三维重建方法汇总
一、什么是三维重建
三维重建是用相机拍摄真实世界的物体、场景,通过计算机视觉技术进行处理,从而得到物体的三维模型。
主要涉及技术包括:多视图立体几何、深度图估计、点云处理、网格重建和优化、纹理贴图、马尔可夫随机场、图像分割等。
主要应用领域包括:增强现实、混合现实、机器人导航、自动驾驶、工业工件尺寸检测、平整度检测等。
二、传统三维重建方法
2.1 RGBD
基础
深度相机:可以直接获取被测对象三维信息的相机。
深度相机主要分为结构光相机和ToF相机。结构光相机是指通过一个红外投影仪向前方投射光栅或激光散斑,再使用相机拍摄是光栅和光斑的形状尺寸,从而得到物体三维信息。ToF是通过测量发射脉冲与接受之间的时间,从而计算目标距离。
KinectFusion - 2011
论文:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6162880
代码:https://github.com/chrdiller/KinectFusionApp
KinectFusion是第一个使用RGBD相机的三维重建系统,使用的地图是TSDF地图,后续很多实时三维重建系统都是在KinectFusion上扩展的。
实现流程:首先获取RGBD图像,计算点云以及归一化后的法向量;然后通过ICP算法计算当前帧的相机位姿;之后将当前点云融合到TSDF地图中,最后通过TSDF地图以及当前帧的位姿预测处当前帧的深度图像。
TSDF地图是一种网格式的地图,先选定要建模的三维空间,按照一定分辨率,将这个空间分成许多小块,存储每个小块内部的信息。每个TSDF体素内,存储了该小块与最近的物体表面的距离。如果小块在最近物体表面的前方,它就有一个正的值;反之,如果该小块位于表面之后,那么这个值就为负。由于物体表面通常是很薄的一层,所以就把值太大的和太小的都取成1和-1,这就得到了截断之后距离,也就是所谓的TSDF。
BundleFunsion - 2016
论文:https://arxiv.org/abs/1604.01093
代码:https://github.com/niessner/BundleFusion
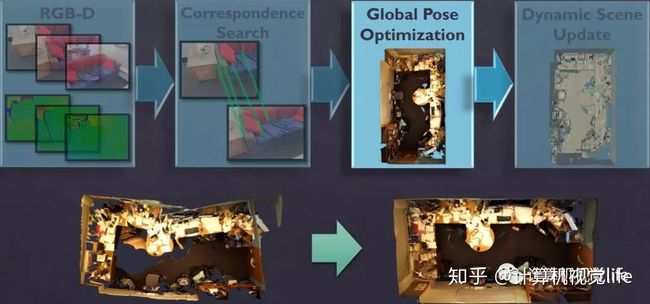
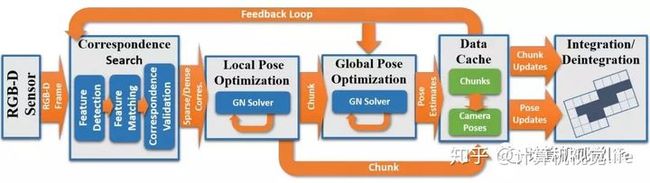
大致流程:输入的color+depth的数据流首先需要做帧与帧之间的对应关系匹配,然后做全局位姿优化,将整体的漂移校正过来(上图下方所示),整个重建过程中模型是在不断动态更新的。
在匹配方面,这里使用的是一种sparse-then-dense的并行全局优化方法。也就是说,先使用稀疏的SIFT特征点来进行比较粗糙的配准,因为稀疏特征点本身就可以用来做loop closure检测和relocalization。然后使用稠密的几何和光度连续性进行更加细致的配准。
在位姿优化方面。这里使用了一种分层的 local-to-global 的优化方法,如下图所示。总共分为两层,在最低的第一层,每连续10帧组成一个chunk,第一帧作为关键帧,然后对这个chunk内所有帧做一个局部位姿优化。在第二层,只使用所有的chunk的关键帧进行互相关联然后进行全局优化。为什么要分层这么麻烦呢?或者说这样分层有什么好处呢?因为可以剥离出关键帧,减少存储和待处理的数据。并且这种分层优化方法减少了每次优化时的未知量,保证该方法可扩展到大场景而漂移很小。
