卷积神经网络中的分类与回归
文章目录
- 数据增强
- 卷积神经网络的发展
-
- LeNet
- AlexNet
- VGGNet
- ReseNet
- 分类网络的实现
- 模型训练
-
- 损失函数
- 优化器
- 学习率
- 训练与验证
- 模型展示
- 多标签分类
-
- 验证码生成
- 模型搭建
- 模型训练
- 验证码识别
数据增强
数据增强是一种在训练模型过程中用于提高样本多样性,增强模型泛化能力的手段。在对图像进行数据增强时,必须保留图像中与标签对应的关键信息。使用了两种数据增强手段:随机裁剪和随机翻转。其中随机裁剪是先在图片外围补存4个像素,然后在图片中随机裁剪32×32图片的方法:随机翻转是按一定概率选择是否对图片进行翻转处理的方法。这两种手段都不会改变图片原有的信息(随机裁剪后保留的信息占原图的比例足够大,所以信息会得以保留)。
#coding=utf-8
import cv2
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from sklearn.datasets import make_blobs
from torchvision.models import resnet18
from torchvision import transforms
from PIL import Image
#定义设备
device=(
torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
)
#数据目录
data_folder="/data/cifar10"
#模型存储目录
checkpoint_folder="/data/chapter_one"
#每一个批次图片的数量
batch_size=64
#随着训练的次数增加,逐步缩小学习率
epochs=[(30,0.001),(20,0.001),(10,0.0001)]
#标签列表
label_list=[
"airplane" , "automobile" , "bird" ,"cat" ,"deer" ,"dog" ,
"frog" , "horse" , "ship" ,"truck",
]
import torchvision
from torchvision import transforms
import torch
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
import sys
from config import data_folder
#将上级目录加入系统目录
sys.path.append("..")
def show_batch(display_transform=None):
#重新定义一个不带Normalize的DataLoader,因为归一化处理后的图片很难辨认
if display_transform==None:
display_transform=transforms.ToTensor()
#解压数据
display_set=torchvision.datasets.CIFAR10(
root=data_folder,train=True,download=True,transform=display_transform
)
#训练集加载器,自动分割成batch
display_loader=torch.utils.data.DataLoader(display_set,batch_size=32)
#将数据转换为图片
topil=transforms.ToPILImage()
#获取图片
for batch_img,batch_label in display_loader:
#将图片拼接
grid=make_grid(batch_img,nrow=8)
#将图片转换
grid_img=topil(grid)
#显示图片
plt.figure(figsize=(15,15))
plt.imshow(grid_img)
grid_img.save("./img/trans_cifar10.png")
plt.show()
break
if __name__=="__main__":
transform_train=transforms.Compose(
[transforms.RandomCrop(32,padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]
)
show_batch(transform_train)

可以看到,处理之后的图片虽然与原图片稍有不同,出现了有一些黑色边框,但是图片中的主要内容保持不变,也就是保证了数据增强之后标签的真实性。
import torchvision
from torchvision import transforms
import torch
from config import data_folder,batch_size
#创建数据集
def create_datasets(data_folder,transform_train=None,transform_test=None):
#训练过程中的图像增强与数据转换
if transform_train is None:
transform_train=transforms.Compose(
[
#扩张之后再随机裁剪
transforms.RandomCrop(32,padding=4),
#随机翻转
transforms.RandomHorizontalFlip(),
#将图片转换成Tensor()
transforms.ToTensor(),
#根据CIFAR-10数据集的各个通道上的像素均值和方差进行归一化处理,使模型更易拟合
transforms.Normalize(
(0.4914,0.4822,0.4465) ,(0.2023,0.1994,0.2010)
),
]
)
#测试过程中的数据转换
if transform_test is None:
transform_test=transforms.Compose(
[
#测试过程中的数据转换
transforms.ToTensor(),
transforms.Normalize(
(0.4914,0.4822,0.4465) ,(0.2023,0.1994,0.2010)
),
]
)
#训练集
trainset=torchvision.datasets.CIFAR10(
