Seq2Seq+Attention代码
文章目录
-
-
- 题目
- 翻译任务
- 比较和单纯的Seq2Seq的区别
-
- 注意力分配过程
- 根据输入得到预测的hx
- 预测值的hx和注意力分配相结合
- 得到预测的值
- 完整代码
-
题目
'''
Description: Seq2Seq+Attention
Autor: 365JHWZGo
Date: 2021-12-18 18:24:19
LastEditors: 365JHWZGo
LastEditTime: 2021-12-26 16:57:05
'''
翻译任务
将Chinese time翻译成English time
Chinese time order: yy/mm/dd [‘31-04-26’, ‘04-07-18’, ‘33-06-06’]
English time order: dd/M/yyyy [‘26/Apr/2031’, ‘18/Jul/2004’, ‘06/Jun/2033’]
可选择词汇,共27个
enc_v_dim = 27
dec_v_dim = 27
Vocabularies: {‘7’, ‘0’, ‘-’, ‘9’, ‘Apr’, ‘4’, ‘Jun’, ‘Feb’, ‘’, ‘’, ‘Jan’, ‘May’, ‘Oct’, ‘/’, ‘3’, ‘Nov’, ‘Jul’, ‘Aug’, ‘Mar’, ‘2’, ‘6’, ‘Sep’, ‘Dec’, ‘’, ‘8’, ‘1’, ‘5’}
x示例输入和张量表示
x index sample:
31-04-26
[6 4 1 3 7 1 5 9]
y示例输入和张量表示
y index sample:
26/Apr/2031
[14 5 9 2 15 2 5 3 6 4 13]
比较和单纯的Seq2Seq的区别
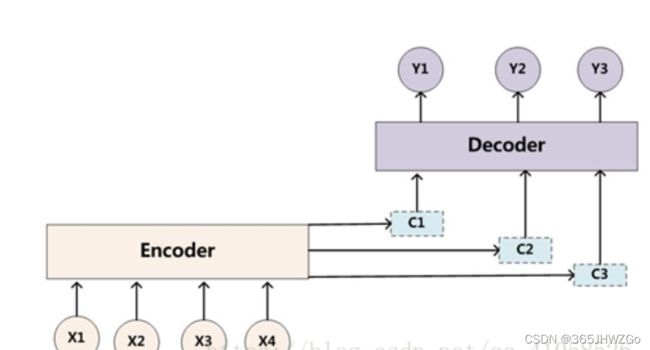
加入注意力机制后就是使得每次的LSTM的h,c都是集中于翻译相关值生成的。
注意力的计算用到了General Attention,它的得分公式是
S c o r e ( k , q ) = k T W a q Score(k,q) = k^TW_aq Score(k,q)=kTWaq
这里的 q 是一个进行注意的对象,在任务中为decoder中新生成的hx(隐状态)
k k k是被注意的对象,在任务中为encoder中的输出o
意思是将decoder每预测一个词, 我都拿着这个decoder现在的信息q去和encoder输出的所有信息k做注意力的计算。
注意力分配过程
# hx 相当于q,decoder生成的hidden state
# o 相当于k,encoder所有信息
# w*q
self.attn(hx.unsqueeze(1)
# k^t*w*q
score = torch.matmul(self.attn(hx.unsqueeze(1)),o.permute(0,2,1))
# 将得分归一化
score01 = softmax(score, dim=2)
# 不同的权重代表不同的注意力分配,在decoder输出hx的作用下
attnDistribute = torch.matmul(score01,o)
根据输入得到预测的hx
# 计算得到的hx
hx, cx = self.decoder_cell(dec_in, (hx, cx))
预测值的hx和注意力分配相结合
ha = torch.cat([context.squeeze(1),hx],dim=1)
得到预测的值
result = self.decoder_dense(ha)
下图是一个简单举例
完整代码
from torch import nn
import torch
import utils
from torch.utils.data import DataLoader
from torch.nn.functional import cross_entropy,softmax
class Seq2Seq(nn.Module):
def __init__(self,enc_v_dim, dec_v_dim, emb_dim, hidden_size, max_pred_len, start_token, end_token):
super().__init__()
self.hidden_size = hidden_size # hidden_size
self.dec_v_dim = dec_v_dim
self.max_pred_len = max_pred_len
self.start_token = start_token
self.end_token = end_token
# encoder
self.enc_embeddings = nn.Embedding(enc_v_dim,emb_dim)
self.enc_embeddings.weight.data.normal_(0,0.1)
self.encoder = nn.LSTM(emb_dim,hidden_size,1,batch_first=True)
# decoder
self.dec_embeddings = nn.Embedding(dec_v_dim,emb_dim)
self.attn = nn.Linear(hidden_size,hidden_size)
self.decoder_cell = nn.LSTMCell(emb_dim,hidden_size)
self.decoder_dense = nn.Linear(hidden_size*2,dec_v_dim)
self.opt = torch.optim.Adam(self.parameters(),lr=0.001)
def encode(self,x):
embedded = self.enc_embeddings(x) # [batch_size, seq_len, emb_dim]
hidden = (torch.zeros(1,x.shape[0],self.hidden_size),torch.zeros(1,x.shape[0],self.hidden_size))
o,(h,c) = self.encoder(embedded,hidden) # [batch_size, seq_len, hidden_size], [num_layers * num_directions, batch_size, hidden_size]
return o,h,c
def inference(self,x,return_align=False):
self.eval()
# x [batch_size,seq_len]
o,hx,cx = self.encode(x) # [batch_size, seq_len, hidden_size], [num_layers * num_directions, batch_size, hidden_size] * 2
hx,cx = hx[0],cx[0] # [batch_size, hidden_size]
start = torch.ones(x.shape[0],1) # [batch_size, 1]
