长视频优化:如何高效减少转码耗时
本文来自微信客户端技术团队,作者:瑞澈。
1.背景介绍
在视频号项目中,允许用户上传一分钟内的编辑视频,或者选择30min内的长视频。目前来看,整个发表(视频转码+上传)的耗时还略显偏久,虽然当下转码过程都是在手机后台运行,不会阻塞用户交互,但是由于视频未发表成功,视频点赞和转发功能都被限制,对用户和业务而言,这都是很不好的体验,有值得优化的必要。
1.1分析:耗时来源
整个耗时 = 视频转码耗时 + 上传耗时目前上传的时间取决于用户网络,这个不是本文讨论的重点,先暂时不予考虑。那么为什么我们需要对视频进行转码呢?
- 对于用户主动编辑的视频,我们需要重新处理视频才能满足需求。
- 考虑到网络带宽影响和用户观看端体验的优化(网速一定时,文件越大,下载的耗时等比增加),我们需要对视频做一些压缩处理,利于首次快速播放。
- 现在的手机屏幕普遍的分辨率是2k左右,让用户去加载4k的视频,是一种资源浪费。在尽量保证视频效果的同时,同时减小视频的体积,可以降低带宽和手机性能压力(编解码播放)。
- 如果用户的视频自身已经满足一般的播放条件,且又未编辑,此时我们会选择直接上传文件(前置MOOV结构,满足边下边播需求),降低二次转码对视频清晰度带来的损耗。
1.2 当前方案
在实现功能的前提下,在视频号发表侧我们选择了不同于其他场景的处理方式,用户编辑完成点击发表视频后,我们选择将整个视频合成的逻辑放到手机后台执行,不阻塞用户的交互,从而优化用户体验。 但是后台合成的耗时也不可小觑,当发表成功后,用户才可以执行点赞、分享等操作。长时间的等待,会降低用户对当前视频的关注度,降低这里的耗时,可以降低用户的等待时间,为活跃视频号分享有重大的意义。
1.3 当前业界主流方案
在满足一定限制条件(分辨率、码率和帧率)且未编辑的视频,允许直接上传后台;超过限制条件或者存在编辑的情况,则客户端转码后上传后台,后台再将视频转码成多路视频,按照策略向客户端下发。和我们当前的方案基本无异。
关于转码速度优化,目前主流的优化的方案,都是采用硬件编解码为主,优化渲染速度或者优化编解码的调用方式(MediaCodec 异步模式),通过降低每个流程的耗时,来优化时间。在一定程度上来说,这种优化方式是存在**“天花板”**的,每个流程是客观存在耗时的,在无多余等待或者操作耗时的时候,优化就到了尽头。

1.4 拓展方案和技术可行性分析
作为有理想的开发,我们是不会止步于此的。抽象一下问题,我们在深入思考类推一下: 对于普通的耗时任务而言,我们通常选取的优化手段是,判断任务是否有时间强相关性,否则可以通过多线程并行的方式来缩短耗时。这个思想在目前操作系统(多线程)和硬件(多核CPU)都得到了体现。 那我们的任务是什么呢?主要耗时又在哪里?任务相关性几何? 任务是将长视频进行转码。细分一下模块,主要包括:视频转码和音频转码。相较于音频编码,视频编码存在更高的复杂度和数据量,所以主要耗时在视频转码。 一个普通的mp4文件,一般由多个轨道组成;最为常见的例子,也就是如下图所示的普通视频,包含一个音轨和一个视轨。
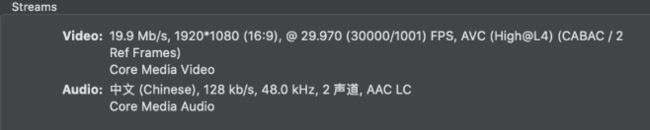
任务时间相关性呢?
视轨和音轨是相互独立的,彼此之间无相关性。在当前方案下,音轨和视轨是同时进行转码的,并且主要的耗时集中在视频转码之上,以此可以减少音轨转码带来的耗时。 接着在来详细分析一下视轨,视轨可以认为就是带有一组连续时间戳的静态图像压缩帧,这些帧按类型分为IPB帧;I帧可以独立解码,P帧和B帧需要依赖其他帧才能完成解码;GOP就是两个I帧之间的间隔。
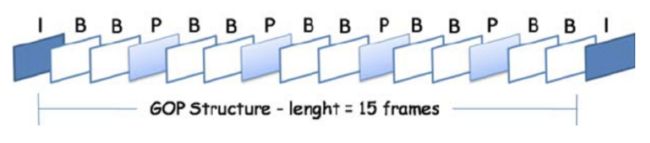
那么我们是不是可以进一步的将视轨转码的任务也拆解一下,视频轨道中仅仅一组GOP内的视频帧存在依赖,GOP之间不存依赖;但是我们却让所有GOP串行执行,不禁想问一句:

1.4.1 技术可行性分析
针对这个问题,那我们是否可以按照GOP或者或者更长的时间区间来划分出多个任务,并行执行从而来减少耗时呢?**值得一试。**磨刀不误砍柴工,开始之前,还是需要先理论分析一波,确保方案的可行性。
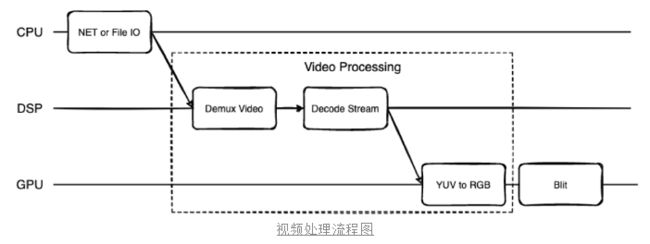
正常处理一个视频,涉及到视频解封装、视频解码、渲染、编码和封装几个流程,另外按照并行处理的方式,视频封装的流程也会改变,从单段H264封装,转变为多段H264封装。
那么我们首先需要考虑的问题就是,DSP芯片、GPU和CPU是否支持多路并行呢?
其中多路解封装、视频解码、渲染和编码,这个从过往的经验中可以推论出来是可行的,比如预加载视频或者视频通话场景,或多或少都存在同时多路解码的场景。
那么多段H264封装是可行的吗?简单分析一下。