root=data_folder,train=True,download=True,transform=transform_train
)
#训练集Loader
trainLoader=torch.utils.data.DataLoader(
trainset,
batch_size=batch_size,
shuffle=True,
num_workers=2
)
#测试集
testset = torchvision.datasets.CIFAR10(
root=data_folder,
train=False,
download=True,
transform=transform_test
)
#测试集Loader
testLoader=torch.utils.data.DataLoader(
testset,
batch_size=batch_size,
shuffle=False,
num_workers=2
)
return trainLoader,testLoader
两个数据集经过DataLoader封装成批次数据,便可以输入模型中进行并行训练了。
卷积神经网络的发展
LeNet
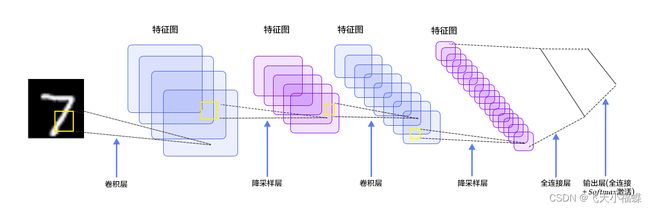
LeNet-5是一个较简单的卷积神经网络。下图显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。
1、INPUT层-输入层
首先是数据 INPUT 层,输入图像的尺寸统一归一化为32*32。 注意:本层不算LeNet-5的网络结构,传统上,不将输入层视为网络层次结构之一。
2、C1层-卷积层
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小 为 55 的卷积核),得到6个C1特征图(6个大小为2828的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为55,总共就有6(55+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的55个像素和1个bias有连接,所以总共有1562828=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
3、S2层-池化层(下采样层)
详细说明:第一次卷积之后紧接着就是池化运算,使用 22核 进行池化,于是得到了S2,6个1414的 特征图(28/2=14)。S2这个pooling层是对C1中的2*2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。于是每个池化核有两个训练参数,所以共有2x6=12个训练参数,但是有5x14x14x6=5880个连接。
4、C3层-卷积层
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 55. 我们知道S2 有6个 1414 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。
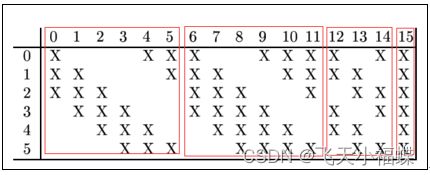
C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为55,所以总共有6(355+1)+6*(455+1)+3*(455+1)+1*(655+1)=1516个参数。而图像大小为10*10,所以共有151600个连接。
5、S4层-池化层(下采样层)
详细说明:S4是pooling层,窗口大小仍然是2*2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。这一层有2x16共32个训练参数,5x5x5x16=2000个连接。连接的方式与S2层类似。
6、C5层-卷积层
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下:
7、F6层-全连接层
详细说明:6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。ASCII编码图如下:

8、Output层-全连接层
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
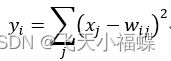
上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接。
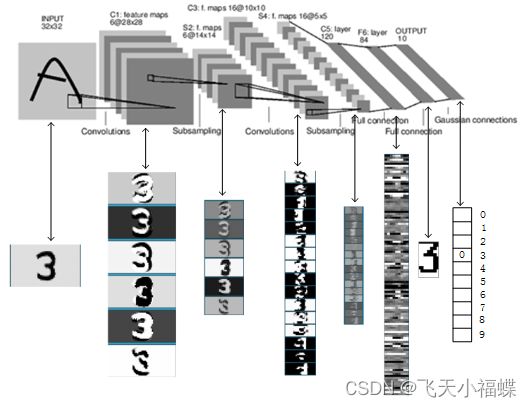
原文来自:https://www.cnblogs.com/duanhx/articles/9655228.html
AlexNet
AlexNet中主要提出了ReLU激活函数和Dropout方法,同时还引入了数据增强操作,使用模型的泛化能力得到进一步提高。
AlexNet中包含了5个卷积层和3个全连接层,层数比LeNet多,但是卷积、池化这样的总体流程没有改变。AlexNet中用到的3个训练技巧对最终的结果起到了积极作用。整个AlexNet前5层为卷积层,后3个为全连接层,其中最后一层是1000类输出的Softmax分类输出层。LRN层在第1个及第2个卷积层之后,Max pooling层在两个LRN层之后和最后一个卷积层之后。ReLU激活函数跟在5个卷积层和2个全连接层后面(最后输出层没有)。因为AlexNet训练时使用了两块GPU,因此这个结构图中不少组件都被拆为了两部分。现在我们GPU的显存足够大可以放下全部模型参数,因此只考虑一块GPU的情况。
Input:图片尺寸224*224
Conv1:卷积核11*11,步长4,96个filter(卷积核尺寸较大)
ReLU
LRN1
Max pooling1:3*3,步长2
Conv2:卷积核5*5,步长1,256个filter
ReLU
LRN2
Max pooling2:3*3,步长2
Conv3:卷积核3*3,步长1,384个filter
ReLU
Conv4:卷积核3*3,步长1,384个filter
ReLU
Conv5:卷积核3*3,步长1,256个filter
ReLU
Max pooling3:3*3,步长2
FC1:4096
ReLU
FC2:4096
ReLU
FC3(Output):100
