SQL使用技巧(2)查询结果的分层汇总
专题:SQL使用技巧——实践是检验SQL函数的唯一标准
- 一.Hive中分层汇总
-
- 1.1分层汇总 rollup()
- 1.2分层汇总 cube()
- 1.3可选择的分层汇总 grouping set()
- 二.其他情况
-
- 2.1最简洁实用的cube()方式
本文所用数据还使用 SQL使用技巧(1)HQL中的合并与拆分 的示例数据
一.Hive中分层汇总
提示:decode() 和 cube()在orcale和hive中使用差异较大。除非使用环境的Hive支持orcale语法,例如:星环TDH、腾讯TDW
1.1分层汇总 rollup()
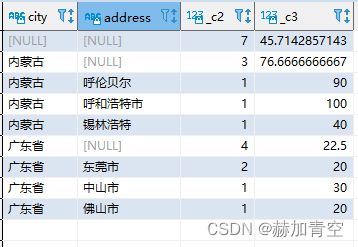
-- with rollup
select city,address,count(1),avg(age)
from default.concat_split_demo2
group by city,address
with ROLLUP
;
-- rollup()
select city,address,count(1),avg(age)
from default.concat_split_demo2
group by rollup(city,address)
;
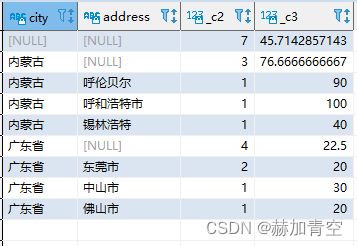
从结果可见,with rollup和rollup(所有group字段)的结果是一样的。rollup()是递进的聚合括号内的字段,并不是把所有组合都来一遍,这点显著区别于cube(),具体请对比cube()结果。
项目中使用情况说明1:经过汇总的结果数据通常也会被用于前台报表展示,如果前台报表筛选city和address两个字段,NULL值不参与谓词计算(=,<>,>…等均无效),所以需要提前将NULL转换为固定值。
-- grouping(),grouping()的结果汇总是1否则是0,所以有下面的case when
select case when grouping(city) = 1 then '255' else city end city
,case when grouping(address) = 1 then '255' else address end address
,count(1) ct,avg(age) ag
from default.concat_split_demo2
group by rollup(city,address)
;

1.2分层汇总 cube()
cube()会将括号内所有字段的组合都罗列出来,具体见下例。可跟rollup()第二个结果做对比,cube()结果多了城市单独做聚合的内容。函数没有好坏,视自己的需求而定。
下方示例中,单纯的Hive环境不能写成group by city,cube(address)来避免维度爆炸,具体使用时可以在自己的环境内尝试各种写法,不能一概而论,实践是检验SQL函数的唯一标准。
-- cube()
select city
,address
,count(1)
,avg(age)
from default.concat_split_demo2
group by cube(city,address)
;

1.3可选择的分层汇总 grouping set()
如果group by字段很多的时候,使用cube()和rollup()可能会出现很多不想要的结果,如果只想展示自己想要的组合结果,可以使用grouping sets()进行限制。
具体使用方法见下例,grouping sets()的方式可以单独设定,下面采用了3种维度的汇总,第一种只用city,第二种只用city和address,第三种只用city和name,而如果使用cube()的话会出现8种组合,可见多维度情况下,使用grouping sets() 可以有效避免 类似使用cube()所造成的维度爆炸。
-- grouping sets
select case when grouping(city) = 1 then '255' else city end city
,case when grouping(address) = 1 then '255' else address end address
,case when grouping(name) = 1 then '255' else name end name
,count(1) ct
from (
select * from concat_split_demo1
union all
select * from concat_split_demo2
) a
group by city,address,name
grouping sets (
(city)
,(city,address)
,(city,name)
)
;
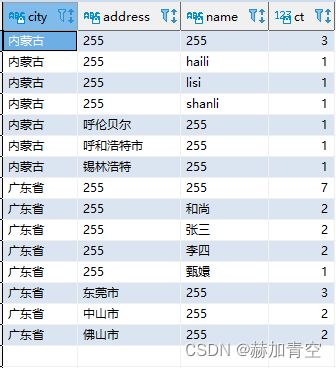
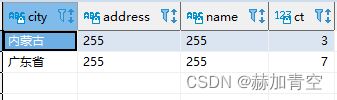
当grouping sets()只选择一个维度时,结果更加明显
-- grouping sets()
select case when grouping(city) = 1 then '255' else city end city
,case when grouping(address) = 1 then '255' else address end address
,case when grouping(name) = 1 then '255' else name end name
,count(1) ct
from (
select * from concat_split_demo1
union all
select * from concat_split_demo2
) a
group by city,address,name
grouping sets (
(city)
)
;
二.其他情况
2.1最简洁实用的cube()方式
下方代码使用环境是腾讯TDW,支持Hive和orcale语法。在非腾讯TDW系统可能无法执行,仅做参考。其中两点做下解释
1.decode()上面没讲到过,这里的例子是如果grouping(city)(grouping()的结果汇总是1否则是0)的结果是1则填写’255’,否则填city字段的内容。
2.cube()字段可以只选需要的,例如只对city结果做汇总,id不做汇总,这点Hive做不到
-- decode()/grouping()/cube()
select id
,decode(grouping(city),1,'255',city) as PlatID
,count(distinct user_id) as cuser
from table
group by id,cube(city);
其他情况碰到再做补充
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,可收藏可转发但请勿转载,如有雷同纯属巧合。