H.264基本流的结构分为两层,包括视频编码层(VCL)和网络适配层(NAL)。我们接触到的为NAL层,H264编码数据主要有多个NALU组成,其中NAL支持32种类型,那么我们编码出来的有哪些类型呢?
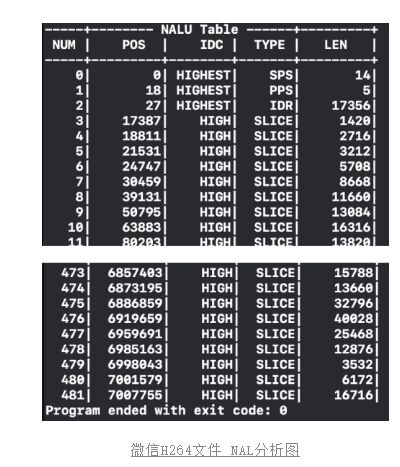
通过FFmpeg分析,我们打印一个普通的单段H264文件,可以发现主要有4种类型NALU,其中SPS和PPS出现在头部,主要是描述视频的一些基本信息,比如分辨率。IDR是I帧的一种特殊类型,IDR帧后面的参考帧,将不会参考之前的帧;SLICE可以认为是参考帧数据。
那么对于多段H264文件拼接,后面的IDR和SLICE正常拼接理论是没有问题,这和普通的单段H264文件结构是一致的;接下来需要考虑的就是头部的SPS和PPS如何处理,参照H264官方文档和一些技术博客,标准并没有限制每种NALU出现的位置,SSP和PPS也可以出现在文件中间,此时有两个作用:
1.解码器需要在码流中间开始解码
2.编码器在编码的过程中改变了码流的参数(如图像分辨率等)
可以简单理解为,H264数据中间的SPS和PPS可有可无,为了方便流程处理,我们直接拼接文件即可。
到此为止,理论方案分析完毕,结论依然是可行。
另外,并行流程中,仅仅是视轨并行转码,音轨保持原有逻辑处理独立处理,因为音轨的处理耗时并不是大头,并且音轨具有更高的敏感性,处理不当,问题会比较明显,相反人对于视频变化的敏感度反而没这么高。这也是为什么一般做音视频同步,往往是视频同步音频的原因。
1.4 可行性测试
Android平台手机类型多,系统版本分布广,性能高中低端分布不均。理论分析完成之后,我们还需要快速验证一下方案的效果如何;为了粗略测试一下并行合成的多机型手机合成效果和支持情况,我们先设计了可以同时运行多个转码任务的demo,期望通过wetest自动化快速测试,得到结论。
同时,我们根据现网视频分布,我们从时长、分辨率、码率、帧率、GOP和编码格式上划分,设计了以下视频用例:
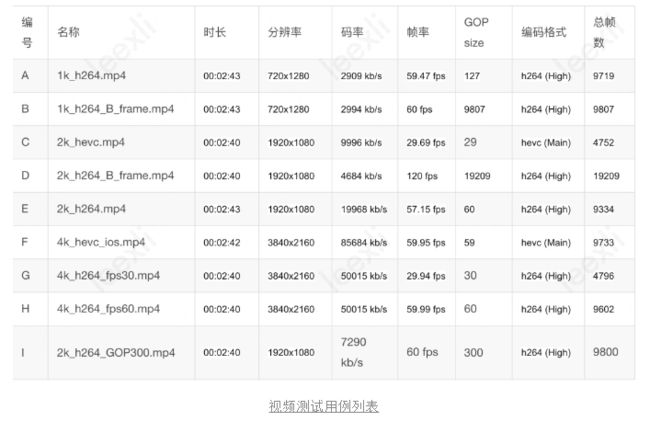
设备用例,多多益善,我们尽量覆盖了全部可以运行的云真机,其中手机芯片覆盖列表(61款机型)

demo自动化测试结果如下,其中用例编号对应上文的视频用例,分段数指将视频转码任务均分成几个work来执行。
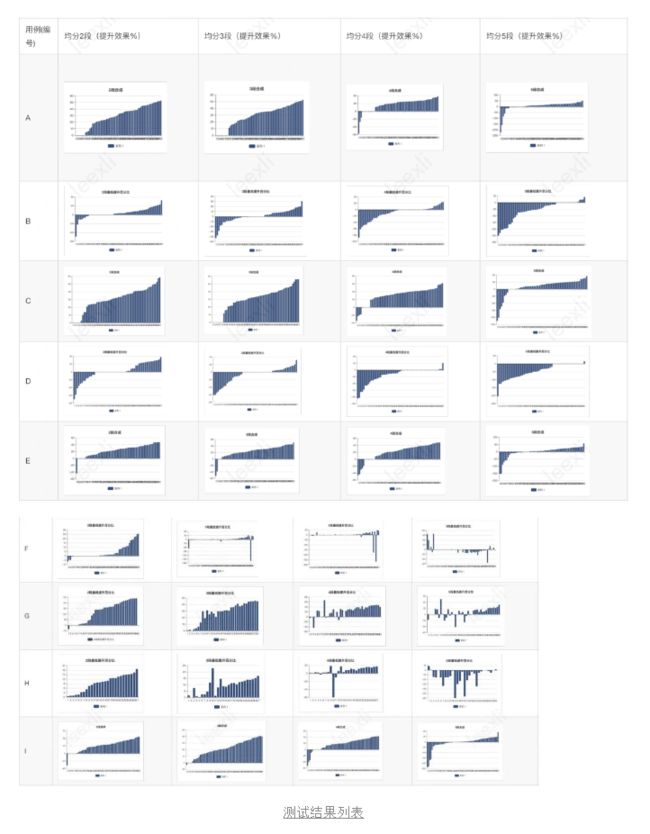
备注:正向的柱子表示当前分段下,相对于普通合成的耗时优化率。0表示当前合成任务因为一些原因导致失败。负向柱子表示当前分段下,相对于普通合成的耗时衰退率。
1.5 总结和推论
- A推论:低分辨率时,2-3段任务并行效果基本优秀30%以上;大于等于4段任务并行时,失败率增加(优化率<=0),优化效果降低。
- B推论:GOP很大时,失败率上升,并行数目增加,失败提升。
- A和C对比推论:2k Hevc视频结果基本和A一致,和视频编码方式无关。
- B和D对比推论:B结论和编码方式无关。
- A、C和E对比推论:A推论成立。
- F推论:4k视频时,段数增加失败率提升,提升效果不明显。
- F和G推论:4k视频时,帧率越高,分段失败率越高;30帧内4段任务开始出现失败率提升问题。
- F、G和H:4k视频时,帧率相同和编码方式相关,H264支持的更好一些。
- E和I:2k视频,GOP300左右,优化效果衰退较小,在可接受范围。
简单来说,并行合成并非对所有视频、所有手机都有很强的增益效果。不过对于常见分辨率或者30fps高分辨率视频而言(2k、4k_h264_fps30)有着不错的优化效果,值得进一步开发实现。

2.实现计划
v1.简单多实例导出任务,并行合成,合并多段h264文件。
导出任务用完即释放,任务时间区间大。实现起来较简单,可行性可以快速上线验证。
v2.细化导出任务粒度(导出时间区间),复用导出任务。
按照v1的方式,可能会发生,均分两段合成任务,但是其中一段合成快,另一段合成慢的情况,形成木桶短板效应。如果我们将时间粒度细化一点,复用导出任务,可以让时间的分配更加均匀,耗时更加优秀。
PS.不考虑【进一步细化导出任务模块,流水线复用各个模块】。
导出任务还可以细化分为解码、自定义渲染和编码模块;在工作环境中,导出任务的主要耗时都在编码模块,追求极致的性能优秀,我们可以更加细粒度去复用每个模块。然而我们并不考虑这么去实现,解码和编码都存在帧的前后相关相关性,内部存在帧缓存的逻辑,如果多个任务肆意篡改解码和编码顺序,会带来不必要的损耗和不可预期的错误。所以从理论层面直接pass掉这个方案。
**复用自定义渲染的逻辑:**需要评估下单独复用这里,造成的逻辑复杂成本和收益是否达到预期。
3.具体实现
3.1 逻辑梳理和实现
根据上面计划好的方案,整个工作涉及到的流程可以分为这四个部分:
**1.根据硬件条件,确认当前设备最大支持的并行任务数量。****2.根据既定策略,将长视频分割成多段独立的转码任务,也就是确定时间裁剪逻辑。****3.协调并行处理流程,处理好多编解码的复用逻辑和工作状态。**4.将多段h264文件以及aac文件生成最终mp4文件。
3.1.1 并行任务数确认
**分析:**个人认为这个问题是最复杂的,目前官方文档没有说明硬件的实际支持情况。更为重要的是,芯片的能力是整个手机共享,某个时刻的可用负载其实是变化且不确定的。
可以明确一点,最大并行任务数量肯定存在限制。多段并行之后,合成耗时并不是简单的成倍优化,而是提升了一定的百分比,说明转码流程中已经有步骤出现了耗时衰退的现象。要确认转码工作的最大并行任务数,我们需要找到当前限制的瓶颈在哪里。
转码过程主要包含5个子流程:解封装、解码、自定义渲染、编码和封装。其中封装逻辑只是流程发生变化,实现不需要多实例,具体和普通视频封装无异,不会成为瓶颈限制。
其他流程涉及到硬件相关,具体对应的Android系统接口为MediaExtractor(解封装)、MediaCodec(编解码)、渲染(GPU OpenGL)。
接下来,我们通过profile详细看下各个阶段耗时情况,具体分析当前的性能瓶颈。为了让效果更加明显,我们对比一下单段和5段的耗时分布情况。