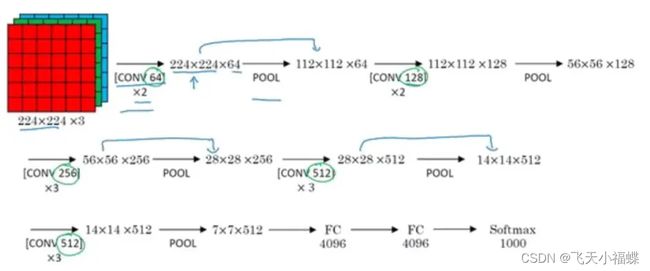
VGGNet
VGG16 各层的结构和参数如下:
C1-1层是个卷积层,其输入输出结构如下:
输入: 224 x 224 x 3 滤波器大小: 3 x 3 x 3 滤波器个数:64
输出: 224 x 224 x 64
C1-2层是个卷积层,其输入输出结构如下:
输入: 224 x 224 x 3 滤波器大小: 3 x 3 x 3 滤波器个数:64
输出: 224 x 224 x 64
P1层是C1-2后面的池化层,其输入输出结构如下:
输入: 224 x 224 x 64 滤波器大小: 2 x 2 滤波器个数:64
输出: 112 x 112 x 64
C2-1层是个卷积层,其输入输出结构如下:
输入: 112 x 112 x 64 滤波器大小: 3 x 3 x 64 滤波器个数:128
输出: 112 x 112 x 128
C2-2层是个卷积层,其输入输出结构如下:
输入: 112 x 112 x 64 滤波器大小: 3 x 3 x 64 滤波器个数:128
输出: 112 x 112 x 128
P2层是C2-2后面的池化层,其输入输出结构如下:
输入: 112 x 112 x 128 滤波器大小: 2 x 2 滤波器个数:128
输出: 56 x 56 x 128
C3-1层是个卷积层,其输入输出结构如下:
输入: 56 x 56 x 128 滤波器大小: 3 x 3 x 128 滤波器个数:256
输出: 56 x 56 x 256
C3-2层是个卷积层,其输入输出结构如下:
输入: 56 x 56 x 256 滤波器大小: 3 x 3 x 256 滤波器个数:256
输出: 56 x 56 x 256
C3-3层是个卷积层,其输入输出结构如下:
输入: 56 x 56 x 256 滤波器大小: 3 x 3 x 256 滤波器个数:256
输出: 56 x 56 x 256
P3层是C3-3后面的池化层,其输入输出结构如下:
输入: 56 x 56 x 256 滤波器大小: 2 x 2 滤波器个数:256
输出: 28 x 28 x 256
C4-1层是个卷积层,其输入输出结构如下:
输入: 28 x 28 x 256 滤波器大小: 3 x 3 x 256 滤波器个数:512
输出: 28 x 28 x 512
C4-2层是个卷积层,其输入输出结构如下:
输入: 28 x 28 x 512 滤波器大小: 3 x 3 x 256 滤波器个数:512
输出: 28 x 28 x 512
C4-3层是个卷积层,其输入输出结构如下:
输入: 28 x 28 x 512 滤波器大小: 3 x 3 x 256 滤波器个数:512
输出: 28 x 28 x 512
P4层是C4-3后面的池化层,其输入输出结构如下:
输入: 28 x 28 x 512 滤波器大小: 2 x 2 滤波器个数:512
输出: 14 x 14 x 512
C5-1层是个卷积层,其输入输出结构如下:
输入: 14 x 14 x 512 滤波器大小: 3 x 3 x 512 滤波器个数:512
输出: 14 x 14 x 512
C5-2层是个卷积层,其输入输出结构如下:
输入: 14 x 14 x 512 滤波器大小: 3 x 3 x 512 滤波器个数:512
输出: 14 x 14 x 512
C5-3层是个卷积层,其输入输出结构如下:
输入: 14 x 14 x 512 滤波器大小: 3 x 3 x 512 滤波器个数:512
输出: 14 x 14 x 512
P5层是C5-3后面的池化层,其输入输出结构如下:
输入: 14 x 14 x 512 滤波器大小: 2 x 2 滤波器个数:512
输出: 7 x 7 x 512
F6层是个全连接层,其输入输出结构如下:
输入:4096
输出:4096
F7层是个全连接层,其输入输出结构如下:
输入:4096
输出:4096
F8层也是个全连接层,即输出层,其输入输出结构如下:
输入:4096
输出:1000 作者:自兴人工智能教育 https://www.bilibili.com/read/cv2686620/ 出处:bilibili
ReseNet
我们知道,网络越深,咱们能获取的信息越多,而且特征也越丰富。但是根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
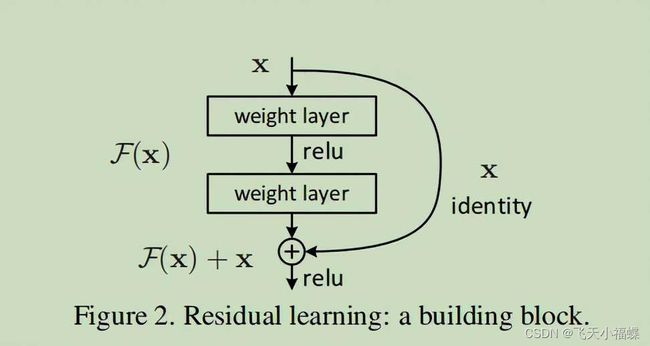
残差:观测值与输入值之间的差。这里H(x)就是观测值,x就是输入值(也就是上一层ResNet输出的特征映射)。我们一般称x为identity Function,它是一个跳跃连接;称F(x)为残差映射ResNet Function。那么咱们要求解的问题变成了H(x) = F(x)+x。
原文链接: https://www.xr686.com/71210.html
分类网络的实现
本节将展示如何搭建适用于CIFAR-10分类的VGG和ResNet网络,因为PyTroch中提供的预训练好的VGGNet和ResNet都是在ImageNet上训练的,不适合CIFAR-10。
import torch
from torch import nn
import torch.nn.functional as F
class VGG(nn.Module):
def __init__(self,cfg,num_classes=10):
super(VGG,self).__init__()
self.features=self._make_layers(cfg)
#512样本特征数,个人认为这种可能和经验有关
self.classifier=nn.Linear(512,num_classes)
def _make_layers(self,cfg):
layers=[]
#输入通道数,rgb =3
in_channels=3
for x in cfg:
if x=="M":
layers+=[nn.MaxPool2d(kernel_size=2,stride=2)]
else:
layers+=[
nn.Conv2d(in_channels,x,kernel_size=3,padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True),
]
in_channels=x
#加入平均池化
