逻辑回归原理详解(附手写推导)
目录
一、逻辑推导
二、手写推算逻辑回归运算步骤
1、梯度下降法
2、最大似然估计法
三、用梯度下降法求损失函数最小值
四、代码部分
一、逻辑推导
因部分内容与作者之前所发布的文章有所重复,故只对新的知识或重复部分中较为重点的内容进行讲解。

逻辑回归通常用于解决分类问题,比如:客户是否该买某个商品,借款人是否会违约等。实际上,“分类”是逻辑回归的目的和结果,中间过程依旧是“回归”,因为通过逻辑回归模型,我们得到的是0-1之间的连续数字,即概率,类似借款人违约的可能性。然后给这个可能性加上一个阈值,就变成了分类。
如何将一个线性函数(如下)的结果控制在(0,1)之间呢?
![]()
我们引入sigmoid函数,通过该函数。可以将线性值转化为(0,1)。
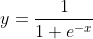
把线性回归函数的结果y,放到sigmod函数中去,就构造了逻辑回归函数,得到的这个结果类似一个概率值。
sigmoid函数告诉我们,当得到拟合曲线的函数值时,如何计算最终的类标号。但是核心问题仍然是这个曲线如何拟合。既然是回归函数,我们就模仿线性回归,用误差的平方和当做代价函数。代价函数如公式(2)所示:

其中,![]() ,yi为Xi真实的类标号。按说此时可以对代价函数求解最小值了,但是如果你将
,yi为Xi真实的类标号。按说此时可以对代价函数求解最小值了,但是如果你将![]() 带入公式(2)的话,那么当前代价函数的图像是一个非凸函数,非凸函数有不止一个极值点,导致不容易做最优化计算。也就是说,公式的这个代价函数不能用。
带入公式(2)的话,那么当前代价函数的图像是一个非凸函数,非凸函数有不止一个极值点,导致不容易做最优化计算。也就是说,公式的这个代价函数不能用。
那自然要想办法设计新的代价函数。我们在上面说了,ϕ(z)ϕ(z)的取值可以看做是测试元组属于类1的后验概率,所以可以得到下面的结论:
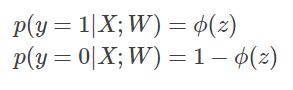
更进一步,上式也可以这样表达:

公式(3)表达的含义是在参数W下,元组类标号为y的后验概率。假设现在已经得到了一个抽样样本,那么联合概率![]() 的大小就可以反映模型的代价:联合概率越大,说明模型的学习结果与真实情况越接近;联合概率越小,说明模型的学习结果与真实情况越背离。而对于这个联合概率,我们可以通过计算参数的最大似然估计的那一套方法来确定使得联合概率最大的参数W,此时的W就是我们要选的最佳参数,它使得联合概率最大(即代价函数最小)。下面看具体的运算步骤。
的大小就可以反映模型的代价:联合概率越大,说明模型的学习结果与真实情况越接近;联合概率越小,说明模型的学习结果与真实情况越背离。而对于这个联合概率,我们可以通过计算参数的最大似然估计的那一套方法来确定使得联合概率最大的参数W,此时的W就是我们要选的最佳参数,它使得联合概率最大(即代价函数最小)。下面看具体的运算步骤。
二、手写推算逻辑回归运算步骤
通过Logistic函数归一化到(0,1)间,y的取值有特殊的含义,它表示结果取准确的概率,如果分类为1,h(x)==1表示预测100%准确,分类为0,h(x)==0表示预测100%准确。
我们有了逻辑回归函数我们需要想办法的到这个函数取最大值时的参数。我们有两种方法去求得。
1、梯度下降法
手写推导如下:

2、最大似然估计法
需要进行对数化处理。
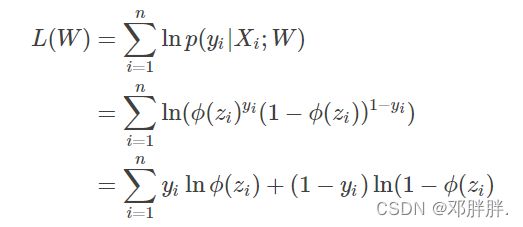
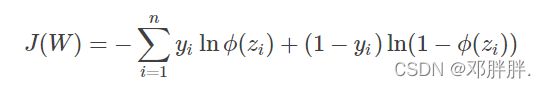
三、用梯度下降法求损失函数最小值
此处在作者之前的博客有详细的讲解,故不再过多赘述。
如果能求出代价函数的最小值,也就是最大似然函数的最大值。那么得到的权重向量WW就是逻辑回归的最终解。但是通过上面的图像,你也能发现,J(W)是一种非线性的S型函数,不能直接利用偏导数为0求解。于是我们采用梯度下降法。
四、代码部分
##估价函数
def sigmoid(z):
return(1 / (1.0 + math.exp(-z)))
def hypothesis(x, theta, feature_number):
h = 0.0
for i in range(feature_number+1):
h += x[i] * theta[i]
return(sigmoid(h))
##计算偏导数
def compute_gradient(x, y, theta, feature_number, feature_pos, sample_number):
sum = 0.0
for i in range(sample_number):
h = hypothesis(x[i], theta, feature_number)
sum += (h - y[i]) * x[i][feature_pos]
return(sum / sample_number)
##代价
def compute_cost(x, y, theta, feature_number, sample_number):
sum = 0.0
for i in range(sample_number):
h = hypothesis(x[i], theta, feature_number)
sum += -y[i] * math.log(h) - (1 - y[i]) * math.log(1 - h)
return(sum / sample_number)
##梯度下降
def gradient_descent(x, y, theta, feature_number, sample_number, alpha, count):
for i in range(count):
tmp = []
for j in range(MAX_FEATURE_DIMENSION):
tmp.append(0)
for j in range(feature_number + 1):
tmp[j] = theta[j] - alpha * compute_gradient(x, y ,theta, feature_number, j, sample_number)
for j in range(feature_number + 1):
theta[j] = tmp[j]
print(compute_cost(x, y, theta, feature_number, sample_number))