抽取任务的基线模型,我们实现了一种用于超关系抽取的两阶段方法(Pipeline Baseline)。
具体来说,我们首先训练了一个现有的关系三元组抽取模型 UniRE [14]。接着,我们训练了一个基于 BERT-Tagger [15] 的实体抽取模型,该模型以输入句子和关系三元组为条件来抽取限定信息。然而,两阶段模型容易产生错误传播,这会减少抽取到的事实数量。
2.3 任务定义
给定一个包含 n 个单词 的输入句子,实体 e 由连续的单词跨度构成,其中 。对于每个句子 s,超关系抽取模型的输出是一组事实,其中每个事实都由带有限定信息的关系三元组组成。
关系三元组由头部实体 和尾部实体 之间的关系类别 组成,其中 是预定义的一组关系标签集。限定信息是关系三元组的一个属性,由限定类别 和值实体 组成,其中 是预定义的限定标签集。因此,超关系事实有五个组成部分:()。
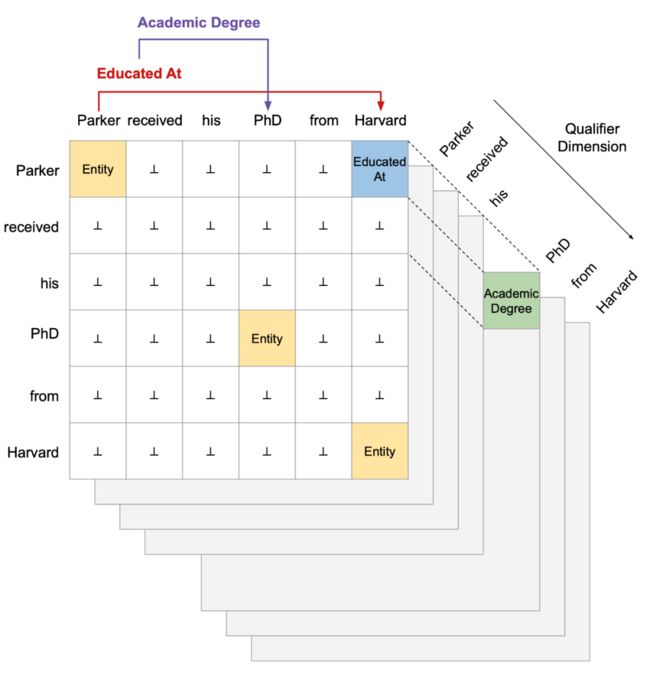
▲ 图2.2 立方体关系抽取。
受表格填空方法的启发,我们将超关系抽取视为立方体填空,这种方法可以端到端地执行超关系抽取,如上图所示。立方体包含多个平面,其中最前面的平面包含实体和关系类别的信息,而后面的平面包含相应的限定信息。最前面的平面对角线代表实体类别,而对角线之外代表关系三元组类别。
例如,“Educated At” 表示了头部实体 “Parker” 和尾部实体“Harvard” 之间的关系。立方体的后面平面代表限定信息,对应关系三元组的可能限定信息的类别和实体词。例如,“PhD” 的限定平面中的条目“Academic Degree” 对应于关系三元组(Parker,Educated At,Harvard),形成了超关系事实(Parker,Educated At,Harvard,Academic Degree,PhD)。
2.4 我们的模型
我们称为立方体关系抽取( CubeRE )的模型首先使用训练语言模型对每个输入句子进行编码,以获得上下文化的序列表示。然后,我们结合了头部实体和尾部实体的表示来捕捉关系三元组的交互,并预测实体关系的分数。我们接下来结合实体对表示与序列表示以捕捉关系三元组和限定信息之间的交互,并预测限定分数。
为了降低立方体计算成本,我们利用立方体剪枝(Cube-pruning)方法对每个句子表示只保留具有较高实体可能性的单词。最后,我们对实体关系的分数和限定分数进行解码以形成预测的超关系事实。
2.5 主要结果
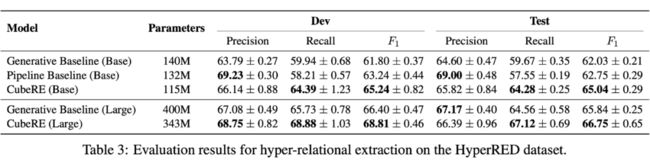
▲ 表2.1 HyperRED 数据集上超关系抽取的测试结果。
我们将 CubeRE 与基线模型进行比较,并在上表中报告分数。结果证明了我们模型的总体有效性,因为 CubeRE 始终具有较高的 F1 分数。与容易产生错误传播的两阶段模型相比,CubeRE 能以端到端的方式执行超关系抽取。因此,CubeRE 避免了错误传播的问题,能够抽取到更多有效的超关系事实,提高了 Recall 和 F1 分数。与生成基线模型相比,我们的方法能够明确考虑关系三元组和限信息之间的交互,以更好地抽取超关系事实。
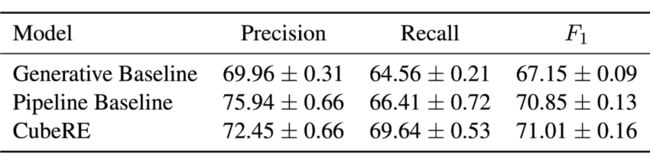
▲ 表2.2 仅考虑超关系事实三元组的测试结果。
为了进一步研究模型性能的差异,我们还报告了仅考虑超关系事实的三元组时的结果,如上表所示。结果表明,当仅考虑关系三元组时,CubeRE 具有与两阶段基线模型相当的抽取性能。这表明超关系抽取的性能优势很可能是由于更准确的限定信息抽取。
两阶段基线模型具有两个独立的语言模型,分别抽取关系三元组和限定信息。另一方面,CubeRE 能学到输入句子的统一表示。该表示由关系三元组和限定信息学习目标指导,能更好地促进关系三元组和限定信息之间的交互。这允许 CubeRE 更准确地抽取限定信息,从而获得更好的整体性能。

▲ 表2.3 立方体剪枝阈值 m 对 Dev F1 的影响。没有用立方体剪枝的模型表示为 m=∞。
除了提高 CubeRE 的计算效率外,我们的立方体剪枝方法还可以提高模型的抽取性能。在训练过程,模型面临着负类的不平衡,从而偏向于负类的预测。我们通过仅考虑与较高实体分数相关的单词来剪枝立方体,缓解了负类不平衡问题。上图中的趋势支持了这一点,因为放宽剪枝阈值会让负类越不平衡,导致性能下降。另一方面,过于严格的剪枝会导致模型只能抽取少数量的超关系事实。
2.6 总结
为了解决超关系抽取的挑战,我们构建了一个名为 HyperRED 的大规模数据集。与现有的关系抽取数据集相比,HyperRED 包含每个关系三元组的限定信息,并且不限于任何域。由于没有现有的模型能支持超关系抽取任务,我们提出了一个立方体填空模型(CubeRE)。
实验结果表明,我们提出的模型优于两个基线模型。与两阶段基线模型相比,CubeRE 可以端到端地抽取超关系事实,避免错误传播问题。与生成基线模型相比,我们的方法能够明确考虑关系三元组和限信息之间的交互,以更好地抽取超关系事实。

参考文献
