知识图谱构建概述
一直想写知识图谱系列一个博客,借工作之便梳理一下知识图谱的生命周期以及构建过程中的心(趟)得(坑),以便供大家共同交流学习,有不当之处,不吝赐教。知识图谱构建的生命周期主要包括
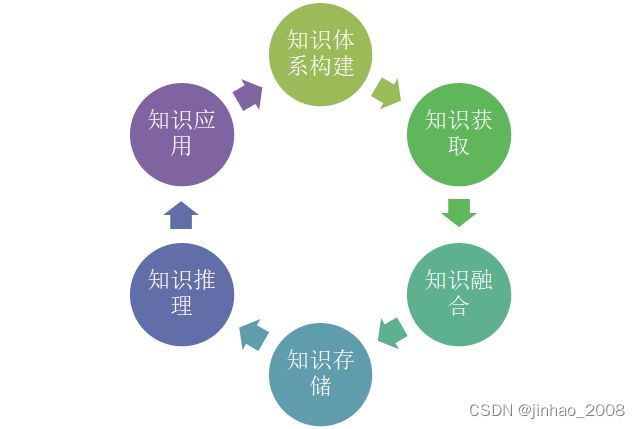
1)基本定义
a)、知识体系(Knowledge Schema)对于知识数据的描述和定义,是描述知识数据的“元数据”(metadata)
本体:是信息组织的一种形式,表达、共享、重要知识的一种方法,通过对概念、术语及其相互关系的规范化描述,勾画出某一领域的基本知识体系和描述语言;使用合适的逻辑来形式化;对某一事实结构的非正式约束规则,可以理解和表达为一组概念及其定义和相互关系;显示化,规范化,公理化。
知识图谱:以三元组为基本单元,以有向标签图为数据结构,从知识本体和知识实例两个层次 ,对世界万物进行体系化、规范化描述,并支持高效的知识推理和语义计算的大规模知识系统。
b)、知识体系主要包含三个方面
i)、词汇、类别/概念的定义和描述
概念是人类万物准确归类的前提;
概念的发展使得人类以最经济有效的方式认识世界;
概念是联想的重要隐含因素;
概念是归纳与推理基础;
ii)、概念之间的相互关系:分类、非分类
iii)、公理:反向、传递、对称等规则、值约束等
c)、知识体系的意义
1)、共享概念化的框架规范
2)、知识体系最重要的就是概念及其属性与关系的定义,有助于实现语义理解
d)、知识存储
知识库(图数据库):服务于知识体系规定的知识单元的载体;
2) 构建知识体系
知识体系构建,也称知识建模,是指采用什么样的方式表达知识,其核心是构建一个本体对目标知识进行描述。在这个本体中需要定义出知识的类别体系、每个类别下所属的概念和实体所具有的属性以及概念之间,实体之间的语义关系,同时也包含定义在这个本体上的一些推理规则。
a)、约束:属性的定义域、值域。
b)、构建过程
i)、确定领域及任务
ii)、体系复用
iii)、定义术语、概念/类别
iv)、确定分类体系
v)、确定关系、属性
vi)、定义约束
c)本体建模工具protege
i)、用于构建域模型与基于知识的本体化应用程序
ii)、提供了大量的知识模型框架与动作,用于创建、可视化、操纵各种表现形式的本体;
iii)、可以通过用户定制实现域友好(领域)的支持,用于创建知识模型并填充数据
iv)、可以通过两种方式进行扩展:插件和基于java的API
v)、常见功能:类建模、实例编辑、模型处理和模型交换
d) 知识获取
知识获取的目标是从海量的文本数据中通过信息抽取的方式获取知识,其方法根据所处理数据源的不同而不同。
知识图谱中数据的主要来源有各种形式的结构化数据、半结构化数据和非结构化文本数据,从结构化和半结构化的数据源中抽取知识是工业界常用的技术手段,这类数据源的信息抽取方法相对简单,而且数据噪音少,经过人工过滤后能够得到高质量的结构化三元组。学术界主要集中再非结构化文本中实体的识别和实体之间关系的抽取,它涉及自然语言分析和处理技术,难度大,它是构建知识图谱的核心技术。
基于结构化、半结构化、非结构化数据的知识体系构建。非结构化文本数据相比于结构化、半结构化数据要丰富很多,因此自然语言分析处理技术备受工业界和学术界关注。由于目前知识表述大多以实体关系三元组为主,因此知识抽取任务包括如下基本任务:实体识别、实体消歧、关系抽取和事件抽取等。
e) 知识融合
知识容二虎是对不同来源、不同语言或不同结构的知识进行融合,从而对已有知识图谱进行补充、更新和去重。
从融合的对象看,知识融合包括:知识体系的融合和实例的融合。知识体系融合就是两个或多个异构知识体系进行融合,相同的类别、属性、关系进行映射。而实例级别的融合是对于两个不同知识图谱中实例(实体实例、关系实例)进行融合,包括不同体系下的实例、不同语言的实例。