在稠密场景重建方面。该算法在特征匹配设置了三道筛选策略。第一种是直接对关键点本身分布的一致性和稳定性进行考验。第二道关卡是对特征匹配对跨越的表面面积进行考验,去掉特别小的,因为跨越面积较小的的话很容易产生歧义。第三道关卡是进行稠密的双边几何和光度验证,去掉重投影误差较大的匹配对。
特点:GPU下实时鲁棒跟踪,可以解决漂移现象,去除了实施以来。
2.2 MVS多帧图像重建
基础
MVS是从一系列图像中重建3D模型。
流程:图像采集 - 位姿计算 - 模型重建 - 纹理贴图。其中图像采集可以是视频等序列化图像,也可以是非连续图像。在位姿计算中根据是否为序列化图像,有不同的方法进行位姿计算。
应用:影音娱乐,AR文物,自动驾驶,大型场景三维重建等。
综述:Multi-View Stero: A Tutorial
COLMAP - 2016
论文:https://ieeexplore.ieee.org/document/7780814
代码:https://github.com/colmap/colmap
SFM通常首先进行特征提取/匹配以及后续的几何校验滤出外点,经过上述步骤可以得到所谓的场景图scene graph,该场景图是后续的增量式的基础(提供数据关联等信息)。增量式重建中需要非常仔细地挑选两帧进行重建,在图像进行注册(即定位当前帧在地图中的位姿)之前,需要进行三角化场景点/滤出外点以及BA优化当前的模型。
COLMAP算法的创新点在于
- 提出了一种多模型几何校验策略:提高了初始化与三角化的鲁棒性;
- 后续最优帧选择策略:提升位姿结算鲁棒性与精度;
- 提出鲁棒三角化方法:使得重建的场景结构更加完整;
- 提出迭代BA,重三角化以及外点滤除策略对重建的完整性与精度都有贡献;
- 高效BA参数化方法对稠密图像的重建具有帮助;
OpenMVS
代码:https://github.com/cdcseacave/openMVS
OpenMVS的输入是图像和位姿,其中位姿可以是从COLMAP、SLAM等多种方式计算得到。然后进行稠密重建 - 点云融合 - 初始网格重建 - 网格优化 - 纹理贴图。
OpenMVS是目前的三维重建的框架中,复原效果比较好的;而且提供自动化的脚本,使用起来也不是很难,可以在github中下载编译安装。
三、基于深度学习的三维重建
3.1 mesh重建
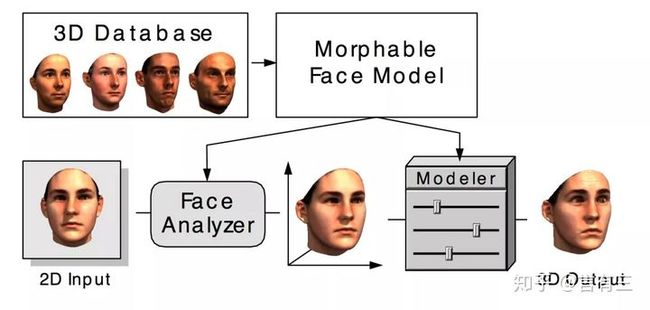
基于3DMM重建
3DMM(3D Morphable Model)可形变模型:任意一张人脸图像都可以根据如下公式重建
S m o d e l = S 2 + ∑ i = 1 m − 1 α i S i , T m o d e l = T 2 + ∑ i = 1 m − 1 β i T i S_{model} = S^2+\sum^{m-1}_{i=1}\alpha_i S_i, T_{model} = T^2+\sum^{m-1}_{i=1}\beta_i T_i Smodel=S2+i=1∑m−1αiSi,Tmodel=T2+i=1∑m−1βiTi

拓展网络:Nonlinear 3D Face Morphable Model
- 学习了一个非线性模型,比传统的线性模型具有更大的表示能力;
- 弱监督学习:利用大量没有三维扫描的二维图像,共同学习模型和模型拟合算法
拓展网络:2DASL
