基于 Paddle2.0 的强化学习新玩法 —— 通关超级马里奥兄弟
基于 Paddle2.0 的强化学习新玩法 —— 通关超级马里奥兄弟
本文目录
- 基于 Paddle2.0 的强化学习新玩法 —— 通关超级马里奥兄弟
-
- 前言
- 马里奥游戏环境简介
- PPO 算法简介
- 基于 Paddle2.0 实现 PPO
- 通关小技巧
- 效果展示
- 全文回顾
前言
超级马里奥兄弟作为几代人的童年回忆,陪伴了我们的成长。如今随着深度强化学习的发展,越来越多的游戏已经被 AI 征服,那么今天我们展示如何用深度强化学习,试着通关超级马里奥兄弟吧!
马里奥游戏环境简介

马里奥游戏环境链接:
https://pypi.org/project/gym-super-mario-bros/
游戏环境允许玩家或 AI 在 3 次尝试内通过游戏的 32 关。环境提供了 RIGHT_ONLY,SIMPLE_MOVEMENT,COMPLEX_MOVEMENT 三种难度的操作模式。只需要对环境输入各种动作所代表的数值,就能实现对马里奥的各种操作。
PPO 算法简介
PPO 算法论文链接:
https://arxiv.org/abs/1707.06347
相信了解强化学习的各位一定听说过近端策略优化 PPO 算法吧。
PPO 算法是一种新型的 Policy Gradient 算法,由于 Policy Gradient 算法对步长十分敏感,若没有选择到合适的步长,在训练过程中新旧策略的变化可能会出现差异如果过大的现象,不利于模型的收敛。PPO 提出了新的目标函数可以在多个训练步骤中实现小幅度的更新,解决了 Policy Gradient 算法中步长难以确定的问题。
作为强化学习领域的 SOTA 算法,PPO 是每一个学习者最常用的算法。OpenAI 也早已把 PPO 作为自己的默认算法。
基于 Paddle2.0 实现 PPO
下面就让我们用 Paddle2.0 实现 PPO 算法吧。
不过在此之前,先让我们看看模型结构。我们的模型是 Actor-Critic 结构,但是对模型结构做了一点简化,Actor 和 Critic 只在输出层有所区别 。由于模型处理的是图像信息,故在全连接层前加入了卷积层。
class MARIO(Layer):
def __init__(self, input_num, actions):
super(MARIO, self).__init__()
self.num_input = input_num
self.channels = 32
self.kernel = 3
self.stride = 2
self.padding = 1
self.fc = 32 * 6 * 6
self.conv0 = Conv2D(out_channels=self.channels,
kernel_size=self.kernel,
stride=self.stride,
padding=self.padding,
dilation=[1, 1],
groups=1,
in_channels=input_num)
self.relu0 = ReLU()
self.conv1 = Conv2D(out_channels=self.channels,
kernel_size=self.kernel,
stride=self.stride,
padding=self.padding,
dilation=[1, 1],
groups=1,
in_channels=self.channels)
self.relu1 = ReLU()
self.conv2 = Conv2D(out_channels=self.channels,
kernel_size=self.kernel,
stride=self.stride,
padding=self.padding,
dilation=[1, 1],
groups=1,
in_channels=self.channels)
self.relu2 = ReLU()
self.conv3 = Conv2D(out_channels=self.channels,
kernel_size=self.kernel,
stride=self.stride,
padding=self.padding,
dilation=[1, 1],
groups=1,
in_channels=self.channels)
self.relu3 = ReLU()
self.linear0 = Linear(in_features=int(self.fc), out_features=512)
self.linear1 = Linear(in_features=512, out_features=actions)
self.linear2 = Linear(in_features=512, out_features=1)
def forward(self, x):
x = paddle.to_tensor(data=x)
x = self.conv0(x)
x = self.relu0(x)
x = self.conv1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.relu3(x)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.linear0(x)
logits = self.linear1(x)
value = self.linear2(x)
return logits, value
本文的 PPO 属于在线学习,大致分为以下三个模块:
- 获取动作轨迹
- 计算优势函数
- 数据采样与模型参数更新
由于 PPO 是 Policy Gradient 算法,我们的智能体需要生成一个类别分布,即一个包含每个动作发生概率的向量,然后根据向量中的概率,选择我们的动作,最后与环境交互并将返回的各种状态信息以及奖励存入列表当中备用。
下面是获取动作轨迹模块的部分代码:
for _ in range(num_local_steps):
logits, value = model(curr_states)
values.append(value.squeeze())
policy = F.softmax(logits, axis=1)
old_m = Categorical(policy) # 生成类别分布
action = old_m.sample([1]) # 采样
old_log_policy = old_m.log_prob(action)
old_log_policies.append(old_log_policy)
[agent_conn.send(("step", act)) for agent_conn, act in zip(envs.agent_conns, action.numpy().astype("int8"))]
state, reward, done, info = zip(*[agent_conn.recv() for agent_conn in envs.agent_conns])
然后就是计算优势函数啦。优势函数具体点是指当前状态 s s s 采用动作 a a a 的收益与当前状态 s s s平均收益的差,优势越大,动作 a a a 收益就越高,同一状态下采用该动作的概率也就应该更高。
A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^{\pi}(s,a)=Q^{\pi}(s,a)-V^{\pi}(s) Aπ(s,a)=Qπ(s,a)−Vπ(s)
这里用到了广义优势估计 GAE,几乎所有最先进的 Policy Gradient 算法实现里面都使用了该技术。这项技术主要是起到修正我们 Critic 模型提供的价值,使其成为方差最小的无偏估计。
for value, reward, done in list(zip(values, rewards, dones))[::-1]:
gae = gae * gamma * tau