#nn.AvgPool2d(2,2)和nn.MaxPool2d(2, 2)
# 一样是图像长宽缩小为原来的一半,即图像大小为原来的1/4。
#该接口用于构建 AvgPool2D 类的一个可调用对象,
# 其将构建一个二维平均池化层,根据输入参数 kernel_size, stride, padding 等参数对输入做平均池化操作。
layers+=[nn.AvgPool2d(kernel_size=1,stride=1)]
return nn.Sequential(*layers)
def forward(self,x):
#计算特征网络
out=self.features(x)
#view(out.size(0), -1)
#目的是将多维的的数据如(none,36,2,2)平铺为一维如(none,144)。
out=out.view(out.size(0),-1)
#计算分类网络
out=self.classifier(out)
return out
class BasicBlock(nn.Module):
def __init__(self,in_channels,mid_channels,stride=1):
super(BasicBlock,self).__init__()
self.conv1=nn.Conv2d(
in_channels=in_channels,
out_channels=mid_channels,
kernel_size=3,
stride=stride,
padding=1,
bias=False,
)
self.bn1=nn.BatchNorm2d(mid_channels)
self.conv2=nn.Conv2d(
mid_channels,
mid_channels,
kernel_size=3,
stride=1,
padding=1,
bias=False,
)
self.bn2=nn.BatchNorm2d(mid_channels)
#定义短接网络,如果不需要调整维度,shortcut就是一个空的nn.Sequential
self.shortcut=nn.Sequential()
#因为shortcut后需要将两个分支累加,所以要求两个分支的维度匹配
#所以input_channels与最终的channels不匹配时,需要通过1x1卷积进行升维
if stride !=1 or in_channels !=mid_channels:
self.shortcut=nn.Sequential(
nn.Conv2d(
in_channels,
mid_channels,
kernel_size=1,
stride=stride,
bias=False
),
nn.BatchNorm2d(mid_channels),
)
def forward(self,x):
out=F.relu(self.bn1(self.conv1(x)))
out=self.bn2(self.conv2(out))
out+=self.shortcut(x)
out=F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,block,num_blocks,num_classes=10):
super(ResNet,self).__init__()
self.in_channels=64
self.conv1=nn.Conv2d(
3,64,kernel_size=3,stride=1,padding=1,bias=False
)
self.bn1=nn.BatchNorm2d(64)
#搭建
self.layer1=self._make_layer(block,64,num_blocks[0],stride=1)
self.layer2=self._make_layer(block,128,num_blocks[1],stride=2)
self.layer3=self._make_layer(block,256,num_blocks[2],stride=2)
self.layer4=self._make_layer(block,512,num_blocks[3],stride=2)
#最后的线性层
self.linear=nn.Linear(512,num_classes)
def _make_layer(self,block,mid_channels,num_blocks,stride):
strides=[stride] +[1]*(
num_blocks-1
)#stride仅指定第一个block的stride,后面的stride都是1
layers=[]
for stride in strides:
layers.append(block(self.in_channels,mid_channels,stride))
self.in_channels=mid_channels
return nn.Sequential(*layers)
def forward(self,x):
out=F.relu(self.bn1(self.conv1(x)))
out=self.layer1(out)
out=self.layer2(out)
out=self.layer3(out)
out=self.layer4(out)
out=F.avg_pool2d(out,4)
out=out.view(out.size(0),-1)
out=self.linear(out)
return out
#构建ResNet-18模型
def resnet18():
return ResNet(BasicBlock,[2,2,2,2])
#构建VGG-11模型
def vgg11():
cfg=[64,"M",128,"M",256,256,"M",512,512,"M",512,512,"M"]
return VGG(cfg)
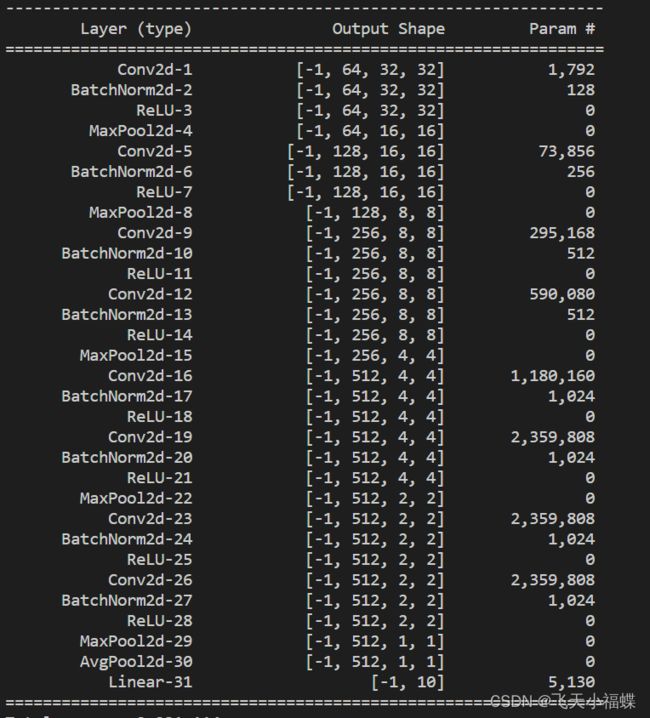
if __name__=="__main__":
from torchsummary import summary
vggnet=vgg11()
resnet=resnet18()
summary(vggnet,(3,32,32))#打印网状线
summary(resnet,(3,32,32))
模型训练
损失函数
损失函数用于衡量预测值与实际值之间的误差,而模型的训练目标就是让损失函数越来越小。损失函数的选择根据模型不同会有所不同。