- 自监督模型,克服3D标注数据不足问题
拓展网络:PRNet
- 以端到端的方式解决了人脸对齐和三维人脸的问题,使其一起完成,而且不受低维解空间的限制
- 运行速度超过100FPS的轻量级框架
IF-Nets
IF-NETS是物体、人体重建网络。该网络可以将稀疏、稠密点云重建为mesh模型。由于数据集的限制(大多数据是CAD模型渲染得到的),真实场景的模型恢复效果一般。
PifuHD
PIFu是人体重建网络。
算法优点
- 同时支持 single-view 和 multi-view;
- 高度复杂的形状,如发型、服装,以及它们的变化和变形都可以用统一的方式数字化
- 重建精度、细节表现比现有的方法更优;
- 与体素表示不同,内存效率更高,可以处理任意拓扑结构,并且生成的表面与输入图像在空间上对齐
3.1 深度图重建MVSNet
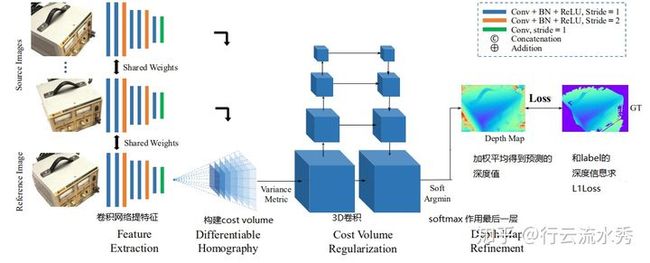
网络结构:输入是任意位姿的多张图像,且多张图片之间的关系需要被整体考虑。
MVSNet本质是借鉴基于两张图片cost volume的双目立体匹配的深度估计方法,扩展到多张图片的深度估计,而基于cost volume的双目立体匹配已经较为成熟,所以MVSNet本质上也是借鉴一个较为成熟的领域,然后提出基于可微分的单应性变换的cost volume用于多视图深度估计。
过程:
(1)输入一张reference image(为主) 和几张source images(辅助);
(2)分别用网络提取出下采样四分之一的32通道的特征图;
(3)采用立体匹配(即双目深度估计)里提出的cost volume的概念,将几张source images的特征利用单应性变换( homography warping)转换到reference image,在转换的过程中,类似极线搜索,引入了深度信息。构建cost volume可以说是MVSNet的关键。
具体costvolume上一个点是所有图片在这个点和深度值上特征的方差,方差越小,说明在该深度上置信度越高。
(4)利用3D卷积操作cost volume,先输出每个深度的概率,然后求深度的加权平均得到预测的深度信息,用L1或smoothL1回归深度信息,是一个回归模型。
(5)利用多张图片之间的重建约束(photometric and geometric consistencies)来选择预测正确的深度信息,重建成三维点云。
拓展网络:MVS-JDACS-MS
在无监督网络框架中引入协同分割和数据增强策略,克服不同视角图像之间天然存在的光照差异干扰。
拓展网络:MVS-PatchMatchNet
一种基于传统PatchMatch算法的高效multi-view stereo框架。
四、算法测评网站
双目立体匹配:https://vision.middlebury.edu/stereo/eval3/
车载双目立体相关算法:http://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=stereo

室外场景:https://www.eth3d.net/low_res_two_view
计算机视觉相关论文、模型、数据集、代码汇总:https://paperswithcode.com/sota
本博客文章首先发布于个人博客网站:https://www.mahaofei.com/,欢迎大家访问。