start[:,0] = torch.tensor(self.start_token)
start= start.type(torch.LongTensor)
dec_emb_in = self.dec_embeddings(start) # [batch_size, 1, emb_dim]
dec_emb_in = dec_emb_in.permute(1,0,2) # [1, batch_size, emb_dim]
dec_in = dec_emb_in[0] # [batch_size, emb_dim]
output = []
for i in range(self.max_pred_len):
# hx.unsqueeze(1)在第一个维度上添加一个维度
score = torch.matmul(self.attn(hx.unsqueeze(1)),o.permute(0,2,1)) # [batch_size, 1, seq_len]
score01 = softmax(score, dim=2) # [batch_size, 1, seq_len]
attnDistribute = torch.matmul(score01,o) # [batch_size, 1, hidden_size]
hx, cx = self.decoder_cell(dec_in, (hx, cx))
ha = torch.cat([attnDistribute.squeeze(1),hx],dim=1) # [batch_size, hidden_size *2]
result = self.decoder_dense(ha)
result = result.argmax(dim=1).view(-1,1)
dec_in=self.dec_embeddings(result).permute(1,0,2)[0]
output.append(result)
output = torch.stack(output,dim=0)
self.train()
return output.permute(1,0,2).view(-1,self.max_pred_len)
def train_logit(self,x,y):
o,hx,cx = self.encode(x) # [batch_size, seq_len, hidden_size], [num_layers * num_directions, batch_size, hidden_size] * 2
hx,cx = hx[0],cx[0] # [batch_size, hidden_size]
dec_in = y[:,:-1] # [batch_size, seq_len]
dec_emb_in = self.dec_embeddings(dec_in) # [batch_size, seq_len, emb_dim]
dec_emb_in = dec_emb_in.permute(1,0,2) # [seq_len, batch_size, emb_dim]
output = []
for i in range(dec_emb_in.shape[0]):
score = torch.matmul(self.attn(hx.unsqueeze(1)),o.permute(0,2,1)) # [batch_size, 1, seq_len]
score01 = softmax(score, dim=2) # [batch_size, 1, seq_len]
attnDistribute = torch.matmul(score01,o) # [batch_size, 1, hidden_size]
hx, cx = self.decoder_cell(dec_emb_in[i], (hx, cx)) # [batch_size, hidden_size]
ha = torch.cat([attnDistribute.squeeze(1),hx],dim=1) # [batch_size, hidden_size *2]
result = self.decoder_dense(ha) # [batch_size, dec_v_dim]
output.append(result)
output = torch.stack(output,dim=0) # [seq_len, batch_size, dec_v_dim]
return output.permute(1,0,2) # [batch_size, seq_len, dec_v_dim]
def step(self,x,y):
self.opt.zero_grad()
logit = self.train_logit(x,y)
dec_out = y[:,1:]
loss = cross_entropy(logit.reshape(-1,self.dec_v_dim),dec_out.reshape(-1))
loss.backward()
self.opt.step()
return loss.detach().numpy()
dataset = utils.DateData(4000)
loader = DataLoader(
dataset,
batch_size=32,
shuffle=True
)
model = Seq2Seq(
dataset.num_word,
dataset.num_word,
emb_dim=16,
hidden_size=32,
max_pred_len=11,
start_token=dataset.start_token,
end_token=dataset.end_token
)
def train():
for i in range(100):
for batch_idx , batch in enumerate(loader):
bx, by, _ = batch
loss = model.step(bx,by)
if batch_idx % 70 == 0:
target = dataset.idx2str(by[0, 1:-1].data.numpy())
pred = model.inference(bx[0:1])
res = dataset.idx2str(pred[0].data.numpy())
src = dataset.idx2str(bx[0].data.numpy())
print(
"Epoch: ",i,
"| t: ", batch_idx,
"| loss: %.3f" % loss,
"| input: ", src,
"| target: ", target,
"| inference: ", res,
)
# pkl_data = {"i2v": dataset.i2v, "x": dataset.x[:6], "y": dataset.y[:6], "align": model.inference(dataset.x[:6], return_align=True)}
# with open("./visual/tmp/attention_align.pkl", "wb") as f:
# pickle.dump(pkl_data, f)
if __name__ == "__main__":
train()