优化器
优化器是预先制定好的优化模型参数的策略,是求损失函数极小值的方法。在神经网络中,因为模型和数据非常复杂,无法直接求得损失函数的极小值,所以通常采用迭代的方式求解。
学习率
学习率的选择在神经网络训练任务中至关重要,对大部分神经网络模型来说,学习率是训练过程中需要调节的最主要参数,调节学习率需要一定的经验。
训练与验证
在训练的过程中,可以进行实时验证,以便及时发现模型的过拟合现象,调整策略。
模型训练过程中的注意现象:
1.在对损失进行前向传播前,需要清空模型中的变量的梯度,避免上次的backward的梯度对这次参数更新造成影响,可以使用net.zero_grad或者optimizer.zero_grad
2.需要进行损失累加或者其他保存损失的操作时,需要取loss.item,否则会造成模型中的梯度不断积累,使显存(或内存)占用越来越高,直至溢出。
#coding=utf-8
from torch import optim,nn
import torch
import os.path as osp
from tqdm import tqdm
from torch.utils.tensorboard import SummaryWriter
from config import epochs ,device ,data_folder,epochs,checkpoint_folder
from data import create_datasets
from model import vgg11
#这里为后续的回归问题预留了一些代码
def train_val(
net,trainloader,valloder,criteron,epochs,device,model_name="cls"):
best_acc = 0.0
best_loss=1e9
writer=SummaryWriter("log")
#如果模型文件已经存在,先加载模型文件在再此基础上训练
#join(path1,path2),将path1和path2各部分组合成一个路径
#exists(path)判断指定路径(目录或文件)是否存在
if osp.exists(osp.join(checkpoint_folder,model_name+".pth")):
net.load_state_dict(
torch.load(osp.join(checkpoint_folder, model_name + ".pth"))
)
print("model finish")
for n,(num_epochs,lr) in enumerate(epochs):
#params:要训练的参数,一般我们传入的都是model.parameters()。
# lr:learning_rate学习率,会梯度下降的应该都知道学习率吧,也就是步长。
# weight_decay(权重衰退)和learning_rate(学习率)的区别
# learning_rate就是我们熟知的更新权重的方式
optimizer=optim.SGD(
net.parameters(),lr=lr,weight_decay=5e-4,momentum=0.9
)
#循环次数
for epoch in range(num_epochs):
net.train()
epoch_loss=0.0
epoch_acc=0.0
for i,(img,label) in tqdm(
enumerate(trainloader), total=len(trainloader)
):
#将照片和标签
# 这段代码的意思就是将所有最开始读取数据时的tensor
# 变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行。
img,label=img.to(device) ,label.to(device)
output=net(img)
#清空梯度
optimizer.zero_grad()
#计算损失
loss=criteron(output,label)
#反向传播
loss.backward()
#更新参数
optimizer.step()
#分类问题容易使用准确率来衡量模型效果
if model_name=="cls":
#将输入input张量,无论有几维,
# 首先将其reshape排列成一个一维向量,然后找出这个一维向量里面最大值的索引。
pred=torch.argmax(output,dim=1)
acc=torch.sum(pred==label)
#累加计算准确率
epoch_acc+=acc.item()
epoch_loss+=loss.item()*img.shape[0]
#计算平均损失
epoch_loss=epoch_loss/len(trainloader.dataset)
if model_name=="cls":
epoch_acc = epoch_acc / len(trainloader.dataset)
print(
"epoch loss:{:.8f} epoch accuary : {:.8f}".format(
epoch_loss,epoch_acc
)
)
#将损失添加到TensorBoard中
writer.add_scalar(
"epoch_loss_{}".format(model_name),
epoch_loss,
sum(e[0] for e in epochs[:n])+epoch,
)
#将准确率添加到TensorBoard中
writer.add_scalar(
"epoch_acc_{}".format(model_name),
epoch_acc,
sum(e[0] for e in epochs[:n]) + epoch,
)
else:
print("epoch loss:{:.8f}".format(epoch_loss))
writer.add_scalar(
"epoch_loss_{}".format(model_name),
epoch_loss,
sum(e[0] for e in epochs[:n]) + epoch,
)
#无梯度模式下快速验证
with torch.no_grad():
#将net设置为验证模式
# train训练模式,eval测试/评估模式
# net.eval()
val_loss=0.0
val_acc=0.0