gae = gae + reward + gamma * next_value.detach().numpy() * (1.0 - done) - value.detach().numpy()
next_value = value
R.append(paddle.to_tensor(gae + value.detach()))
advantages = R - values
最后是使用 PPO 算法更新模型参数,这里并没有计算 KL 散度,而是通过截断的方式实现小幅度的更新。
for i in range(num_epochs):
indice = paddle.randperm(num_local_steps * num_processes)
for j in range(batch_size):
batch_indices = indice[
int(j * (num_local_steps * num_processes / batch_size)): int((j + 1) * (
num_local_steps * num_processes / batch_size))]
logits, value = model(paddle.gather(states, batch_indices, axis=0))
new_policy = F.softmax(logits, axis=1)
new_m = Categorical(new_policy)
new_log_policy = new_m.log_prob(paddle.gather(actions, batch_indices, axis=0))
ratio = paddle.exp(new_log_policy - paddle.gather(old_log_policies, batch_indices, axis=0))
advantages = paddle.gather(advantages, batch_indices, axis=0)
actor_loss = paddle.concat([np.squeeze(ratio * advantages), np.squeeze(paddle.clip(ratio, 1.0 - epsilon, 1.0 + epsilon) * advantages)])
actor_loss = -paddle.mean(paddle.min(actor_loss, axis=0))
critic_loss = F.smooth_l1_loss(paddle.gather(R, batch_indices), value)
entropy_loss = paddle.mean(new_m.entropy())
total_loss = actor_loss + critic_loss - beta * entropy_loss
clip_grad = paddle.nn.ClipGradByNorm(clip_norm=0.25)
optimizer = paddle.optimizer.Adam(learning_rate=lr, parameters=model.parameters(), grad_clip=clip_grad)
optimizer.clear_grad()
total_loss.backward()
optimizer.step()
由于篇幅有限,这里只放上了简要思路与部分删减后的代码,感兴趣的同学可以直接看看源码。
通关小技巧
马里奥的通关小技巧有很多,这里主要给大家提供三个方向的思路:
- 原始输入图像预处理
简化图像特征,叠合连续4帧图像作为输入,可以起到捕捉游戏环境的动态性的作用。 - 奖励函数重设置
不同的奖励函数所鼓励的行为是不同的,例如提高踩怪的奖励,就可以使模型更倾向于踩怪。本文重新分配了一下各种奖励的权重,对于通关也有更丰厚的额外奖励。
def step(self, action):
state, reward, done, info = self.env.step(action)
if self.monitor:
self.monitor.record(state)
state = process_frame(state)
reward += (info["score"] - self.curr_score) / 40.
self.curr_score = info["score"]
if done:
if info["flag_get"]:
reward += 50
else:
reward -= 50
self.env.reset()
return state, reward / 10., done, info
- 多线程/并行训练
并行化可以有效提高模型的训练效率,同时也是目前强化学习的趋势之一。本文通过 python 的 multiprocess 模块实现并行化。
class MultipleEnvironments:
def __init__(self, world, stage, action_type, num_envs, output_path=None):
self.agent_conns, self.env_conns = zip(*[mp.Pipe() for _ in range(num_envs)])
'''选择操作模式
'''
if action_type == "right":
actions = RIGHT_ONLY
elif action_type == "simple":
actions = SIMPLE_MOVEMENT
else:
actions = COMPLEX_MOVEMENT
'''创建多环境
'''
self.envs = [create_train_env(world, stage, actions, output_path=output_path) for _ in range(num_envs)]
self.num_states = self.envs[0].observation_space.shape[0]
self.num_actions = len(actions)
'''创建多进程
'''
for index in range(num_envs):
process = mp.Process(target=self.run, args=(index,))
process.start()
self.env_conns[index].close()
def run(self, index):
self.agent_conns[index].close()
while True:
request, action = self.env_conns[index].recv()
if request == "step":
self.env_conns[index].send(self.envs[index].step(int(action)))
elif request == "reset":
self.env_conns[index].send(self.envs[index].reset())
else:
raise NotImplementedError
效果展示
本文以关卡 1-1 为例(为了避免翻车),由于多线程模型仍然存在一点小问题,这里采用单线程训练。
训练过程的 Reward 值变化趋势如下图所示:
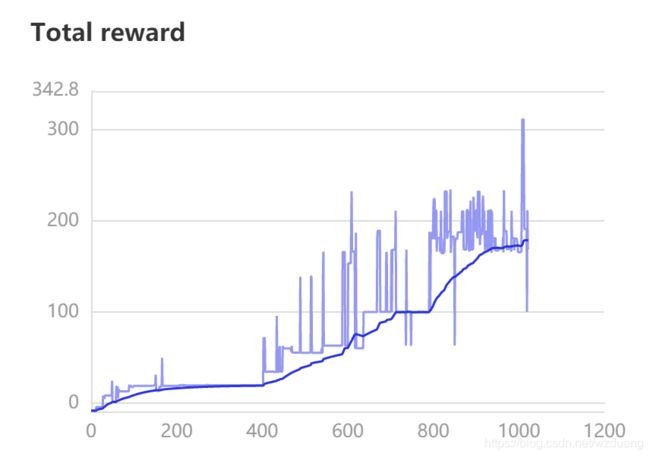
最后邀请大家收看全损画质通关全过程(好像有点压缩过头了…):
全文回顾
首先本文简单介绍了一下超级马里奥兄弟的游戏环境,然后本文介绍了与 PPO 算法有关的一些知识,并基于 Paddle2.0 进行实现了该算法。
除此之外,本文还总结了一些通关小技巧,并以第一关为例展示了训练过程,最后以全损画质的形式向大家展示了训练完成后的效果。
训练代码项目链接:https://aistudio.baidu.com/aistudio/projectdetail/1434971(测试中)
通关展示项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/1434950