知识融合的核心是计算两个知识图谱中两个节点或边之间的语义映射关系。从融合的周四hi图谱类型看,知识融合可以分为:竖直方向的融合和水平方向的融合。竖直方向的融合是指融合较高层通用本体与低层领域本体或实例数据,实现实例数据的互补。
f) 知识存储
知识存储就是研究何种方式将已有知识图谱进行存储,它的存储方式主要两种形式:RDF格式存储和图数据库。目前典型的开源图数据库是Neo4j,这种图数据库优缺点以及近期研究的热点归纳如下:
| neo4j | 特征 |
|---|---|
| 优点 | 具有完善的图查询语言; 支持大多数的图挖掘算法; |
| 缺点 | 数据更新慢; 大节点的处理开销大; |
| 研究热点 | 针对上述的问题,子图筛选、子图同构判定 等技术是目前图数据库的研究热点。 |
g) 知识推理
通过知识建模、知识获取和知识融合,我们基本可以构建一个可用的知识图谱。但是由于处理数据的不完备性,所构建的知识图谱中肯定存在知识缺失现象(包括实体缺失、关系缺失)。由于数据的稀疏性,我们也很难利用抽取或者融合的方法对于缺失的知识进行补齐。因此需要采用推理的手段发现已有的隐含知识。目前知识推理的研究主要集中在针对知识图谱中缺失关系的补足,即挖掘两个实体之间隐含的语义关系。主要采用一下两种方法:
| 方法 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 基于传统逻辑规则的方法进行推理 | 研究的热点如何自动学习推理规则,以及如何解决推理过程中的规则冲突问题 | ||
| 基于表示学习的推理 | 该学习方式,将传统推理过程转化为基于分布式表示的语义向量相似度任务。 | 容错率高,可学习; | 不可解释,缺乏语义约束。 |
h) 知识应用
i)智能搜索
在智能搜索方面,基于知识图谱的搜索引擎,内部存储了大量的实体以及实体之间的关系,可以根据用户查询准确的返回答案。
ii)自动问答
在自动问答方面,可以利用知识图谱中实体及其关系进行推理得到答案。
iii)推荐
在推荐方面,可以利用知识图谱中实体的关系向用户推荐相关的产品
iv) 决策支持
知识图谱能够把领域内复杂知识通过信息抽取、数据挖掘、语义匹配、语义计算、知识推理等过程精准地描述出来,并可以描述知识的演化过程和发展规律,从而为研究和决策提供准确、可追踪、可解释、可推理的知识数据。
3)、典型知识体系
a)、SUMO(Suggeated Upper Merges Ontology)
目前最大的公共本体
与WordNet进行映射
可以作为构建新知识体系的基础
https://www.ontologyportal.org/
b)、GeoNames
GeoNames是一个免费的全球地理数据库。
GeoNames的目标是把各种来源的免费数据进行集成并制作成一个数据库或一系列的Web服务。
GeoNames地名辞典包含了1100万个地点将近200种语言的1100万个地名和200万种别名。地理信息还详细到坐标、行政区划、邮政编码、人口、海拔和时区。GeoNames的数据收集自(美国)国家测绘机构、国家统计署、国家邮政局,还有美国陆军。
https://www.geonames.org/
c)、统一的知识体系标准
cnSchema.org是一个基于社群的数据标准,结合中文特定应用场景的应用需求,我们连接了schema.org,WikiData等开放数据接口标准,为中文领域的知识图谱,聊天机器人,网页开发等在线服务提供数据接口标准。
http://cnschema.org/
4)、已有的知识图谱融合系统
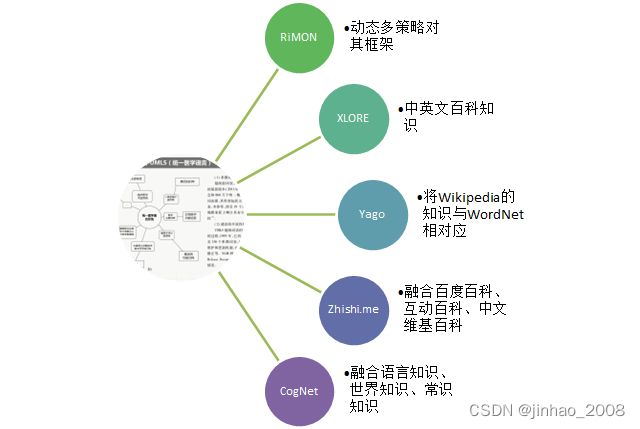
参考文献
知识图谱 - 知识体系构建与知识融合_无脑敲代码,bug漫天飞的博客-CSDN博客_知识图谱schema