for i,(img,label) in tqdm(enumerate(valloder), total=len(valloder) ):
img, label = img.to(device), label.to(device)
output = net(img)
#计算损失
loss = criteron(output, label)
if model_name=="cls":
#将输入input张量,无论有几维,
# 首先将其reshape排列成一个一维向量,然后找出这个一维向量里面最大值的索引。
pred=torch.argmax(output,dim=1)
acc=torch.sum(pred==label)
val_acc+=acc.item()
val_loss+=loss.item()*img.shape[0]
val_loss /=len(valloder.dataset)
val_acc /= len(valloder.dataset)
if model_name=="cls":
#如果验证之后的模型超过了目前最好的模型
if val_acc >best_acc:
#更新
best_acc=val_acc
#保存模型
torch.save(
net.state_dict(),
osp.join(checkpoint_folder,model_name+".pth"),
)
print(
"validation loss:{:.8f} epoch accuary : {:.8f}".format(
val_loss,val_acc
)
)
#加入TensorBoard
#将损失添加到TensorBoard中
writer.add_scalar(
"validation_loss_{}".format(model_name),
val_loss,
sum(e[0] for e in epochs[:n]) + epoch,
)
#将准确率添加到TensorBoard中
writer.add_scalar(
"validation_acc_{}".format(model_name),
val_acc,
sum(e[0] for e in epochs[:n]) + epoch,
)
else:
#如果得到的损失比当前最好的损失还好
if val_loss <best_loss:
#更新best_loss
best_loss=val_loss
#保存模型
torch.save(
net.state_dict(),
osp.join(checkpoint_folder,model_name),
)
print("validation loss: {:.8}".format(val_loss))
writer.add_scalar(
"epoch_loss_{}".format(model_name),
val_loss,
sum(e[0] for e in epochs[:n]) + epoch,
)
writer.close()
if __name__=="__main__":
trainloader,valloader = create_datasets(data_folder)
net=vgg11().to(device)
criteron=nn.CrossEntropyLoss()
train_val(net,trainloader,valloader,criteron,epochs,device)
上述代码定义了分类模型和回归模型的训练过程,分为如下几个步骤:
1)开始训练前,查看有没有预训练过的模型,如果有,先把模型就加载进来再在此基础上训练。这项操作可以方便在调整了参数之后继续之前的训练。
2)定义模型,优化器,损失函数和数据。
3)遍历数据,将数据输入模型进行前向传播,计算结果用于计算模型损失。
4)根据损失进行反向传播,更新模型参数。
5)每次遍历完训练数据集后,再遍历验证数据集,进行模型效果验证。验证的作用是观察模型是否过拟合,所以不一定每次训练之后都需要验证。
模型展示
#coding=utf-8
import torch
import os.path as osp
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
from model import vgg11
from config import checkpoint_folder , label_list
from data import create_datasets
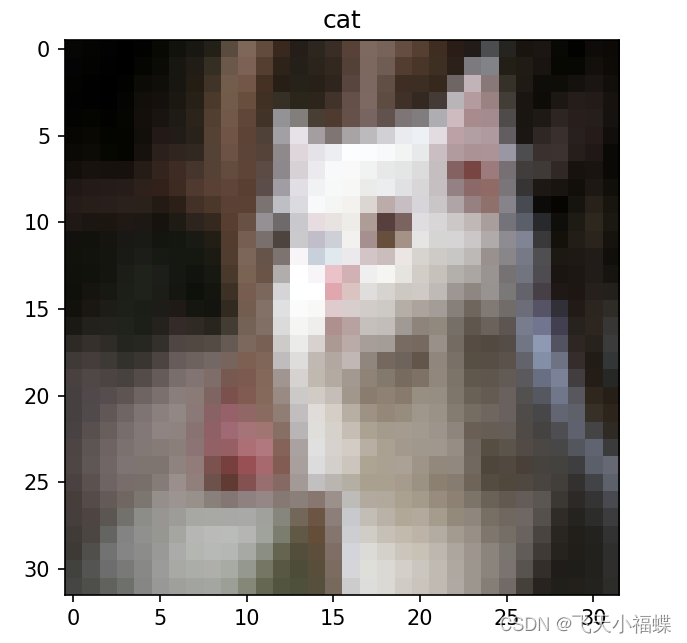
def demo(img_patch):
totensor=transforms.ToTensor()
#输入前需要调整尺寸
img=Image.open(img_patch).resize((32,32))
#添加一个维度,以适应(N,C,H,W)格式
img_tensor=totensor(img).unsqueeze(0)
net=vgg11()
#加载模型
net.load_state_dict(torch.load(osp.join(checkpoint_folder,"cls.pth")))
#验证模型
net.eval()
output=net(img_tensor)
#跳圈概率最大的预测标签
label=torch.argmax(output,dim=1)
plt.imshow(np.array(img))
plt.title(str(label_list[label]))
plt.savefig("./cat.jpg")
plt.show()
if __name__=="__main__":
demo("./cat.jpg")
多标签分类
验证码生成
#coding=utf-8
from captcha.image import ImageCaptcha
from random import randint,seed
import matplotlib.pyplot as plt
#字符列表
char_list=['0','1','2','3','4','5','6','7','8','9',
'a','b','c','d','e','f','g','h','i','j','k',
'l','m','n','o','p','q','r','s','t','u','v','w',
'x','y','z',
]
#创建空字符,用于记录验证码标签
chars=''
for i in range(4):