[1] Yao, Yuan, et al. "DocRED: A Large-Scale Document-Level Relation Extraction Dataset." Proceedings of ACL. 2019.
[2] Tan, Qingyu, et al. "Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation." Findings of ACL. 2022.
[3] Zhang, Ningyu, et al. "Document-level Relation Extraction as Semantic Segmentation." Proceedings of IJCAI. 2021.
[4] Zhou, Wenxuan, et al. "Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling." Proceedings of AAAI.2021.
[5] Eberts, Markus, et al. "An End-to-end Model for Entity-level Relation Extraction using Multi-instance Learning." Proceedings of EACL. 2021.
[6] Li, Yangming, et al. "Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition." Proceedings of ICLR. 2020.
[7] Eduard Hovy, Roberto Navigli, and Simone Paolo Ponzetto. 2013. Collaboratively built semi-structured content and artificial intelligence: The story so far. Artificial Intelligence.
[8] Paolo Rosso, Dingqi Yang, and Philippe Cudré- Mauroux. 2020. Beyond Triplets: Hyper-Relational Knowledge Graph Embedding for Link Prediction. In Proc. of WWW.
[9] Makoto Miwa and Yutaka Sasaki. 2014. Modeling joint entity and relation extraction with table represen- tation. In Proc. of EMNLP.
[10] Yuhao Zhang, Victor Zhong, Danqi Chen, Gabor Angeli, and Christopher D. Manning. 2017. Position-aware Attention and Supervised Data Improve Slot Filling. In Proc. of EMNLP.
[11] Robin Jia, Cliff Wong, and Hoifung Poon. 2019. Document-Level N-ary Relation Extraction with Multiscale Representation Learning. In Proc. of NAACL.
[12] Giovanni Paolini, Ben Athiwaratkun, Jason Krone, Jie Ma, Alessandro Achille, RISHITA ANUBHAI, Cicero Nogueira dos Santos, Bing Xiang, and Stefano Soatto. 2021. Structured prediction as translation between augmented natural languages. In Proc. of ICLR.
[13] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proc. of ACL.
[14] Yijun Wang, Changzhi Sun, Yuanbin Wu, Hao Zhou, Lei Li, and Junchi Yan. 2021. UniRE: A Unified Label Space for Entity Relation Extraction. In Proc. of ACL.
[15] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proc. of NAACL.
关于作者:
本文由阿里巴巴达摩院自然语言智能实验室邴立东、联培博士生谭清宇、谢耀赓等共同整理。由PaperWeekly编辑做了校对和格式调整。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