视频信息:Duration: 00:01:15.84 Video: h264,yuv420p(tv, bt709), 2560x1440, 25042 kb/s, 30.01 fps 总帧数:2262 GOP:30
机型信息:SM-N9600 Android 8.1
普通耗时分析:
解码渲染耗时估算:(0.488+2.291+8.898)* 2262 ≈ 26413 ms
编码耗时估算:12.389 * 2262 ≈ 28032 ms
3段并行耗时分析:
第一段区间:[0-26000] 784帧
第二段区间:[26000,51988] 784帧
第三段区间:[51988,75375] 694帧
解码渲染耗时估算:(1.011+2.776+9.139 + 7.979)* 784 ≈ 16381 ms
编码耗时估算:26.755 * 784 ≈ 20975ms
理想情况下,3段提升的效率为300%,耗时可以优化20s左右,但是实际上只优化了11s;其中Encoder dequeueBuffer衰退带来的耗时为(7.979 - 0.432) * 2262 / 3 ≈ 5714 ms,可以基本确认主要耗时衰退都来自这里。也就是多段任务并行之后,主要的限制在于MediaCodec编码器的功效。
除此之外,还有一些失败的case,在强制设置分段并行后,MediaCodec初始化失败,在一定程度上也说明当前硬件资源不足以支持。
那么可以得出结论:限制最大并行任务数的条件为当前MediaCodec实例数量和MediaCodec最大负载能力。