# Return random integer in range [a, b], including both end points.
# range(5) 相当于 range(0,5) 01234,range(a,b) ,即取值个数是b-a,不包含b
chars+=char_list[randint(0,35)]
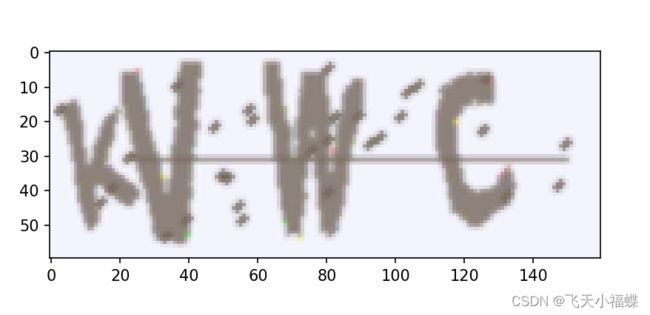
#生成验证码
image=ImageCaptcha().generate_image(chars)
plt.imshow(image)
plt.show()
#coding=utf-8
from captcha.image import ImageCaptcha
from random import randint, seed
import matplotlib.pyplot as plt
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms
import torch
from tqdm import tqdm
char_list=[
"0","1","2","3","4","5","6","7","8","9",
"a","b","c","d","e","f","g","h","i",
"j","k","l","m","n","o","p","q","r","s",
"t","u","v","w","x","y","z",
]
class CaptchaData(Dataset):
def __init__(self,char_list,num=1000):
#字符列表
self.char_list=char_list
#字符转ID
self.char2index={
self.char_list[i] : i for i in range(len(self.char_list))
}
#标签列表
self.label_list=[]
#图片列表
self.img_list=[]
#生成验证码数量
self.num=num
for i in tqdm(range(self.num)):
chars=""
for i in range(4):
# Return random integer in range [a, b], including both end points.
# range(5) 相当于 range(0,5) 01234,range(a,b) ,即取值个数是b-a,不包含b
chars+=self.char_list[randint(0,35)]
#生成验证码
image=ImageCaptcha().generate_image(chars)
self.img_list.append(image)
#不区分大小写
self.label_list.append(chars)
def __getitem__(self,index):
#通过index去除验证码和对应标签
chars=self.label_list[index]
image=self.img_list[index].convert("L")
#将字符转成Tensor
chars_tensor=self._numerical(chars)
iamge_tensor=self._totensor(image)
#把标签转换为One-Hot编码
label=chars_tensor.long().unsqueeze(1)
label_onehot=torch.zeros(4,36)
label_onehot.scatter_(1,label,1)
label=label_onehot.view(-1)
return iamge_tensor,label
def _numerical(self,chars):
#标签字符转id
chars_tensor=torch.zeros(4)
for i in range(len(chars)):
chars_tensor[i]=self.char2index[chars[i]]
return chars_tensor
def _totensor(self,image):
#图片转tensor
return transforms.ToTensor()(image)
def __len__(self):
#必须指定Dataset的长度
return self.num
#实例化一个Dataset
data=CaptchaData(char_list,num=10000)
#多进程加载
dataloader=DataLoader(data,batch_size=128,shuffle=True,num_workers=4)
val_data = CaptchaData(char_list, num=2000)
val_loader = DataLoader(val_data,batch_size=256,shuffle=True, num_workers=4)
if __name__ =="__main__":
#可以通过如下的方式从数据集中获取图片和标签
img,label=data[10]
predict=torch.argmax(label.view(-1,36),dim=1)
plt.title("-".join([char_list[lab.int()] for lab in predict]))
plt.imshow(transforms.ToPILImage()(img))
plt.show()

模型搭建
鉴于验证图片背景和文字信息都比较简单,不需要用到太复杂的网络。在这个多标签分类任务中,共有4个标签,每个标签有36个分类,所以模型最终的输出节点4X36个,分别对应着每个标签中的每个分类。
#coding=utf-8
from torchvision.models import resnet18
from torch import nn,optim
class CNN(nn.modules):
def __init__(self):
super(CNN,self).__init__()
#使用nn.Sequentioal搭建子模块
# 利用nn.Sequential()搭建好模型架构,
# 模型前向传播时调用forward()方法,模型接收的输入首先被传入nn.Sequential()包含的第一个网络模块中。
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
#在训练期间,
# 使用来自伯努利分布的样本以概率 p
# 将输入张量的一些元素随机归零。每个通道将在每次前转调用时独立归零。
# Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p(伯努利分布)停止工作
# ,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如下图所示。
nn.Dropout(0.5),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
#在训练期间,
# 使用来自伯努利分布的样本以概率 p
# 将输入张量的一些元素随机归零。每个通道将在每次前转调用时独立归零。
# Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p(伯努利分布)停止工作
