Python Pandas读取文件和DataFrame、Series的基本使用
1.读取文件和数据属性的基本查看方法
| 数据类型 | 读取方法 |
|---|---|
| csv,tsv,txt | pd.read_csv(filepath) |
| excel | pd.read_excel(filepath) |
| mysql | pd.read_sql(filepath) |
注意,读取mysql时,要先进行sql连接
import pymysql
conn = pymysql.connect(
host="127.0.0.1"
user="root"
password="123456"
database="data_info"
charset="utf8"
)
mysql_info=pd.read_sql("select * from information",con=conn)
其他一些查看表属性的基本操作
improt pandas as pd
filepath="./information.txt"
info = pd.read_csv(filepath,sep=",",header=None,names=["column_A","column_B","column_C"],skiprows=2)
#第二个参数表示文件中的数据以什么形式进行分割,第三个参数表示文件有无标题行,第四个参数表示对文件的每一列的属性进行命名,最后一个参数表示跳过前两行数据不进行处理
info.head() #读取前几行数据
info.shape #用元祖返回数据的行数和列数
info.columns #查看列索引
info.index #查看行索引
2.DataFrame和Series
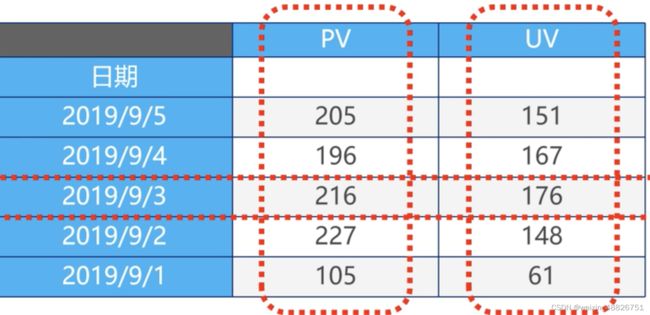
如上图,一整张表就是一个DataFrame,即DataFrame是一个二维数组。PV一整列就称为是一个Series,2019/9/3的一整行数据也称为一个Series,即Series是一个一维数组。
一.Series
(1)创建Series
# 使用一个列表生成一个Series
s1 = pd.Series([1, 2, 3, 4])
# 使用数组生成一个Series
s2 = pd.Series(np.arange(7))
# 使用一个字典生成Series,其中字典的键,就是索引
s3 = pd.Series({'one':1, 'two':2, 'three':3})
(2)Series的常用操作

例如s3是上面的一组Series数据,其中第一列表示索引,第二列是数据值
"""方式二(推荐)"""
s3.loc["java"] #输出61
s3.loc["c","python"] #输出61,62
s3.loc[0] #索引方式,输出第1个元素62
s3.loc["php":"h5"] #切片方式,输出86,65,93
二.DataFrame
(1)创建DataFrame
#用字典嵌套列表来创建
fruits_dict = { 'Fruits':['Apple','Banana','Cherry','Dates','Eggfruit'],
'Quantity': [5, 10, 8, 3, 7],
}
#用列表来创建
pd.DataFrame(data=[['Apple',5],
['Banana',10],
['Cherry',8],
['Dates',3],
['Eggfruit',7]],
columns = ['Fruits','Quantity'],
index=[1,2,3,4,5])
结果: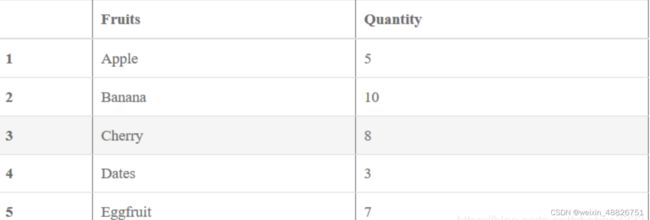
(2)设置索引
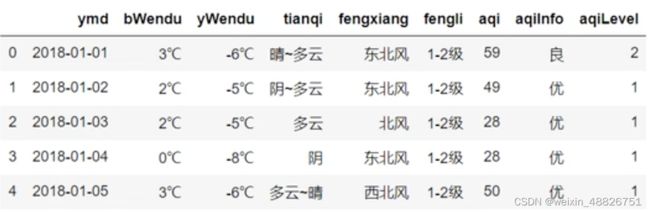
例如s3是上面的一个文件数据,行默认是按照0-4进行索引,若要设置成按照ymd属性的值进行索引,表示如下:
info.set_index("ymd",inplace=True,drop=True) #drop=True表示丢弃原来的索引
(3)替换操作
#替换bWendu和yWendu的后缀的摄氏度
s3.loc[:,"bWendu"] = s3["bWendu"].str.replace("℃","").astype("int32") #注意一定要先转换成字符串进行操作,最后再转换成int32类型
s3.loc[:,"yWendu"] = s3["yWendu"].str.replace("℃","").astype("int32")
处理后结果: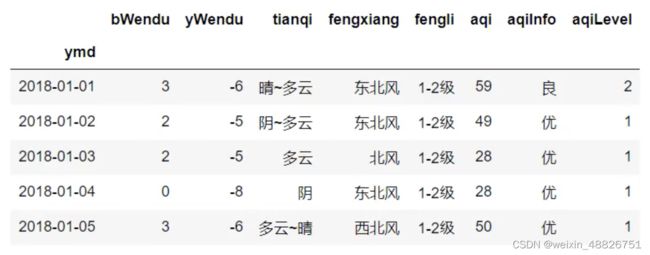
(3)常用操作
#得到单个值
s3.loc["2018-01-03","bWendu"] #逗号前为行索引,逗号后为列索引
#得到一个Series
s3.loc["2018-01-03",["bWendu","yWendu"]]
#得到一个Series
s3.loc[["2018-01-03","2018-01-04"],"bWendu"]
#得到一个DataFrame
s3.loc[["2018-01-03","2018-01-05"],["bWendu","yWendu"]
#简单条件查询
s3.loc[s3["yWendu"]<10,:] #返回所有最低温度<10的所有行
#函数查询
s3.loc[lambda s3:(s3["bWendu"]<=30) &&(s3["yWendu"]>=10),: ] #返回所有最低温度>10且最高温度<30的所有行