关于MediaCodec实例数量,在Android平台上,我们可以通过MediaCodecInfo.CodecCapabilities类,获取当前设备MediaCodec的一些能力支持情况。不过,按照过往经验来看,这里的数值仅仅具有参考意义,并不能作为可靠的参考数据。
进行一些简单的测试,选取小米8 se作为测试机型,我们设置分辨率为720x1280,码率为3500kbps来创建MediaCodec实例,我们可以看到如下图所示信息。
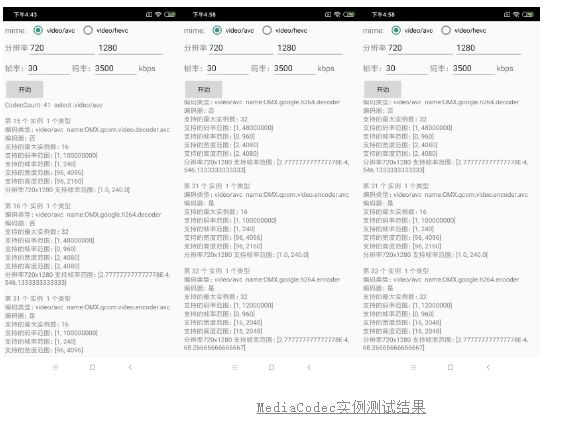
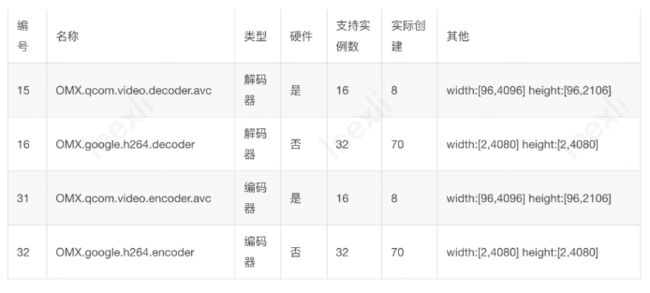
设备一共有41个编解码器类型,其中支持avc编码格式共有4个类型:
//创建实例代码
codec = MediaCodec.createDecoderByType(mime)
val mediaFormat = MediaFormat.createVideoFormat(mime, width, height)
mediaFormat.setInteger(MediaFormat.KEY_FRAME_RATE, frame)
mediaFormat.setInteger(MediaFormat.KEY_BIT_RATE, bitrate * 1000)
codec.configure(mediaFormat, null, null, 0)
通过实际验证,我们可以看到MediaCodec实际支持的实例个数其实并不太准确,最大实例数需要创建出来才能确认。(ps:其中带有google开头的编解码器,为goole自己实现的软编逻辑,暂时仅仅考虑硬编场景;)
CodecCapabilities本质也是从系统中读取配置文件,那我们直接从Android系统文件中读取对应的配置文件/vendor/etc/media_codecs.xml,可以获取更多一些关于MediaCodec的信息。
······
可以看到里面有一句注释很显眼, ,等价最大4096x2048分辨率。如果按照这个理解,那么,配置文件中字段"block-size"、"block-count"和"blocks-per-second"可以表示为当前编解码器支持工作时处理宏块的size、每秒处理宏块的数量等信息。通过进一步和厂商沟通,也确认了以上推论无误。
block-size * block-count = 当前处理最大分辨率
161632768 = 8388608
4096*2048 = 8388608
这里说明解码器在最大利用率时,可以处理一张4096*2048的图像,并且把它们划分为32768个16x16的宏块同时处理。另外通过"blocks-per-second",我们可以知道对当前芯片而言,每秒最多处理这么多宏块,可以由此计算出来处理帧率为:1966080/32768 ≈ 60 帧。
**处理帧率 = 芯片每秒宏块数量 / 单次处理的宏块数量 **
为了快速验证效果,我们先利用现网大盘数据的实际处理帧率作为经验值,通过理论处理帧率/大盘实际处理帧率,估算出来最大并行任务数量。
3.1.2 长视频分割策略
目标:将长视频划分为多段“均衡且合理”的时间区间。所谓均衡,就是最好多段并行任务同时结束;所谓合理,就是分割策略不能带来多余的性能和资源损耗。
均衡的目标比较好理解,也比较好实现,只要让长视频分段后,每段任务的时间区间基本相同,理论即可达到均衡的目标。但是简单均等分割并不是合理的方案,在这里我们在继续补充一些视频相关的知识,理解什么才是合理的分割条件。
先来了解下视频中的IBP帧概念。
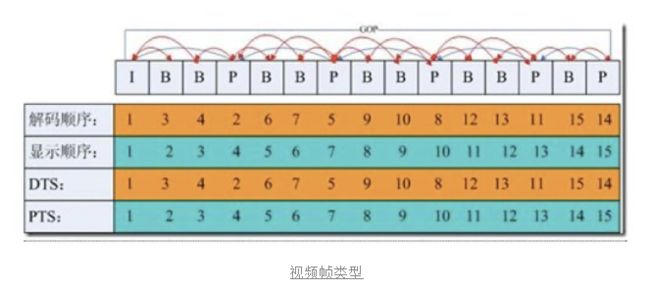
视频压缩中,每帧都代表着一幅静止的图像。而在进行实际压缩时,会采取各种算法以减少数据的容量,其中IPB帧就是最常见的一种。
I帧:帧内编码帧(intra picture),I帧通常是每个GOP(MPEG所使用的一种视频压缩技术)的第一帧,经过适度地压缩,作为随机访问的参考点可以当成静态图像。I帧可以看做一个图像经过压缩后觉得产物,I帧压缩可以到6:1的压缩比而不会产生任何可觉察的模糊现象。I帧压缩可去掉视频的空间冗余信息,下面即将介绍P帧和B帧是为了去掉时间冗余信息。
**P帧:**前向预测编码在帧,通过将图像序列中前面已编码帧的时间冗余信息去充分去除压缩传输数据量的编码图像。
**B帧:**双向预测内插编码帧,既考虑源图像序列前面的已编码帧,又估计源图像序列后面的已编码帧之间的时间冗余信息,来压缩传输数据量的编码图像,也成为双向预测帧。
基于上面的定义,我们可以从解码的角度来理解IBP帧。
P帧需要参考其前面一个I帧或者P帧来解码成一张完整的视频画面。
B帧则需要参考前一个I帧或者P帧及其后面一个P帧来生成后面一张完整的视频画面,所以P帧与B帧去掉是视频在时间维度上的冗余信息。
GOP就是两个I帧之间的间隔。
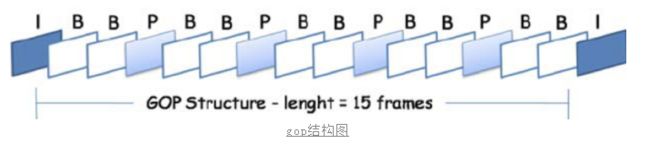
如果我们分割策略不对,很容易造成,为了解码当前帧,而去重复解码当前GOP的开头数据,如果GOP数据很大,分片有很多的话,这里也会造成很多不必要的损耗。
所以我们以I帧作为筛选区间即可避免上述问题。
那么我们就找到了最细粒度的划分条件:I帧间隔*N。
那就引入一个新的问题,对于一个给定的视频,我们如何快速高效找到在我们想划分区间内的I帧的时间戳呢?
这里有两个办法:
** 其一:**通过ffmpeg解封装,利用av_read_frame 函数解封装得到 AvPacket,即可得到当前帧的类型和时间戳。
** 其二:**我们可以通过MediaExtractor的seekto(timestamp,SEEK_TO_NEXT_SYNC)方法,找到距离当前区间最近的下一个I帧,循环执行多次seek即可完成区间划分。从而避免了去解码每一帧的耗时操作。
但是其实我们并不需要知道所有的I帧时间戳,我们只是想知道某几个间隔附近的I帧时间戳。这里我们选择方案二,在指定的分割区间内,尝试seek几次,即可得到任务分割的区间,快捷高效。
3.1.3 多实例编解码器复用管理
在当前转码实现的逻辑下,抽象单段任务model,分别对应了任务类型(视频、音频),对应的解码模块、渲染和编码模块等。
其中PipelineWorkInfo表示具体的转码work,负责管理独立的转码任务。
public static final int PIPELINE_TYPE_VIDEO = 1;
public static final int PIPELINE_TYPE_AUDIO = 2;
public class PipelineWorkInfo {
public int type;
public AssetReaderOutput readerOutput;
public AssetWriterInput writerInput;
public HandlerThread thread; //转码线程
private PipelineIndicator indicator;
public AssetWriter assetWriter;
}
当中的PipelineIndicator表示当前段任务的指示器,分别记录当前段的任务时间间隔、完成状态和进度等信息。通过这种方式抽离合成数据和转码work,为后面复用work,做出准备。
public class PipelineIndicator {
private int index; //任务index
public AssetParallelSegmentStatus segmentStatus; //当前段的状态
public AVAssetReaderStatus readerStatus; //解码模块状态
public AssetWriterStatus writerStatus; //编码模块状态
//范围0-1f
private float progress; //进度
public CMTimeRange timeRange; //时间区间
}
其次是多任务管理模型,这里主要注意多线程的处理,并无太大难点。
3.1.4 分段h264文件合并
在工作开始前的理论分析中,我们已经确认了此方案是可行的。我们具体需要做的就是将多段H264文件按照单段的逻辑进行拼接。
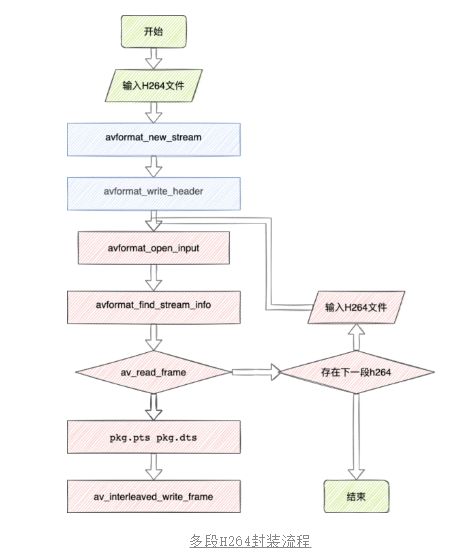
让我们先看下目前单段处理的逻辑,其中主要逻辑为视频文件创建新的轨道后,将H264文件中的frame循环写入,并为每一帧都附上pts和dts,直到写入完毕,完成封装。
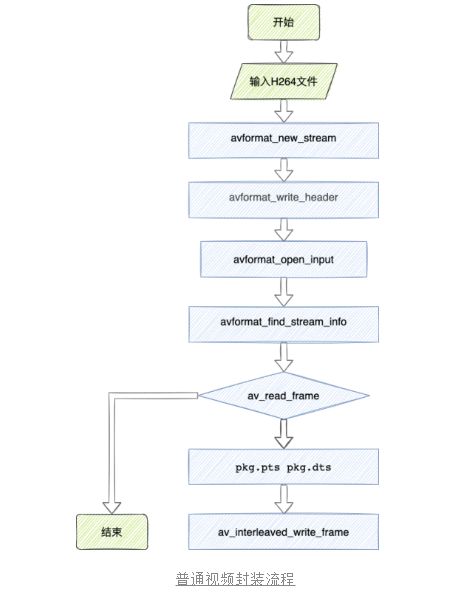
那么对应多段H264文件的封装,前置的流程不需要改变(为视频文件创建视轨),我们需要修改的流程为单段H264文件写入完毕后,判断是否还有剩余的H264文件,如果还有文件,则继续写入,流程图如下。
しかし,这件事情并非如此简单。