# ,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如下图所示。
nn.Dropout(0.5),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.layer2= nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.Dropout(0.5),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.layer3= nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.Dropout(0.5),
nn.ReLU(),
nn.MaxPool2d(2),
)
#全连接层
self.fc=nn.Sequential(
nn.Linear(20*7*64,1024),
nn.Dropout(0.5),
nn.ReLU(),
)
#输出层
self.rfc=nn.Sequential(
nn.Linear(1024,4*36)
)
def forward(self,x):
out=self.layer1(x)
out=self.layer2(out)
out=self.layer3(out)
out=out.view(out.size(0),-1)
out=self.fc(out)
out=self.rfc(out)
return out
net=CNN()
模型训练
训练模型之前,可以先预设好学习率的变化规则,这种小型任务训练时间较短。
#coding=utf-8
import torch
from torch import nn,optim
from chaptcha_model import net
from captcha_data import dataloader,val_loader
from tqdm import tqdm
#分段的平台式学习率衰减方法
epoch_lr=[
(1000,0.1),
(100,0.1),
(100,0.1),
(100,0.0001),
]
#将device设置为cpu
#定义设备
device = (torch.device("cuda")
if torch.cuda.is_available() else torch.device("cpu"))
#多标签分类损失函数
criteron=nn.MultiLabelSoftMarginLoss()
def train():
net.to(device)
accuracies=[]
losses=[]
val_accuracies=[]
val_losses=[]
for n,(num_epoch,lr) in enumerate(epoch_lr):
#优化器
optimizer=optim.SGD(
net.parameters(),lr=lr,momentum=0.9,weight_decay=5e-4
)
for epoch in range(num_epoch):
#验证
net.train()
epoch_loss=0.0
epoch_acc=0.0
for i,(img,label) in tqdm(enumerate(dataloader)):
out=net(img.to(device))
label=label.to(device)
#清空梯度
optimizer.zero_grad()
#计算loss
loss=criteron(out,label.to(device))
loss.backward()
#更新参数
optimizer.step()
#整理输出,方便与标签进行比对
predict = torch.argmax(out.view(-1,36),dim=1)
true_label = torch.argmax(label.view(-1, 36), dim=1)
epoch_acc +=torch.sum(predict==true_label).item()
epoch_loss +=loss.item()
if epoch % 3==0:
#no_grad()模式不计算梯度,可以运行得快一点
with torch.no_grad():
net.eval()
val_loss=0.0
val_acc=0.0
for i,(img,label) in tqdm(enumerate(val_loader)):
out = net(img.to(device))
label = label.to(device)
loss=criteron(out,label.to(device))
predict = torch.argmax(out.view(-1,36),dim=1)
true_label = torch.argmax(label.view(-1, 36), dim=1)
val_acc +=torch.sum(predict==true_label).item()
val_loss +=loss.item()
val_acc/=len(val_loader.dataset)*4
val_loss/=len(val_loader)
epoch_acc/=len(dataloader.dataset)*4
epoch_loss/=len(dataloader)
print(
"epoch:{},epoch loss:{},epoch accuracy:{}".format(
epoch+sum([e[0] for e in epoch_lr[:n]]),epoch_loss,epoch_acc
)
)
if epoch%3==0:
print("epoch:{},val loss:{},val accuracy:{}".format(
epoch + sum([e[0] for e in epoch_lr[:n]]), val_loss,
val_acc))
for i in range(3):
val_accuracies.append(val_acc)
val_losses.append(val_losses)
accuracies.append(epoch_acc)
losses.append(epoch_loss)
if __name__=="__main__":
train()
验证码识别
模型训练完毕之后,就可以加载模型,用来识别验证码了,这里直接选择使用验证集中得验证码进行识别。
#coding=utf-8
from chaptcha_model import net
from captcha_data import val_data,char_list
from chaptcha_train import device
import matplotlib.pyplot as plt
from torchvision import transforms
import torch
#验证模式
net.eval()
#训练集
img,label=val_data[12]
prediction=net(img.unsqueeze(0).to(device)).view(4,36)
predict=torch.argmax(prediction,dim=1)
#打印预测结果
print(
"Predict Label:{}".format(
"-".join([char_list[lab.int()] for lab in predict])
)
)
plt.imshow(transforms.ToPILImage()(img))
plt.show()