我们写入每一帧数据的时候,需要为每一帧都指定pts和dts。合法的视频文件对这两个时间戳有着严格的要求。
1.dts单调递增。
2.pts大于等于dts。
对应单段视频而言,这两个问题比较好解决。但是对应多段视频而言,我们得到的pts和dts都是从0开始,这意味着我们需要自己处理多组时间戳偏移,按照要求把他们拼接成1组满足要求的时间戳。
这里也是坑比较多的地方:
PTS和DTS在开头会有一些特殊数据,比如连续两个0,或者负数开头,这就会让我们拼接的时候发生难度;更恶劣的是,有时候在中间还会吐脏数据(问题原因待确认);还有另外一些情况,pts末尾数值为-1或者数值很大。
这些问题都给我们合法的拼接时间戳带来了挑战,我主要通过以下几个策略来实现目标:
策略:
确保开头数据合法:检查开头数据是否有重复0、负数或者大偏移数值的,统一改成0开头的时间戳。同时设置偏移值,后面的时间戳都会被偏移值修改为合法数据。
确保拼接处数据合法:优先检查当前时间戳集合的末尾数据,确保最后一个数据是合法的;如果不合法,按照上一帧和当前帧率,重新计算赋值合理的帧时间戳。随后检查待拼接的前两帧数据,按照上一步骤的方法,先做“合理化数据”操作,其次在累加上一帧的时间戳作为偏移。
拼接完成后,在封装mp4时多做一次检查,确保合成mp4的数据是合法的。如果存在较大问题,比如合成时间异常等,则按照失败处理,确保合成结果的可靠性。
3.2 覆盖率优化
V1版本方案实现之后,我们再次运行wetest尝试,分析数据得到并行覆盖率为58.75%,明显低于本文开始前的实验数据。经过分析,主要原因为通过CodecCapabilities计算出来的“每秒处理帧率数”太过于严格,亦或者是不支持当前分辨率,走了默认逻辑,导致覆盖率降低,然而实际情况是大部分case都是可以支持并行转码的。

另外,V1版本方案的最大并行任务数,是根据经验值估算的,或多或少会存在偏差,我们需要做到极致的优化,那就需要更为稳妥的方案。接下来思考,如何设计最优并行任务数的计算逻辑。
发现了问题就等于成功了一半!!!
**明确矛盾点:**目标:尽可能的发挥MediaCodec的能力。 矛盾点:无法当前时刻MediaCodec的最大能力。
**问题抽象:**拥塞控制
和TCP拥塞控制面临的问题一样,我们希望尽可能大的利用当前带宽,但是我们并不知道当前网络的拥塞状况是怎样的。所以我们是不是也可以参照TCP拥塞控制策略,指定一套转码拥塞控制方案。参照TCP的处理策略:慢启动和快恢复。
但是我们的场景还是和TCP网络环境有一点区别,网络环境是在实时变化,快速波动的;但是对于手机设备MediaCodec的负载而言,短时间内是稳定的,所以我们不用考虑快恢复,重点处理下慢启动的逻辑。
**3.2.1 慢启动 **
所谓慢启动,就是我们逐步开启新的转码任务,直到达到芯片编解码的极限。那么核心问题就来了,怎么判断芯片是否达到当前最高负载呢?在最开始的分析中,我们有计算当前MediaCodec理论处理的帧率极限,首先这是一个理论值,其本身是否可靠存在疑问;其次整个Android系统中,其他app对应MediaCodec的使用情况,我们不得而知;另外大部分情况,编解码的分辨率不一致,不确定这种模式下的计算逻辑还是否满足上面的公式。
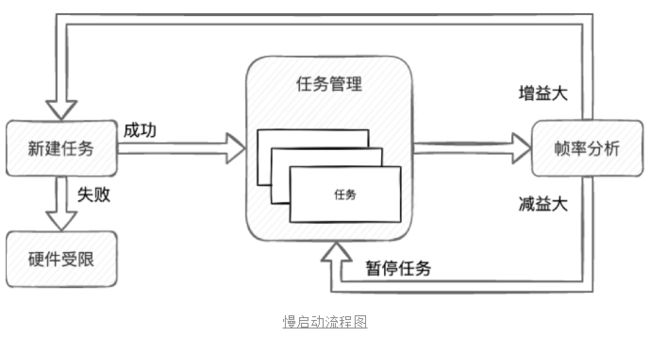
那么,我们真的需要获取精确的负载数值?在TCP协议中是如何确定网络进入了拥塞状态的,TCP认为网络拥塞的主要依据是它重传了一个报文段。同理映射到我们当前的系统,可以认为判断依据是单帧处理超时。然而我们不能直接用这个指标,经过统计分析,多段模式下,会存在个别帧耗时异常的情况,新建转码任务是需要消耗资源的,我们希望寻找更为“稳重”的参考依据,所以我们将依据修改为:每秒处理的帧率。
如下图所示,我们新建任务后,任务管理模块会定时去分析每秒处理的帧率,如果我们判定帧率提升的足够大,则继续尝试新增一个并行任务;如果任务创建失败,则认为是当前硬件首先,后面将忽略帧率的增益限制,不会再创建新的任务。同理,如果新建任务后,处理帧率反而下降,说明当前的策略有问题,则暂停刚才新建的任务。不过由于我们启动参考的依据比较稳定,这个分支一般很少走到。
**3.2.2 转码任务复用 **
既然已经确认了当前MediaCodec的最大负载,也就是确认了最大并行任务数。但是又有新的问题产生,我们无法保证,长视频的分段数就是刚好等于最大并行任务数量。那就可能会发生短板效应,其他任务已经完成,最后只有一个任务在跑。比如视频分了4段,但是并行任务同时只有3个在运行,假设前3段任务基本同时完成,此时整体时间就变成了“2段”转码的耗时,优化效率大大降低。
此时就需要我们继续扩展实现计划【V2-细化导出任务粒度(导出时间区间),复用导出任务】,我们将视频分段设置的足够小,那么就最终的短板效应就可以小到忽略不计。(不过这里事实上也不是越短越好,一个正常的转码流程中,码率不是恒定的,往往画面复杂度高的画面会需要更多的码率;简单的画面可以降低码率,从而实现整体码率恒定,而清晰度获得不错的提升,这里也就要求分段时长不能过短。)
分段策略上面已经介绍过了,下面的重点就变成了如何复用转码任务。
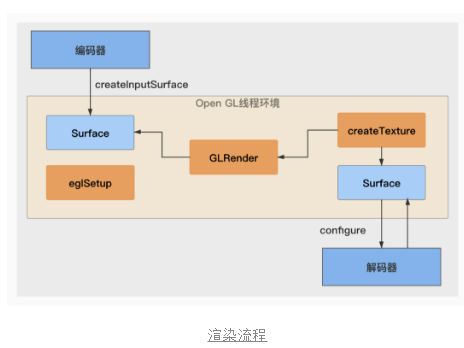
一个标准的转码流程如下图所示,创建编码器后,获取编码器的surface,通过当前surface创建EGL环境,在当前EGL环境中通过新建纹理创建一个surface,然后将当前surface设置给解码器,解码到当前纹理上。
当我们执行完一段转码任务后,我们在分别在decoder和encoder输入end-of-stream信号,当输出端收到刚才的eos信号时,任务结束。
下图是Google官方给的MediaCodec的状态图,我们可以看到在Eos之后,可以通过flush重置MediaCodec的状态,清空之前缓存的数据,那么此时就可以复用整个转码环境了。但是,事实如此吗?
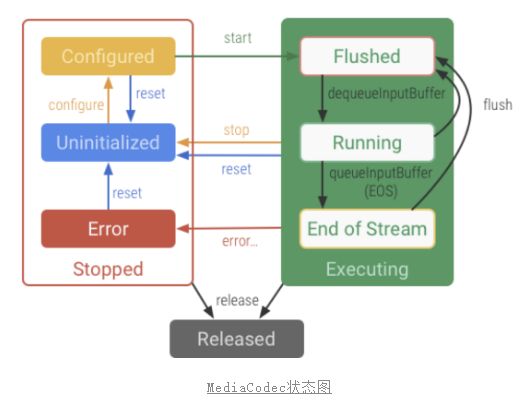
通过实际测试发现,在执行flush之后,MediaCodec无法复用。我们尝试重新输入数据,编码器却进行异常提示:onFrameAvailable: EOS is sent, ignoring frame。

如下图所示,通过进一步分析MediaCodec底层源码,我们可以看到内部GraphicBuffer在收到EOS之后,会将标志位mEndOfStreamSent设置为true,将不会再抛出数据。

那么我们是否有办法能重置这个标志位呢?可以看到除了初始化之外,还能通过confire方法设置mEndOfStreamSent为false。
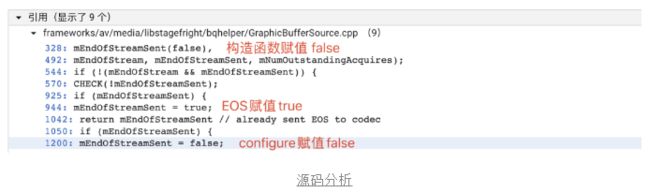
但是,MediaCodec的状态机管理,只允许从在NITIALIZED状态下configure,只能说此路不通。从文档上看通过QueueBuffer模式可以触发复用,但是相较于Surface方案(可以避免数据格式的转换和避免中间数据的拷贝),性能较低,这里不考虑。

那么接下来问题就再度转换,变成尽可能将视频分段数和视频转码并行任务数保持一致,避免短板效应。
3.2.3 分段数命中率优化
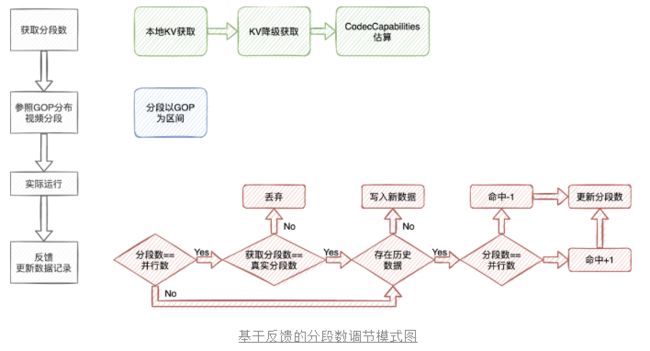
既然我们无法一开始就获取最合适的分段数,那么我们能采取的策略,就是通过后续的转码数据,不断优化并行分段数的逻辑,也就是基于反馈的维护模式。
如下图所示,在获取分段数时,我们首先尝试从本地KV获取当前分辨率的分段数记录,KV存储中的key为【视频宽高/1000】,通过这种方式将分辨率接近的数据归纳到一起,比如12901920/1000=22。如果当前分辨率没有数据,尝试找分辨率比较接近的一组数据,误差在一定范围以内,如果还是没有找到数据,则尝试根据CodecCapabilities估算分段数。
随后我们按照分段数,将原视频按照GOP为划分区间进行分段。在一些情况下,如果视频时长比较短或者视频GOP比较大,也会去影响实际的分段数。也就是说,实际分段数应该是小于等于建议分段数。
在任务执行完毕后,我们再次根据当前任务实际的最大并行任务数量,来更新本地记录。如果当前分段数和真实并行数不相符,说明当前的分段已经超过了手机的负载极限。那么判断当前是否有记录,如果无记录则直接新增记录;如果存在记录,则再根据分段数和并行数是否相等,反馈更新命中,当命中降低为0,或者超过一定次数,则再动态减少或者增加本地分段记录。其他分支流程也是一样,实现反馈调节的目标。
3.2.4 思考极致优化方案----负载均衡
再次思考一下我们的目标是什么,充分利用硬件性能,降低转码耗时。上面的工作在很大程度来说,只是完成了负载尽量高,但是没有特别的操作使得负载一直维持在最高。
理论上是可能发生这种情况,一部分时间内,负载没有到达极限;而另一部分时间,发生排队的现象;让我们profile看下具体的效果。
如下图所示,前三行分别表示3个解码渲染线程,后3行对应3个编码输出线程。我们可以看到解码是dequeubuffer的耗时其实分布不均匀的,并且杂乱的排布。
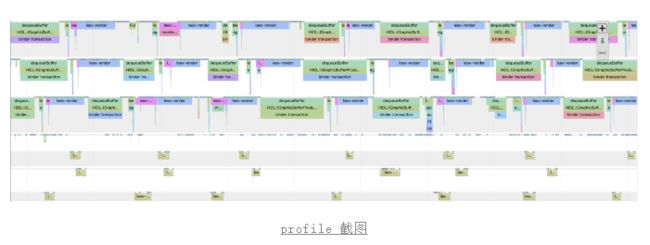
那么我们是否有办法能做到让整个编解码的负载均衡负载呢?目前来说,没有办法。主要原因还是我们没法获取当前编解码的状态,MediaCodec具体内部的状态目前是处于一个黑盒的情况。我们只能外部通过queuebuffer的操作来大概维护整个编解码的流程,更准确一点的描述应该是:通过控制输入的时间点,从而控制整个流程的时间执行阶段。
采取上面这种方式,又会产生两个问题,第一点是无法精确计划每一帧编码任务开始的时间点,比如当前是同时执行两帧的任务亦或者更多;第二点是在多线程模式下,这里的复杂度会成倍上升。最终评估,这里预期产生的收益不足以抵消上面两个问题带来的成本,遂此方案没有继续深入实现。
ps:实际上这个方案也是花费了很长时间profile数据,详细分析每个阶段的耗时占比,尝试找出多段并行后,那个阶段耗时出现退化,最终发现耗时在dequeubuffer上出现退化,可以理解为编解码器当前正在处理数据,所以dequeubuffer出现等待。
3.3 性能优化
到目前为止,我们算是实现标准的并行转码工作,不过到这里整个工作只能算完成了8成,接下来我们还需要进一步分析下性能数据,将效率优化成。

3.3.1 cpu使用率优化
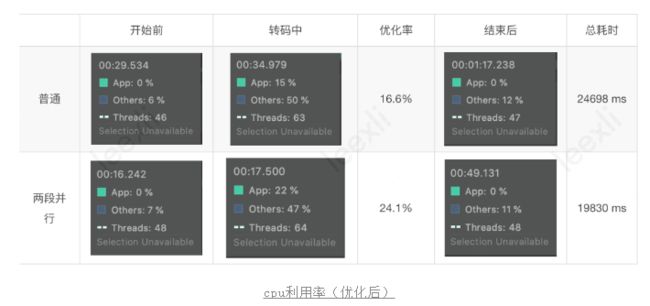
我们先分析下普通模式下的CPU使用率,分析方式为通过profile转码过程中主要线程的方法耗时。
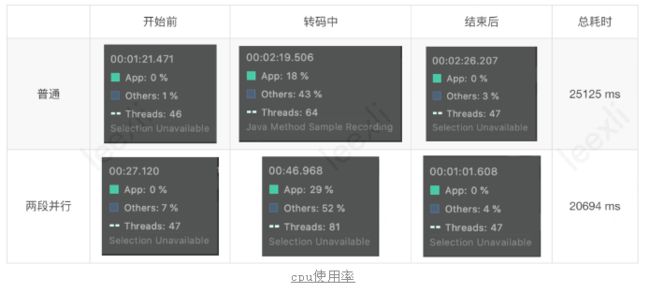
测试用例:Duration: 00:01:02.66 1080x1920, bitrate:19926 kb/s fps:60 输出信息:720x1280 bitrate:3500 kb/s fps:30测试机型:Google Pixel 5
可以看到使用前后,cpu使用率可以完美归零,说明整体没有性能泄露的情况,其中转码过程中,cpu使用率稳定在18%左右,让我们详细分析下具体每个线程的使用情况,具体如下图所示。

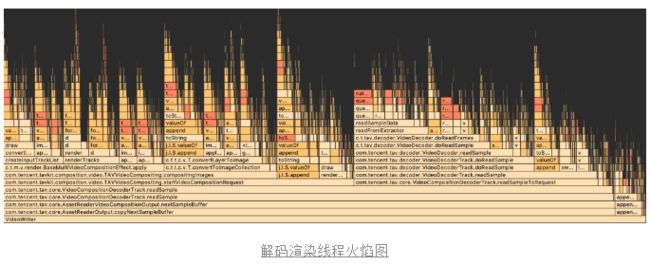
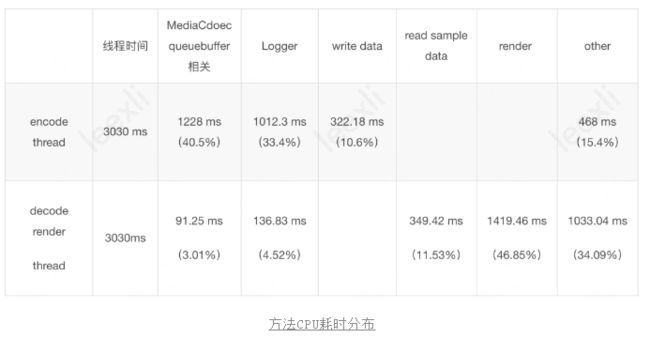
为了方便分析,我们把主要方法的耗时整理到了下面的表格中。我们对主要耗时的方法进行逐个分析,其中MediaCodec、read sample data相关的接口耗时,属于流程需要,暂时没有优化空间。render方法的真实耗时在GPU上,这里的耗时不一定代表真实的消耗。
不过可以看到其中Log的打印占据了不少线程时间,主要消耗在于string拼接,这里的流程是有问题的,Debug级别的日志,真实场景下不会输出,但是目前的实现方式,却在打印之前做了string拼接,频繁的日志打印导致这里反而成了性能的瓶颈。这里优化成,提前判断log等级,只有当log需要输出时,才会去拼接string。
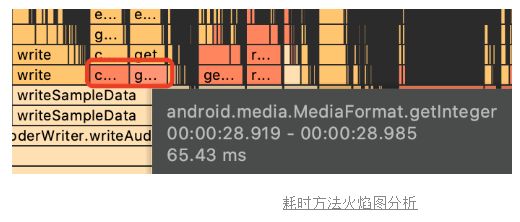
备注:profile模式下,所有耗时都会上升,性能也会有所下降。另外CPU耗时只能在一定程度上体现CPU使用率,渲染实际是在GPU执行,此时CPU出于等待状态,并不会造成很大损耗。
除此之外,我们也分析下wirte data方法,在写入音轨时,我们需要重新处理音频数据,为每一帧添加adts头,这里原本实现每次都会去format里获取音频的一些信息,导致消耗了将近130ms时间,这里优化成只有第一次去获取信息,降低耗时。
在完成上述优化后,再次profile获取cpu的使用,可以看到转码过程中耗时占据比较多的log已经没了。
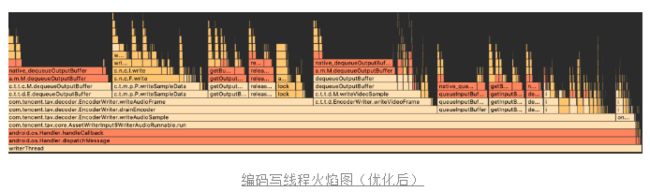
我们在看下全局的优化效果,可以看到cpu使用率在转码期间稳定时候,大概下降了2%,还是略有成效的。不过耗时整体基本没有变化,这是因为编码写入线程并不作为转码耗时的短板,只是作为一个子线程在不停获取编码数据。
3.3.2 内存优化
接下里在让我们看看内存相关的数据,测试用例信息同上。
如下表格所示,普通合成过程中,内存增量主要是Graphic内存上升导致,其中增量为92.3M;在相同场景下,开启2段合成逻辑后,稳定时Graphic内存上升约160M。
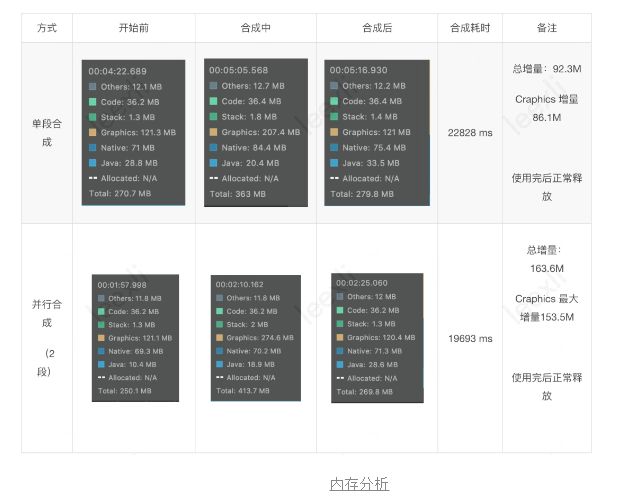
同理可推论,在相同情况下,开启4条或者更多并行任务时,势必会对系统内存造成比较大的负载,这里有必要分析下具体的内存增量来源,以及是否存在优化的空间。
先让我来看下当前的整个渲染流程。主要分为三个步骤,第一步将视频解码到OES纹理,然后对OES纹理进行缩放和格式转换,输出为普通纹理;第二步针对用户选择的效果,依次执行每个步骤的效果渲染;第三步将最后渲染结果的纹理渲染上屏。

为了更好的分析,我们详细分析一下Graphic内存增量来源。目前业界没有很好的graphic内存分析工具,目前我采用的方案是hook纹理的创建和释放方法,从而大致估算出来当前graphic内存分配情况。
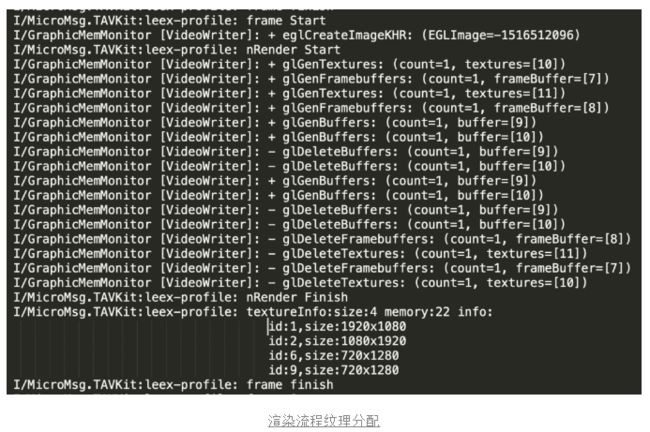
在结合上面的内存分析,主要的Graphic内存增量有两部分:Java层纹理申请和Effect Render 纹理申请。

排除其他分配,还有50M显存应该是来自GL环境相关的内容。
按照之前的设想,针对显存优化,是否可以优化渲染流程呢?
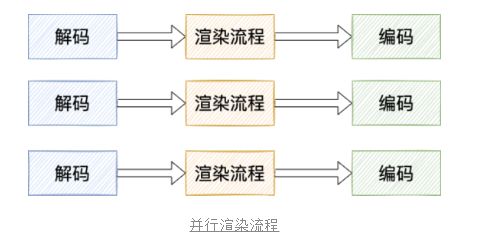
我们将三个渲染流程合并,此时渲染环境就变成1个,并且瞬时最大纹理数量也会降低。
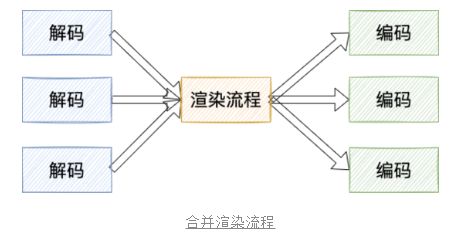
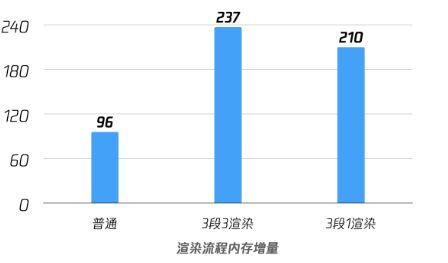
实现之后,观察效果,发现收益不够明显,3段1渲染流程相较于3段3渲染,显存优化27M左右,优化率10.1%,我们还需要更大的优化!
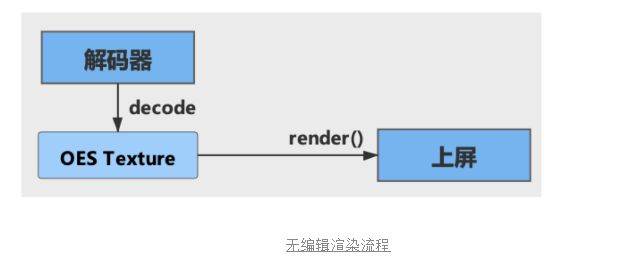
但是实际上,针对长视频而言,目前是不存在编辑行为的;退一步讲,一分钟内的视频,用户也有可能选择不编辑视频,所以这里的流程其实也是存在优化空间的。针对无编辑视频,我们应该跳过无效渲染流程,包括中间全部的无效渲染流程,这对内存和耗时都将会有不错的优化。
具体修改方案如下图所示,在判断用户不存在图像效果编辑时,则跳过所有中间流程,直接在上屏时做纹理缩放,实现压缩分辨率的目的。
再来看看具体的优化效果:

结果:最终看下我们优化的效果,合成耗时从25125ms优化为17184ms,优化将近31.6%(当前手机按照策略,最大并行数为2);普通模式下内存优化率29.3%,CPU使用率优化2%。
3.4 最终效果
接下来看下现网具体的运行数据,分别为多段并行和普通模式的效率对比。绝对时间优化的图标可能会涉及敏感数据,暂时不放上来。
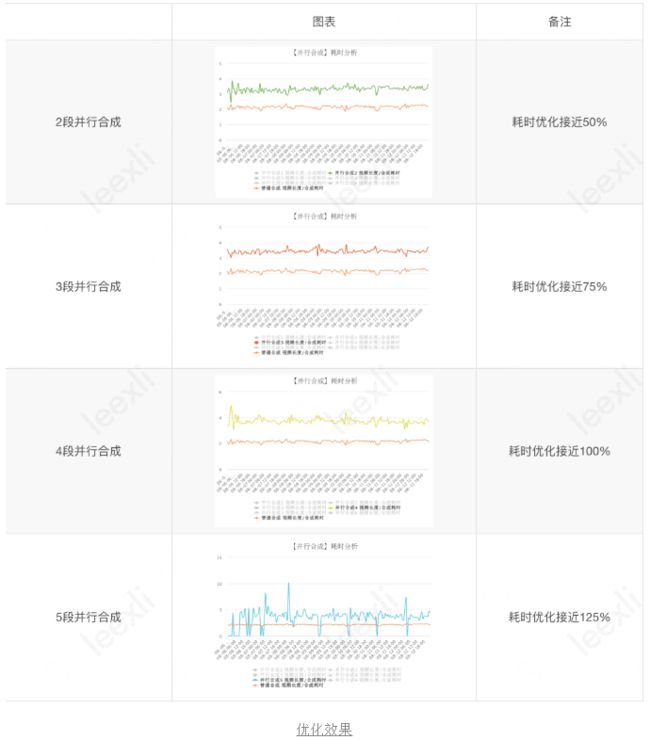
备注:耗时优化效果,具体指标为 视频时长/输出耗时
再来看看理论分段数的覆盖率,分段数大于1的用例接近93.4%,相比之前有了很大的提升。
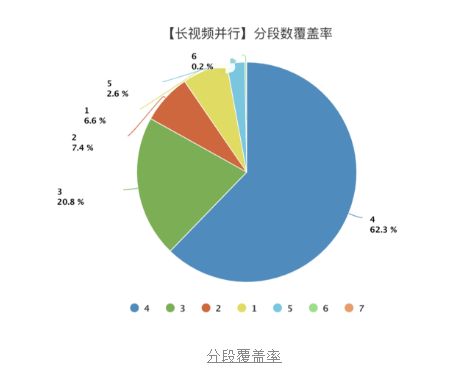
理论分段数超过1段的视频中,超过**99.9%**的视频成功运行到并行的逻辑,也就是实际运行的并行任务数大于等于2,效果拔群。
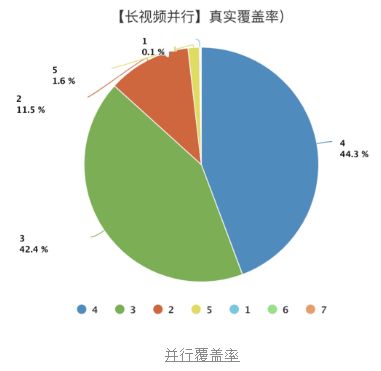
最后总结
1.分析时间相关性,提出视轨并行编码方案,理论分析可行。
2.预测效果,长视频均分多段,同时多实例运行转码任务,大部分手机有着不错的增益,预估耗时提升超过30%。
3.分析和实现4步流程(任务数确认、分割策略、流程管理和多段H264文件拼接),并行覆盖率待优化。
4.profile分析多实例转码瓶颈,提出转码拥塞控制慢启动策略以及基于反馈的分段数据维护。
5.性能优化,Android源码问题导致转码任务无法复用。
6.CPU使用率优化。
7.渲染流程优化,非编辑视频跳过中间渲染流程,优化Graphic内存和耗时。
8.数据展示